
E2E 测试之旅第 1 部分:从 STUI 到 WebdriverIO
已发表: 2019-11-21注意:这是来自#frontend@twiliosendgrid 的帖子。 对于其他工程帖子,请转到技术博客卷。
随着 SendGrid 的前端架构在我们的 Web 应用程序中开始成熟,我们希望在我们通常的单元和集成测试层之外添加另一个级别的测试。 我们试图使用浏览器自动化工具构建具有 E2E(端到端)测试覆盖率的新页面和功能。
我们希望从客户的角度自动化测试,并尽可能避免对堆栈的任何部分可能发生的任何重大变化进行手动回归测试。 我们有并且仍然有以下目标:提供一种方法来为我们的前端应用程序编写一致的、可调试的、可维护的和有价值的 E2E 自动化测试,并与 CICD(持续集成和持续部署)集成。
我们尝试了多种技术方法,直到最终确定了用于 E2E 测试的理想解决方案。 在高层次上,这总结了我们的旅程:
- 构建我们自己的自定义内部 Ruby Selenium 解决方案,SiteTestUI aka STUI
- 从 STUI 过渡到基于节点的 WebdriverIO
- 对任何一种设置都不满意,最终迁移到赛普拉斯
这篇博文是记录和强调我们的经验、经验教训和权衡使用的每种方法的两部分之一,希望能指导您和其他开发人员如何将 E2E 测试与有用的模式和测试策略联系起来。
第一部分包括我们早期与 STUI 的斗争,我们如何迁移到 WebdriverIO,但仍然经历了许多与 STUI 类似的失败。 我们将介绍如何使用 WebdriverIO 编写测试,将测试 Docker 化以在容器中运行,并最终将测试与我们的 CICD 提供商 Buildkite 集成。
如果您想跳到我们今天的 E2E 测试,请继续阅读第二部分,因为它完成了我们从 STUI 和 WebdriverIO 到赛普拉斯的最终迁移,以及我们如何在不同团队之间进行设置。
TLDR:我们在使用 Selenium 包装器解决方案 STUI 和 WebdriverIO 时经历了类似的痛苦和挣扎,最终我们开始在 Cypress 中寻找替代方案。 我们学到了很多有见地的课程来解决编写 E2E 测试以及与 Docker 和 Buildkite 集成的问题。
目录:
首次涉足 E2E 测试:siteTESUI aka STUI
从 STUI 切换到 WebdriverIO
第 1 步:确定 WebdriverIO 的依赖项
第 2 步:环境配置和脚本
第 3 步:在本地实施 ENE 测试
第 4 步:Docker 化所有测试
第 5 步:与 CICD 集成
与 WebdriverIo 的权衡
搬到赛普拉斯
首次涉足 E2E 测试:SiteTestUI aka STUI
在最初寻找浏览器自动化工具时,我们的 SDET(测试中的软件开发工程师)投入使用 Ruby 和 Selenium 构建我们自己的自定义内部解决方案,特别是 Rspec 和一个名为 Gridium 的自定义 Selenium 框架。 我们重视它的跨浏览器支持、为我们的 QA(质量保证)工程师测试用例配置我们自己与 TestRail 的自定义集成的能力,以及为所有前端团队构建理想存储库以在一个位置编写 E2E 测试并成为按计划运行。
作为一个渴望第一次使用 SDET 为我们构建的工具编写一些 E2E 测试的前端开发人员,我们开始为我们已经发布的页面实施测试,并思考如何正确设置用户和种子数据以专注于部分我们想要测试的功能。 我们在此过程中学到了一些很棒的东西,比如形成页面对象来组织帮助功能和我们希望按页面交互的元素的选择器,并开始形成遵循这种结构的规范:
我们按照类似的模式逐渐在同一个 repo 中的不同团队中建立了大量的测试套件,但我们很快就遇到了许多挫折,这将极大地减缓我们对 STUI 的新开发人员和一致贡献者的进度,例如:
- 在运行测试套件之前,启动和运行需要花费大量时间和精力来安装所有浏览器驱动程序、Ruby Gem 依赖项和正确的版本。 我们有时不得不弄清楚为什么测试会在一个人的机器上运行而不是在另一个人的机器上运行,以及它们的设置有何不同。
- 测试套件激增并运行了数小时直到完成。 由于所有团队都为同一个 repo 做出了贡献,连续运行所有测试意味着要等待几个小时才能运行整个测试套件,并且多个团队推送新代码可能会导致其他地方的另一个测试失败。
- 我们对易碎的 CSS 选择器和复杂的 XPath 选择器感到沮丧。 下图充分解释了使用 XPath 如何使事情变得更复杂,而这些是一些更简单的事情。

- 调试测试很痛苦。 我们在调试模糊的错误输出时遇到了麻烦,我们通常不知道事情在哪里以及如何失败。 我们只能反复运行测试并观察浏览器来推断它可能失败的地方以及导致它的代码。 当 CICD 中的 Docker 环境中的测试失败时,除了控制台输出之外没有太多可看的东西,我们很难在本地重现并解决问题。
- 我们遇到了Selenium 错误和缓慢。 由于所有请求都从服务器发送到浏览器,测试运行缓慢,有时我们的测试会在尝试选择页面上的许多元素或在测试运行期间出于未知原因时完全崩溃。
- 更多的时间花在修复和跳过测试上,而损坏的计划构建测试运行开始被忽略。 这些测试在实际表示系统中的真实错误方面没有提供价值。
- 我们的前端团队感觉与 E2E 测试脱节,因为它存在于与各自 Web 应用程序不同的单独存储库中。 我们经常需要同时打开两个存储库,并在测试运行时继续在代码库和浏览器选项卡之间来回查看。
- 前端团队不喜欢从每天用 JavaScript 或 TypeScript 编写代码到 Ruby 的上下文切换,并且在为 STUI 做出贡献时必须重新学习如何编写测试。
- 由于这是我们很多人在为测试做出贡献时的第一次尝试,我们陷入了许多反模式,例如通过 UI 建立登录状态,没有通过 API 进行足够的拆卸或设置,以及没有足够的文档跟随什么使一个伟大的测试。
尽管我们在一个 repo 中为许多不同的团队编写了大量的 E2E 测试取得了进展,并学习了一些有用的模式,但我们对整体开发人员体验感到头疼,多点故障,以及缺乏有价值的稳定测试验证我们的整个堆栈。
我们重视一种授权其他前端开发人员和 QA 使用 JavaScript 构建自己的稳定 E2E 测试套件的方法,该套件驻留在他们自己的应用程序代码中,以促进测试的重用、接近性和所有权。 这促使我们探索 WebdriverIO,这是一个基于 JavaScript 的 Selenium 浏览器自动化测试框架,作为我们对 STUI(自定义 Ruby Selenium 内部解决方案)的初始替代品。
我们稍后会经历它的失败并最终转向赛普拉斯(如果 WebdriverIO 的东西不吸引您,请在此处快速前进到第 2 部分),但是我们在每个团队的存储库中建立标准化基础设施、将 E2E 测试集成到我们前端的 CICD 中获得了宝贵的经验团队,并采用在我们的旅程中值得记录的技术模式,并让其他人了解谁可能即将加入 WebdriverIO 或任何其他 E2E 测试解决方案。
从 STUI 切换到 WebdriverIO

在着手开发 WebdriverIO 以减轻我们所经历的挫败感时,我们尝试让每个前端团队将使用 Ruby Selenium 方法编写的现有自动化测试转换为 JavaScript 或 TypeScript 中的 WebdriverIO 测试,并比较稳定性、速度、开发人员体验和整体维护测试。
为了实现我们将 E2E 测试驻留在前端团队的应用程序存储库中并在 CICD 和预定管道中运行的理想设置,我们回顾了以下步骤,这些步骤通常适用于任何希望加入具有类似目标的 E2E 测试框架的团队:
- 安装和选择依赖项以与测试框架挂钩
- 建立环境配置和脚本命令
- 实施针对不同环境在本地通过的端到端测试
- Docker 化测试
- 将 Dockerized 测试与 CICD 提供程序集成
第 1 步:确定 WebdriverIO 的依赖项
WebdriverIO 为开发人员提供了在许多框架、报告器和服务中进行选择的灵活性,以启动测试运行程序。 这需要团队进行大量的修补和研究才能确定某些库才能开始。
由于 WebdriverIO 没有规定使用什么,它为前端团队打开了拥有不同库和配置的大门,尽管整体核心测试在使用 WebdriverIO API 时是一致的。
我们选择让每个前端团队根据自己的喜好进行定制,我们通常使用 Mocha 作为测试框架,Mochawesome 作为报告器,Selenium Standalone 服务和 Typescript 支持。 我们之所以选择 Mocha 和 Mochawesome,是因为我们的团队之前对 Mocha 的熟悉和经验,但其他团队也决定使用其他替代方案。
第 2 步:环境配置和脚本
在决定了 WebdriverIO 基础设施之后,我们需要一种方法让我们的 WebdriverIO 测试在每个环境的不同设置下运行。 这是一个列表,说明了我们希望如何执行这些测试以及为什么我们希望支持它们的大多数用例:
- 针对在 localhost 上运行的 Webpack 开发服务器(即 http://localhost:8000),该开发服务器将指向某个环境 API,例如测试或登台(即 https://testing.api.com 或 https:// staging.api.com)。
为什么? 有时我们需要对本地 Web 应用程序进行更改,例如为我们的测试添加更多特定的选择器,以便以更健壮的方式与元素交互,或者我们正在开发新功能并需要调整和验证现有的自动化测试将针对我们的新代码更改在本地传递。 每当应用程序代码更改并且我们还没有推送到已部署的环境时,我们使用此命令针对我们的本地 Web 应用程序运行我们的测试。 - 针对特定环境(即 https://testing.app.com 或 https://staging.app.com)的已部署应用程序,例如测试或登台
为什么? 其他时候应用程序代码不会改变,但我们可能不得不改变我们的测试代码来修复一些脆弱性,或者我们有足够的信心在不进行任何前端更改的情况下完全添加或删除测试。 我们大量使用此命令来针对已部署的应用程序在本地更新或调试测试,以更接近地模拟我们的测试如何在 CICD 管道中运行。 - 在Docker 容器中针对特定环境(如测试或登台)部署的应用程序运行
为什么? 这适用于 CICD 管道,因此我们可以触发 E2E 测试在 Docker 容器中运行,例如针对暂存部署的应用程序,并确保它们在将代码部署到生产之前或在专用管道中的预定测试运行中通过。 最初设置这些命令时,我们进行了大量试验和错误,以使用不同的环境变量值启动 Docker 容器,并在将其与我们的 CICD 提供程序 Buildkite 挂钩之前,测试是否成功执行了正确的测试。
为了实现这一点,我们设置了一个具有共享属性和许多环境特定文件的通用基础配置文件,这样每个环境配置文件都将与基础文件合并,并根据需要覆盖或添加属性以运行。 我们可以为每个环境拥有一个文件,而不需要基本文件,但这会导致常见设置中的大量重复。 我们选择使用像deepmerge这样的库来为我们处理它,但重要的是要注意,对于嵌套对象或数组,合并并不总是完美的。 始终仔细检查生成的输出配置,因为当存在未正确合并的重复属性时,它可能会导致未定义的行为。
我们形成了一个通用的基本配置文件wdio.conf.js ,如下所示:
为了适应我们针对指向环境 API 的本地 webpack 开发服务器运行 E2E 测试的第一个主要用例,我们通过以下方式生成了 localhost 配置文件wdio.localhost.conf.js :
请注意,我们合并了基础文件并将 localhost 特定属性添加到文件中,以使其更紧凑且更易于维护。 我们还使用 Selenium Standalone 服务来启动不同类型的浏览器,也就是功能。
对于针对已部署的 Web 应用程序运行 E2E 测试的第二个用例,我们设置了测试和暂存应用程序配置文件`wdio.testing.conf.js` 和wdio.staging.conf.js ,类似于以下内容:
在这里,我们在配置文件中添加了一些额外的环境变量,例如登台专用用户的登录凭据,并更新了“baseUrl”以指向已部署的登台应用程序 URL。
对于在 Docker 容器中针对 CICD 提供者范围内部署的 Web 应用程序运行 E2E 测试的第三个用例,我们设置了 CICD配置文件wdio.cicd.testing.conf.js和wdio.cicd.staging.conf.js ,像这样:
请注意我们不再使用 Selenium Standalone 服务,因为稍后我们将在 Docker Compose 文件中的单独服务中安装 Selenium Chrome、Selenium Hub 和应用程序代码。 该配置还展示了与登台配置相同的环境变量,例如登录凭据和“baseUrl”,因为我们希望针对已部署的登台应用程序运行我们的测试,唯一的区别是这些测试旨在在 Docker 容器中执行.
建立这些环境配置文件后,我们概述了package.json脚本命令,这些命令将作为我们测试的基础。 对于这个例子,我们在命令前加上“uitest”来表示使用 WebdriverIO 的 UI 测试,因为我们也用*.uitest.js结束了测试文件。 以下是暂存环境的一些示例命令:
第 3 步:在本地实施 E2E 测试
有了手头的所有测试命令,我们在 STUI 存储库中确定了测试范围,以便我们转换为 WebdriverIO 测试。 我们专注于中小型页面测试,并开始应用页面对象模式,以有组织的方式封装每个页面的所有 UI。
我们可以使用一堆辅助函数或对象文字或任何其他策略来构建结构化文件,但关键是要有一种一致的方式来快速交付可维护的测试并坚持下去。 如果特定页面的 UI 流或 DOM 元素发生变化,我们只需要重构与其相关的页面对象以及可能的测试代码即可再次通过测试。
我们通过拥有一个具有共享功能的基础页面对象来实现页面对象模式,所有其他页面对象都将从该基础页面对象扩展而来。 我们有诸如 open 之类的函数来为所有页面对象提供一致的 API,以便在浏览器中“打开”或访问页面的 URL。 它类似于这样:
实现特定页面对象遵循从基Page类扩展的相同模式,并将选择器添加到我们希望与之交互或断言的某些元素以及辅助函数以在页面上执行操作。
请注意我们如何使用通过super.open(...)打开的基类和页面的特定路由,因此我们可以通过调用SomePage.open()访问页面。 我们还导出了已经初始化的类,因此我们可以引用SomePage.submitButton或SomePage.tableRows等元素,并使用 WebdriverIO 命令与这些元素交互或断言。 如果页面对象打算在构造函数中使用其自己的成员属性进行共享和初始化,我们也可以直接导出类并在测试文件中使用new SomePage(...constructorArgs)实例化页面对象。
在我们用选择器和一些辅助功能布置页面对象之后,我们编写了 E2E 测试并通常建模了这个测试公式:
- 在运行实际测试之前,通过 API 设置或拆除将测试条件重置为预期起点所必需的内容。
- 登录到专门的用户进行测试,这样每当我们直接访问页面时,我们都会保持登录状态,而不必通过 UI。 我们创建了一个简单的
login辅助函数,它接收用户名和密码,调用我们用于登录页面的相同 API,最终返回我们保持登录所需的身份验证令牌并传递受保护的 API 请求的标头。 其他公司可能有更多的自定义内部端点或工具来快速创建具有种子数据和配置的全新用户,但不幸的是,我们没有足够充实。 我们会以老式的方式来做,并在我们的环境中通过 UI 使用不同的配置创建专门的测试用户,并且经常对具有不同用户的页面进行测试,以避免资源冲突并在测试并行运行时保持隔离。 我们必须确保专门的测试用户不会被其他人触动,否则当有人在不知不觉中修改其中一个时,测试会中断。 - 自动执行这些步骤,就好像最终用户会与功能/页面进行交互一样。 通常,我们会访问包含我们的功能流的页面,并开始遵循最终用户的高级步骤,例如填写输入、单击按钮、等待模式或横幅出现,以及观察表格以查看更改的输出行动的结果。 通过使用我们方便的页面对象和选择器,我们快速实现了每个步骤,并且在此过程中进行完整性检查,我们将断言用户在功能流期间应该或不应该在页面上看到什么,以确保某些事情的行为符合预期在每个步骤之前和之后。 我们还考虑选择高价值的快乐路径测试和有时容易重现的常见错误状态,将其余较低级别的测试推迟到单元和集成测试。
这是我们 E2E 测试总体布局的粗略示例(此策略也适用于我们尝试过的其他测试框架):
附带说明一下,我们选择不在本系列博文中介绍 WebdriverIO 和 E2E 最佳实践的所有技巧和陷阱,但我们将在以后的博文中讨论这些主题,敬请期待!
第 4 步:Docker 化所有测试
在云中的新 AWS 机器上执行每个 Buildkite 管道步骤时,我们不能简单地调用“npm run uitests:staging”,因为这些机器没有 Node、浏览器、我们的应用程序代码或任何其他依赖项来实际运行测试.
为了解决这个问题,我们将 Node、Selenium、Chrome 和应用程序代码等所有依赖项捆绑在一个 Docker 容器中,以便 WebdriverIO 测试能够成功运行。 我们利用 Docker 和 Docker Compose 来组装启动和运行所需的所有服务,这些服务转换为Dockerfiles和docker-compose.yml文件,并进行了大量实验,在本地启动 Docker 容器以使事情正常运行。
为了提供更多背景信息,我们不是 Docker 方面的专家,因此确实需要相当长的时间来了解如何将所有东西放在一起。 Dockerize WebdriverIO 测试有多种方法,我们发现很难将许多不同的服务编排在一起,并筛选不同的 Docker 映像、Compose 版本和教程,直到一切正常。
我们将展示与我们团队的一个配置相匹配的大部分充实文件,我们希望这为您或任何解决基于 Selenium 的 Dockerizing 测试的一般问题的人提供见解。
在高层次上,我们的测试要求以下内容:
- Selenium用于执行命令并与浏览器通信。 我们使用 Selenium Hub 随意启动多个实例,并在 docker-compose 文件中为
selenium-hub服务下载了镜像“selenium/hub”。 - 要运行的浏览器。 我们启动了 Selenium Chrome 实例并在
docker-compose.yml file中为selenium-chrome服务安装了映像“selenium/node-chrome-debug”。 - 在安装了任何其他 Node 模块的情况下运行我们的测试文件的应用程序代码。 我们创建了一个新的
Dockerfile来为 Node 提供一个环境来安装 npm 包和运行package.json脚本,复制测试代码,并在 dockerdocker-compose.yml文件中分配一个专门用于运行名为uitests的测试文件的服务。
为了提供运行 WebdriverIO 测试所需的所有应用程序和测试代码的服务,我们制作了一个名为Dockerfile的Dockerfile.uitests并安装了所有node_modules并将代码复制到 Node 环境中映像的工作目录中。 这将被我们的uitests Docker Compose 服务使用,我们通过以下方式实现了Dockerfile设置:

为了让 Selenium Hub、Chrome 浏览器和应用程序测试代码一起运行 WebdriverIO 测试,我们在 docker docker-compose.uitests.yml文件中概述了selenium-hub 、 selenium-chrom e 和uitest服务:
我们通过环境变量、 depends_on和向服务公开端口来连接 Selenium Hub 和 Chrome 映像。 我们的测试应用程序代码映像最终会从我们管理的私有 Docker 注册表中推送和拉取。
我们将在 CICD 期间使用某些环境变量(如VERSION和PIPELINE_SUFFIX )为测试代码构建 Docker 映像,以通过标签和更具体的名称引用映像。 然后我们将启动 Selenium 服务并通过uitests服务执行命令来执行 WebdriverIO 测试。
当我们构建我们的 Docker Compose 文件时,我们利用docker-compose up和docker-compose down等有用的命令以及安装在我们机器上的 Mac Docker 来本地测试我们的图像是否具有正确的配置并在与 Buildkite 集成之前顺利运行。 我们记录了构建标记图像所需的所有命令,将它们推送到注册表,将它们拉下,并根据环境变量值运行测试。
第 5 步:与 CICD 集成
在我们建立了有效的 Docker 命令并且我们的测试在 Docker 容器中针对不同环境成功运行后,我们开始与我们的 CICD 提供商 Buildkite 集成。
Buildkite 提供了在我们的 AWS 机器上执行.yml文件中的步骤的方法,其中 Bash 脚本和环境变量通过代码或 Buildkite 设置 UI 为我们的 repo 管道设置。
Buildkite 还允许我们使用导出的环境变量从我们的主部署管道触发这个测试管道,我们可以将这些测试步骤重用于其他隔离的测试管道,这些测试管道将按计划运行,供我们的 QA 监控和查看。
在高层次上,我们为 WebdriverIO 和后来的 Cypress 测试 Buildkite 管道共享以下类似步骤:
- 设置 Docker 映像。 构建、标记测试所需的 Docker 映像并将其推送到注册表,以便我们可以在后面的步骤中将其拉下。
- 根据环境变量配置运行测试。 为特定构建拉下标记的 Docker 映像,并针对已部署的环境执行正确的命令,以从设置的环境变量中运行选定的测试套件。
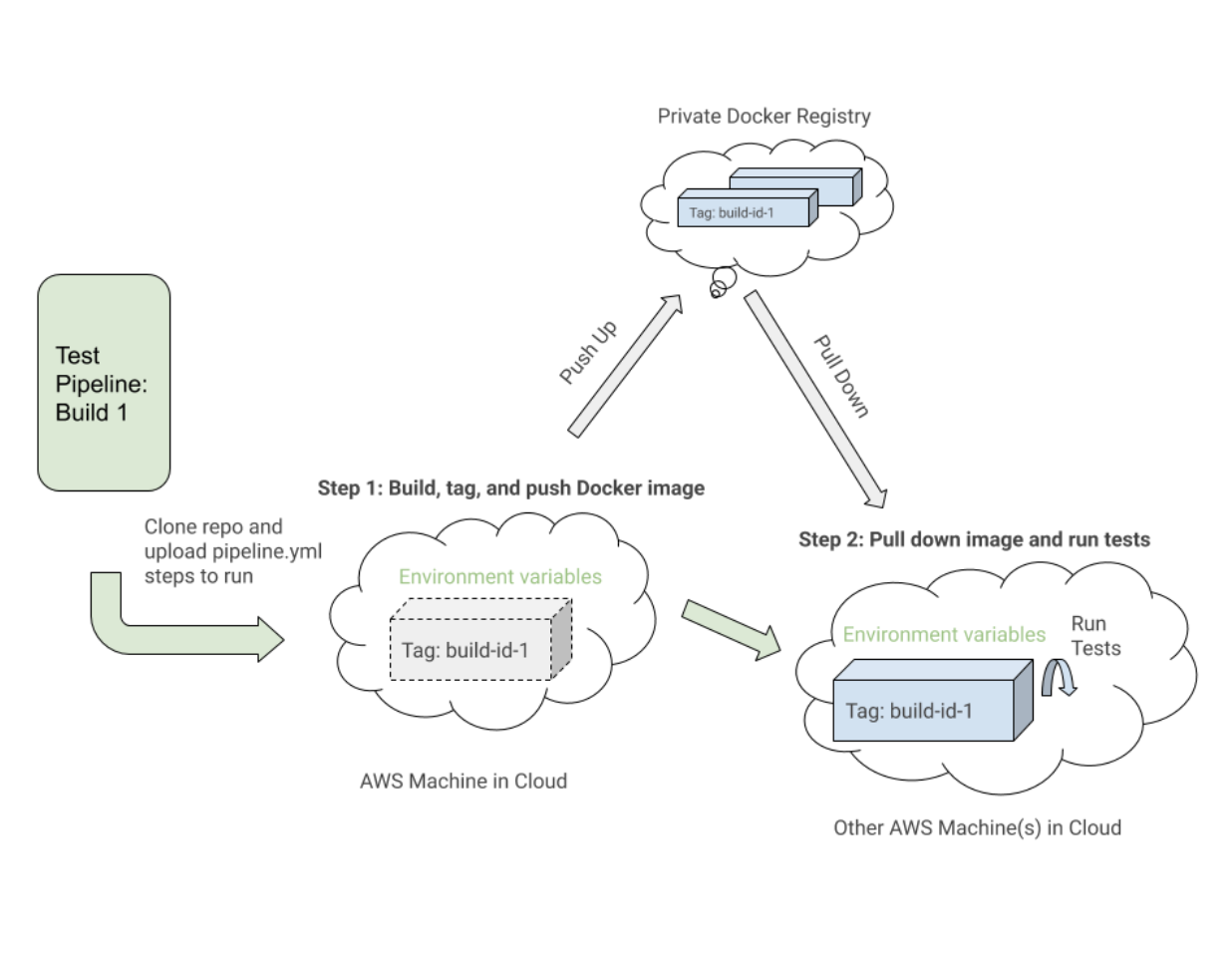
这是一个pipeline.uitests.yml文件的示例,该文件演示了在“构建 UITests Docker 映像”步骤中设置 Docker 映像并在“针对 Chrome 运行 Webdriver 测试”步骤中运行测试:
需要注意的一点是第一步,“构建 UITests Docker 映像”,以及它如何为测试设置 Docker 映像。 它使用 Docker Compose build命令来构建带有所有应用程序测试代码的uitests服务,并使用latest和${VERSION}环境变量对其进行标记,以便我们最终可以在未来为该构建拉取具有适当标签的相同图像步。
每个步骤都可能在 AWS 云中某处的不同机器上执行,因此标签唯一地标识特定 Buildkite 运行的映像。 标记图像后,我们将最新和版本标记的图像推送到我们的私有 Docker 注册表以供重用。
在“针对 Chrome 运行 Webdriver 测试”步骤中,我们拉下我们在第一步中构建、标记和推送的映像,并启动 Selenium Hub、Chrome 和测试服务。 基于诸如$UITESTENV和$UITESTSUITE之类的环境变量,我们将选择要运行的命令类型,例如npm run uitest:以及为此特定 Buildkite 构建运行的测试套件,例如--suite $UITESTSUITE 。
这些环境变量将通过 Buildkite 管道设置进行设置,或者从 Bash 脚本动态触发,该脚本将解析 Buildkite 选择字段以确定要运行哪些测试套件以及针对哪个环境运行。
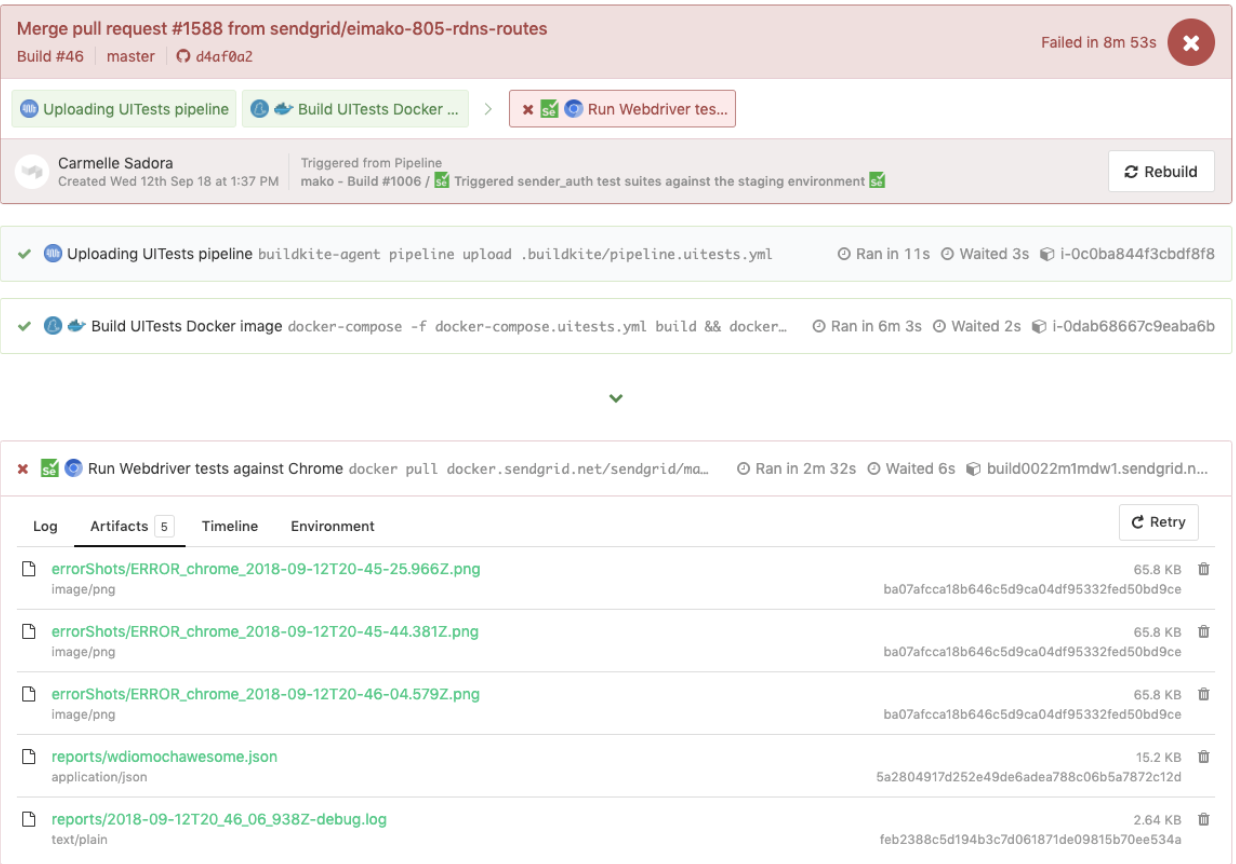
这是在专用测试管道中触发的 WebdriverIO 测试的示例,它也重用了相同的pipeline.uitests.yml文件,但在触发管道的位置设置了环境变量。 此构建失败并有错误屏幕截图供我们查看,供我们查看Artifacts选项卡和Logs选项卡下的控制台输出。 记住pipeline.uitests.yml中的artifact_paths (https://gist.github.com/alfredlucero/71032a82f3a72cb2128361c08edbcff2#file-pipeline-uitests-yml-L38),`wdio.conf.js 中`mochawesome`的截图设置` 文件(https://gist.github.com/alfredlucero/4ee280be0e0674048974520b79dc993a#file-wdio-conf-js-L39),并在 `docker-compose.uitests.yml` 中的 `uitests` 服务中安装卷(https://gist.github.com/alfredlucero/d2df4533a4a49d5b2f2c4a0eb5590ff8#file-docker-compose-yml-L32)?
我们能够连接屏幕截图,以便通过 Buildkite UI 访问,以便我们直接下载并立即查看,以帮助调试测试,如下所示。
下面显示了 WebdriverIO 测试的另一个示例,该测试使用pipeline.uitests.yml文件按计划针对特定页面在单独的管道中运行,但已在 Buildkite 管道设置中配置了环境变量。
重要的是要注意,每个 CICD 提供程序都有不同的功能和方法来在合并新代码时将步骤集成到某种部署过程中,无论是通过具有特定语法、GUI 设置、Bash 脚本或任何其他方式的.yml文件。
当我们从 Jenkins 切换到 Buildkite 时,我们极大地提高了团队在各自的代码库中定义自己的管道、按需跨扩展机器并行化步骤以及使用更易于阅读的命令的能力。
无论您使用哪个 CICD 提供程序,集成测试的策略在设置 Docker 映像和基于环境变量运行测试方面都是相似的,以实现可移植性和灵活性。
与 WebdriverIO 的权衡
在将大量自定义 Ruby Selenium 解决方案测试转换为 WebdriverIO 测试并与 Docker 和 Buildkite 集成后,我们在某些方面有所改进,但仍然感到与旧系统类似的挣扎,最终导致我们在 Cypress 的下一个也是最后一站我们的端到端测试解决方案。
以下是我们从使用 WebdriverIO 的经验中发现的与自定义 Ruby Selenium 解决方案相比的一些优点列表:
- 测试是纯粹用 JavaScript 或 TypeScript 而不是 Ruby 编写的。 这意味着每次编写 E2E 测试时语言之间的上下文切换和重新学习 Ruby 的时间都会减少。
- 我们将测试与应用程序代码放在一起,而不是放在 Ruby 共享存储库中。 我们不再觉得依赖于其他团队的测试失败,而是更直接地拥有我们回购中功能的 E2E 测试所有权。
- 我们赞赏跨浏览器测试的选项。 借助 WebdriverIO,我们可以针对 Chrome、Firefox 和 IE 等不同功能或浏览器进行测试,尽管我们主要专注于针对 Chrome 运行测试,因为超过 80% 的用户通过 Chrome 访问了我们的应用程序。
- 我们接受了与第三方服务集成的可能性。 WebdriverIO 文档解释了如何与 BrowserStack 和 SauceLabs 等第三方服务集成,以帮助将我们的应用程序覆盖到所有设备和浏览器中。
- 我们可以灵活地选择我们自己的测试运行器、报告器和服务。 WebdriverIO 没有规定使用什么,因此每个团队都可以自由决定是否使用 Mocha 和 Chai 或 Jest 等服务。 这也可以解释为一个缺点,因为团队开始偏离彼此的设置,并且需要大量时间来试验我们选择的每个选项。
- WebdriverIO API、CLI 和文档足以编写测试并与 Docker 和 CIC D 集成。我们可以有许多不同的配置文件,对规范进行分组,通过命令行执行测试,并按照页面对象模式编写测试。 但是,文档可能更清晰,我们不得不挖掘很多奇怪的错误。 尽管如此,我们还是能够从 Ruby Selenium 解决方案转换我们的测试。
我们在之前的 Ruby Selenium 解决方案中缺乏的很多领域取得了进展,但是我们遇到了很多阻碍我们使用 WebdriverIO 的阻碍,例如:
- 由于 WebdriverIO 仍然是基于 Selenium 的,我们经历了很多奇怪的超时、崩溃和错误,提醒我们旧的 Ruby Selenium 解决方案的负面闪回。 有时,当我们在页面上选择许多元素时,我们的测试会完全崩溃,并且测试会运行得比我们想要的慢。 我们不得不通过很多 Github 问题找出解决方法,或者在编写测试时避免使用某些方法。
- 整体的开发者体验不是最理想的。 该文档提供了一些命令的高级概述,但没有足够的示例来解释所有使用它的方法。 我们避免使用 Ruby 编写 E2E 测试,最终使用 JavaScript 或 TypeScript 编写测试,但 WebdriverIO API 处理起来有点混乱。 一些常见的例子是
$与$$用于单数与复数元素,$('...').waitForVisible(9000, true)用于等待元素不可见,以及其他不直观的命令。 我们经历了很多不稳定的选择器,不得不为所有东西显式地$(...).waitForVisible()。 - 对于开发人员和 QA 来说,调试测试非常痛苦和乏味。 Whenever tests failed, we only had screenshots, which would often be blank or not capturing the right moment for us to deduce what went wrong, and vague console error messages that did not point us in the right direction of how to solve the problem and even where the issue occurred. We often had to re-run the tests many times and stare closely at the Chrome browser running the tests to hopefully put things together as to where in the code our tests failed. We used things like
browser.debug()but it often did not work or did not provide enough information. We gradually gathered a bunch of console error messages and mapped them to possible solutions over time but it took lots of pain and headache to get there. - WebdriverIO tests were tough to set up with Docker . We struggled with trying to incorporate it into Docker as there were many tutorials and ways to do things in articles online, but it was hard to figure out a way that worked in general. Hooking up 2 to 3 services together with all these configurations led to long trial and error experiments and the documentation did not guide us enough in how to do that.
- Choosing the test runner, reporter, assertions, and services demanded lots of research time upfront . Since WebdriverIO was flexible enough to allow other options, many teams had to spend plenty of time to even have a solid WebdriverIO infrastructure after experimenting with a lot of different choices and each team can have a completely different setup that doesn't transfer over well for shared knowledge and reuse.
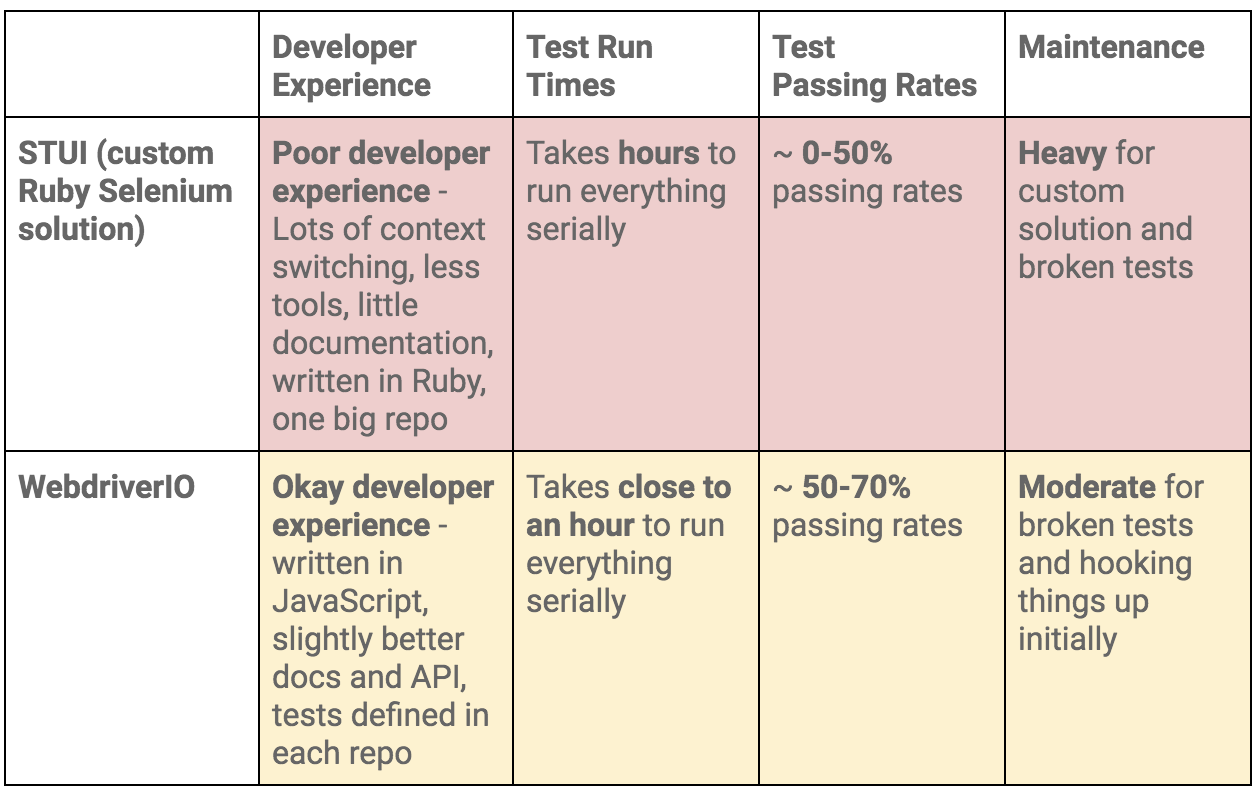
To summarize our WebdriverIO and STUI comparison, we analyzed the overall developer experience (related to tools, writing tests, debugging, API, documentation, etc.), test run times, test passing rates, and maintenance as displayed in this table:
Moving On to Cypress
At the end of the day, our WebdriverIO tests were still flaky and tough to maintain. More time was still spent debugging tests in dealing with weird Selenium issues, vague console errors, and somewhat useful screenshots than actually reaping the benefits of seeing tests fail for when the backend or frontend encountered issues.
We appreciated cross-browser testing and implementing tests in JavaScript, but if our tests could not pass consistently without much headache for even Chrome, then it became no longer worth it and we would then simply have a STUI 2.0.
With WebdriverIO we still strayed from the crucial aspect of providing a way to write consistent, debuggable, maintainable, and valuable E2E automation tests for our frontend applications in our original goal. Overall, we learned a lot about integrating with Buildkite and Docker, using page objects, and outlining tests in a structured way that will transfer over to our final solution with Cypress.
If we felt it was necessary to run our tests in multiple browsers and against various third-party services, we could always circle back to having some tests written with WebdriverIO, or if we needed something fully custom, we would revisit the STUI solution.
Ultimately, neither solution met our main goal for E2E tests, so follow us on our journey in how we migrated from STUI and WebdriverIO to Cypress in part 2 of the blog post series.