
使用互联网档案网站的 5 种方法?
已发表: 2021-10-25Internet Archive 是一个非营利性数字图书馆,拥有最大的在线资产收藏。 它始于 1996 年,声称使用其 WaybackMachine 存档了超过 6000 亿个网页。 您可以通过不同方式将这些存档页面用于您的项目。 在本文中,我们将解释如何使用 Internet Archive 内容并提交您的网站进行存档。
互联网档案内容
许多人认为 arhive.org 只托管存档网页。 但是,除了网页之外,您还可以从他们的网站上找到书籍、音频、视频、软件和图像。 以下是您可以使用 Internet Archive 网站的一些方法。
1. 查找已删除和不可用的网页内容
Internet Archive 最简单和最有用的方法是查找当前网络上不可用的内容。 让我们用一个例子来解释这一点。 一些网站建设者(如 Weebly)不提供将您的文章保存在“垃圾箱”中的选项。 如果您错误地删除了一个页面,它将从您的网站上永久消失。 问题是他们的博客页面是索引页面,删除该单个博客页面将永久删除您多年来创建的所有博客文章。 我们的一位读者向我们发送电子邮件,询问如何检索 100 多篇 Weebly 博客文章,因为他错误地删除了博客索引页。
查看 Internet Archive 是检索已删除内容的最简单选项。 尽管 Internet Archive 不会提供快速解决方案,但至少您可以从存档页面查看和检索您的内容。
- 转到 Internet Archive 网站的 WaybackMachine 部分。
- 输入要查看历史记录的站点或页面 URL,然后单击“浏览历史记录”按钮。

- 您将看到一个日历,其中突出显示了日期,表明这些日期有可用的档案。
- 单击日期并选择要查看的快照。
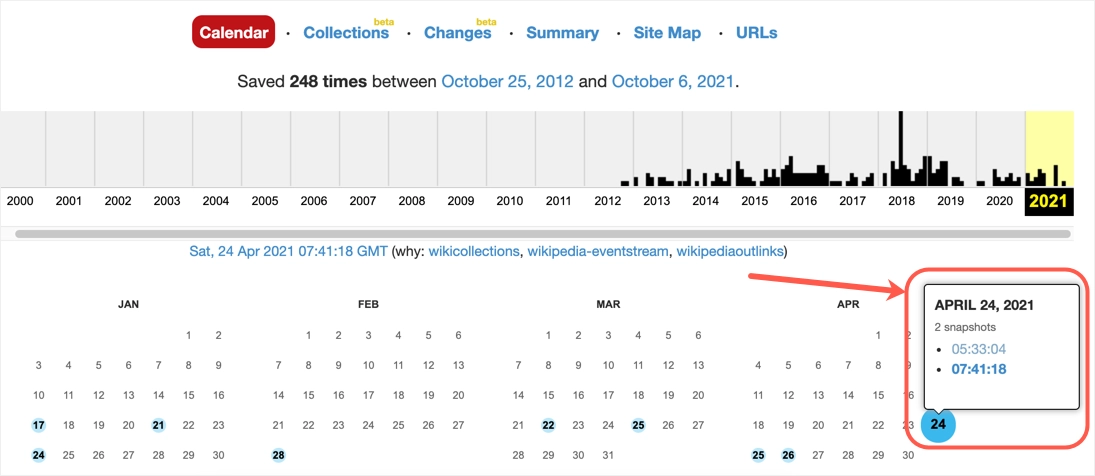
- 您可以查看所选日期的网页内容。 您可以更改顶部栏上的日期以将快照更改为不同的日期。
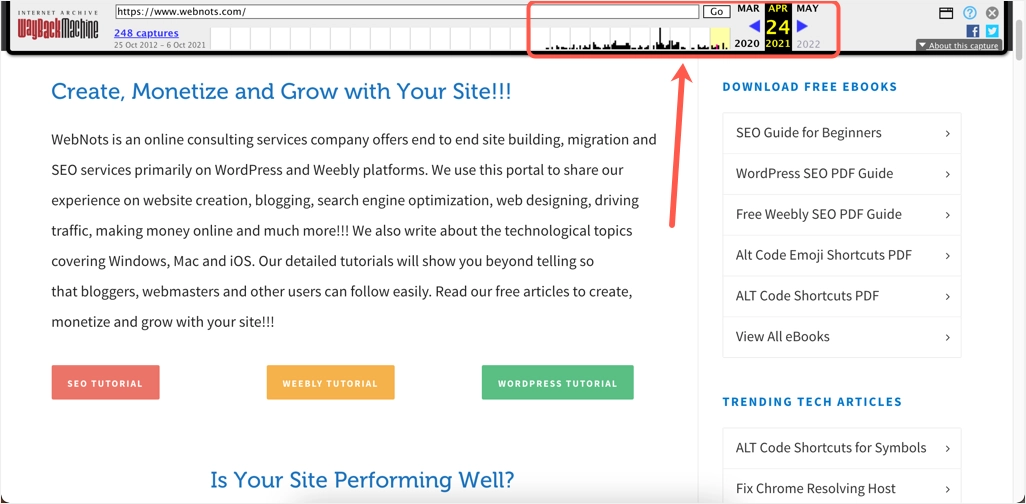
- 现在,如果您在实时站点上错误地删除或修改了内容,您可以复制和使用该内容。
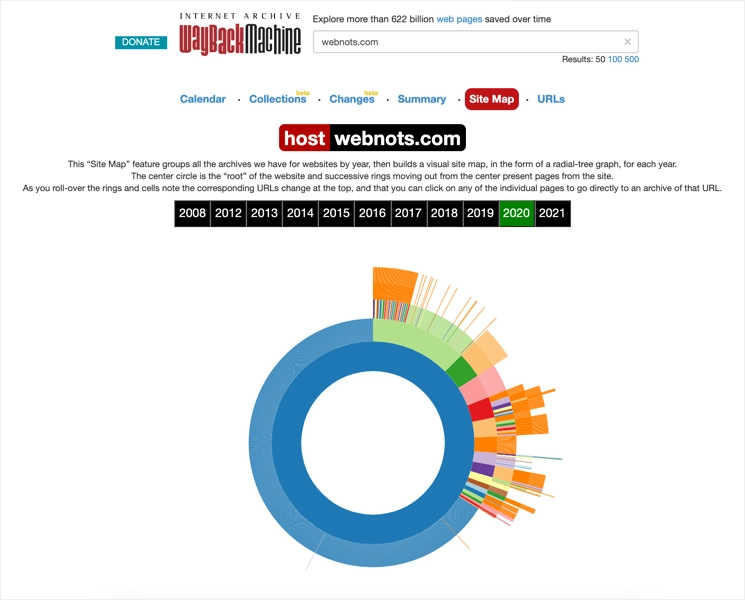
除了作为日历查看之外,您还可以将视图更改为集合、更改、摘要、站点地图和 URL。 您会惊讶地看到 Internet Archive 中关于您的站点的可用信息数量。 下面是“站点地图”视图的外观,您可以将鼠标悬停在图表上以选择 URL 来查看快照。
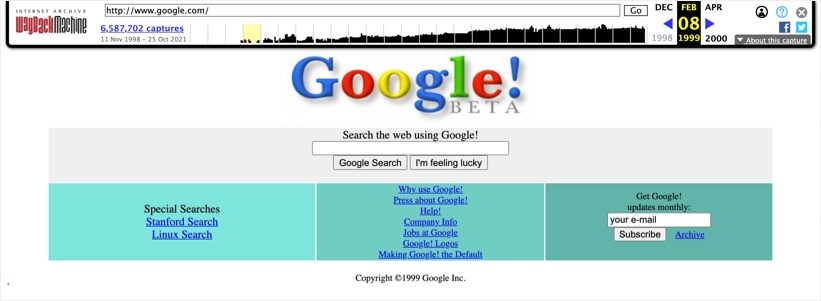
当您想了解某个特定站点十年前的样子时,快照对于文档也很有用。 例如,以下是 1999 年 Google 网站的外观。
SEO 优惠:使用 Semrush Pro 14 天特别免费试用优化您的网站。
2. 提交您的网站快照
也可以将网页内容保存到 Internet Archive。 您可以提交您自己的网站或您喜欢的任何网页,但在 archive.org 网站中找不到。
- 转到 Internet Archive 的 web 部分并向下滚动一点。
- 您将看到“立即保存页面”选项,如下所示。
- 输入您的 URL 并单击“保存页面”按钮以捕获页面的当前快照。
3. 从集合中查看和收听
如前所述,网页只是 Internet Archive 网站的一部分。 您可以在线阅读或收听大量电子书、音频和视频。
- 当您在 Internet Archive 主页中时,向下滚动并单击您最喜欢的收藏。
- 例如,您可以找到“欧洲图书馆”并单击它。

- 您会找到超过 700K 的数字图书,然后点击您想阅读或聆听的图书。
- 它将打开一个电子书阅读器界面; 您可以简单地放大或更改为一页视图以放大书籍并在线阅读。 也可以为您阅读本书并在您完成另一项任务时聆听。
您甚至可以找到 1900 年代出版的书籍,而这些书籍在实体图书馆中很难找到。

4. 检查互联网档案项目
Internet Archive 有许多有用的项目,您可以根据需要使用它们。
- 组织可以将档案用作 Internet Archive 的 arhive-it.org 项目部分的订阅服务。
- 从他们的 openlibrary.org 项目借书。
- 获取您喜欢的软件的存档。
您可以查看他们的项目页面以获取有关当前项目的更多详细信息。
5. 从档案重建您的网站
运行一个网站需要很大的耐心,许多博主在中间删除了他们的网站,并因为没有获得足够的流量而沮丧地退出博客。 然而,一段时间后,他们后悔并没有办法继续他们的博客之旅。 如果您是删除站点的人,请不要担心!!! 有许多第三方服务提供商可以帮助您从 Internet Archive 内容重建您的站点。 您必须为内容检索和恢复所需格式支付象征性费用。 例如,您只需 45 美元即可重建您的原始 WordPress 博客,然后从您离开的地方继续。

查看此 Internet Archive 页面中的重建服务提供商列表。
阻止 WaybackMachine Crawler
最后,您可能不希望您的网站内容成为 Internet 档案馆的一部分,这是有充分理由的。 可能您想保持站点的个人信息,或者发现一些已从站点中删除的敏感信息已存档。 简单的选择是使用 robots.txt 文件并阻止 Internet Archive 的爬虫访问。 在您的 robots.txt 文件中添加以下行以阻止整个站点存档。
User-agent: ia_archiver Disallow: /另一种选择是通过电子邮件与他们联系并请求排除。
使用 Internet Archive 的常见问题
是的,如果您的页面之前已存档。
是的,如果可用,您可以找到称为快照的历史版本。
是的,您只需转到 WaybackMachine 部分并保存您的页面内容即可。
不,用于查看快照。 但是,您需要一个来上传您的资产。
使用 robots.txt 阻止网站或页面,或通过电子邮件联系他们以排除网站。
坏主意,即使是简单的抄袭检查器也会比较 Internet Archive 中可用的内容。 在花费大量时间后,您很可能会收到侵犯版权 (DMCA) 的通知,或者因窃取他人的内容而受到搜索引擎的惩罚。 如果是自己的站点,可以自己重建或者使用第三方服务。 出于 SEO 的目的,如果您仍然持有旧域名,则可能需要设置重定向。
大量电子书、音频、视频、软件等。
存档页面只是像屏幕截图一样的快照。 您无法登录、访问数据库、查看受密码保护的内容。