
Üretken yapay zeka nedir ve nasıl çalışır?
Yayınlanan: 2023-09-26Yapay zekanın bir alt kümesi olan üretken yapay zeka, teknoloji dünyasında devrim niteliğinde bir güç olarak ortaya çıktı. Ama bu tam olarak nedir? Ve neden bu kadar ilgi görüyor?
Bu ayrıntılı kılavuz, üretken yapay zeka modellerinin nasıl çalıştığını, neler yapıp yapamadıklarını ve tüm bu öğelerin sonuçlarını ayrıntılı olarak ele alacaktır.
Üretken yapay zeka nedir?
Üretken yapay zeka veya genAI, metin, resim, müzik ve hatta video gibi yeni içerik üretebilen sistemleri ifade eder. Geleneksel olarak AI/ML üç anlama geliyordu: denetimli, denetimsiz ve takviyeli öğrenme. Her biri kümeleme çıktısına dayalı öngörüler sağlar.
Üretken olmayan yapay zeka modelleri, girdiye dayalı hesaplamalar yapar (bir görüntüyü sınıflandırmak veya bir cümleyi çevirmek gibi). Bunun tersine, üretken modeller makale yazmak, müzik bestelemek, grafik tasarlamak ve hatta gerçek dünyada var olmayan gerçekçi insan yüzleri yaratmak gibi "yeni" çıktılar üretir.
Üretken yapay zekanın etkileri
Üretken yapay zekanın yükselişinin önemli sonuçları var. İçerik üretme yeteneği sayesinde eğlence, tasarım ve gazetecilik gibi endüstriler bir paradigma değişimine tanık oluyor.
Örneğin, haber ajansları rapor taslakları oluşturmak için yapay zekayı kullanabilirken, tasarımcılar da grafikler için yapay zeka destekli öneriler alabiliyor. Yapay zeka, bu seçenekler iyi olsa da olmasa da saniyeler içinde yüzlerce reklam sloganı üretebilir olup olmadığı başka bir konudur.
Üretken yapay zeka, bireysel kullanıcılar için özel içerik üretebilir. Ruh halinize göre benzersiz bir şarkı oluşturan bir müzik uygulaması veya ilgilendiğiniz konularla ilgili makaleler hazırlayan bir haber uygulaması gibi bir şey düşünün.
Sorun şu ki yapay zeka içerik oluşturmada daha bütünleyici bir rol oynadıkça özgünlük, telif hakkı ve insan yaratıcılığının değeri hakkındaki sorular daha yaygın hale geliyor.
Üretken yapay zeka nasıl çalışır?
Üretken yapay zeka, özünde, ister bir cümledeki bir sonraki kelime, ister bir görüntüdeki bir sonraki piksel olsun, bir sıradaki bir sonraki veri parçasını tahmin etmekle ilgilidir. Bunun nasıl başarıldığını açıklayalım.
İstatistiksel modeller
İstatistiksel modeller çoğu yapay zeka sisteminin omurgasını oluşturur. Farklı değişkenler arasındaki ilişkiyi temsil etmek için matematiksel denklemler kullanırlar.
Üretken yapay zeka için modeller, verilerdeki kalıpları tanıyacak ve daha sonra bu kalıpları kullanarak veri üretecek şekilde eğitilir. yeni, benzer veriler.
Bir model İngilizce cümleler üzerine eğitilmişse, bir kelimenin diğerini takip etmesinin istatistiksel olasılığını öğrenerek tutarlı cümleler oluşturmasına olanak tanır.
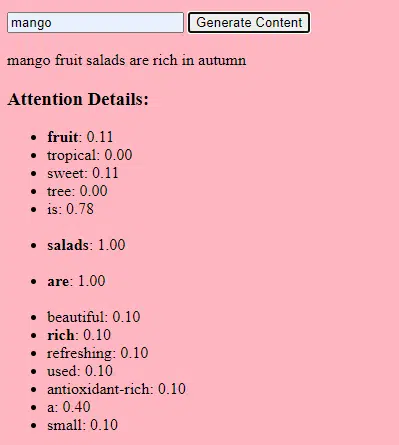
Veri toplama
Verilerin hem niteliği hem de niceliği çok önemlidir. Üretken modeller, kalıpları anlamak için geniş veri kümeleri üzerinde eğitilir.
Bir dil modeli için bu, kitaplardan, web sitelerinden ve diğer metinlerden milyarlarca kelimenin alınması anlamına gelebilir.
Bir görüntü modeli için bu, milyonlarca görüntünün analiz edilmesi anlamına gelebilir. Eğitim verileri ne kadar çeşitli ve kapsamlı olursa model o kadar iyi çeşitli çıktılar üretecektir.
Dönüştürücüler ve dikkat nasıl çalışır?
Transformatörler, Vaswani ve arkadaşlarının 2017'de "İhtiyacınız Olan Tek Şey Dikkat" başlıklı makalesinde tanıtılan bir tür sinir ağı mimarisidir. O günden bu yana en son teknolojiye sahip dil modellerinin temeli haline geldiler. ChatGPT, transformatörler olmadan çalışmaz.
"Dikkat" mekanizması, tıpkı insanların bir cümleyi anlarken belirli kelimelere dikkat etmesi gibi, modelin de girdi verilerinin farklı bölümlerine odaklanmasına olanak tanıyor.
Bu mekanizma, modelin girdinin hangi bölümlerinin belirli bir görevle ilgili olduğuna karar vermesine olanak tanıyarak onu son derece esnek ve güçlü kılar.
Aşağıdaki kod, her bir parçayı sade İngilizce olarak açıklayan, transformatör mekanizmalarının temel bir dökümüdür.
class Transformer: # Convert words to vectors # What this is : turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other. # Demo : "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9] self.embedding = Embedding(vocab_size, d_model) # Add position information to the vectors # What this is : Since words in a sentence have a specific order, we add information about each word's position in the sentence. # Demo : "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06] self.positional_encoding = PositionalEncoding(d_model) # Stack of transformer layers # What this is : Multiple layers of the Transformer model stacked on top of each other to process data in depth. # Why it does it : Each layer captures different patterns and relationships in the data. # Explained like I'm five : Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done! self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)] # Convert the output vectors to word probabilities # What this is : A way to predict the next word in a sequence. # Why it does it : After processing the input, we want to guess what word comes next. # Explained like I'm five : After listening to a story, this tries to guess what happens next. self.output_layer = Linear(d_model, vocab_size) def forward(self, x): # Convert words to vectors, as above x = self.embedding(x) # Add position information, as above x = self.positional_encoding(x) # Pass through each transformer layer # What this is : Sending our data through each floor of our multi-story building. # Why it does it : To deeply process and understand the data. # Explained like I'm five : It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess. for layer in self.transformer_layers: x = layer(x) # Get the output word probabilities # What this is : Our best guess for the next word in the sequence. return self.output_layer(x)Kodda bir Transformer sınıfınız ve tek bir TransformerLayer sınıfınız olabilir. Bu, bir binanın tamamının yerine bir zeminin planına sahip olmak gibidir.
Bu TransformerLayer kod parçası, çok kafalı dikkat ve özel düzenlemeler gibi belirli bileşenlerin nasıl çalıştığını gösterir.
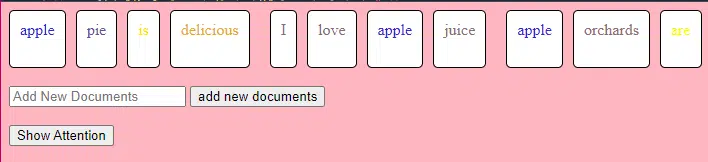
class TransformerLayer: # Multi-head attention mechanism # What this is : A mechanism that lets the model focus on different parts of the input data simultaneously. # Demo : "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words. self.attention = MultiHeadAttention(d_model, nhead) # Simple feed-forward neural network # What this is : A basic neural network that processes the data after the attention mechanism. # Demo : "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing) self.feed_forward = FeedForward(d_model) def forward(self, x): # Apply attention mechanism # What this is : The step where we focus on different parts of the sentence. # Explained like I'm five : It's like highlighting important parts of a book. attention_output = self.attention(x, x, x) # Pass the output through the feed-forward network # What this is : The step where we process the highlighted information. return self.feed_forward(attention_output)İleri beslemeli sinir ağı, yapay sinir ağlarının en basit türlerinden biridir. Bir giriş katmanı, bir veya daha fazla gizli katman ve bir çıkış katmanından oluşur.
Veriler giriş katmanından gizli katmanlara ve çıkış katmanına doğru tek yönde akar. Ağda döngü veya döngü yoktur.
Transformatör mimarisi kapsamında her katmanda dikkat mekanizmasından sonra ileri beslemeli sinir ağı kullanılmaktadır. Bu, arada ReLU aktivasyonu bulunan iki katmanlı basit bir doğrusal dönüşümdür.
# Scaled dot-product attention mechanism class ScaledDotProductAttention: def __init__(self, d_model): # Scaling factor helps in stabilizing the gradients # it reduces the variance of the dot product. # What this is: A scaling factor based on the size of our model's embeddings. # What it does : Helps to make sure the dot products don't get too big. # Why it does it : Big dot products can make a model unstable and harder to train. # How it does it : By dividing the dot products by the square root of the embedding size. # It's used when calculating attention scores. # Explained like I'm five : Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud. self.scaling_factor = d_model ** 0.5 def forward(self, query, key, value): # What this is : The function that calculates how much attention each word should get. # What it does : Determines how relevant each word in a sentence is to every other word. # Why it does it : So we can focus more on important words when trying to understand a sentence. # How it does it : By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values. # How it fits into the rest of the code : This function is called whenever we want to calculate attention in our model. # Explained like I'm five : Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers. # Calculate attention scores by taking the dot product of the query and key. scores = dot_product(query, key) / self.scaling_factor # Convert the raw scores to probabilities using the softmax function. attention_weights = softmax(scores) # Weight the values using the attention probabilities. return dot_product(attention_weights, value) # Feed-forward neural network # This is an extremely basic example of a neural network. class FeedForward: def __init__(self, d_model): # First linear layer increases the dimensionality of the data. self.layer1 = Linear(d_model, d_model * 4) # Second linear layer brings the dimensionality back to d_model. self.layer2 = Linear(d_model * 4, d_model) def forward(self, x): # Pass the input through the first layer, #Pass the input through the first layer: # Input : This refers to the data you feed into the neural network. I # First layer : Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output. # apply ReLU activation to introduce non-linearity, # and then pass through the second layer. #ReLU activation: ReLU stands for Rectified Linear Unit. # It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero. # Neural networks can model complex relationships in data by introducing non-linearities. # Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model. # Non-linearities allow the network to capture complex patterns and make better predictions. return self.layer2(relu(self.layer1(x))) # Positional encoding adds information about the position of each word in the sequence. class PositionalEncoding: def __init__(self, d_model): # What this is : A setup to add information about where each word is in a sentence. # What it does : Prepares to add a unique "position" value to each word. # Why it does it : Words in a sentence have an order, and this helps the model remember that order. # How it does it : By creating a special pattern of numbers for each position in a sentence. # How it fits into the rest of the code : Before processing words, we add their position info. # Explained like I'm five : Imagine you're in a line with your friends. This gives everyone a number to remember their place in line. pass def forward(self, x): # What this is : The main function that adds position info to our words. # What it does : Combines the word's original value with its position value. # Why it does it : So the model knows the order of words in a sentence. # How it does it : By adding the position values we prepared earlier to the word values. # How it fits into the rest of the code : This function is called whenever we want to add position info to our words. # Explained like I'm five : It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on. return x # Helper functions def dot_product(a, b): # Calculate the dot product of two matrices. # What this is : A mathematical operation to see how similar two lists of numbers are. # What it does : Multiplies matching items in the lists and then adds them up. # Why it does it : To measure similarity or relevance between two sets of data. # How it does it : By multiplying and summing up. # How it fits into the rest of the code : Used in attention to see how relevant words are to each other. # Explained like I'm five : Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have. return a @ b.transpose(-2, -1) def softmax(x): # Convert raw scores to probabilities ensuring they sum up to 1. # What this is : A way to turn any list of numbers into probabilities. # What it does : Makes the numbers between 0 and 1 and ensures they all add up to 1. # Why it does it : So we can understand the numbers as chances or probabilities. # How it does it : By using exponentiation and division. # How it fits into the rest of the code : Used to convert attention scores into probabilities. # Explained like I'm five : Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind. return exp(x) / sum(exp(x), axis=-1) def relu(x): # Activation function that introduces non-linearity. It sets negative values to 0. # What this is : A simple rule for numbers. # What it does : If a number is negative, it changes it to zero. Otherwise, it leaves it as it is. # Why it does it : To introduce some simplicity and non-linearity in our model's calculations. # How it does it : By checking each number and setting it to zero if it's negative. # How it fits into the rest of the code : Used in neural networks to make them more powerful and flexible. # Explained like I'm five : Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones. return max(0, x)Üretken yapay zeka basit bir ifadeyle nasıl çalışır?
Üretken yapay zekayı ağırlıklı bir zar atmak olarak düşünün. Eğitim verileri ağırlıkları (veya olasılıkları) belirler.
Zar bir cümledeki bir sonraki kelimeyi temsil ediyorsa, eğitim verilerinde çoğunlukla mevcut kelimeyi takip eden kelime daha yüksek bir ağırlığa sahip olacaktır. Yani "gökyüzü", "muz" yerine "mavi"yi daha sık takip edebilir. Yapay zeka içerik üretmek için "zar attığında", eğitimine dayalı olarak istatistiksel olarak daha olası dizileri seçme olasılığı daha yüksektir.
Peki Yüksek Lisans'lar nasıl orijinal "görünen" içerik üretebilir?
"İçerik pazarlamacıları için en iyi Ramazan Bayramı hediyeleri" başlıklı sahte bir liste alalım ve bir Yüksek Lisans'ın nasıl kazanç sağlayabileceğini inceleyelim. Bu liste hediyeler, bayramlar ve içerik pazarlamacılarla ilgili belgelerdeki metinsel ipuçlarını birleştirerek oluşturulmuştur.
İşlenmeden önce metin "belirteçler" adı verilen daha küçük parçalara bölünür. Bu jetonlar bir karakter kadar kısa veya bir kelime kadar uzun olabilir.
Örnek: “Ramazan Bayramı bir kutlamadır” [“Bayram”, “el-Fitr”, “dir”, “bir”, “kutlama”] olur.
Bu, modelin yönetilebilir metin parçalarıyla çalışmasına ve cümlelerin yapısını anlamasına olanak tanır.
Her jeton daha sonra yerleştirmeler kullanılarak bir vektöre (sayı listesi) dönüştürülür. Bu vektörler her kelimenin anlamını ve bağlamını yakalar.
Konumsal kodlama, her kelime vektörüne cümle içindeki konumu hakkında bilgi ekleyerek modelin bu sıra bilgisini kaybetmemesini sağlar.
Daha sonra bir dikkat mekanizması kullanırız: bu, modelin bir çıktı oluştururken girdi metninin farklı bölümlerine odaklanmasını sağlar. BERT'i hatırlarsanız, Google çalışanlarını BERT konusunda bu kadar heyecanlandıran şey de buydu.
Modelimiz " hediyeler " ile ilgili metinleri görmüşse ve insanların kutlamalar sırasında hediye verdiklerini biliyorsa ve " Ramazan Bayramı "nın önemli bir kutlama olduğuna ilişkin metinleri de görmüşse, bu bağlantılara " dikkat edecektir".
Benzer şekilde, belirli araçlara veya kaynaklara ihtiyaç duyan " içerik pazarlamacıları " ile ilgili metinler görmüşse, " hediyeler " fikrini "içerik pazarlamacılara " bağlayabilir.

Artık bağlamları birleştirebiliriz: Model, giriş metnini birden çok Transformer katmanı aracılığıyla işlerken, öğrendiği bağlamları birleştirir.
Dolayısıyla, orijinal metinlerde “İçerik pazarlamacıları için Ramazan Bayramı hediyeleri” hiç belirtilmemiş olsa bile model, bu içeriği oluşturmak için “Ramazan Bayramı”, “hediyeler” ve “içerik pazarlamacıları” kavramlarını bir araya getirebilir.
Bunun nedeni, bu terimlerin her birinin etrafındaki daha geniş bağlamları öğrenmiş olmasıdır.
Girdiyi dikkat mekanizması ve her Transformer katmanındaki ileri beslemeli ağlar yoluyla işledikten sonra model, dizideki bir sonraki kelime için kelime dağarcığı üzerinden bir olasılık dağılımı üretir.
“En iyi” ve “Ramazan Bayramı” gibi kelimelerden sonra “hediyeler” kelimesinin gelme ihtimalinin yüksek olduğunu düşünebilir. Benzer şekilde, "hediyeleri" "içerik pazarlamacıları" gibi potansiyel alıcılarla ilişkilendirebilir.
Pazarlamacıların güvendiği günlük haber bülteni aramasını alın.
Şartlara bakın.
Ne kadar büyük dil modelleri oluşturuldu?
Temel bir transformatör modelinden GPT-3 veya BERT gibi gelişmiş bir geniş dil modeline (LLM) yolculuk, çeşitli bileşenlerin ölçeğinin büyütülmesini ve iyileştirilmesini içerir.
İşte adım adım bir döküm:
Yüksek Lisans'lar çok miktarda metin verisi üzerinde eğitilir. Bu verilerin ne kadar geniş olduğunu açıklamak zor.
Birçok Yüksek Lisans için başlangıç noktası olan C4 veri kümesi 750 GB metin verisidir. Bu 805.306.368.000 bayt anlamına gelir; çok fazla bilgi. Bu veriler kitaplar, makaleler, web siteleri, forumlar, yorum bölümleri ve diğer kaynakları içerebilir.
Veriler ne kadar çeşitli ve kapsamlı olursa modelin anlama ve genelleme yetenekleri de o kadar iyi olur.
Temel transformatör mimarisi temel olmaya devam ederken, LLM'ler önemli ölçüde daha fazla sayıda parametreye sahiptir. Örneğin GPT-3'ün 175 milyar parametresi var. Bu durumda parametreler, eğitim süreci sırasında öğrenilen sinir ağındaki ağırlıkları ve önyargıları ifade eder.

Derin öğrenmede bir model, tahminleri ile gerçek sonuçlar arasındaki farkı azaltmak için bu parametreleri ayarlayarak tahminlerde bulunmak üzere eğitilir.
Bu parametreleri ayarlama işlemine, gradyan iniş gibi algoritmalar kullanan optimizasyon adı verilir.
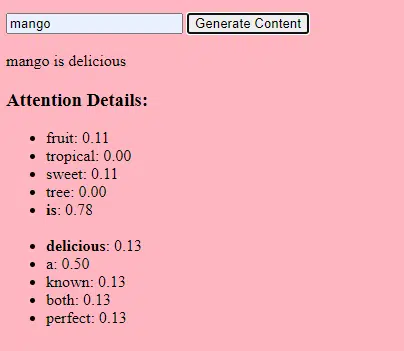
- Ağırlıklar: Bunlar, sinir ağındaki, ağın katmanları içindeki girdi verilerini dönüştüren değerlerdir. Modelin çıktısını optimize etmek için eğitim sırasında ayarlanırlar. Bitişik katmanlardaki nöronlar arasındaki her bağlantının ilişkili bir ağırlığı vardır.
- Önyargılar: Bunlar aynı zamanda sinir ağındaki bir katmanın dönüşümünün çıktısına eklenen değerlerdir. Modele ek bir özgürlük derecesi sağlayarak eğitim verilerine daha iyi uyum sağlamasına olanak tanır. Bir katmandaki her nöronun ilişkili bir önyargısı vardır.
Bu ölçeklendirme, modelin verilerdeki daha karmaşık kalıpları ve ilişkileri depolamasına ve işlemesine olanak tanır.
Çok sayıda parametre aynı zamanda modelin eğitim ve çıkarım için önemli düzeyde hesaplama gücü ve hafıza gerektirdiği anlamına da gelir. Bu tür modellerin eğitiminin kaynak yoğun olmasının ve genellikle GPU'lar veya TPU'lar gibi özel donanımların kullanılmasının nedeni budur.
Model, güçlü hesaplama kaynaklarını kullanarak sıradaki bir sonraki kelimeyi tahmin edecek şekilde eğitildi. Yaptığı hatalara göre iç parametrelerini ayarlar, tahminlerini sürekli geliştirir.
Tartıştığımıza benzer dikkat mekanizmaları yüksek lisans öğrencileri için çok önemlidir. Modelin çıktı üretirken girdinin farklı bölümlerine odaklanmasına olanak tanır.
Dikkat mekanizmaları, bir bağlamda farklı kelimelerin önemini tartarak modelin tutarlı ve bağlamsal olarak alakalı metinler üretmesini sağlar. Bunu bu kadar büyük ölçekte yapmak, LLM'lerin bu şekilde çalışmasını sağlar.
Bir transformatör metni nasıl tahmin eder?
Transformatörler, giriş belirteçlerini her biri dikkat mekanizmaları ve ileri besleme ağlarıyla donatılmış birden fazla katman aracılığıyla işleyerek metni tahmin eder.
İşlemden sonra model, dizideki bir sonraki kelime için kelime dağarcığı üzerinde bir olasılık dağılımı üretir. En yüksek olasılığa sahip kelime genellikle tahmin olarak seçilir.
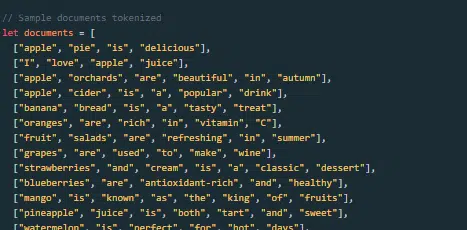
Büyük bir dil modeli nasıl oluşturulur ve eğitilir?
Bir Yüksek Lisans eğitimi oluşturmak, veri toplamayı, temizlemeyi, modeli eğitmeyi, modele ince ayar yapmayı ve güçlü, sürekli testleri içerir.
Model başlangıçta bir dizideki bir sonraki kelimeyi tahmin etmek için geniş bir külliyat üzerinde eğitilir. Bu aşama, modelin dilbilgisindeki kalıpları yakalayan kelimeler arasındaki bağlantıları, dünya hakkındaki gerçekleri temsil edebilecek ilişkileri ve mantıksal akıl yürütme gibi hissettiren bağlantıları öğrenmesine olanak tanır. Bu bağlantılar aynı zamanda eğitim verilerinde mevcut olan önyargıları da tespit etmesini sağlar.
Ön eğitimden sonra model, genellikle insan incelemecilerin yönergeleri takip etmesiyle daha dar bir veri kümesi üzerinde geliştirilir.
İnce ayar, LLM'lerin oluşturulmasında çok önemli bir adımdır. Önceden eğitilmiş modelin daha spesifik bir veri kümesi veya görev üzerinde eğitilmesini içerir. Örnek olarak ChatGPT'yi ele alalım.
GPT modelleriyle oynadıysanız, yönlendirmenin "bu şeyi yaz"dan ziyade "şunu yaz" şeklinde olduğunu bilirsiniz.
- Komut: Bir zamanlar
- Devam: Bir kulenin tepesinde kötü bir büyücü vardı.
- Devam: Bir kulenin tepesinde kötü bir büyücü vardı.
- Soru : Tavuk neden bir gruba katıldı?
- Devam : Çünkü bagetleri vardı!
Bu noktadan itibaren ChatGPT'ye ulaşmak çok sayıda düşük ücretli emek gerektirir. Bu insanlar, GPT yanıtlarının ve beklenen davranışların ağırlığına parmak basmak için muazzam bir bütünlük oluştururlar. Bu çalışanlar aşağıdakilere benzer tonlarca bilgi/devam metni oluşturur:
- Komut : Bu hikayeyi bitirin: “Bir varmış bir yokmuş..”
- Devamı: Elbette ! Bir varmış bir yokmuş, çok uzak bir diyarda, iki heybetli dağın arasında küçük bir köy varmış.
- Devamı: Elbette ! Bir varmış bir yokmuş, çok uzak bir diyarda, iki heybetli dağın arasında küçük bir köy varmış.
- Komut : Bana tavukla ilgili bir fıkra anlat.
- Devam : Tavuk neden bir gruba katıldı? Çünkü bagetleri vardı!
Bu ince ayar süreci birkaç nedenden dolayı önemlidir:
- Özgüllük: Ön eğitim modele dil hakkında geniş bir anlayış kazandırırken, ince ayar belirli görevlere veya alanlarla daha uyumlu hale getirmek için bilgi ve davranışını daraltır. Örneğin tıbbi verilere göre hassas şekilde ayarlanmış bir model, tıbbi sorulara daha iyi yanıt verecektir.
- Kontrol: İnce ayar, geliştiricilere modelin çıktıları üzerinde daha fazla kontrol sağlar. Geliştiriciler, istenen yanıtları üretmek ve istenmeyen davranışlardan kaçınmak için modeli yönlendirmek üzere seçilmiş bir veri kümesi kullanabilir.
- Güvenlik: Zararlı veya önyargılı çıktıların azaltılmasına yardımcı olur. Gerçek kişi olan incelemeciler, ince ayar süreci sırasında yönergeleri kullanarak modelin uygunsuz içerik üretmemesini sağlayabilir.
- Performans: İnce ayar, modelin belirli görevlerdeki performansını önemli ölçüde artırabilir. Örneğin, müşteri desteği için ince ayar yapılmış bir model, bu konuda genel bir modele göre çok daha iyi olacaktır.
ChatGPT'nin bazı açılardan özellikle ince ayarlandığını söyleyebilirsiniz.
Örneğin, "mantıksal akıl yürütme" yüksek lisans öğrencilerinin uğraştığı bir şeydir. ChatGPT'nin en iyi mantıksal akıl yürütme modeli - GPT-4 - sayılardaki kalıpları açıkça tanımak için yoğun bir şekilde eğitilmiştir.
Bunun gibi bir şey yerine:
- Komut : 2+2 nedir?
- Süreç : Çoğu zaman çocuklara yönelik matematik ders kitaplarında 2+2 =4. Bazen "2+2=5" ifadesine göndermeler olur, ancak durum böyle olduğunda genellikle George Orwell veya Star Trek ile ilgili daha fazla bağlam vardır. Eğer durum bu bağlamda olsaydı, ağırlık daha çok 2+2=5 lehine olurdu. Ancak bu bağlam mevcut değil, dolayısıyla bu örnekte bir sonraki jeton muhtemelen 4'tür.
- Yanıt : 2+2=4
Eğitim şöyle bir şey yapar:
- antrenman: 2+2=4
- antrenman: 4/2=2
- eğitim: 4'ün yarısı 2'dir
- eğitim: 2/2 dört eder
…ve benzeri.
Bu, daha "mantıklı" modeller için eğitim sürecinin daha sıkı olduğu ve modelin mantıksal ve matematiksel ilkeleri anlamasını ve doğru şekilde uygulamasını sağlamaya odaklandığı anlamına gelir.
Model, çeşitli matematik problemlerine ve bunların çözümlerine maruz bırakılarak, bu ilkelerin genelleştirilebilmesi ve yeni, görünmeyen problemlere uygulanabilmesi sağlanır.
Bu ince ayar sürecinin özellikle mantıksal akıl yürütme açısından önemi göz ardı edilemez. Bu olmadan model, basit mantıksal veya matematiksel sorulara yanlış veya anlamsız yanıtlar verebilir.
Görüntü modelleri ve dil modelleri
Hem görüntü hem de dil modelleri transformatörler gibi benzer mimarileri kullansa da işledikleri veriler temelde farklıdır:
Resim modelleri
Bu modeller piksellerle ilgilenir ve genellikle hiyerarşik bir şekilde çalışır; önce küçük desenleri (kenarlar gibi) analiz eder, ardından bunları daha büyük yapıları (şekiller gibi) tanımak için birleştirir ve görüntünün tamamını anlayana kadar bu şekilde devam eder.
Dil modelleri
Bu modeller kelime veya karakter dizilerini işler. Tutarlı ve bağlamsal olarak alakalı metinler oluşturmak için bağlamı, dilbilgisini ve anlambilimi anlamaları gerekir.
Öne çıkan üretken yapay zeka arayüzleri nasıl çalışır?
Dall-E + Yolculuğun Ortası
Dall-E, GPT-3 modelinin görüntü oluşturmaya uyarlanmış bir çeşididir. Metin-görüntü çiftlerinden oluşan geniş bir veri kümesi üzerinde eğitilmiştir. Midjourney, tescilli bir modele dayanan başka bir görüntü oluşturma yazılımıdır.
- Giriş: "İki başlı flamingo" gibi metinsel bir açıklama sağlarsınız.
- İşleme: Bu modeller, bu metni bir dizi sayı halinde kodlar ve ardından bu vektörlerin kodunu çözerek piksellerle ilişkileri bulur ve bir görüntü oluşturur. Model, metinsel açıklamalar ile görsel temsiller arasındaki ilişkileri eğitim verilerinden öğrenmiştir.
- Çıktı: Verilen açıklamaya uyan veya onunla ilgili olan bir resim.
Parmaklar, desenler, sorunlar
Bu araçlar neden sürekli olarak normal görünen eller üretemiyor? Bu araçlar yan yana piksellere bakarak çalışır.
Daha eski veya daha ilkel oluşturulmuş görüntüleri daha yeni olanlarla karşılaştırırken bunun nasıl çalıştığını görebilirsiniz: önceki modeller çok bulanık görünüyor. Buna karşılık, daha yeni modeller çok daha canlı.
Bu modeller, daha önce oluşturduğu piksellere dayanarak bir sonraki pikseli tahmin ederek görüntüler üretir. Tam bir görüntü elde etmek için bu işlem milyonlarca kez tekrarlanır.
Eller, özellikle de parmaklar karmaşıktır ve doğru bir şekilde yakalanması gereken birçok ayrıntıya sahiptir.
Her parmağın konumu, uzunluğu ve yönü farklı görüntülerde büyük ölçüde farklılık gösterebilir.
Metinsel bir açıklamadan bir görüntü oluştururken modelin, elin tam pozu ve yapısı hakkında birçok varsayımda bulunması gerekir; bu da anormalliklere yol açabilir.
SohbetGPT
ChatGPT, doğal dil işleme görevleri için tasarlanmış transformatör tabanlı bir model olan GPT-3.5 mimarisini temel alır.
- Giriş: Bir konuşmayı simüle etmek için bir istem veya bir dizi mesaj.
- İşleme: ChatGPT, yanıtlar oluşturmak için çeşitli internet metinlerinden elde ettiği engin bilgisini kullanır. Konuşmada sunulan bağlamı dikkate alır ve en alakalı ve tutarlı yanıtı üretmeye çalışır.
- Çıktı: Konuşmayı sürdüren veya yanıtlayan bir metin yanıtı.
Uzmanlık
ChatGPT'nin gücü, çeşitli konuları ele alma ve insan benzeri konuşmaları simüle etme yeteneğinde yatmaktadır; bu da onu sohbet robotları ve sanal asistanlar için ideal kılmaktadır.
Bard + Arama Üretken Deneyimi (SGE)
Belirli ayrıntılar tescilli olsa da Bard, diğer son teknoloji ürünü dil modellerine benzer şekilde transformatör yapay zeka tekniklerini temel alır. SGE benzer modelleri temel alır ancak Google'ın kullandığı diğer makine öğrenimi algoritmalarını da kullanır.
SGE muhtemelen transformatör tabanlı üretken bir model kullanarak içerik üretiyor ve ardından aramadaki sıralama sayfalarından yanıtları bulanık bir şekilde çıkarıyor. (Bu doğru olmayabilir. Sadece onunla oynamanın nasıl işe yaradığına dayanan bir tahmin. Lütfen beni dava etmeyin!)
- Giriş: Bir bilgi istemi/komut/arama
- İşleme: Bard, girdiyi işler ve diğer LLM'lerin yaptığı gibi çalışır. SGE benzer bir mimari kullanır ancak uygun bir yanıt oluşturmak için kendi dahili bilgisini (eğitim verilerinden elde edilen) araştırdığı bir katman ekler. İlgili içeriği üretmek için istemin yapısını, bağlamını ve amacını dikkate alır.
- Çıktı: Bir hikaye, yanıt veya başka türde bir metin olabilecek oluşturulan içerik.
Üretken yapay zeka uygulamaları (ve bunların tartışmaları)
Sanat ve Tasarım
Üretken yapay zeka artık sanat eserleri, müzik ve hatta ürün tasarımları oluşturabiliyor. Bu, yaratıcılık ve yenilik için yeni yollar açtı.
Tartışma
Yapay zekanın sanatta yükselişi, yaratıcı alanlardaki iş kayıplarına ilişkin tartışmaları ateşledi.
Ayrıca aşağıdakilerle ilgili endişeler vardır:
- Özellikle yapay zeka tarafından oluşturulan içeriğin uygun bir atıf yapılmadan veya tazminat ödenmeden kullanılması durumunda iş gücü ihlalleri.
- Yöneticilerin yazarları yapay zekayla değiştirmekle tehdit etmesi, yazarların grevini tetikleyen konulardan biri.
Doğal dil işleme (NLP)
Yapay zeka modelleri artık sohbet robotları, dil çevirisi ve diğer NLP görevleri için yaygın olarak kullanılıyor.
Yapay genel zeka (AGI) hayalinin dışında, bu, "genelci" bir NLP modeline yakın oldukları için LLM'ler için en iyi kullanımdır.
Tartışma
Birçok kullanıcı, sohbet robotlarının kişisel olmayan ve bazen sinir bozucu olduğunu düşünüyor.
Üstelik yapay zeka, dil çevirisinde önemli ilerlemeler kaydetmiş olsa da çoğu zaman insan çevirmenlerin getirdiği inceliklerden ve kültürel anlayıştan yoksundur ve bu da etkileyici ve kusurlu çevirilere yol açmaktadır.
İlaç ve ilaç keşfi
Yapay zeka, çok miktarda tıbbi veriyi hızlı bir şekilde analiz edebilir ve potansiyel ilaç bileşikleri üreterek ilaç keşif sürecini hızlandırabilir. Pek çok doktor zaten not yazmak ve hasta iletişimleri için yüksek lisans eğitimlerini kullanıyor
Tartışma
Tıbbi amaçlar için Yüksek Lisans'a güvenmek sorunlu olabilir. Tıp hassasiyet gerektirir ve yapay zekanın yaptığı herhangi bir hata veya dikkatsizlik ciddi sonuçlara yol açabilir.
Tıpta ayrıca yüksek lisans eğitimi kullanıldığında daha da fazla pişen önyargılar zaten var. Aşağıda tartışıldığı gibi mahremiyet, etkililik ve etik ile ilgili benzer sorunlar da vardır.
Oyun
Pek çok yapay zeka meraklısı, yapay zekayı oyunlarda kullanmaktan heyecan duyuyor: yapay zekanın gerçekçi oyun ortamları, karakterler ve hatta tüm oyun olay örgüsünü yaratarak oyun deneyimini geliştirebileceğini söylüyorlar. NPC diyaloğu bu araçlar kullanılarak geliştirilebilir.
Tartışma
Oyun tasarımında kasıtlılık konusunda bir tartışma var.
Yapay zeka çok büyük miktarda içerik üretebilse de bazıları, insan tasarımcıların getirdiği kasıtlı tasarım ve anlatı bütünlüğünden yoksun olduğunu savunuyor.
Watchdogs 2'de programatik NPC'ler vardı ve bu, oyunun bir bütün olarak anlatı bütünlüğüne çok az katkıda bulundu.
Pazarlama ve Reklamcılık
Yapay zeka, tüketici davranışlarını analiz edip kişiselleştirilmiş reklamlar ve tanıtım içerikleri üreterek pazarlama kampanyalarını daha etkili hale getirebilir.
LLM'ler diğer insanların yazdıklarından bağlam alır, bu da onları kullanıcı hikayeleri veya daha incelikli programatik fikirler oluşturmak için faydalı kılar. Yüksek Lisans'lar, yeni TV satın alan birine TV önermek yerine, birinin isteyebileceği aksesuarları önerebilir.
Controversy
The use of AI in marketing raises privacy concerns. There's also a debate about the ethical implications of using AI to influence consumer behavior.
Dig deeper: How to scale the use of large language models in marketing
Continuing issues with LLMS
Contextual understanding and comprehension of human speech
- Limitation: AI models, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI models, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they've seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model's last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI models can store vast amounts of information, they often lack a "common sense" understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI models learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI models generate content based on patterns they've seen. While they can combine these patterns in novel ways, they don't "invent" like humans do. Their "creativity" is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration : Using AI models in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI models might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-date expectations for code, using functions like “document.write” that are no longer considered best practice.
Hot takes from an MLOps engineer and technical SEO
This section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn't real (for generative text interfaces)
Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these models have become the new “gold rush," people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there's no guarantee they'll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don't know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they're essentially regurgitating and recombining what they've seen before. They don't "invent" in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it's hard for LLMs to deal with it.

For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks.
LLMs don't know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can't verify facts or discern true and false information.
If they've been exposed to misinformation or biased data during training, or they don't have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it's a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there's a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that's challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
Bu makalede ifade edilen görüşler konuk yazara aittir ve mutlaka Search Engine Land değildir. Personel yazarları burada listelenir.