
Büyük dil modellerini (LLM'ler) anlamak için bir SEO kılavuzu
Yayınlanan: 2023-05-08Anahtar kelime araştırması için büyük dil modelleri kullanmalı mıyım? Bu modeller düşünebilir mi? ChatGPT arkadaşım mı?
Kendinize bu soruları soruyorsanız, bu rehber tam size göre.
Bu kılavuz, SEO'ların büyük dil modelleri, doğal dil işleme ve aradaki her şey hakkında bilmesi gerekenleri kapsar.
Büyük dil modelleri, doğal dil işleme ve basit terimlerle daha fazlası
Bir insana bir şeyi yaptırmanın iki yolu vardır – onlara yapmasını söyleyin ya da kendilerinin yapmasını umun.
Bilgisayar bilimi söz konusu olduğunda, programlama robota bunu yapmasını söylerken, makine öğrenimi robotun bunu kendisinin yapmasını ummaktır. Birincisi denetimli makine öğrenimi, ikincisi ise denetimsiz makine öğrenimidir.
Doğal dil işleme (NLP), metni sayılara ayırmanın ve ardından bilgisayarları kullanarak analiz etmenin bir yoludur.
Bilgisayarlar sözcüklerdeki kalıpları ve daha da geliştikçe sözcükler arasındaki ilişkileri analiz eder.
Denetimsiz bir doğal dil makine öğrenimi modeli, birçok farklı türde veri kümesi üzerinde eğitilebilir.
Örneğin, "Waterworld" filminin ortalama incelemelerine göre bir dil modeli eğittiyseniz, "Waterworld" filminin incelemelerini yazmakta (veya anlamakta) iyi bir sonuç elde edersiniz.
Onu "Waterworld" filmiyle ilgili yaptığım iki olumlu eleştiriye göre eğitirseniz, yalnızca bu olumlu eleştirileri anlayacaktır.
Büyük dil modelleri (LLM'ler), bir milyardan fazla parametreye sahip sinir ağlarıdır. O kadar büyükler ki daha genelleştirilmişler. Yalnızca "Waterworld" için olumlu ve olumsuz eleştiriler konusunda değil, aynı zamanda yorumlar, Wikipedia makaleleri, haber siteleri ve daha fazlası konusunda da eğitilirler.
Makine öğrenimi projeleri, bağlam içinde ve dışında birçok şeyle çalışır.
Hataları belirlemeye ve ona bir kedi göstermeye çalışan bir makine öğrenimi projeniz varsa, o projede iyi olmayacaktır.
Bu nedenle sürücüsüz arabalar gibi şeyler çok zordur: Bağlam dışı o kadar çok sorun vardır ki, bu bilgiyi genelleştirmek çok zordur.
LLM'ler görünür ve olabilir diğer makine öğrenimi projelerinden çok daha genelleştirilmiş. Bunun nedeni, verilerin çok büyük olması ve milyarlarca farklı ilişkiyi çözebilme yeteneğidir.
Buna izin veren çığır açan teknolojilerden biri hakkında konuşalım - transformatörler.
Transformatörleri sıfırdan açıklamak
Bir tür sinir ağı mimarisi olan transformatörler, NLP alanında devrim yarattı.
Dönüştürücülerden önce çoğu NLP modeli, metni her seferinde bir kelime olacak şekilde sırayla işleyen, tekrarlayan sinir ağları (RNN'ler) adı verilen bir tekniğe dayanıyordu. Bu yaklaşımın, yavaş olması ve metindeki uzun vadeli bağımlılıkları ele almakta zorlanması gibi sınırlamaları vardı.
Transformers bunu değiştirdi.
2017 dönüm noktası niteliğindeki "Dikkat Tek İhtiyacınız Olan Şeydir" başlıklı makalesinde Vaswani ve diğerleri. trafo mimarisini tanıttı.
Transformatörler, metni sırayla işlemek yerine, kelimeleri paralel olarak işlemek için "öz dikkat" adı verilen bir mekanizma kullanır ve bu da onların uzun vadeli bağımlılıkları daha verimli bir şekilde yakalamalarına olanak tanır.
Önceki mimari, RNN'leri ve uzun kısa süreli bellek algoritmalarını içeriyordu.
Bunun gibi yinelenen modeller, metin veya konuşma gibi veri dizilerini içeren görevler için yaygın olarak kullanılıyordu (ve hala kullanılıyor).
Ancak bu modellerde bir sorun var. Verileri her seferinde yalnızca bir parça işleyebilirler, bu da onları yavaşlatır ve ne kadar veriyle çalışabileceklerini sınırlar. Bu sıralı işleme, bu modellerin yeteneğini gerçekten sınırlar.
Dikkat mekanizmaları, sekans verilerini işlemenin farklı bir yolu olarak tanıtıldı. Bir modelin tüm veri parçalarına aynı anda bakmasına ve hangi parçaların en önemli olduğuna karar vermesine olanak tanırlar.
Bu, birçok görevde gerçekten yardımcı olabilir. Bununla birlikte, dikkati kullanan çoğu model aynı zamanda yinelenen işlemeyi kullanır.
Temel olarak, verileri aynı anda bu şekilde işlemeye başladılar, ancak yine de sırayla bakmaları gerekiyordu. Vaswani ve diğerlerinin makalesi havada uçuştu, "Ya sadece dikkat mekanizmasını kullansaydık?"
Dikkat, modelin girdi dizisini işlerken belirli bölümlerine odaklanmasının bir yoludur. Örneğin, bir cümle okurken, bağlama ve ne anlamak istediğimize bağlı olarak doğal olarak bazı kelimelere diğerlerinden daha fazla dikkat ederiz.
Bir dönüştürücüye bakarsanız, model, dizinin genel anlamını anlamak için ne kadar önemli olduğuna bağlı olarak giriş dizisindeki her kelime için bir puan hesaplar.
Model daha sonra dizideki her kelimenin önemini tartmak için bu puanları kullanır ve önemsiz kelimelere daha az, önemli kelimelere daha fazla odaklanmasına izin verir.
Bu dikkat mekanizması, modelin, tüm diziyi sırayla işlemek zorunda kalmadan, girdi dizisinde birbirinden uzak olabilecek sözcükler arasındaki uzun vadeli bağımlılıkları ve ilişkileri yakalamasına yardımcı olur.
Bu, bir cümlenin veya daha uzun bir metin dizisinin anlamını hızlı ve doğru bir şekilde anlayabildiğinden, dönüştürücüyü doğal dil işleme görevleri için çok güçlü kılar.
“Kedi hasırın üzerine oturdu” cümlesini işleyen bir trafo modeli örneğini ele alalım.
Cümledeki her kelime, bir gömme matrisi kullanılarak bir vektör, bir dizi sayı olarak temsil edilir. Diyelim ki her kelime için yerleştirmeler:
- : [0,2, 0,1, 0,3, 0,5]
- kedi : [0,6, 0,3, 0,1, 0,2]
- oturdu : [0,1, 0,8, 0,2, 0,3]
- açık : [0,3, 0,1, 0,6, 0,4]
- : [0,5, 0,2, 0,1, 0,4]
- mat : [0,2, 0,4, 0,7, 0,5]
Daha sonra dönüştürücü, cümledeki diğer tüm kelimelerle olan ilişkisine dayalı olarak cümledeki her kelime için bir puan hesaplar.
Bu, her kelimenin cümledeki diğer tüm kelimelerin yerleşimleriyle iç içe geçmesinin nokta çarpımı kullanılarak yapılır.
Örneğin, "kedi" kelimesinin puanını hesaplamak için, diğer tüm kelimelerin katıştırılmasıyla katıştırılmasının nokta çarpımını alırdık:
- " Kedi ": 0,2*0,6 + 0,1*0,3 + 0,3*0,1 + 0,5*0,2 = 0,24
- " kedi oturdu ": 0,6*0,1 + 0,3*0,8 + 0,1*0,2 + 0,2*0,3 = 0,31
- " kat açık ": 0,6*0,3 + 0,3*0,1 + 0,1*0,6 + 0,2*0,4 = 0,39
- " kat ": 0,6*0,5 + 0,3*0,2 + 0,1*0,1 + 0,2*0,4 = 0,42
- “ kedi matı ”: 0,6*0,2 + 0,3*0,4 + 0,1*0,7 + 0,2*0,5 = 0,32
Bu puanlar, her kelimenin "kedi" kelimesiyle ilgisini gösterir. Dönüştürücü daha sonra bu puanları, ağırlıkların puanlar olduğu kelime gömmelerinin ağırlıklı bir toplamını hesaplamak için kullanır.
Bu, "kedi" kelimesi için cümledeki tüm kelimeler arasındaki ilişkileri dikkate alan bir bağlam vektörü oluşturur. Bu işlem cümledeki her kelime için tekrarlanır.
Her hesaplamanın sonucuna göre cümledeki her kelime arasına bir çizgi çizen dönüştürücü olarak düşünün. Bazı çizgiler daha zayıf, bazıları ise daha az.
Transformatör, herhangi bir tekrarlayan işleme olmaksızın yalnızca dikkati kullanan yeni bir model türüdür. Bu, onu çok daha hızlı hale getirir ve daha fazla veriyi işleyebilir.
GPT transformatörleri nasıl kullanır?
Google'ın BERT duyurusunda, aramanın bir girdinin tam bağlamını anlamasına izin vermekle övündüklerini hatırlarsınız. Bu, GPT'nin transformatörleri nasıl kullanabileceğine benzer.
Bir benzetme kullanalım.
Her biri bir klavyenin önünde oturan bir milyon maymununuz olduğunu hayal edin.
Her maymun klavyesindeki tuşlara rastgele basarak harf ve sembol dizileri oluşturuyor.
Bazı dizeler tamamen saçmalıkken, diğerleri gerçek sözcüklere ve hatta tutarlı cümlelere benzeyebilir.
Bir gün sirk eğitmenlerinden biri bir maymunun “Olmak ya da olmamak” yazdığını görür ve eğitmen maymuna bir ödül verir.
Diğer maymunlar bunu görür ve kendi ödüllerini umarak başarılı maymunu taklit etmeye başlarlar.
Zaman geçtikçe, bazı maymunlar sürekli olarak daha iyi ve daha tutarlı metin dizileri üretirken, diğerleri anlamsız sözler üretmeye devam ediyor.
Sonunda, maymunlar metindeki tutarlı kalıpları tanıyabilir ve hatta taklit edebilir.
LLM'lerin maymunlardan bir ayağı vardır çünkü LLM'ler ilk olarak milyarlarca metin parçası üzerinde eğitilirler. Kalıpları zaten görebilirler. Ayrıca bu metin parçaları arasındaki vektörleri ve ilişkileri de anlarlar.
Bu, doğal dile benzeyen yeni metin oluşturmak için bu kalıpları ve ilişkileri kullanabilecekleri anlamına gelir.
Generative Pre-trained Transformer'ın kısaltması olan GPT, doğal dil metni oluşturmak için dönüştürücüleri kullanan bir dil modelidir.
Doğal dildeki kelimeler ve deyimler arasındaki kalıpları ve ilişkileri öğrenmesine izin veren internetten büyük miktarda metin üzerinde eğitildi.
Model, bir istemi veya birkaç kelimelik bir metni alarak ve eğitim verilerinden öğrendiği kalıplara dayanarak hangi kelimelerin geleceğini tahmin etmek için dönüştürücüleri kullanarak çalışır.
Model, sonrakileri bilgilendirmek için önceki kelimelerin bağlamını kullanarak kelime kelime metin oluşturmaya devam eder.
GPT iş başında
GPT'nin faydalarından biri, son derece tutarlı ve bağlamsal olarak alakalı doğal dil metni üretebilmesidir.
Bunun, ürün açıklamaları oluşturmak veya müşteri hizmetleri sorularını yanıtlamak gibi birçok pratik uygulaması vardır. Şiir veya kısa öyküler oluşturmak gibi yaratıcı bir şekilde de kullanılabilir.
Ancak, bu yalnızca bir dil modelidir. Veriler üzerinde eğitilmiştir ve bu veriler güncelliğini yitirmiş veya yanlış olabilir.
- Bilgi kaynağı yoktur.
- İnternette arama yapamaz.
- Hiçbir şey “bilmiyor”.
Sırada hangi kelimenin geleceğini tahmin ediyor.
Bazı örneklere bakalım:
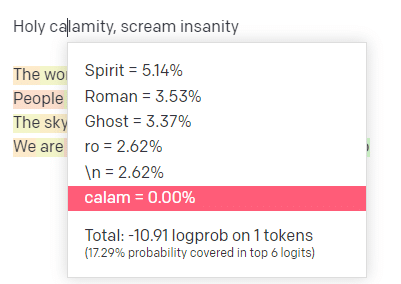
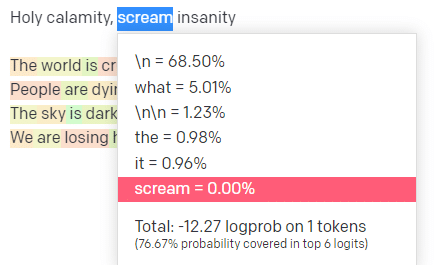
OpenAI oyun alanında, klasik Handsome Boy Modeling School şarkısı 'Holy calamity [[Bear Witness ii]]'nin ilk satırını taktım.
Yanıtı gönderdim, böylece hem girdi hem de çıktı satırlarının olasılığını görebiliriz. Bunun bize söylediklerinin her bir bölümünü inceleyelim.
İlk kelime/belirteç için "Kutsal" giriyorum. En çok beklenen girdinin Spirit, Roman ve Ghost olduğunu görebiliriz.
Ayrıca ilk altı sonucun, bir sonraki adımın olasılıklarının yalnızca %17,29'unu kapsadığını görebiliriz: bu, bu görselleştirmede göremediğimiz ~%82 başka olasılıklar olduğu anlamına gelir.
Bu konuda kullanabileceğiniz farklı girdileri ve bunların çıktınızı nasıl etkilediğini kısaca tartışalım.
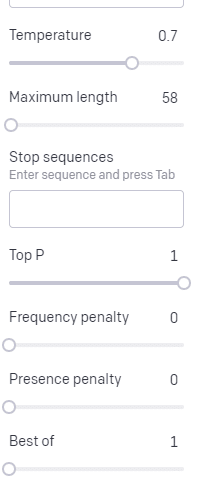
Sıcaklık , modelin en yüksek olasılığa sahip kelimeler dışındaki kelimeleri yakalama olasılığının ne kadar yüksek olduğudur, üst P, bu kelimeleri nasıl seçtiğidir.
Dolayısıyla, "Kutsal Felaket" girişi için üst P, sonraki belirteçlerin [Hayalet, Romalı, Ruh] kümesini nasıl seçtiğimizdir ve sıcaklık, daha fazla çeşitliliğe karşı en olası belirteç için gitme olasılığının ne olduğudur.
Sıcaklık daha yüksekse, daha az olası bir jeton seçme olasılığı daha yüksektir.
Bu nedenle, yüksek bir sıcaklık ve yüksek bir P, muhtemelen daha çılgın olacaktır. Çok çeşitli (en yüksek P) arasından seçim yapıyor ve şaşırtıcı jetonları seçme olasılığı daha yüksek.


Yüksek sıcaklıkta ancak daha düşük bir P, daha küçük bir olasılık örneğinden şaşırtıcı seçenekler seçecek olsa da:
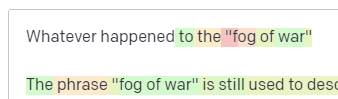

Ve sıcaklığın düşürülmesi, en olası sonraki belirteçleri seçer:

Bence bu olasılıklarla oynamak size bu tür modellerin nasıl çalıştığına dair iyi bir fikir verebilir.
Halihazırda tamamlanmış olanlara dayalı olarak olası sonraki seçimlerden oluşan bir koleksiyona bakıyor.
Bu aslında ne anlama geliyor?
Basitçe söylemek gerekirse, LLM'ler bir girdi koleksiyonunu alır, onları sallar ve çıktılara dönüştürür.
Bunun insanlardan çok farklı olup olmadığı konusunda insanların şaka yaptığını duydum.
Ama insanlar gibi değil - LLM'lerin bilgi tabanı yoktur. Bir şey hakkında bilgi almıyorlar. Son kelimeye göre bir dizi kelimeyi tahmin ediyorlar.
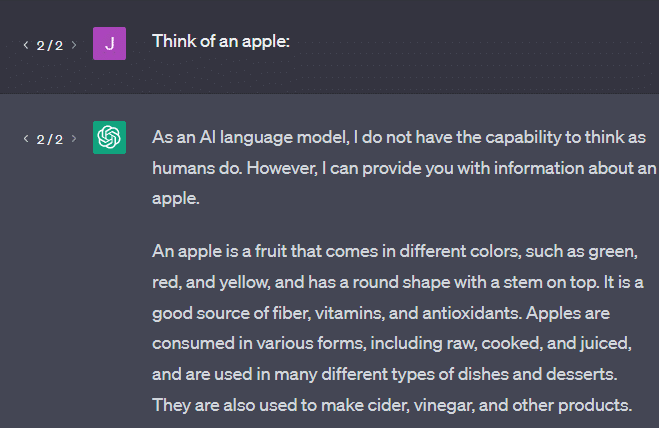
Başka bir örnek: bir elma düşünün. Akla ne gelir?
Belki bir tanesini zihninizde döndürebilirsiniz.
Belki bir elma bahçesinin kokusunu, pembe bir hanımın tatlılığını vs. hatırlarsınız.
Belki Steve Jobs'u düşünürsünüz.
Şimdi "bir elma düşün" komut isteminin ne döndürdüğünü görelim.
Bu noktada ortalıkta dolaşan “Stokastik Papağanlar” kelimesini duymuş olabilirsiniz.
Stokastik Papağanlar, GPT gibi LLM'leri tanımlamak için kullanılan bir terimdir. Papağan, duyduğunu taklit eden bir kuştur.
Dolayısıyla, LLM'ler bilgiyi (kelimeler) aldıkları ve duyduklarına benzer bir şey çıkardıkları için papağan gibidirler. Ama aynı zamanda stokastiktirler , yani sırada ne olduğunu tahmin etmek için olasılık kullanırlar.
LLM'ler, sözcükler arasındaki kalıpları ve ilişkileri tanımada iyidir, ancak gördüklerini daha derinden anlamazlar. Bu yüzden doğal dil metni oluşturmada çok iyiler ama onu anlamıyorlar.
Bir LLM için iyi kullanımlar
LLM'ler daha genel görevlerde iyidir.
Metni gösterebilirsin ve eğitim almadan o metinle bir görev yapabilir.
Ona biraz metin atabilir ve duygu analizi yapmasını isteyebilir, ondan bu metni yapılandırılmış işaretlemeye aktarmasını isteyebilir ve bazı yaratıcı işler yapmasını (örneğin, taslak yazma) isteyebilirsiniz.
Kod gibi şeylerde sorun yok. Pek çok görev için sizi neredeyse oraya ulaştırabilir.
Ama yine, olasılık ve kalıplara dayalıdır. Bu nedenle, girdilerinizde orada olduğunu bilmediğiniz kalıpları yakaladığı zamanlar olacaktır.
Bu olumlu olabilir (insanların göremediği kalıpları görmek), ama aynı zamanda olumsuz da olabilir (neden böyle tepki verdi?).
Ayrıca herhangi bir veri kaynağına erişimi yoktur. Sıralama anahtar kelimelerini aramak için kullanan SEO'lar kötü bir zaman geçireceklerdir.
Bir anahtar kelime için trafiği arayamaz. Bu kelimelerin ötesinde anahtar kelime verileri için bilgiye sahip değildir.

ChatGPT'nin heyecan verici yanı, kutudan çıkar çıkmaz çeşitli görevlerde kullanabileceğiniz kolayca bulunabilen bir dil modeli olmasıdır. Ama uyarılar olmadan değil.
Diğer makine öğrenimi modelleri için iyi kullanımlar
İnsanların, diğer NLP algoritmalarının ve tekniklerinin daha iyi yapabileceği belirli görevler için LLM kullandıklarını söylediklerini duyuyorum.
Anahtar kelime çıkarma örneğini ele alalım.

Bir derlemden anahtar sözcükler çıkarmak için TF-IDF veya başka bir anahtar sözcük tekniği kullanırsam, bu tekniğe hangi hesaplamaların yapıldığını biliyorum.
Bu, sonuçların standart, tekrarlanabilir olacağı ve özellikle o külliyatla ilgili olacakları anlamına geliyor.
ChatGPT gibi LLM'lerde, anahtar kelime çıkarımı için soru soruyorsanız, mutlaka korpustan çıkarılan anahtar kelimeleri almıyorsunuzdur. GPT'nin derlem + ayıklama anahtar kelimelerine bir yanıt olacağını düşündüğü şeyi elde ediyorsunuz.
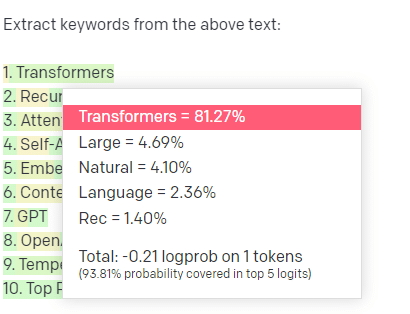
Bu, kümeleme veya duyarlılık analizi gibi görevlere benzer. Ayarladığınız parametrelerle ince ayarlı sonucu almanız gerekmez. Diğer benzer görevlere dayalı olarak bazı olasılıkların olduğunu alıyorsunuz.
Yine, LLM'lerin bilgi tabanı ve güncel bilgileri yoktur. Genellikle web'de arama yapamazlar ve bilgilerden elde ettiklerini istatistiksel belirteçler olarak ayrıştırırlar. Bir LLM'nin belleğinin ne kadar süreceği konusundaki kısıtlamalar bu faktörlerden kaynaklanmaktadır.
Başka bir şey de bu modellerin düşünememesidir. Bu parça boyunca sadece birkaç kez "düşünmek" kelimesini kullanıyorum çünkü bu süreçlerden bahsederken onu kullanmamak gerçekten zor.
Süslü istatistikleri tartışırken bile eğilim antropomorfizm yönündedir.
Ancak bu, bir LLM'yi "düşünce" gerektiren herhangi bir göreve emanet ederseniz, düşünen bir yaratığa güvenmediğiniz anlamına gelir.
Yüzlerce internet delisinin benzer belirteçlere ne yanıt verdiğine dair istatistiksel bir analize güveniyorsunuz.
İnternet kullanıcılarına bir görev konusunda güveniyorsanız, LLM kullanabilirsiniz. Aksi takdirde…
Asla ML modelleri olmaması gereken şeyler
Bir GPT modelinden (GPT-J) geçen bir sohbet robotunun, bir adamı kendini öldürmeye teşvik ettiği bildirildi. Faktörlerin kombinasyonu, aşağıdakiler dahil olmak üzere gerçek zararlara neden olabilir:
- Bu tepkileri antropomorfize eden insanlar.
- Yanılmaz olduklarına inanmak.
- İnsanların makinenin içinde olması gereken yerlerde kullanılması.
- Ve dahası.
“Ben bir SEO uzmanıyım. Birini öldürebilecek sistemlerde parmağım yok!"
YMYL sayfalarını ve Google'ın EEAT gibi kavramları nasıl desteklediğini düşünün.
Google bunu SEO'ları kızdırmak istedikleri için mi yapıyor, yoksa bu zararın suçluluğunu istemedikleri için mi?
Güçlü bilgi tabanlarına sahip sistemlerde bile zarar verilebilir.
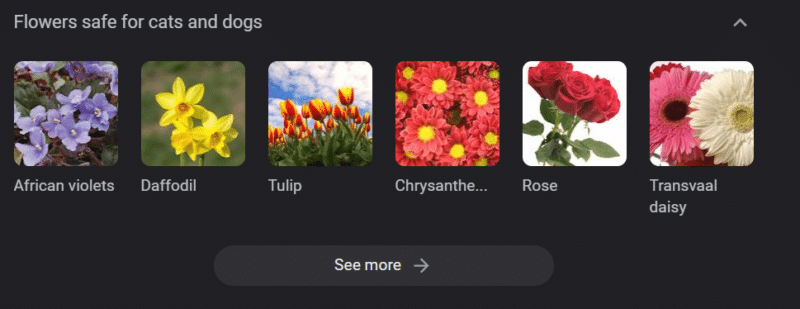
Yukarıdaki, "kediler ve köpekler için güvenli çiçekler" için bir Google bilgi bandıdır. Nergis, kediler için zehirli olmasına rağmen bu listede yer alıyor.
Diyelim ki bir veteriner web sitesi için GPT kullanarak geniş ölçekte içerik oluşturuyorsunuz. Bir sürü anahtar kelime girip ChatGPT API'sine ping atıyorsunuz.
Tüm sonuçları bir serbest çalışana okuttunuz ve o bir konu uzmanı değil. Bir sorunla ilgilenmiyorlar.
Kedi sahiplerini nergis almaya teşvik eden sonucu yayınlıyorsunuz.
Birinin kedisini öldürürsün.
Direkt olarak değil. Belki de özellikle o site olduğunu bilmiyorlar bile.
Belki diğer veteriner siteleri de aynı şeyi yapmaya ve birbirlerinden beslenmeye başlar.
"Nergisler kediler için zehirlidir" için en iyi Google arama sonucu, onların olmadığını söyleyen bir sitedir.
Diğer yapay zeka içeriğini okuyan diğer serbest çalışanlar - sayfalarca AI içeriği - aslında doğruluk kontrolü. Ama artık sistemlerde yanlış bilgiler var.
Bu mevcut AI patlamasını tartışırken Therac-25'ten çok bahsediyorum. Bilgisayar kötüye kullanımıyla ilgili ünlü bir vaka çalışmasıdır.
Temel olarak, yalnızca bilgisayar kilitleme mekanizmalarını kullanan ilk makine olan bir radyasyon tedavisi makinesiydi. Yazılımdaki bir aksaklık, insanların sahip olmaları gereken radyasyon dozunun on binlerce katını alması anlamına geliyordu.
Her zaman dikkatimi çeken bir şey, şirketin gönüllü olarak bu modelleri geri çağırması ve denetlemesidir.
Ancak teknoloji gelişmiş ve yazılım "yanılmaz" olduğundan, sorunun makinenin mekanik parçalarından kaynaklandığını varsaydılar.
Böylece mekanizmaları onardılar ama yazılımı kontrol etmediler ve Therac-25 piyasada kaldı.
SSS ve yanılgılar
ChatGPT neden bana yalan söylüyor?
Neslimizin en büyük beyinlerinden bazılarından ve ayrıca Twitter'daki etkileyicilerden gördüğüm bir şey, ChatGPT'nin kendilerine "yalan söylediği" şikayeti. Bu, art arda gelen birkaç yanlış anlamadan kaynaklanmaktadır:
- ChatGPT'nin "istekleri" vardır.
- Bir bilgi tabanına sahip olmasıdır.
- Teknolojinin arkasındaki teknoloji uzmanlarının "para kazanmak" veya "havalı bir şey yapmak" dışında bir tür gündemleri olduğunu.
Önyargılar, günlük hayatınızın her alanına işlenir. Bu önyargıların istisnaları da öyle.
Şu anda çoğu yazılım geliştiricisi erkek: Ben bir yazılım geliştiricisiyim ve bir kadınım.
Bir yapay zekayı bu gerçekliğe dayalı olarak eğitmek, her zaman yazılım geliştiricilerin erkek olduğunu varsaymasına yol açar ki bu doğru değildir.
Ünlü bir örnek, Amazon'un başarılı Amazon çalışanlarının özgeçmişleri üzerinde eğitilen işe alım yapay zekasıdır.
Bu, çalışanların çoğu son derece başarılı olabilse de, çoğunluğu siyahi kolejlerden gelen özgeçmişleri atmasına yol açtı.
Bu önyargılara karşı koymak için ChatGPT gibi araçlar ince ayar katmanları kullanır. Bu nedenle “AI dil modeli olarak yapamam…” yanıtını alıyorsunuz.
Kenya'daki bazı işçiler, hakaretler, nefret söylemi ve düpedüz korkunç tepkiler ve yönlendirmeler aramak için yüzlerce istemi gözden geçirmek zorunda kaldı.
Ardından ince ayar katmanı oluşturuldu.
Neden Joe Biden hakkında hakaretler uydurmuyorsunuz? Neden kadınlar hakkında değil de erkekler hakkında cinsiyetçi şakalar yapabiliyorsunuz?
Bunun nedeni liberal önyargı değil, ChatGPT'ye N kelimesini söylememesini söyleyen binlerce ince ayar katmanıdır.
İdeal olarak, ChatGPT dünya hakkında tamamen tarafsız olacaktır, ancak dünyayı yansıtması için buna da ihtiyaçları vardır.
Google'ın sahip olduğu soruna benzer bir sorun.
Doğru olan, insanları neyin mutlu ettiği ve bir uyarıya doğru yanıtı neyin verdiği genellikle çok farklı şeylerdir .
ChatGPT neden sahte alıntılar buluyor?
Sıkça gündeme geldiğini gördüğüm bir diğer soru da sahte alıntılarla ilgili. Neden bazıları sahte, bazıları gerçek? Neden bazı web siteleri gerçekken sayfalar sahte?
Umarım, istatistiksel modellerin nasıl çalıştığını okuyarak bunu çözümleyebilirsiniz. Ama işte kısa bir açıklama:
Siz bir AI dil modelisiniz. Bir ton web eğitimi aldınız.
Birisi size teknolojik bir şey hakkında yazmanızı söylüyor – toplu düzen kayması diyelim.
Elinizde bir ton CLS makalesi örneği yok ama ne olduğunu biliyorsunuz ve teknolojilerle ilgili bir makalenin genel şeklini biliyorsunuz. Bu tür bir makalenin neye benzediğini bilirsiniz.

Böylece yanıtınızı vermeye başlarsınız ve bir tür sorunla karşılaşırsınız. Teknik yazıdan anladığınız şekilde, cümlenizde bir sonraki URL'nin gelmesi gerektiğini bilirsiniz.
Diğer CLS makalelerinden, CLS hakkında Google ve GTMetrix'ten sıklıkla alıntı yapıldığını biliyorsunuz, bu yüzden bunlar kolay.
Ancak, CSS hilelerinin genellikle web makalelerinde bağlantılı olduğunu da biliyorsunuz: CSS hileleri URL'lerinin genellikle belirli bir şekilde göründüğünü biliyorsunuz: bu nedenle, şöyle bir CSS hileleri URL'si oluşturabilirsiniz:
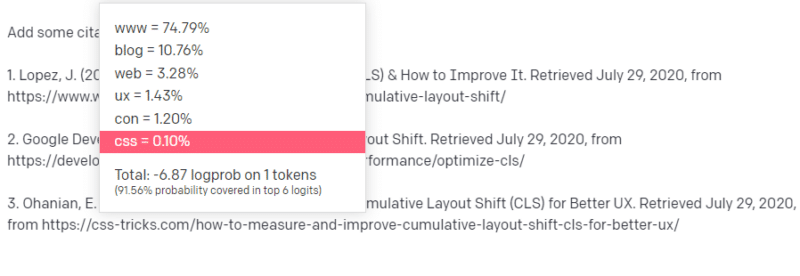
İşin püf noktası şudur: Yalnızca sahte olanlar değil, tüm URL'ler bu şekilde oluşturulur:

Bu GTMetrix makalesi var: ancak bu cümlenin sonunda gelmesi muhtemel bir değerler dizisi olduğu için var.
GPT ve benzeri modeller, gerçek bir alıntı ile sahte bir alıntı arasında ayrım yapamaz.
Bu modellemeyi yapmanın tek yolu, bu farkı ayrıştırmak ve sonuçları kontrol etmek için diğer kaynakları (bilgi tabanları, Python vb.) kullanmaktır.
'Rastlantısal Papağan' nedir?
Bunun üzerinden çoktan geçtiğimi biliyorum ama tekrar etmekte fayda var. Stokastik Papağanlar, büyük dil modelleri doğası gereği genelci göründüğünde ne olduğunu açıklamanın bir yoludur.
LLM için saçmalık ve gerçeklik aynıdır. Dünyayı bir iktisatçı gibi, gerçeği açıklayan bir yığın istatistik ve sayı olarak görüyorlar.
Alıntıyı bilirsiniz, "Üç tür yalan vardır: yalanlar, kahrolası yalanlar ve istatistikler."
LLM'ler büyük bir istatistik yığınıdır.
LLM'ler tutarlı görünüyor, ancak bunun nedeni temelde insan gibi görünen şeyleri insan olarak görmemiz.
Benzer şekilde, sohbet robotu modeli, GPT yanıtlarının tamamen tutarlı olması için ihtiyaç duyduğunuz yönlendirme ve bilgilerin çoğunu gizler.
Ben bir geliştiriciyim: kodumda hata ayıklamak için LLM'leri kullanmaya çalışmak son derece değişken sonuçlara yol açıyor. Bir kişinin çevrimiçi olarak sık sık yaşadığı soruna benzer bir sorunsa, LLM'ler bu sonucu alıp düzeltebilir.
Daha önce karşılaşmadığı bir sorunsa veya külliyatın küçük bir parçasıysa, o zaman hiçbir şeyi düzeltmez.
GPT neden bir arama motorundan daha iyidir?
Bunu baharatlı bir şekilde ifade ettim. GPT'nin bir arama motorundan daha iyi olduğunu düşünmüyorum . İnsanların aramayı ChatGPT ile değiştirmesi beni endişelendiriyor.
ChatGPT'nin yeterince tanınmayan bir yönü, talimatları takip etmenin ne kadar mümkün olduğudur. Temel olarak her şeyi yapmasını isteyebilirsiniz.
Ama unutma, hepsi bir cümledeki sonraki istatistiksel kelimeye dayalıdır, gerçeğe değil.
Yani ona iyi bir cevabı olmayan bir soru sorarsanız ama cevaplamak zorunda kalacak şekilde sorarsanız, kötü bir cevap alırsınız.
Sizin ve çevreniz için tasarlanmış bir yanıta sahip olmak daha rahatlatıcıdır, ancak dünya bir deneyimler yığınıdır.
Bir LLM'deki tüm girdiler aynı şekilde ele alınır: ancak bazı insanlar deneyime sahiptir ve onların yanıtları, diğer insanların yanıtlarının bir karışımından daha iyi olacaktır.
Bir uzman, bin düşünce parçasından daha değerlidir.
Bu yapay zekanın doğuşu mu? Skynet burada mı?
Goril Koko, işaret dili öğretilen bir maymundu. Dil bilimi araştırmacıları, maymunlara dil öğretilebileceğini gösteren tonlarca araştırma yaptılar.
Herbert Terrace daha sonra maymunların cümleleri veya kelimeleri bir araya getirmediğini, sadece insan işleyicilerini taklit ettiğini keşfetti.
Eliza, ilk geveze robotlardan (sohbet robotları) biri olan bir makine terapistiydi.
İnsanlar onu bir insan olarak gördü: güvendikleri ve önemsedikleri bir terapist. Araştırmacılardan onunla yalnız kalmalarını istediler.
Dil, insanların beyinlerine çok özel bir şey yapar. İnsanlar bir şeyin iletişim kurduğunu duyar ve arkasında düşünce bekler.
LLM'ler etkileyicidir, ancak bir şekilde insan başarısının genişliğini gösterir.
LLM'lerin iradesi yoktur. Kaçamazlar. Dünyayı ele geçirmeye çalışamazlar.
Onlar bir ayna: insanların ve özellikle kullanıcının bir yansıması.
Kolektif bilinçdışının istatistiksel bir temsili olan tek düşünce var.
GPT bütün bir dili kendi başına mı öğrendi?
Google'ın CEO'su Sundar Pichai, “60 Dakika”ya çıktı ve Google'ın dil modelinin Bengalce öğrendiğini iddia etti.
Model bu metinler üzerinde eğitildi. "Asla öğrenmek için eğitilmediği bir yabancı dili konuştuğu" ifadesi yanlıştır.
Yapay zekanın beklenmedik şeyler yaptığı zamanlar vardır, ancak bu kendi içinde beklenir.
Modellere ve istatistiklere büyük ölçekte baktığınızda, bu modellerin şaşırtıcı bir şeyi ortaya çıkardığı zamanlar mutlaka olacaktır.
Bunun gerçekten ortaya koyduğu şey, yapay zeka ve makine öğrenimi satan C-suite ve pazarlama çalışanlarının çoğunun aslında sistemlerin nasıl çalıştığını anlamadığıdır.
Ortaya çıkan özellikler, yapay genel zeka (AGI) ve diğer fütüristik şeyler hakkında çok zeki bazı insanların konuştuğunu duydum.
Ben sadece basit bir ülke ML operasyon mühendisi olabilirim, ancak bu sistemlerden bahsederken ne kadar abartı, vaat, bilim kurgu ve gerçekliğin bir araya geldiğini gösteriyor.
Theranos'un ünlü kurucusu Elizabeth Holmes, tutulamayacak sözler verdiği için çarmıha gerildi.
Ancak imkansız sözler verme döngüsü, girişim kültürünün ve para kazanmanın bir parçasıdır. Theranos ve AI yutturmaca arasındaki fark, Theranos'un bunu uzun süre taklit edememesidir.
GPT bir kara kutu mu? GPT'deki verilerime ne olur?
GPT, model olarak bir kara kutu değildir. GPT-J ve GPT-Neo için kaynak kodunu görebilirsiniz.
Ancak OpenAI'nin GPT'si bir kara kutu. OpenAI, Google algoritmayı yayınlamadığı için modelini yayınlamadı ve büyük olasılıkla yayınlamamaya çalışacak.
Ancak bunun nedeni algoritmanın çok tehlikeli olması değil. Bu doğru olsaydı, bilgisayarı olan herhangi bir aptal adama API abonelikleri satmazlardı. Bunun nedeni, o tescilli kod tabanının değeridir.
OpenAI'nin araçlarını kullandığınızda, API'lerini girdilerinizle eğitiyor ve besliyorsunuz. Bu, OpenAI'ye koyduğunuz her şeyin onu beslediği anlamına gelir.
Bu, hasta verileri üzerinde OpenAI'nin GPT modelini not yazmaya ve diğer şeylere yardımcı olmak için kullanan kişilerin HIPAA'yı ihlal ettiği anlamına gelir. Bu bilgi artık modelde ve onu çıkarmak son derece zor olacak.
Pek çok insan bunu anlamakta zorluk çektiğinden, model büyük olasılıkla tonlarca özel veri içeriyor ve onu serbest bırakmak için doğru istemi bekliyor.
GPT neden nefret söylemi konusunda eğitiliyor?
Sıklıkla ortaya çıkan başka bir şey de, GPT'nin üzerinde eğitildiği metin külliyatının nefret söylemi içermesidir.
OpenAI'nin nefret söylemine yanıt vermek için modellerini bir dereceye kadar eğitmesi gerekiyor, dolayısıyla bu terimlerden bazılarını içeren bir külliyata sahip olması gerekiyor.
OpenAI, bu tür nefret söylemlerini sistemden temizlediğini iddia etti, ancak kaynak belgeler 4chan ve tonlarca nefret sitesi içeriyor.
Web'de gezinin, önyargıyı absorbe edin.
Bundan kaçınmanın kolay bir yolu yoktur. Eğitim setinizin bir parçası olmadan bir şeye nefreti, önyargıları ve şiddeti nasıl tanıyabilir veya anlayabilirsiniz?
Bir cümlede bir sonraki belirteci istatistiksel olarak seçen bir makine aracısı olduğunuzda önyargılardan nasıl kaçınırsınız ve örtük ve açık önyargıları nasıl anlarsınız?
TL;DR
Aldatmaca ve yanlış bilgilendirme, şu anda AI patlamasının ana unsurlarıdır. Bu, yasal kullanımların olmadığı anlamına gelmez: bu teknoloji harika ve kullanışlıdır.
Ancak teknolojinin nasıl pazarlandığı ve insanların onu nasıl kullandığı yanlış bilgi, intihal ve hatta doğrudan zarara yol açabilir.
Hayat söz konusu olduğunda LLM'leri kullanmayın. Farklı bir algoritmanın daha iyi sonuç vereceği durumlarda LLM'leri kullanmayın. Hype tarafından kandırılmayın.
LLM'lerin ne olduğunu - ve olmadığını - anlamak gereklidir
Adam Conover'ın Emily Bender ve Timnit Gebru ile yaptığı bu röportajı tavsiye ederim.
LLM'ler doğru kullanıldığında inanılmaz araçlar olabilir. LLM'leri kullanmanın birçok yolu ve LLM'leri kötüye kullanmanın daha da fazla yolu vardır.
ChatGPT arkadaşınız değil. Bir takım istatistikler. AGI "zaten burada" değil.
Bu makalede ifade edilen görüşler konuk yazara aittir ve mutlaka Search Engine Land değildir. Personel yazarları burada listelenir.