
与十亿封电子邮件共进早餐
已发表: 2020-02-05我们只要求一个顺利的黑色星期五
当我在黑色星期五周末每天早上 8 点左右在太平洋标准时间 (PST) 吃早餐时,Twilio SendGrid 已经处理了超过 1B 封以美国东部标准时间 (EST) 计算的电子邮件。
查看统计数据,我们从感恩节到网络星期一处理了超过 16.5B 的电子邮件,从感恩节前的星期二开始的一周处理了超过 22.3B 的电子邮件。 这些对企业来说确实是很好的数字。 从工程组织的角度来看,在没有任何警报触发或任何降级客户体验的情况下这样做是非常令人满意的。
我建议阅读这篇由我的同事 Sara Saedinia 撰写的博客文章,在一天内为超过 40 亿封电子邮件扩展我们的基础架构,其中谈到了以这种规模顺利运营对我们的业务和依赖我们的企业的重要性。 在这里,我将重点介绍我们的准备工作,这些准备工作使我们的电子邮件客户今年最关键的周末成为迄今为止最顺利的周末。
我们是如何让这成为一个无缝的黑色星期五周末? 在我们根据遥测观测验证系统改进时,处理我们最大的发送日需要勤奋的计划、大量的区域摆动测试、数十人分析数据以及收紧反馈循环。 我们仍将进行更多自动化和改进,以确保我们继续让客户满意,并确保我们迅速将正确的通信发送给正确的收件人。
了解我们的业务
SendGrid 的业务模型要求我们始终处于运行状态——我们没有用于接收和传递邮件的维护窗口。 我们的客户需要可靠的服务,能够不间断地接收和递送邮件。 这意味着我们所有的基础设施更改、硬件和软件都需要在我们继续处理和发送电子邮件的同时完成,没有任何明显的延迟。
如下图所示,我们处理的电子邮件数量在过去几年中大幅增长。
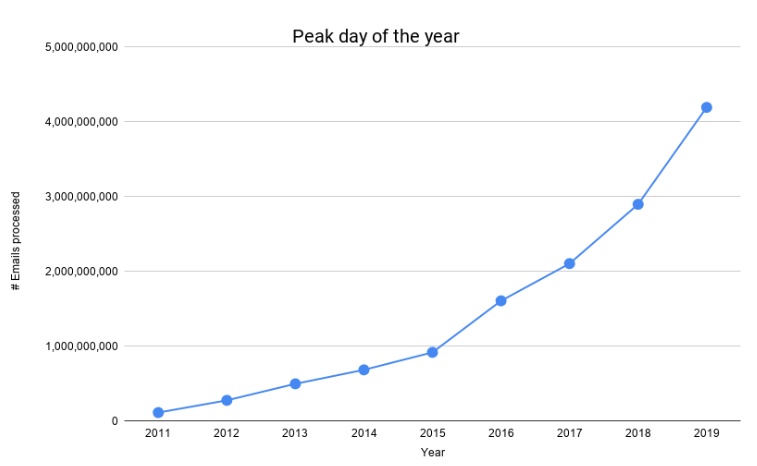
我们在 2016 年年中度过了第一个 1B 日,而在这个黑色星期五我们度过了第一个 4B 日。 在不到 4 年的时间里增长了 400%。 考虑到我们不断扩大的规模,保持我们的成本可控,并为我们的客户提供更高的可靠性,我们不得不重新设计和发展我们的邮件处理管道。
黑色星期五来了
人们问我,“为什么黑色星期五和网络星期一对你如此重要?” 这个网络星期一,我们处理的电子邮件比去年的峰值多 45%。 黑色星期五是美国最重要的零售和消费活动之一。 传统上,这一天是零售商全年盈利(净正数)的日子。 电子邮件营销和交易电子邮件的使用已成为所有企业的关键。
从零售商到提供营销自动化的企业,在黑色星期五周末无法可靠地发送电子邮件可能会导致重大的收入损失。 因此,这个周末对我们来说通常是一个决定业务的周末。 我们尽最大努力为我们的工程师、支持代理、客户成功经理、高管,最重要的是,为我们的客户提供尽可能简单的服务。
为黑色星期五做准备
那么我们如何为黑色星期五做准备呢? 我们买T恤! (并做大量工作。)继续阅读我们如何准备。
Twilio SendGrid 尔湾办事处的成员

Twilio SendGrid 丹佛办事处的一些成员。

统计数据
让我们从一些统计数据开始:
- 在黑色星期五处理 4.1B+ 电子邮件,在网络星期一处理 4.2B+ 电子邮件
- 从感恩节到网络星期一处理了 16.5B+ 封电子邮件
- 在高峰时段处理了 3.15 亿多封电子邮件
- 黑色星期五和网络星期一,每个连续 8 小时处理 2.2 亿封或更多电子邮件
- 所有这一切,可交付电子邮件的中位端到端时间为 1.9 秒
- 平均而言,我们每条消息大约发出 5.5 个事件。 基于此,我们的系统发出并处理了从感恩节到网络星期一的 91B+ 事件,仅网络星期一就发出并处理了 23B+
挑战
前所未有的规模:我们要测试的规模必须与我们预测的峰值负载相匹配。 当我们在 4 月初对过去一年的准备工作进行第一次测试时,我们的平均工作日交易量还不到我们预测峰值的一半。 我们的每小时峰值甚至不到我们将要测试的一半。
管理我们的环境:电子邮件是一个有状态的工作流程:有必要跟踪消息的状态。 因此,当消息在管道中移动时,我们会跟踪它是否反弹或延迟,并防止重复。 因此,我们的邮件管道是混合云和本地架构,自动缩放并不是一个神奇的解决方案。 我们面临的挑战是在不影响客户成本的情况下,最大限度地提高数据中心服务的效率,同时准备处理海量峰值的能力。

缩放不是线性的:并非所有系统都是线性缩放的。 由于我们预测的规模比我们第一次开始测试时要高得多,我们不能仅仅通过一个简单的数学模型来计算我们的硬件需求。 同样重要的是要记住,盲目地扩展服务会使依赖项过载,而数据库等依赖项的扩展方式与我们的邮件传输代理 (MTA) 不同。
平衡我们的投资:随着我们不断创新,确保我们支持与电子邮件传递相关的客户需求,我们明白,如果我们的功能无法访问并按需要执行,我们的功能不会为我们的客户提供任何价值。 我们必须找到一个平衡点,并在测试、学习、升级和改进我们的系统方面进行适当的投资,以在我们的规模上保持可靠和弹性。 有效地这样做使我们能够继续投资于创新。
我们是怎么做的?
我们一起做,作为一个团队。 正如我们所说,手挽手。 从 4 月到 11 月,我们今年的准备工作涉及多个团队的 100 多名成员的参与。 对峰值预测进行建模、定义可观察性标准、从我们的观察中学习、设计必要的更改、规划和管理需要多个人的各种技能。
我们彼此信任,同时保持彼此诚实,保持专注并实现我们的目标。
一个有效且不断改进的过程是我们的朋友。
规划
我们有三个数据中心来处理客户的电子邮件。 为了规划一个未达到的规模,我们验证我们可以在只有两个数据中心可用的情况下处理我们的峰值预计流量。 为了满足我们的高可用性 SLA,我们的基础架构内置了区域故障转移。 这意味着我们有能力在区域之间对流量进行故障转移。
我们在全年以频繁的节奏利用此功能作为标准操作程序,并加速它作为我们努力证明我们能够在保持服务质量的同时服务黑色星期五/网络星期一高峰量的一部分。 如果系统遥测接近我们的服务级别目标 (SLO) 的阈值,我们能够快速利用多个区域来恢复名义状态。 然后,我们利用收集到的遥测数据来确定我们需要在哪里进行更改。
与此同时,我们已经开始审查和巩固我们的服务水平目标 (SLO),它为我们提供了系统可用性的精确数字目标和我们的服务水平指标 (SLI),它为我们提供了成功探测系统的频率。
观察、学习和交流
每次测试都提供了大量信息。 我们面临的挑战之一是有效地记录和交流轮换测试团队的观察结果,然后跨多个系统分析数据。 尽管我们有标准的团队仪表板,但每个成员都可以有他们观察到的特定内容。
我们开始与测试团队一起进行回顾,以分析为多个团队管理的多个服务转储的所有技术信息。 这些回顾很长,而且在大部分时间里,每次测试只对一两个团队有用。 我们最终转而使用 Slack Thread 进行复古笔记,每次测试节省了 10 个小时的会议时间。
我们的测试管理团队包括两名工程经理、一名架构师和一名高级工程师。 管理人员在规划和依赖管理方面发挥着关键作用,而更多的技术人员则帮助处理和分析端到端系统级别的信息。
基于对可用信息的分析,我们反复验证我们的 SLI 严格符合我们的 SLO。 我们微调了我们的警报并使某些关键警报更加敏感,以便提前识别任何潜在的系统降级。
优先级和实施
我们对提议的更改进行了票证,并且团队对这些票证进行了优先排序。 这里的第一个挑战是跨多个团队董事会管理这些票证。 另一个挑战是无情地将黑色星期五的工作与其他优先事项放在一起。
我们需要为我们的工程师提供创造性的自由,以提出解决难题的方法。 同时,我们必须确保这些解决方案符合我们的长期计划。 同样至关重要的是,我们始终意识到任何利益冲突,这意味着要避免任何可能反过来影响我们的短期解决方案。
验证已实施的更改将成为我们即将进行的测试的目标。
随着我们接近黑色星期五,保持和加快节奏是计划和执行方面的一项重大挑战。
加速度
进入 9 月后,我们开始每周进行多次压力测试。 这要求我们更快地识别、修复和验证问题。 它还为我们提供了更快的学习和适应周期。
除了如前所述的邮件管道的全面测试外,我们还同时开始对我们的支持服务进行压力测试。 在同一时期,我们开始与我们最大的客户之一进行负载测试,以确保我们的传入 geopod 能够在假期期间毫无顾虑地处理他们预期的突发发送。
由于工作时间长和管理工作的挑战,我们的团队已经筋疲力尽。 我们列出了必要时停止测试所需的最关键警报,并使它们更加敏感。 这使我们能够开始进行测试,而无需我们一大早就在场监控我们的系统。
小心加速
当我们接近 9 月底时,有人担心我们可能没有朝着正确的方向足够快地前进。 我们创建了一个老虎团队,一个可以跨多个团队处理任何票证的专家团队,以及一个日常工作流程更精简的团队。
我们对运营基础设施和邮件处理软件进行了重大改进,为黑色星期五做准备。 这些变化被明确优先考虑,团队必须相互配合。 对于将 SendGrid 放在首位的人来说,这是一次很棒的经历。 我们正在对应用程序、基础架构进行更改,并增加我们的硬件容量,同时以启动速度运行上市公司业务部门的核心引擎。 最重要的是,我们做到了这一切,并没有降低客户的服务体验。
未来的计划
我们花了很多时间为 2019 年黑色星期五做准备。今年的经验教训将帮助我们为 2020 年黑色星期五和网络星期一的大部分准备工作自动化。我们期待在无压力、创纪录的情况下又一个成功的一年- 为我们的客户和员工发送大量假期。