
Apache Spark:大数据苍穹中的耀眼明星。
已发表: 2015-09-24- 向合适的客户推荐数百万种产品。
- 跟踪搜索历史并提供航班旅程的折扣价。
- 比较人员的技术技能并适当地建议与您所在领域的人员建立联系。
- 了解数十亿移动对象、网络信号塔和呼叫交易的模式,计算电信网络优化或查找网络漏洞。
- 研究数以百万计的传感器特征并分析传感器网络中的故障。
为上述所有任务获得正确结果所需的基础数据相对较大。 传统系统无法有效地处理它(在空间和时间方面)。
这些都是大数据场景。
为了收集、存储和计算这种海量数据,我们需要一个专门的集群计算系统。 Apache Hadoop为我们解决了这个问题。
它提供了分布式存储系统(HDFS)和并行计算平台(MapReduce)。
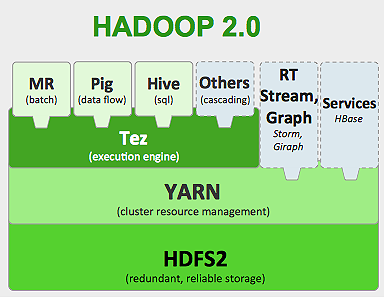
Hadoop 框架的工作原理如下:
- 将大数据文件分解成更小的块,由单个机器处理(分布式存储)。
- 将较长的作业分成较小的任务以并行方式执行(并行计算)。
- 自动处理故障。
Hadoop的局限性
Hadoop在其生态系统中有专门的工具来执行不同的任务。 因此,如果您想运行应用程序的端到端生命周期,您需要使用多种工具。 例如,对于SQL查询,您将使用hive/pig ,对于流式源,您必须使用Hadoop 内置流或 Apache Storm (它不是 Hadoop 生态系统的一部分),或者对于机器学习算法,您必须使用Mahout 。 将所有这些系统集成在一起以构建单个数据管道用例是一项艰巨的任务。
在MapReduce作业中,
- 所有地图任务输出都被转储到本地磁盘(或 HDFS)上。
- Hadoop 将所有溢出文件合并为一个更大的文件,该文件根据减速器的数量进行排序和分区。
- 并且减少任务必须再次将其加载到内存中。
此过程使作业变慢,导致磁盘 I/O 和网络 I/O。 这也使得 Mapreduce 不适合迭代处理,您必须一遍又一遍地将机器学习算法应用于同一组数据。
进入 Apache Spark 的世界:
Apache Spark于 2009 年在加州大学伯克利分校 AMPLAB开发,并在 2010 年成为 Apache 迄今为止贡献最大的开源项目。
Apache Spark是更通用的系统,您可以在其中一次运行批处理和流式作业。 它通过添加在内存中更快地处理数据的功能,在速度上取代了其前身 MapReduce。 它在磁盘上的效率也更高。 它利用其基本数据单元RDD(弹性分布式数据集)进行内存处理。 它们在内存中保存尽可能多的数据集,以实现作业的完整生命周期,从而节省磁盘 I/O。 在内存上限之后,某些数据可能会溢出磁盘。
下图显示了 Apache Hadoop 和 Spark 用于计算逻辑回归的运行时间(以秒为单位)。 Hadoop 用了 110 秒,而 spark 只用了 0.9 秒完成了同样的工作。
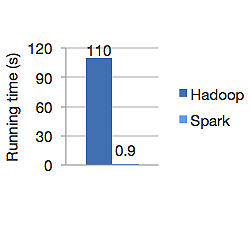
Spark 不会将所有数据存储在内存中。 但是如果数据在内存中,它会充分利用 LRU 缓存来更快地处理它。 在内存中计算数据时,它比 Hadoop 在磁盘上快 100 倍。
Spark 的分布式数据存储模型,弹性分布式数据集 (RDD),保证容错,从而最大限度地减少网络 I/O。 火花纸 说:

“RDD 通过沿袭的概念实现容错:如果 RDD 的一个分区丢失,RDD 有足够的信息来说明它是如何从其他 RDD 派生的,以便能够仅重建该分区。”
所以你不需要复制数据来实现容错。
在 Spark MapReduce 中,mappers 的输出保存在 OS 缓冲区缓存中,reducers 将其拉到自己的一侧并直接写入内存,这与 Hadoop 不同,Hadoop 的输出会溢出到磁盘并再次读取。
Spark 的内存缓存使其适用于需要反复使用相同数据的机器学习算法。 Spark 可以使用直接无环图 (DAG) 运行复杂的作业、多步骤数据管道。
Spark 是用 Scala 编写的,它运行在 JVM(Java 虚拟机)上。 Spark 为 Java、Scala、Python 和 R 语言提供开发 API。 Spark 在 Hadoop YARN、Apache Mesos 上运行,并且拥有自己的独立集群管理器。
2014 年,它在短短 23 分钟内获得了对 100TB 数据(1 万亿条记录)基准进行排序的世界纪录第一名,而雅虎之前的 Hadoop 记录约为 72 分钟。 这证明 spark 排序数据的速度提高了 3 倍,机器数量减少了 10 倍。 所有排序都发生在磁盘 (HDFS) 上,实际上没有使用 spark 内存缓存功能。
星火生态系统
Spark 旨在一次性进行高级分析,以实现它提供以下组件:
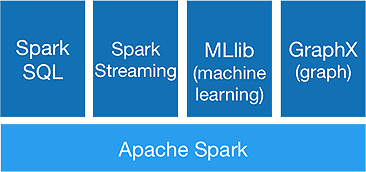
1.火花芯:
Spark 核心 API 是 Apache Spark 框架的基础,它处理作业调度、任务分配、内存管理、I/O 操作和故障恢复。 Spark中主要的逻辑数据单元称为RDD(Resilient Distributed Dataset),它以分布式的方式存储数据,以供以后并行处理。 它懒惰地计算操作。 因此,内存不必一直被占用,其他作业可以使用它。
2.火花SQL:
它提供了低延迟的交互式查询功能。 新的DataFrame API 可以保存结构化和半结构化数据,并允许所有 SQL 操作和函数进行计算。
3.火花流:
它提供实时流 API ,以微批次的形式收集和处理数据。
它使用Dstreams ,它只是 RDD 的连续序列,来计算传入数据的业务逻辑并立即生成结果。
4.MLlib :
它是spark 的机器学习库(几乎比 Mahout 快 9 倍),提供机器学习以及分类、回归、协同过滤等统计算法。
5.GraphX :
GraphX API 提供处理图形和执行图形并行计算的功能。 它包括像 PageRank 这样的图算法和各种分析图的函数。
Spark 会标志着 Hadoop 时代的终结吗?
Spark 仍然是一个年轻的系统,不如 Hadoop 成熟。 没有像 HBase 这样的 NOSQL 工具。 考虑到更快的数据处理需要高内存,你不能说它在商用硬件上运行。 Spark 没有自己的存储系统。 它依赖于 HDFS。
因此,Hadoop MapReduce 仍然适用于某些不包含太多数据管道的批处理作业。
“新技术永远不会完全取代旧技术; 他们都宁愿共存。”
结论
在这篇博客中,我们探讨了为什么需要像 Spark 这样的工具,是什么让它更快的集群计算系统及其核心组件。 下一部分我们将深入了解 Spark 核心 API RDD、转换和操作。