
TW-BERT: Uçtan uca sorgu terimi ağırlığı ve Google Arama'nın geleceği
Yayınlanan: 2023-09-14Seth Godin'in 2005'te yazdığı gibi arama zordur.
Demek istediğim, SEO'nun zor olduğunu düşünürsek (ve öyle), aşağıdakilerin olduğu bir dünyada bir arama motoru oluşturmaya çalıştığınızı hayal edin:
- Kullanıcılar önemli ölçüde farklılık gösterir ve zaman içinde tercihlerini değiştirirler.
- Aramaya eriştikleri teknoloji her geçen gün gelişiyor.
- Rakipler sürekli topuklarınızı ısırıyor.
Bunun da ötesinde, ziyaretçileriniz için en iyi optimizasyonun nasıl yapılacağına dair içgörüler elde etmek için algoritmanızı kandırmaya çalışan sinir bozucu SEO'larla da uğraşıyorsunuz.
Bu işi çok daha zorlaştıracak.
Şimdi ilerlemek için güvenmeniz gereken ana teknolojilerin kendi sınırlamalarıyla ve belki de daha kötüsü devasa maliyetlerle gelip gelmediğini hayal edin.
Yakın zamanda yayınlanan "Uçtan Uca Sorgu Terimi Ağırlıklandırma" başlıklı makalenin yazarlarından biriyseniz, bunu parlamak için bir fırsat olarak görüyorsunuz.
Uçtan uca sorgu terimi ağırlığı nedir?
Uçtan uca sorgu terimi ağırlıklandırma, bir sorgudaki her bir terimin ağırlığının, manuel olarak programlanan veya geleneksel terim ağırlıklandırma şemalarına veya diğer bağımsız modellere dayanmaksızın genel modelin bir parçası olarak belirlendiği bir yöntemi ifade eder.
Bu neye benziyor?
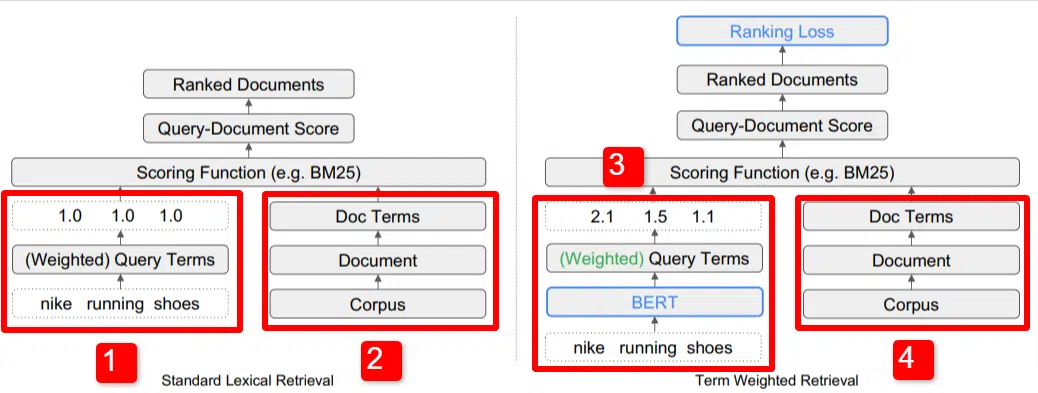
Burada, makalede özetlenen modelin temel farklılaştırıcılarından birinin resmini görüyoruz (özellikle Şekil 1).
Standart modelin (2) sağ tarafında, önerilen modelde (4) yaptığımızın aynısını görüyoruz; bu, belgelere giden, terimlere giden derlem (dizindeki belgelerin tamamı seti).
Bu, sistemdeki gerçek hiyerarşiyi gösterir, ancak bunu tersten, yukarıdan aşağıya düşünebilirsiniz. Şartlarımız var. Bu terimleri içeren belgeleri arıyoruz. Bu belgeler bildiğimiz tüm belgelerin külliyatında yer alıyor.
Standart Bilgi Erişimi (IR) mimarisinde sol altta (1) BERT katmanının olmadığını fark edeceksiniz. Resimde kullanılan sorgu (nike koşu ayakkabısı) sisteme girilir ve modelden bağımsız olarak ağırlıklar hesaplanıp sisteme iletilir.
Buradaki çizimde ağırlıklar sorgudaki üç kelime arasında eşit olarak geçmektedir. Ancak bu şekilde olmak zorunda değildir. Bu sadece varsayılan ve iyi bir örnektir.
Anlaşılması gereken önemli olan ağırlıkların model dışından atanıp sorgu ile girilmesidir. Bunun neden önemli olduğunu birazdan ele alacağız.
Sağ taraftaki terim ağırlığı versiyonuna bakarsak, "nike koşu ayakkabıları" sorgusunun, ayakkabının ağırlıklarını atamak için kullanılan BERT'e (Term Ağırlıklandırma BERT veya TW-BERT) girdiğini görürsünüz. bu sorguya en iyi şekilde uygulanır.
Oradan her ikisi için de benzer bir yol izleniyor, bir puanlama fonksiyonu uygulanıyor ve belgeler sıralanıyor. Ancak yeni modelde önemli bir son adım daha var; asıl mesele bu, sıralama kaybı hesaplaması.
Yukarıda bahsettiğim bu hesaplama, model içerisinde belirlenen ağırlıkların çok önemli olmasını sağlıyor. Bunu en iyi şekilde anlamak için, burada neler olup bittiğini gerçekten anlamak için önemli olan kayıp fonksiyonlarını tartışmak için kısa bir kenara çekilelim.
Kayıp fonksiyonu nedir?
Makine öğreniminde kayıp fonksiyonu, temel olarak bir sistemin, söz konusu sistemin mümkün olduğunca sıfır kayba yaklaşmayı öğrenmeye çalışmasıyla ne kadar hatalı olduğunun hesaplanmasıdır.
Örneğin ev fiyatlarını belirlemek için tasarlanmış bir modeli ele alalım. Eğer evinizin tüm istatistiklerini girdiyseniz ve değeri 250.000 $ ise, ancak eviniz 260.000 $'a satıldıysa aradaki fark zarar olarak kabul edilir (ki bu mutlak bir değerdir).
Çok sayıda örnek üzerinden modelin, en iyi sonucu alana kadar, verilen parametrelere farklı ağırlıklar atayarak kaybı en aza indirmesi öğretilir. Bu durumda bir parametre metrekare, yatak odaları, bahçe büyüklüğü, okula yakınlık gibi şeyleri içerebilir.
Şimdi sorgu terimi ağırlıklandırmasına dönelim
Yukarıdaki iki örneğe baktığımızda odaklanmamız gereken şey, sıralama kaybı hesaplamasının alt hunisindeki terimlerin ağırlığını sağlayacak bir BERT modelinin varlığıdır.
Başka bir deyişle, geleneksel modellerde terimlerin ağırlıklandırılması modelden bağımsız olarak yapılmaktaydı ve bu nedenle genel modelin performansına yanıt veremiyordu. Ağırlıklandırmalarda nasıl iyileştirme yapılacağını öğrenemedi.

Önerilen sistemde bu durum değişmektedir. Ağırlıklandırma modelin kendisinden yapılır ve bu nedenle model, performansını iyileştirmeye ve kayıp fonksiyonunu azaltmaya çalışırken, terim ağırlığını denklemin içine katmak için bu ekstra kadranlara sahiptir. Gerçekten.
ngram
TW-BERT kelimelerle değil, ngramlarla çalışacak şekilde tasarlanmıştır.
Makalenin yazarları, "nike koşu ayakkabıları" sorgusunda yalnızca kelimeleri ağırlıklandırırsanız nike, koşu ve ayakkabı kelimelerinden bahseden bir sayfanın iyi sıralamaya girebileceğini belirterek, neden kelimeler yerine ngram kullandıklarını çok iyi açıklıyorlar. "nike koşu çorapları" ve "kaykay ayakkabıları" tartışılıyorsa.
Geleneksel IR yöntemleri, sorgu istatistiklerini ve belge istatistiklerini kullanır ve bu veya benzer sorunların olduğu sayfaları ortaya çıkarabilir. Bu konuyu ele almaya yönelik geçmişteki girişimler, birlikte meydana gelme ve sıralamaya odaklanmıştı.
Bu modelde, ngramlar önceki örneğimizdeki kelimelerle aynı şekilde ağırlıklandırılır, dolayısıyla şöyle bir sonuç elde ederiz:
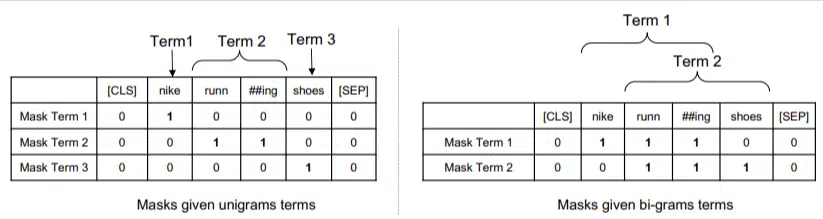
Solda sorgunun uni-gram (1 kelimelik ngram) ve sağda bi-gram (2 kelimelik ngram) olarak nasıl ağırlıklandırılacağını görüyoruz.
Sistem, ağırlıklandırmanın kendi içinde yerleşik olması nedeniyle, yalnızca frekans gibi istatistiklere güvenmek yerine, en iyi ngramları ve ayrıca her biri için uygun ağırlığı belirlemek üzere tüm permütasyonlar üzerinde eğitim alabilir.
Sıfır atış
Bu modelin önemli bir özelliği sıfır kısa görevlerdeki performansıdır. Yazarlar şunları test etti:
- MS MARCO veri kümesi – Belge ve pasaj sıralaması için Microsoft veri kümesi
- TREC-COVID veri kümesi – COVID makaleleri ve çalışmaları
- Robust04 – Haber makaleleri
- Ortak Çekirdek – Eğitim makaleleri ve blog gönderileri
Yalnızca az sayıda değerlendirme sorgusu vardı ve hiçbirini ince ayar için kullanmadılar; bu, modelin özellikle bu alanlardaki belgeleri sıralamak üzere eğitilmemesi nedeniyle bunu sıfır atışlı bir test haline getirdi. Sonuçlar şunlardı:
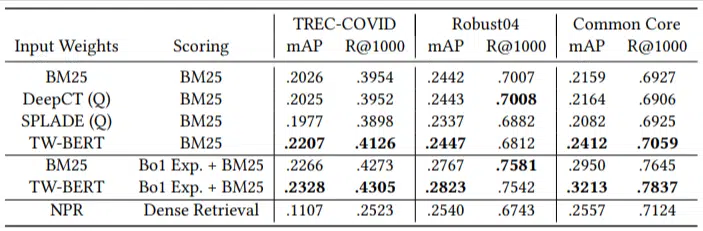
Çoğu görevde daha iyi performans gösterdi ve daha kısa sorgularda (1 ila 10 kelime) en iyi performansı gösterdi.
Ve tak-çalıştır özelliğindedir!
Tamam, bu aşırı basitleştirici olabilir, ancak yazarlar şunu yazıyor:
"TW-BERT'in arama motoru puanlayıcılarla uyumlu hale getirilmesi , onu mevcut üretim uygulamalarına entegre etmek için gereken değişiklikleri en aza indirirken , mevcut derin öğrenme tabanlı arama yöntemleri daha fazla altyapı optimizasyonu ve donanım gereksinimleri gerektirecektir. Öğrenilen ağırlıklar, standart sözcüksel alıcılar ve sorgu genişletme gibi diğer erişim teknikleri tarafından kolaylıkla kullanılabilir."
TW-BERT mevcut sisteme entegre olacak şekilde tasarlandığından entegrasyon diğer seçeneklere göre çok daha basit ve ucuzdur.
Bütün bunlar sizin için ne anlama geliyor?
Makine öğrenimi modelleriyle, SEO olarak sizin bu konuda neler yapabileceğinizi tahmin etmek zordur (Bard veya ChatGPT gibi görünür dağıtımlar dışında).
Bu modelin bir permütasyonu, iyileştirmeleri ve uygulama kolaylığı nedeniyle (ifadelerin doğru olduğu varsayılarak) şüphesiz uygulanacaktır.
Bununla birlikte, bu, Google'da sıralamaları ve sıfır atış sonuçlarını düşük maliyetle iyileştirecek bir yaşam kalitesi iyileştirmesidir.
Gerçekten güvenebileceğimiz tek şey, uygulandığı takdirde daha iyi sonuçların daha güvenilir bir şekilde ortaya çıkacağıdır. Bu da SEO profesyonelleri için iyi bir haber.
Bu makalede ifade edilen görüşler konuk yazara aittir ve mutlaka Search Engine Land değildir. Personel yazarları burada listelenir.