
Spark vs Hadoop: Hangi Büyük Veri Çerçevesi İşinizi Yükseltecek?
Yayınlanan: 2019-09-24“Veri, Dijital Ekonominin yakıtıdır”
Tüketicilerini ve pazarını daha iyi anlamak için veri yığınına güvenen modern işletmelerle birlikte, Büyük Veri gibi teknolojiler büyük bir ivme kazanıyor.
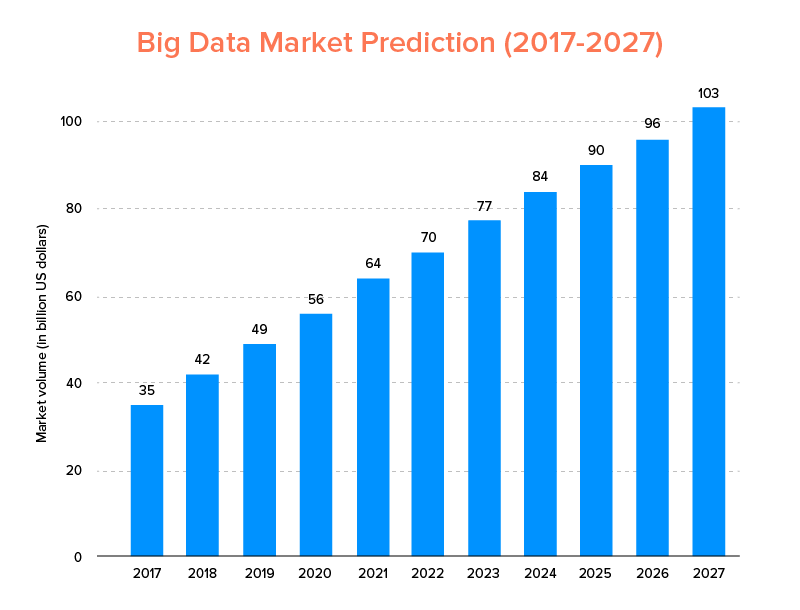
Tıpkı AI'nın 2020 için en iyi teknoloji trendleri listesine girmediği gibi, Büyük Veri de katlanarak büyümenin keyfini çıkarmak ve daha yüksek müşteri sadakati sağlamak için hem yeni başlayanlar hem de Fortune 500 şirketleri tarafından benimsenmesi bekleniyor. Bunun açık bir göstergesi, Büyük Veri pazarının 2027 yılına kadar 103 milyar dolara ulaşacağının tahmin edilmesidir.
Şimdi, bu bir yandan herkes geleneksel veri analizi araçlarını - Blockchain ve AI'nın ilerlemesi için zemin hazırlayan Büyük Veri ile değiştirmek için oldukça motive olurken, aynı zamanda doğru Büyük veri aracını seçme konusunda kafaları karıştı. Büyük Veri dünyasının iki devi Apache Hadoop ve Spark arasında seçim yapma ikilemiyle karşı karşıyalar.
Bu düşünceyi göz önünde bulundurarak, bugün Apache Spark ve Hadoop hakkında bir makaleyi ele alacağız ve ihtiyaçlarınız için hangisinin doğru seçenek olduğunu belirlemenize yardımcı olacağız.
Ama önce Hadoop ve Spark'ın ne olduğuna dair kısa bir giriş yapalım.
Apache Hadoop, kullanıcıların basit programlama yapılarını kullanarak büyük verileri birden çok bilgisayar kümesinde depolamasına ve işlemesine olanak tanıyan açık kaynaklı, dağıtılmış ve Java tabanlı bir çerçevedir. Gelişmiş bir deneyim sunmak için birlikte çalışan çeşitli modüllerden oluşur: -
- Hadoop Ortak
- Hadoop Dağıtılmış Dosya Sistemi (HDFS)
- Hadoop İPLİK
- Hadoop HaritasıKüçült
Oysa Apache Spark, 'kullanımı kolay' ve daha hızlı hizmetler sunan, açık kaynaklı, dağıtılmış bir küme bilgi işlem büyük veri çerçevesidir.
İki büyük veri çerçevesi, sundukları fırsatlar nedeniyle çok sayıda büyük şirket tarafından desteklenmektedir.
Hadoop Büyük Veri Çerçevesinin Avantajları
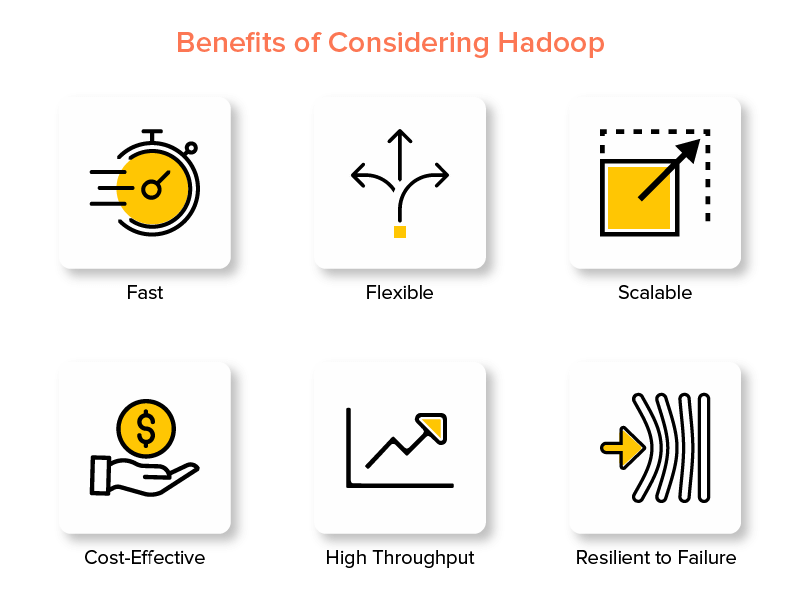
1. Hızlı
Hadoop'u büyük veri dünyasında popüler yapan özelliklerinden biri de hızlı olmasıdır.
Depolama yöntemi, verileri öncelikle bir kümede bulunan her yerde "eşleyen" dağıtılmış bir dosya sistemine dayanır. Ayrıca, veri işleme için kullanılan veriler ve araçlar genellikle aynı sunucuda bulunur ve bu da veri işlemeyi sorunsuz ve daha hızlı bir görev haline getirir.
Aslında, Hadoop'un terabaytlarca yapılandırılmamış veriyi sadece birkaç dakika içinde, petabaytları ise saatler içinde işleyebildiği bulundu.
2. Esnek
Hadoop, geleneksel veri işleme araçlarının aksine, üst düzey esneklik sunar.
İşletmelerin farklı kaynaklardan (sosyal medya, e-postalar vb. gibi) veri toplamasına, farklı veri türleriyle (hem yapılandırılmış hem de yapılandırılmamış) çalışmasına ve çeşitli amaçlar için (günlük işleme, pazar kampanyası analizi, vb.) dolandırıcılık tespiti vb.)
3. Ölçeklenebilir
Hadoop'un bir başka avantajı da yüksek düzeyde ölçeklenebilir olmasıdır. Platform, geleneksel ilişkisel veritabanı sistemlerinden (RDBMS) farklı olarak, işletmelerin paralel olarak çalışan yüzlerce sunucudan büyük veri kümelerini depolamasına ve dağıtmasına olanak tanır.
4. Uygun Maliyetli
Apache Hadoop, diğer büyük veri analiz araçlarıyla karşılaştırıldığında çok daha ucuzdur. Bunun nedeni, herhangi bir özel makine gerektirmemesidir; bir grup emtia donanımı üzerinde çalışır. Ayrıca, uzun vadede daha fazla düğüm eklemek daha kolaydır.
Yani, bir vaka, önceden planlama gereksinimlerinin herhangi bir kesinti süresinden muzdarip olmadan düğümleri kolayca artırır.
5. Yüksek Verim
Hadoop çerçevesi durumunda, veriler, küçük bir işin paralel olarak birden çok veri parçasına bölüneceği şekilde dağıtılmış bir şekilde depolanır. Bu, işletmelerin daha kısa sürede daha fazla iş yapmasını kolaylaştırır ve bu da sonuçta daha yüksek verimle sonuçlanır.
6. Başarısızlığa Karşı Dayanıklı
Son olarak Hadoop, hatanın sonuçlarını azaltmaya yardımcı olan yüksek hata toleransı seçenekleri sunar. Herhangi bir düğüm çöktüğünde verileri kurtarmayı mümkün kılan her bloğun bir kopyasını depolar.
Hadoop Çerçevesinin Dezavantajları
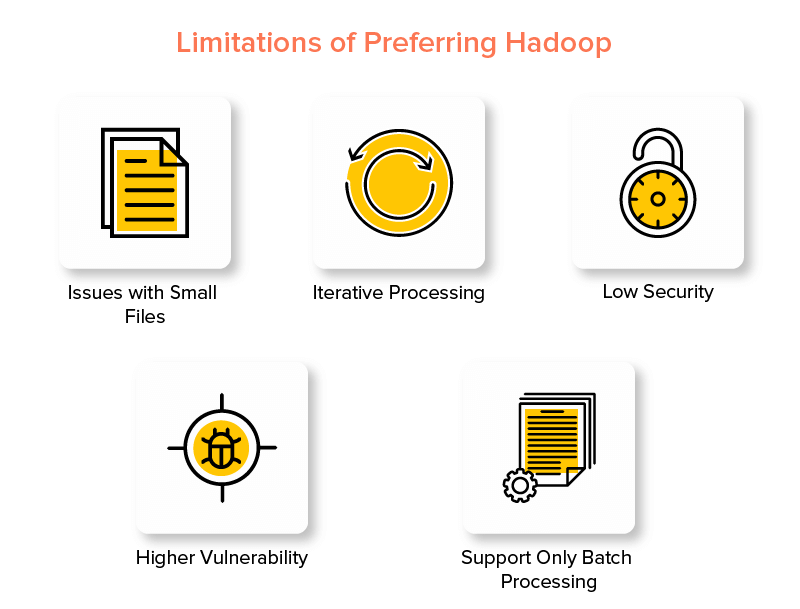
1. Küçük Dosyalarla İlgili Sorunlar
Hadoop'u büyük veri analitiği için değerlendirmenin en büyük dezavantajı, küçük dosyaların rastgele okunmasını verimli ve etkili bir şekilde destekleme potansiyelinden yoksun olmasıdır.
Bunun nedeni, küçük bir dosyanın HDFS blok boyutundan nispeten daha düşük bellek boyutuna sahip olmasıdır. Böyle bir senaryoda, çok sayıda küçük dosya depolanırsa, HDFS'nin ad alanını depolayan NameNode'un aşırı yüklenme olasılığı daha yüksektir ve bu pratik olarak iyi bir fikir değildir.
2. Yinelemeli İşleme
Büyük veri Hadoop çerçevesindeki veri akışı bir zincir şeklindedir, öyle ki birinin çıktısı diğer aşamanın girdisi olur. Oysa yinelemeli işlemedeki veri akışı doğada döngüseldir.
Bu nedenle Hadoop, Makine Öğrenimi veya Yinelemeli işleme tabanlı çözümler için uygun olmayan bir seçimdir.
3. Düşük Güvenlik
Hadoop çerçevesine geçmenin bir başka dezavantajı, daha düşük güvenlik özellikleri sunmasıdır.
Örneğin çerçeve, varsayılan olarak devre dışı bırakılmış güvenlik modeline sahiptir. Bu büyük veri aracını kullanan biri onu nasıl etkinleştireceğini bilmiyorsa, verilerinin çalınma/kötüye kullanılma riski daha yüksek olabilir. Ayrıca Hadoop, veri ihlali tehdidi olasılığını artıran depolama ve ağ düzeylerinde şifreleme işlevselliği sağlamaz.
4. Daha Yüksek Güvenlik Açığı
Hadoop çerçevesi, en popüler ancak en çok kullanılan programlama dili olan Java ile yazılmıştır. Bu, siber suçluların Hadoop tabanlı çözümlere kolayca erişmesini ve hassas verileri kötüye kullanmasını kolaylaştırır.
5. Yalnızca Toplu İşleme Desteği
Diğer çeşitli büyük veri çerçevelerinin aksine, Hadoop akışlı verileri işlemez. Yalnızca toplu işlemeyi destekler ve bunun nedeni MapReduce'un Hadoop Kümesinin belleğinden maksimum düzeyde yararlanamamasıdır.
Bunların hepsi Hadoop, özellikleri ve dezavantajları ile ilgili olsa da, ikisi arasındaki farkı anlamada bir kolaylık bulmak için Spark'ın artılarına ve eksilerine bir göz atalım.
Apache Spark Çerçevesinin Faydaları
1. Doğada Dinamik
Apache Spark yaklaşık 80 üst düzey operatör sunduğundan, verileri dinamik olarak işlemek için kullanılabilir. Paralel uygulamaları geliştirmek ve yönetmek için doğru büyük veri aracı olarak kabul edilebilir.
2. Güçlü
Düşük gecikmeli bellek içi veri işleme yeteneği ve makine öğrenimi ve grafik analizi algoritmaları için çeşitli yerleşik kitaplıkların kullanılabilirliği nedeniyle, çeşitli analitik zorlukların üstesinden gelebilir. Bu, onu pazarda birlikte gitmek için güçlü bir büyük veri seçeneği yapar.
3. Gelişmiş Analitik
Spark'ın diğer bir ayırt edici özelliği, yalnızca 'MAP' ve 'azaltmayı' teşvik etmekle kalmayıp, aynı zamanda Makine Öğrenimi (ML), SQL sorgularını, Grafik algoritmalarını ve Veri Akışını da desteklemesidir. Bu, onu gelişmiş analitiklerin keyfini çıkarmak için uygun hale getirir.
4. Yeniden Kullanılabilirlik
Hadoop'tan farklı olarak, Spark kodu toplu işleme için yeniden kullanılabilir, akış durumunda geçici sorgular çalıştırabilir, akışı geçmiş verilere göre birleştirebilir ve daha fazlası için kullanılabilir.
5. Gerçek Zamanlı Akış İşleme
Apache Spark ile çalışmanın bir diğer avantajı, verilerin gerçek zamanlı olarak işlenmesini ve işlenmesini sağlamasıdır.
6. Çok Dilli Destek
Son olarak, bu büyük veri analiz aracı, Java, Python ve Scala dahil olmak üzere kodlama için birden çok dili destekler.
Spark Büyük Veri Aracının Sınırlamaları

1. Dosya Yönetim Süreci Yok
Apache Spark'ı kullanmanın en büyük dezavantajı, kendi dosya yönetim sistemine sahip olmamasıdır. Bu gereksinimi karşılamak için Hadoop gibi diğer platformlara güvenir.
2. Birkaç Algoritma
Apache Spark, Tanimoto mesafesi gibi algoritmaların kullanılabilirliği göz önüne alındığında diğer büyük veri çerçevelerinin gerisinde kalıyor.
3. Küçük Dosyalar Sorunu
Spark kullanmanın diğer bir dezavantajı, küçük dosyaları verimli bir şekilde işlememesidir.
Bunun nedeni, çok sayıda küçük dosya üzerinden sınırlı sayıda büyük dosyayı yönetmeyi daha kolay bulan Hadoop Dağıtılmış Dosya Sistemi (HDFS) ile çalışmasıdır.
4. Otomatik Optimizasyon Süreci Yok
Diğer çeşitli büyük veri ve bulut tabanlı platformlardan farklı olarak Spark, herhangi bir otomatik kod optimizasyon sürecine sahip değildir. Kodu yalnızca manuel olarak optimize etmek gerekir.
5. Çok Kullanıcılı Ortam İçin Uygun Değil
Apache Spark aynı anda birden fazla kullanıcıyı idare edemediğinden çok kullanıcılı ortamda verimli çalışmaz. Yine sınırlamalarına eklenen bir şey.
Kapsanan her iki büyük veri çerçevesinin temelleri ile, Spark ve Hadoop arasındaki farklara aşina olmayı umuyorsunuz.
Öyleyse daha fazla beklemeyelim ve 'Spark vs Hadoop' savaşına hangisinin öncülük ettiğini görmek için karşılaştırmalarına gidelim.
Spark vs Hadoop: İki Büyük Veri Aracı Birbirine Karşı Nasıl Yığınlanıyor?
[tablo kimliği=38 /]
1. Mimarlık
Spark ve Hadoop mimarisi söz konusu olduğunda, ikincisi, her ikisi de dağıtılmış bilgi işlem ortamında çalıştığında bile liderdir.
Bunun nedeni, Hadoop mimarisinin - Spark'ın aksine - iki ana öğeye sahip olmasıdır - HDFS (Hadoop Dağıtılmış Dosya Sistemi) ve YARN (Yine Başka Bir Kaynak Müzakerecisi). Burada HDFS, çeşitli düğümler arasında büyük veri depolamayı işlerken YARN, kaynak tahsisi ve iş planlama mekanizmaları aracılığıyla görevlerin işlenmesiyle ilgilenir. Bu bileşenler daha sonra, Hata toleransı gibi hizmetlerle daha iyi çözümler sunmak için daha fazla bileşene bölünür.
2. Kullanım Kolaylığı
Apache Spark, geliştiricilerin geliştirme ortamlarında Scala, Python, R, Java ve Spark SQL için bunun gibi çeşitli kullanıcı dostu API'ler sunmalarını sağlar. Ayrıca, hem kullanıcıları hem de geliştiricileri destekleyen etkileşimli bir modla birlikte gelir. Bu, kullanımı kolay ve düşük öğrenme eğrisi ile yapar.
Oysa Hadoop hakkında konuşurken, kullanıcıları desteklemek için eklentiler sunar, ancak etkileşimli bir mod değil. Bu, Spark'ın bu 'büyük veri' savaşında Hadoop'u kazanmasını sağlar.
3. Hata Toleransı ve Güvenlik
Hem Apache Spark hem de Hadoop MapReduce, hataya dayanıklılık olanağı sunarken, ikincisi savaşı kazanır.
Bunun nedeni, Spark ortamında işlemin ortasında bir işlemin çökmesi durumunda sıfırdan başlamak zorunda olmasıdır. Ancak, Hadoop'a gelince, çökme noktasından devam edebilirler.
4. Performans
Spark ve MapReduce performansının değerlendirilmesi söz konusu olduğunda, birincisi ikincisine karşı kazanır.
Spark çerçevesi, diskte 10 kat ve bellekte 100 kat daha hızlı çalışabilir. Bu, 100 TB veriyi Hadoop MapReduce'dan 3 kat daha hızlı yönetmeyi mümkün kılar.
5. Veri İşleme
Apache Spark ve Hadoop karşılaştırması sırasında dikkate alınması gereken bir diğer faktör de veri işlemedir.
Apache Hadoop yalnızca toplu işleme için bir fırsat sunarken, diğer büyük veri çerçevesi etkileşimli, yinelemeli, akış, grafik ve toplu işleme ile çalışmayı sağlar. Daha iyi veri işleme hizmetlerinden yararlanmak için Spark'ın daha iyi bir seçenek olduğunu kanıtlayan bir şey.
6. Uyumluluk
Spark ve Hadoop MapReduce'un uyumluluğu biraz aynıdır.
Bazen her iki büyük veri çerçevesi bağımsız uygulamalar olarak hareket etse de birlikte de çalışabilirler. Spark, Hadoop YARN üzerinde verimli bir şekilde çalışabilirken Hadoop, Sqoop ve Flume ile kolayca entegre olabilir. Bu nedenle her ikisi de birbirinin veri kaynaklarını ve dosya formatlarını destekler.
7. Güvenlik
Spark ortamı, web kullanıcı arabirimlerini korumak için olay günlüğü ve javax sunucu uygulaması filtrelerinin kullanımı gibi farklı güvenlik özellikleriyle yüklenir. Ayrıca, paylaşılan sır aracılığıyla kimlik doğrulamayı teşvik eder ve YARN ve HDFS ile entegre edildiğinde HDFS dosya izinlerinin, modlar arası şifrelemenin ve Kerberos'un potansiyelinden yararlanabilir.
Oysa Hadoop, Kerberos kimlik doğrulamasını, üçüncü taraf kimlik doğrulamasını, geleneksel dosya izinlerini ve erişim kontrol listelerini ve daha fazlasını destekler ve bu da sonunda daha iyi güvenlik sonuçları sunar.
Bu nedenle, Güvenlik açısından Spark ve Hadoop karşılaştırması düşünüldüğünde, ikincisi önde gelir.
8. Maliyet-Etkinlik
Hadoop ve Spark'ı karşılaştırırken, birincisi diskte daha fazla belleğe ihtiyaç duyarken ikincisi daha fazla RAM gerektirir. Ayrıca Spark, Apache Hadoop'a kıyasla oldukça yeni olduğundan, Spark ile çalışan geliştiriciler daha nadirdir.
Bu, Spark ile çalışmayı pahalı bir iş haline getirir. Yani Hadoop, Spark maliyetine karşı Hadoop'a odaklanıldığında uygun maliyetli çözümler sunar.
9. Pazar Kapsamı
Hem Apache Spark hem de Hadoop büyük şirketler tarafından desteklenir ve farklı amaçlar için kullanılırken, Hadoop pazar kapsamı açısından liderdir.
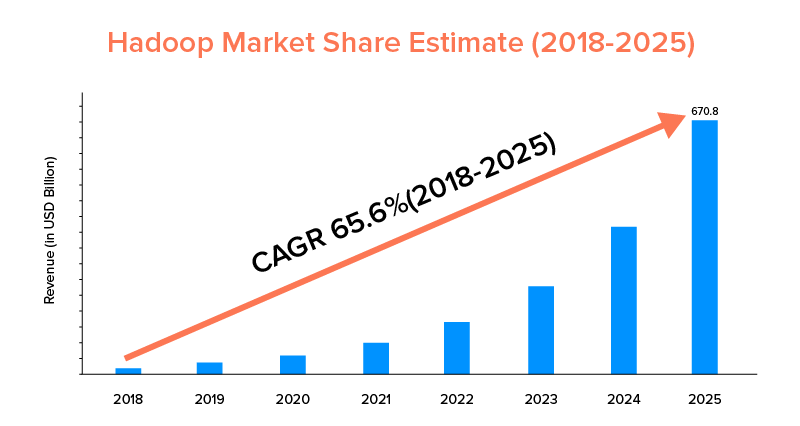
Pazar istatistiklerine göre, Apache Hadoop pazarının 2018-2025 döneminde yalnızca %33.9'luk bir CAGR'ye sahip Spark ile karşılaştırıldığında %65,6'lık bir CAGR ile büyümesi bekleniyor.
Bu faktörler, işletmeniz için doğru büyük veri aracını belirlemenize yardımcı olurken, bunların kullanım durumları hakkında bilgi sahibi olmak karlı olacaktır. Öyleyse, burayı kapatalım.
Apache Spark Framework Kullanım Örnekleri
Bu büyük veri aracı, aşağıdakileri yapmak istediklerinde işletmeler tarafından benimsenir:
- Verileri gerçek zamanlı olarak aktarın ve analiz edin.
- Makine Öğreniminin gücünün tadını çıkarın.
- Etkileşimli analitikle çalışın.
- İş modellerine Fog and Edge Computing'i tanıtın.
Apache Hadoop Çerçevesi Örneklerini Kullanın
Hadoop, aşağıdakileri yapmak istediklerinde yeni başlayanlar ve İşletmeler tarafından tercih edilir:-
- Arşiv verilerini analiz edin.
- Daha iyi finansal ticaret ve tahmin seçeneklerinin keyfini çıkarın.
- Emtia donanımından oluşan işlemleri yürütün.
- Doğrusal veri işlemeyi düşünün.
Bununla, işinizle ilgili olarak 'Spark vs Hadoop' savaşının kazananının hangisi olduğuna karar verdiğinizi umuyoruz. Değilse, tüm şüpheleri gidermek ve daha yüksek başarı oranı ile örnek hizmetler almak için Büyük Veri Uzmanlarımızla bağlantı kurmaktan çekinmeyin.
SIKÇA SORULAN SORULAR
1. Hangi Büyük Veri Çerçevesini Seçmelisiniz?
Seçim tamamen iş ihtiyaçlarınıza bağlıdır. Performansa, veri uyumluluğuna ve kullanım kolaylığına odaklanıyorsanız Spark, Hadoop'tan daha iyidir. Oysa Hadoop büyük veri çerçevesi, mimariye, güvenliğe ve maliyet etkinliğine odaklandığınızda daha iyidir.
2. Hadoop ve Spark Arasındaki Fark Nedir?
Spark ve Hadoop arasında çeşitli farklılıklar vardır. Örneğin:-
- Spark, Hadoop MapReduce'un 100 katı faktördür.
- Hadoop toplu işleme için kullanılırken, Spark toplu, grafik, makine öğrenimi ve yinelemeli işleme içindir.
- Spark, Hadoop büyük veri çerçevesinden daha kompakt ve daha kolaydır.
- Spark'ın aksine Hadoop, verilerin önbelleğe alınmasını desteklemez.
3. Spark, Hadoop'tan Daha İyi mi?
Ana odak noktanız hız ve güvenlik olduğunda Spark, Hadoop'tan daha iyidir. Ancak diğer durumlarda, bu büyük veri analizi aracı Apache Hadoop'un gerisinde kalıyor.
4. Spark Neden Hadoop'tan Daha Hızlı?
Spark, diske daha düşük okuma/yazma döngüsü sayısı ve bellekte ara verileri depolaması nedeniyle Hadoop'tan daha hızlıdır.
5. Apache Spark Ne İçin Kullanılır?
Apache Spark, istendiğinde veri analizi için kullanılır.
- Verileri gerçek zamanlı olarak analiz edin.
- İş modelinize ML ve Sis Bilişimi ekleyin.
- Etkileşimli Analitik ile çalışın.