
使用无服务器框架、AWS 和 BigQuery 构建应用程序
已发表: 2021-01-28无服务器是指由云提供商管理和分配服务器和资源的应用程序。 这意味着云提供商动态分配资源。 该应用程序在一个可以由事件触发的无状态容器中运行。 上面的一个示例以及我们将在本文中使用的示例是关于AWS Lambda的。
简而言之,我们可以将“无服务器应用程序”确定为基于事件驱动的基于云的系统的应用程序。 该应用程序依赖于第三方服务、客户端逻辑和远程调用(直接将其称为 Function as a Service )。
为 Amazon AWS 安装和配置无服务器框架

1.无服务器框架
无服务器框架是一个开源框架。 它由一个命令行界面或 CLI 和一个托管仪表板组成,它为我们提供了一个完全无服务器的应用程序管理系统。 使用该框架可确保减少开销和成本,快速开发和部署并保护无服务器应用程序。
在继续安装无服务器框架之前,您必须先设置 NodeJS。 在大多数操作系统上很容易做到——您只需访问官方 NodeJS 站点即可下载并安装它。 记得选择高于 6.0.0 的版本。
安装后,您可以通过在控制台中运行node -v来确认 NodeJS 可用。 它应该返回您已安装的节点版本:
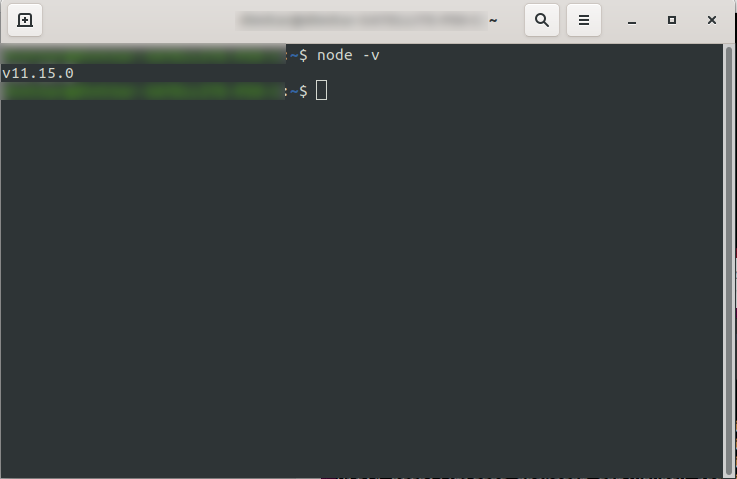
您现在可以开始了,所以继续安装无服务器框架。
为此,请按照文档设置和配置框架。 如果你愿意,你可以只为一个项目安装它,但在 DevriX,我们通常在全局安装框架: npm install -g serverless
等待该过程完成并通过运行以下命令确保 Serverless 已成功安装: serverless -v
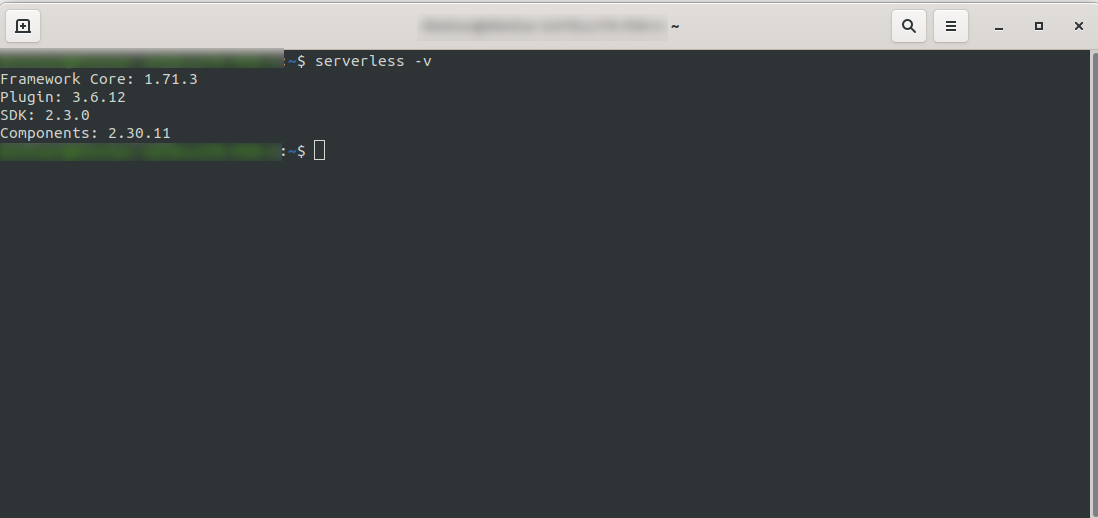
2. 创建亚马逊 AWS 账户
在继续创建示例应用程序之前,您应该在Amazon AWS中创建一个账户。 如果您还没有,只需前往 Amazon AWS 并单击右上角的“创建 AWS 帐户”并按照步骤创建帐户即可。
亚马逊要求您输入信用卡,因此您必须输入该信息才能继续操作。 成功注册并登录后,您应该会看到 AWS 管理控制台:
伟大的! 现在让我们继续创建您的应用程序。
3. 使用 AWS Provider 配置无服务器框架并创建示例应用程序
在这一步中,我们必须使用 AWS 提供商配置无服务器框架。 某些服务(例如 AWS Lambda)在您访问它们时需要凭证,以确保您有权访问该服务所拥有的资源。 AWS 建议使用 AWS Identity and Access Manager (IAM) 来完成此操作。
因此,首先也是最重要的事情是在AWS中创建一个IAM用户,以便在我们的应用程序中使用它:
在 AWS 控制台:
- 在“查找服务”字段中键入IAM 。
- 点击“IAM” 。
- 转到“用户” 。
- 点击“添加用户” 。
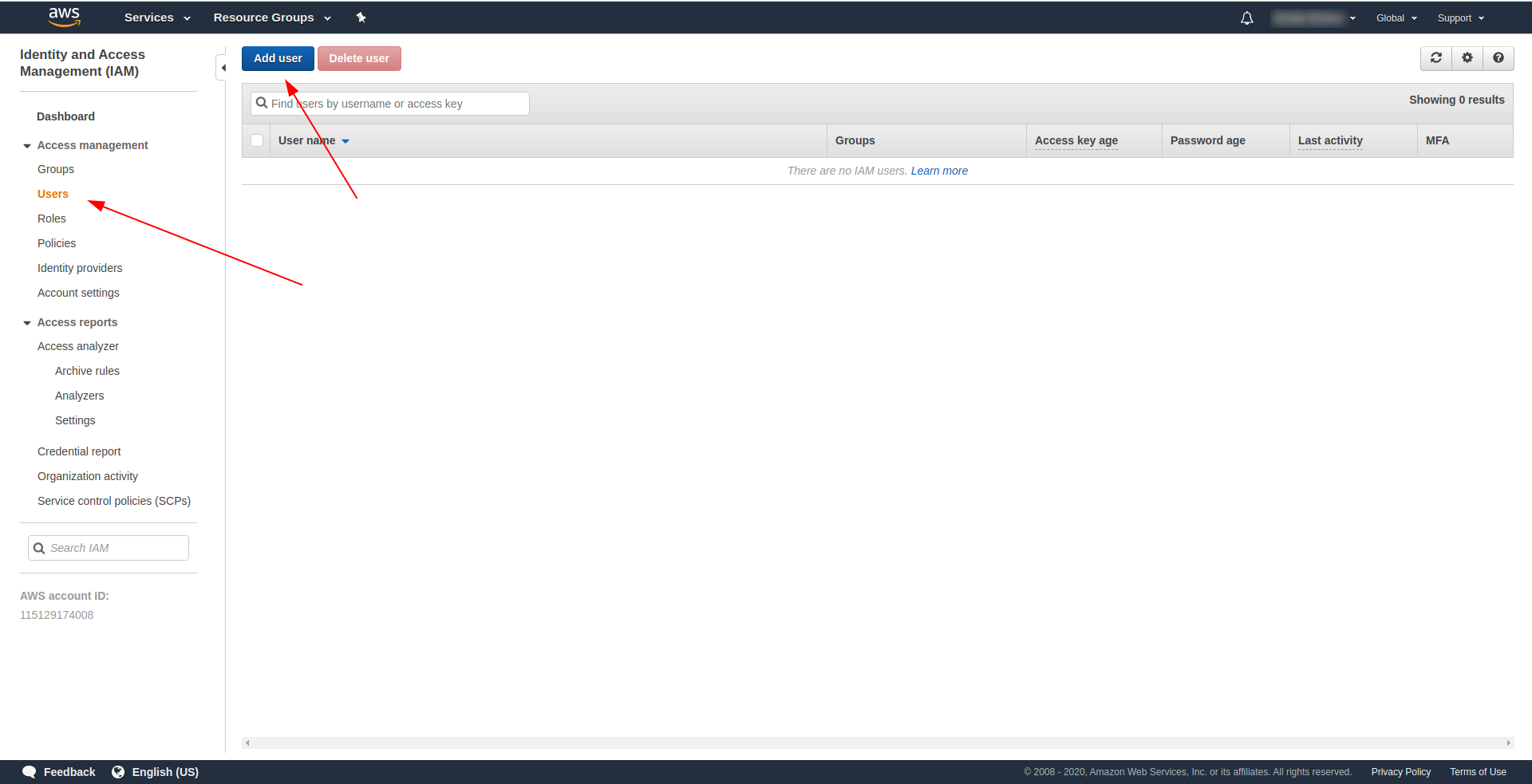
对于“用户名” ,使用任何你想要的。 例如,我们使用serverless-admin。 对于“访问类型” ,选中“程序访问” ,然后单击“下一步权限”。
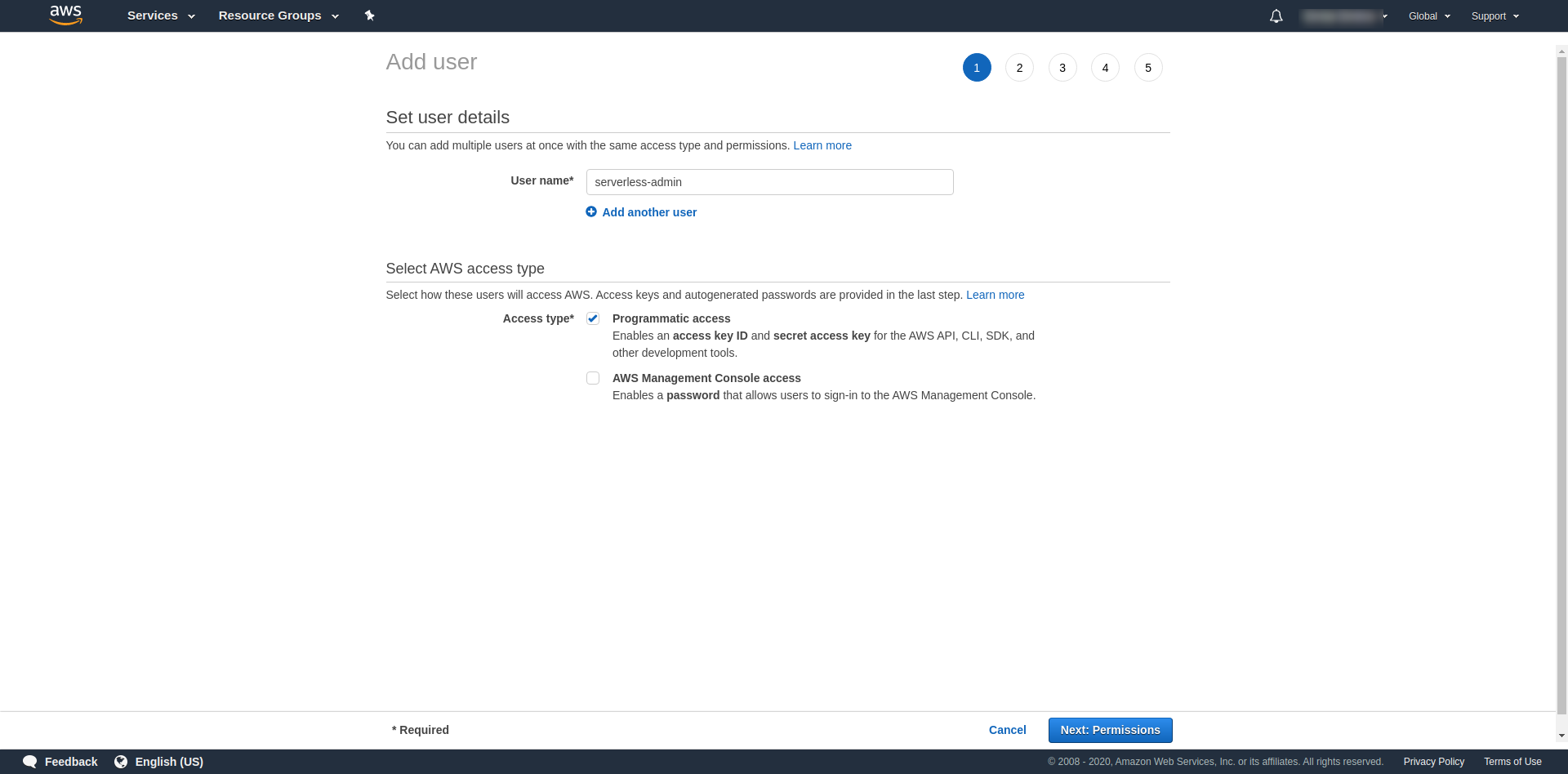
之后,我们必须为用户附加权限,单击“直接附加现有策略”,搜索“管理员访问”并单击它。 继续单击“下一个标签”
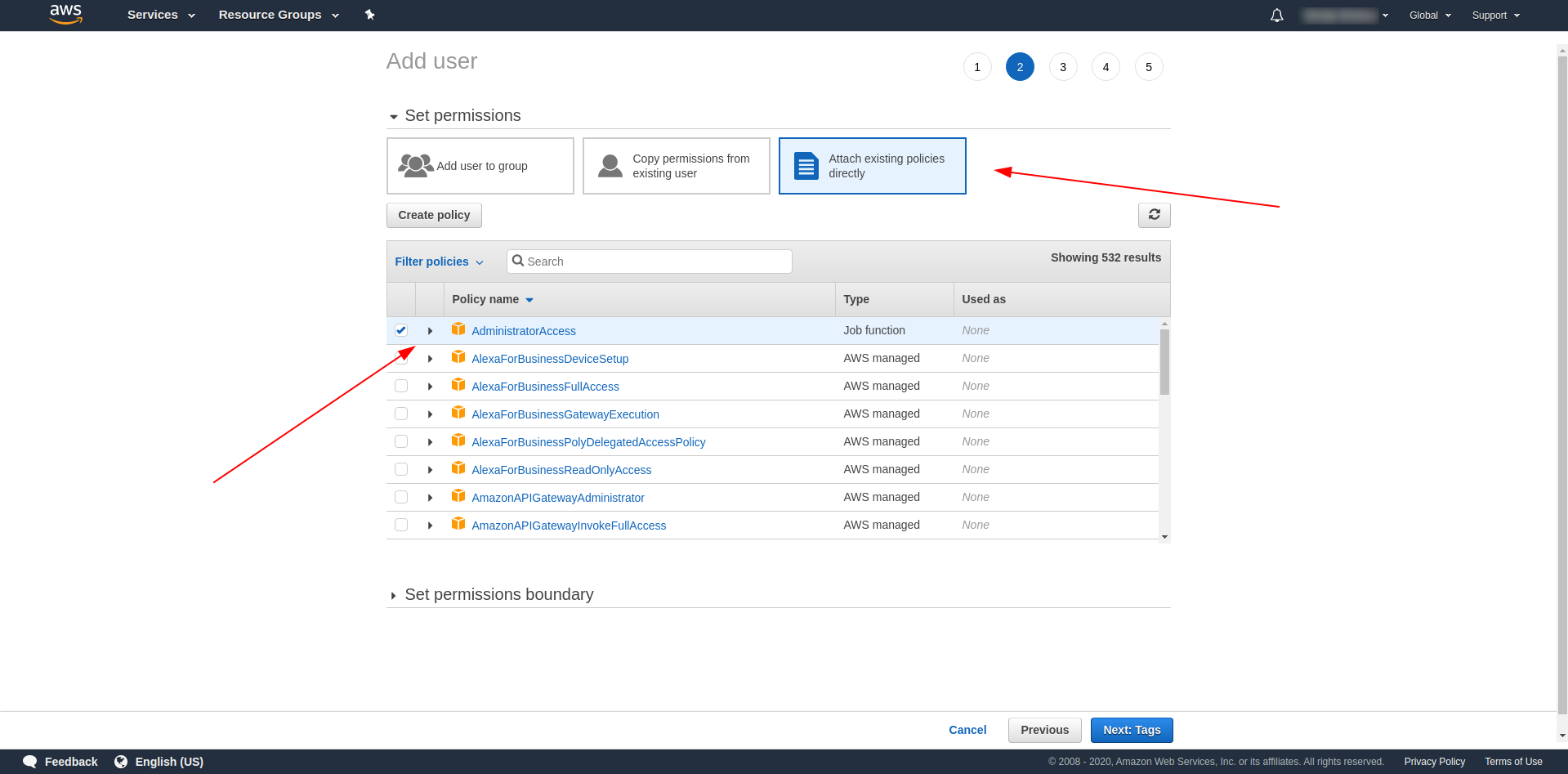
标签是可选的,因此您可以通过单击“下一个审核”和“创建用户”继续。 完成并加载后,页面上会显示一条成功消息,其中包含我们需要的凭据。
现在我们必须运行以下命令:
serverless config credentials --provider aws --key key --secret secret --profile serverless-admin
用上面提供的替换密钥和秘密。 您的 AWS 凭证被创建为配置文件。 您可以通过打开~/.aws/credentials文件来仔细检查。 它应该由 AWS 配置文件组成。 目前,在下面的示例中,它只有一个——我们创建的那个:
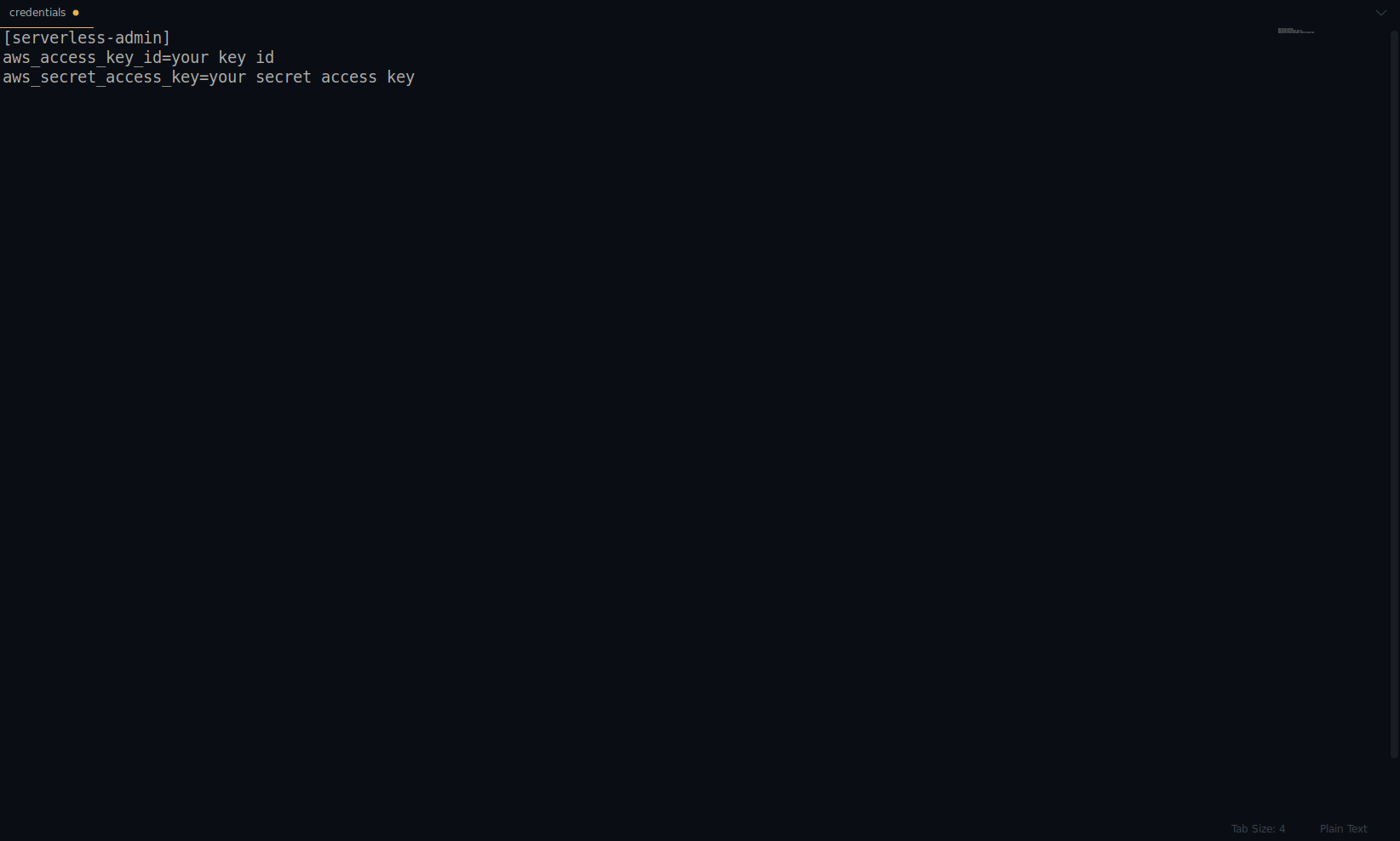
到目前为止做得很好! 您可以继续使用NodeJS和内置的启动模板创建一个示例应用程序。
注意:此外,在本文中,我们使用的是sls命令,它是serverless的缩写。
创建一个空目录并输入它。 运行命令
ls create --template aws-nodejs
使用create –template命令指定可用模板之一,在本例中为aws-nodejs,它是一个NodeJS “Hello world”模板应用程序。
完成后,您的目录应包含以下内容,如下所示:
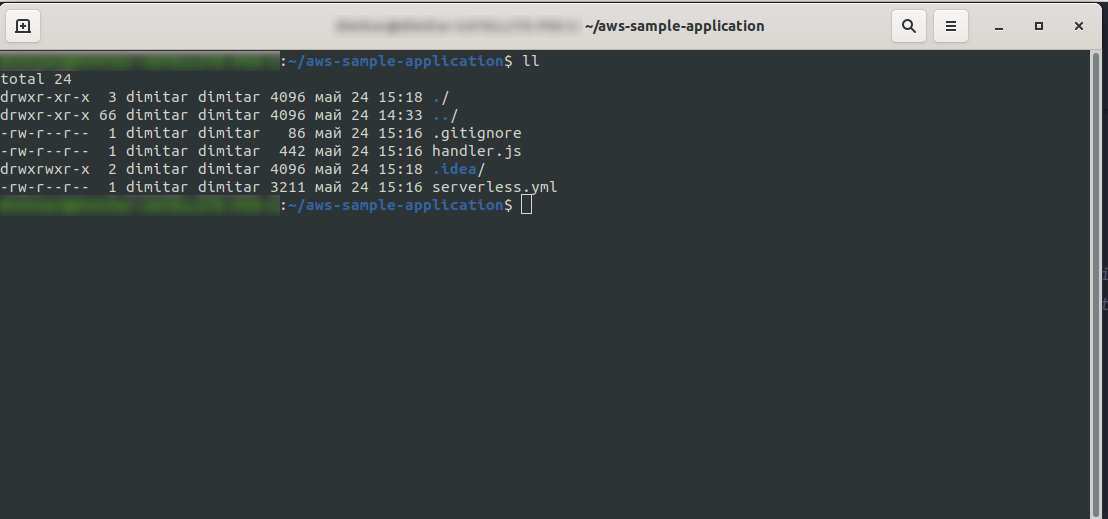
我们创建了新文件handler.js和serverless.yml 。
handler.js文件存储您的函数, serverless.yml存储您稍后将更改的配置属性。 如果您想知道.yml文件是什么,简而言之,它是一种人类可读的数据序列化语言。 熟悉它是件好事,因为在插入任何配置参数时都会用到它。 但是现在让我们看一下serverless.yml文件中的内容:
服务:aws-sample-application
提供者:
名称:aws
运行时:nodejs12.x
职能:
你好:
处理程序:handler.hello
- service: – 我们的服务名称。
- provider: – 一个包含提供者属性的对象,正如我们在这里看到的,我们的提供者是 AWS,我们使用的是 NodeJS 运行时。
- 函数: – 它是一个对象,包含可部署到 Lambda 的所有函数。 在这个例子中,我们只有一个名为hello的函数,它指向handler.js 的 hello 函数。
在继续部署应用程序之前,您必须在这里做一件关键的事情。 之前,我们使用配置文件(我们将其命名为serverless-admin )设置 AWS 的凭证。 现在您所要做的就是告诉无服务器配置使用该配置文件和您的区域。 打开serverless.yml并在运行时下方的provider属性下输入:
个人资料:无服务器管理员 地区:us-east-2
最后,我们应该有这个:
提供者: 名称:aws 运行时:nodejs12.x 个人资料:无服务器管理员 地区:us-east-2
注意:要获取区域,一个简单的方法是在您登录到控制台后查看 URL:示例:
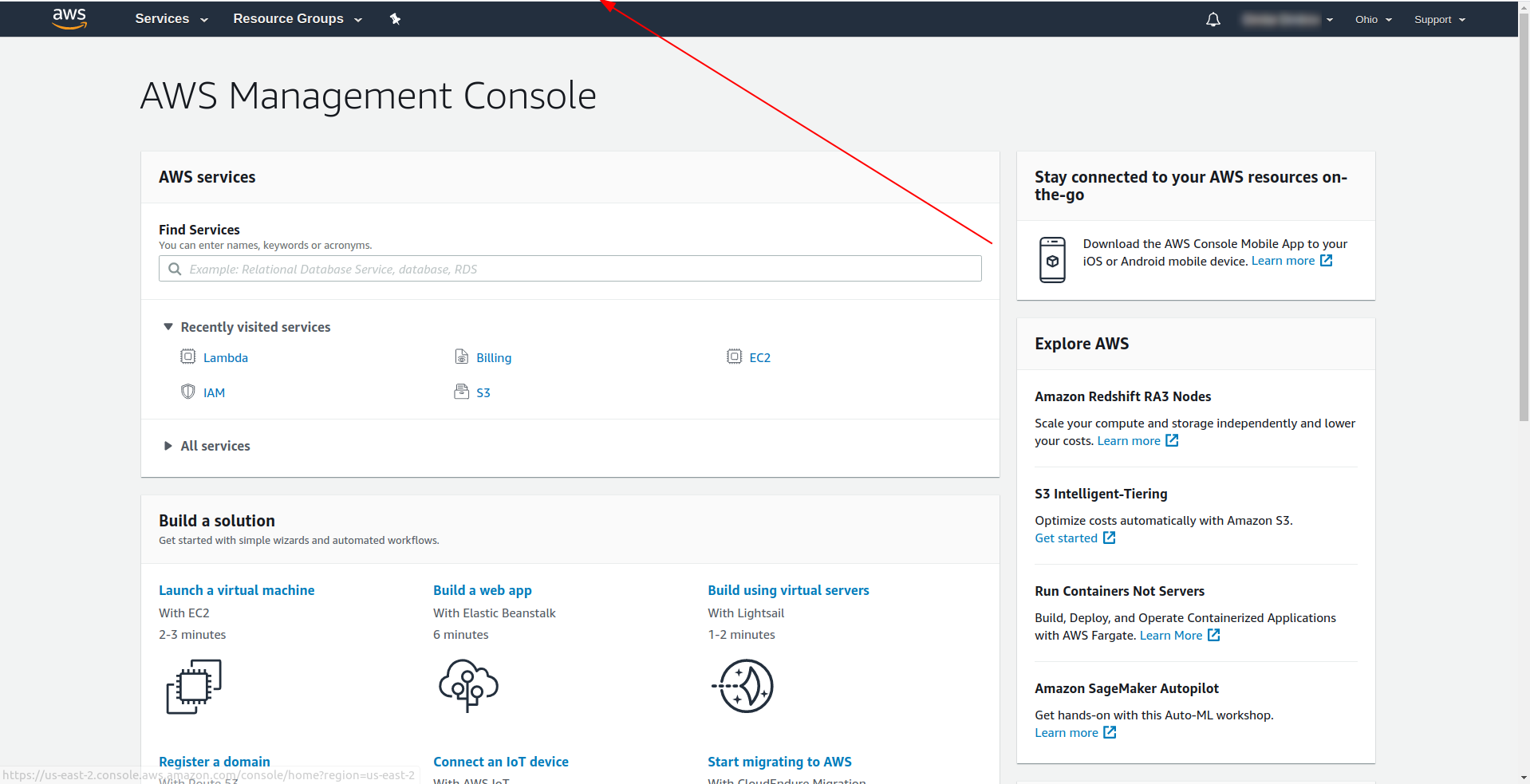
现在我们有了关于我们生成的模板的必要信息。 让我们检查一下如何在本地调用该函数并将其部署到 AWS Lambda。
我们可以通过在本地调用函数来立即测试应用程序:
sls invoke local -f hello
它调用函数(但仅在本地!),并将输出返回到控制台:
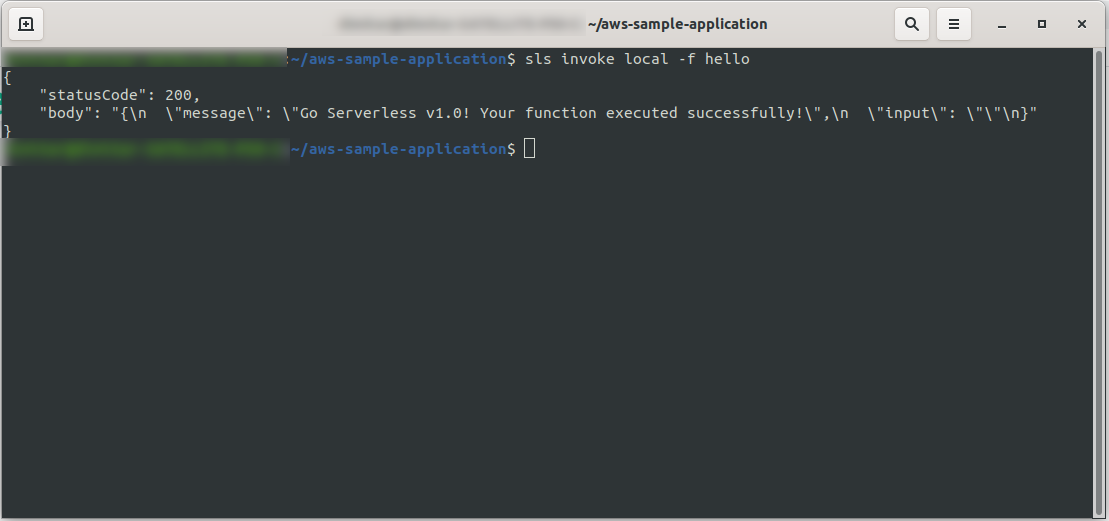
现在,如果一切正常,您可以尝试将您的函数部署到AWS Lambda 。
那么,有那么复杂吗? 不,不是! 感谢无服务器框架,它只是一行代码:
sls deploy -v
等待一切完成,可能需要几分钟,如果一切正常,您应该以这样的方式结束:
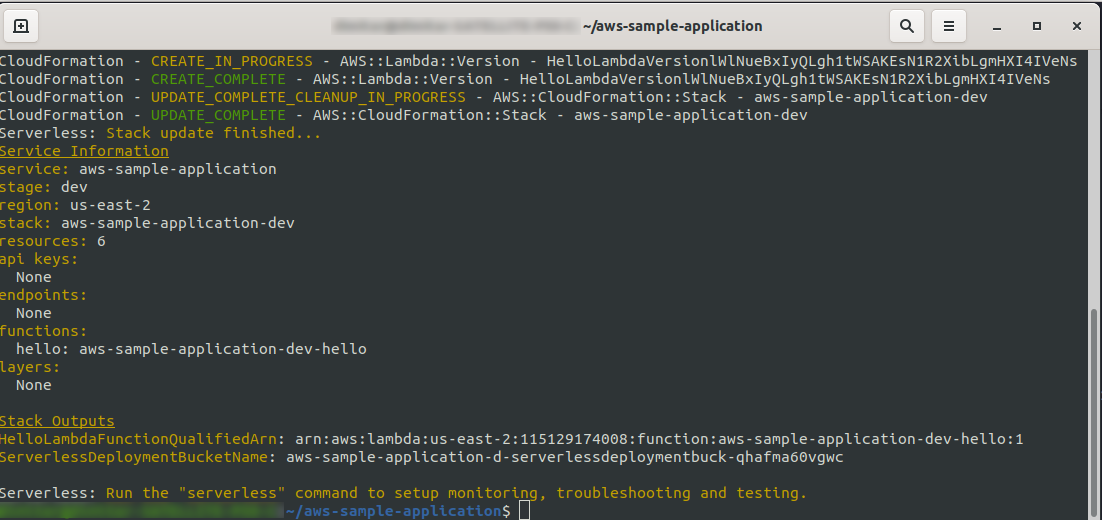
现在让我们检查一下 AWS 中发生了什么。 转到 Lambda(在“查找服务”类型Lambda中),您应该会看到您的Lambda函数已创建。
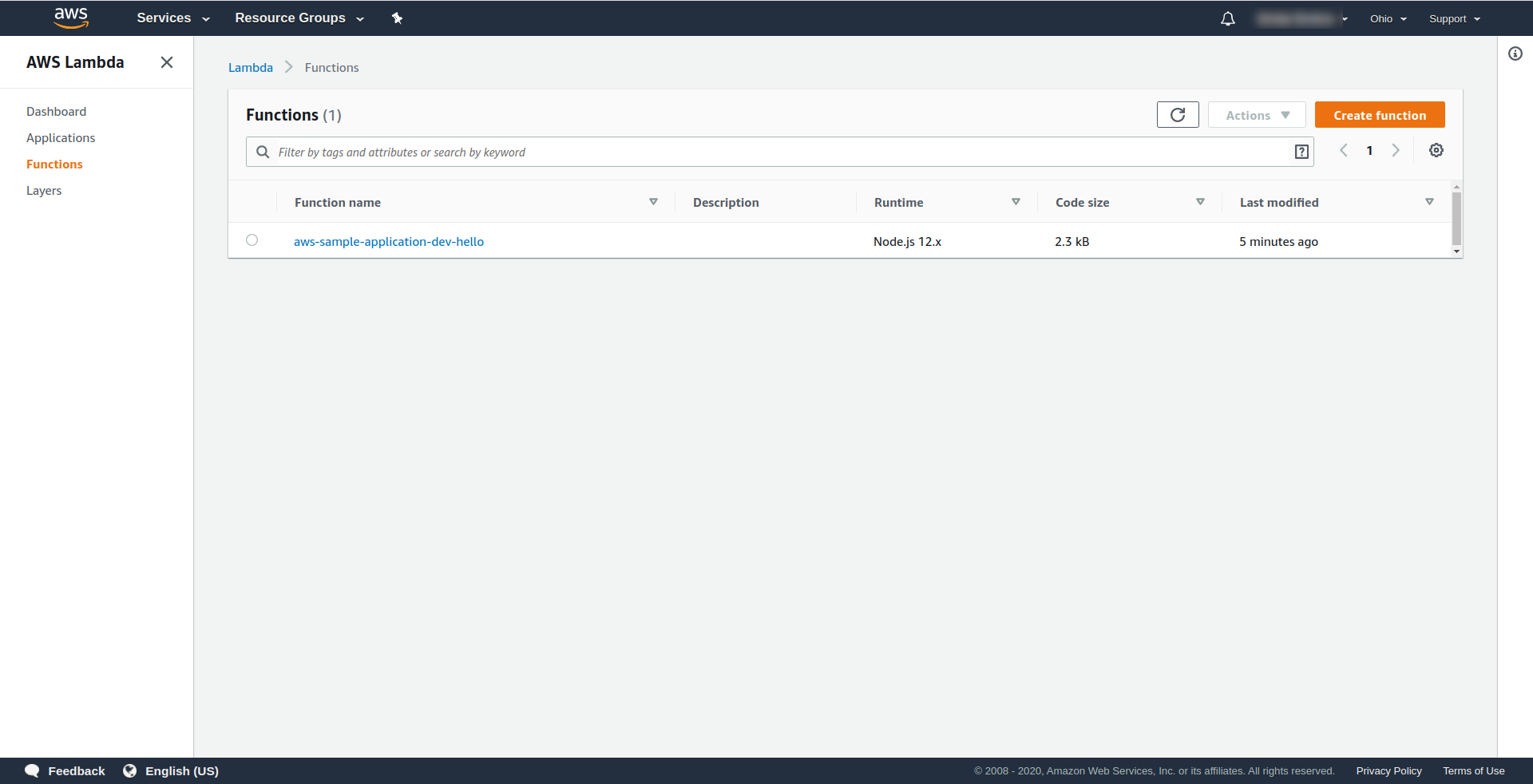
现在您可以尝试从 AWS Lambda 调用您的函数。 在终端类型sls invoke -f hello
它应该返回与之前相同的输出(当我们在本地测试时):
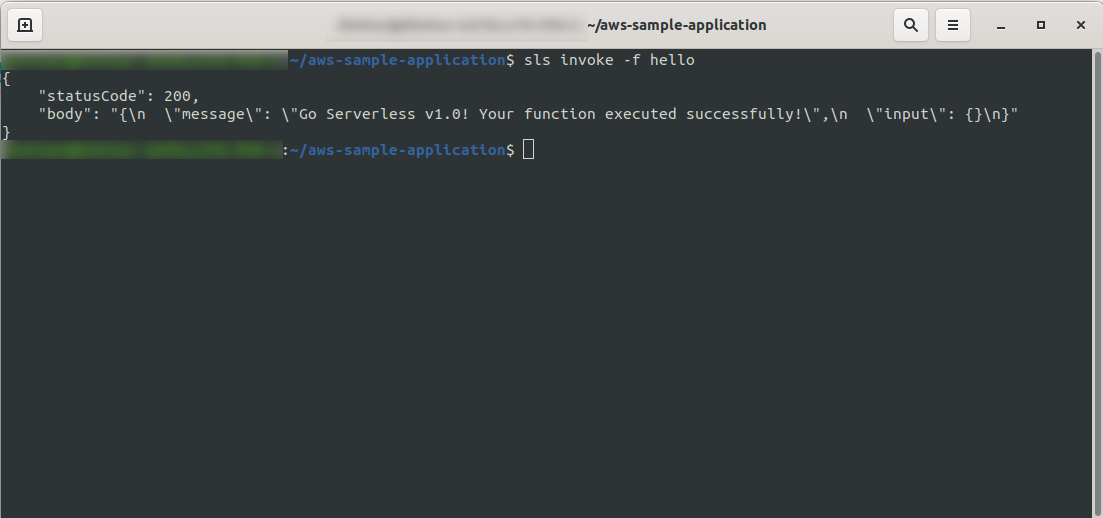
您可以通过在AWS Lambda中打开函数并转到“监控”选项卡并单击“在 CloudWatch 中查看日志”来检查是否已触发 AWS 的函数。 “。
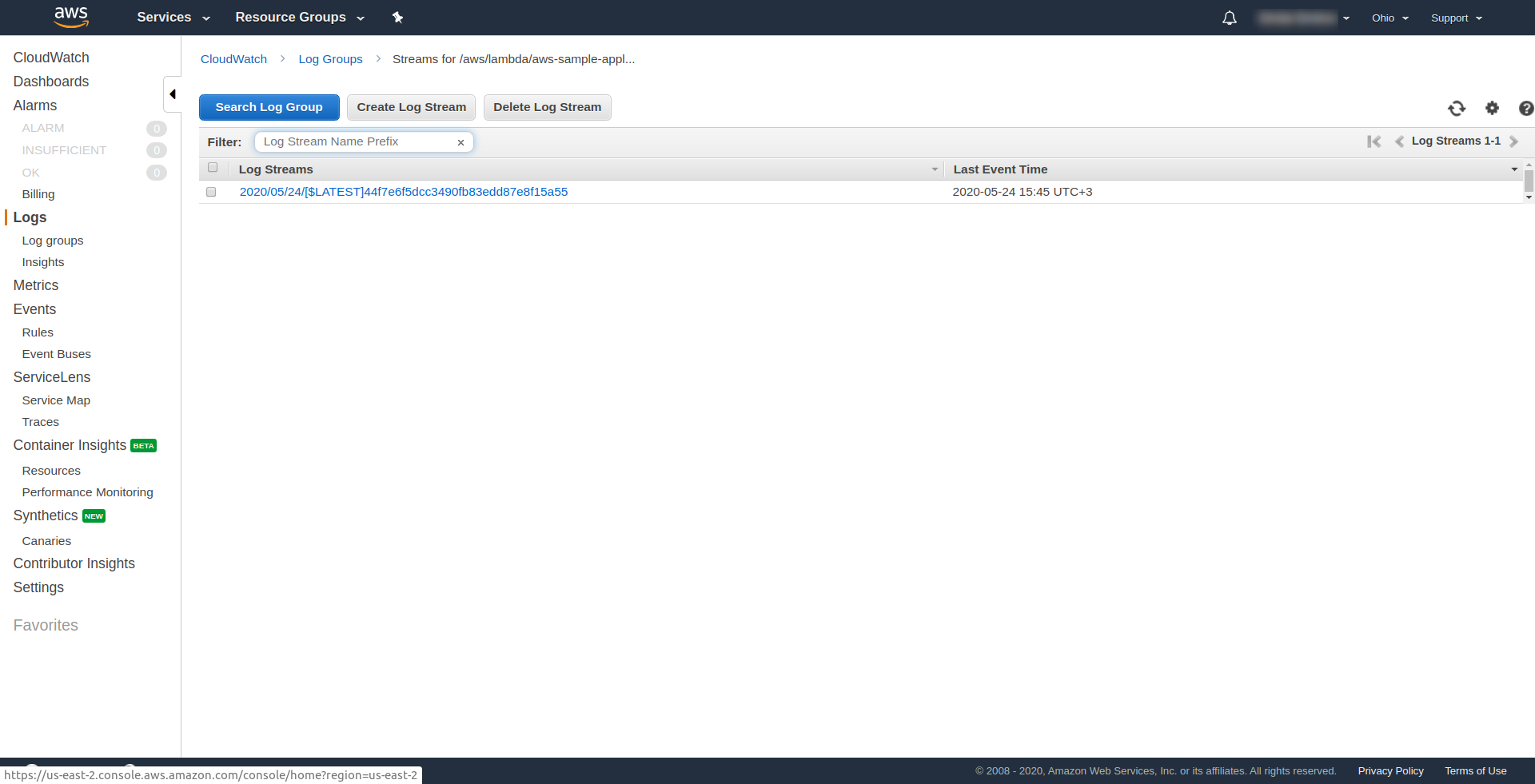
你应该在那里有一个日志。
现在,您的应用程序中仍然缺少一件事,但它是什么……? 好吧,您没有可以访问您的应用程序的端点,所以让我们使用AWS API Gateway 创建它。
您必须先打开serverless.yml文件并清除注释。 您需要在我们的函数及其http属性下添加一个events属性。 这告诉无服务器框架创建一个 API 网关,并在部署应用程序时将其附加到我们的 Lambda 函数。 我们的配置文件应该这样结束:
服务:aws-sample-application
提供者:
名称:aws
运行时:nodejs12.x
个人资料:无服务器管理员
地区:us-east-2
职能:
你好:
处理程序:handler.hello
事件:
- 网址:
路径:/你好
方法:获取
在http我们指定路径和 HTTP 方法。
就是这样,让我们通过运行sls deploy -v再次部署我们的应用程序
完成后,输出终端中应该会出现一件新事物,那就是已创建的端点:
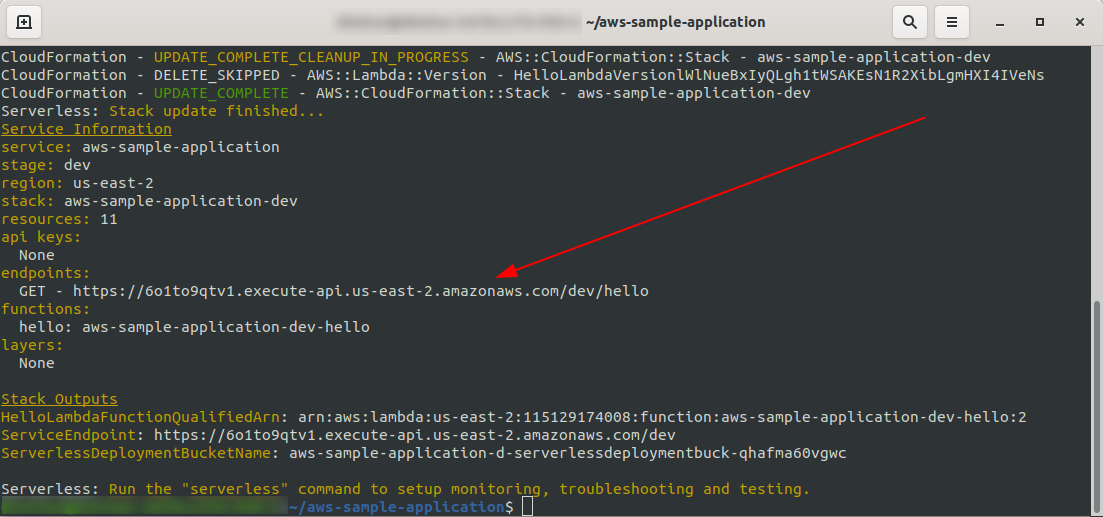
让我们打开端点:
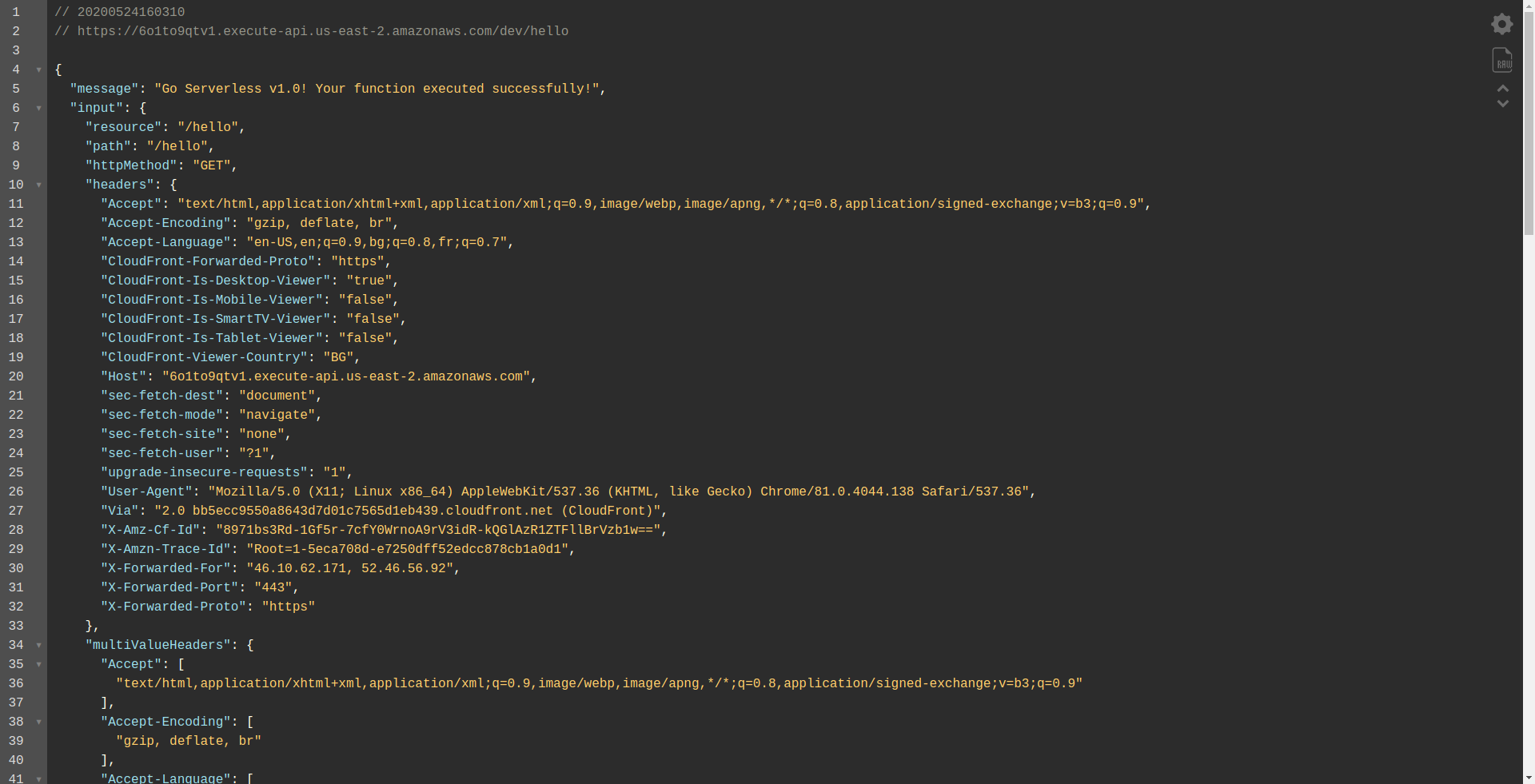
您应该看到您的函数正在执行、返回输出以及有关请求的一些信息。 让我们检查一下我们的 Lambda 函数发生了什么变化。
打开AWS Lambda ,然后单击您的函数。
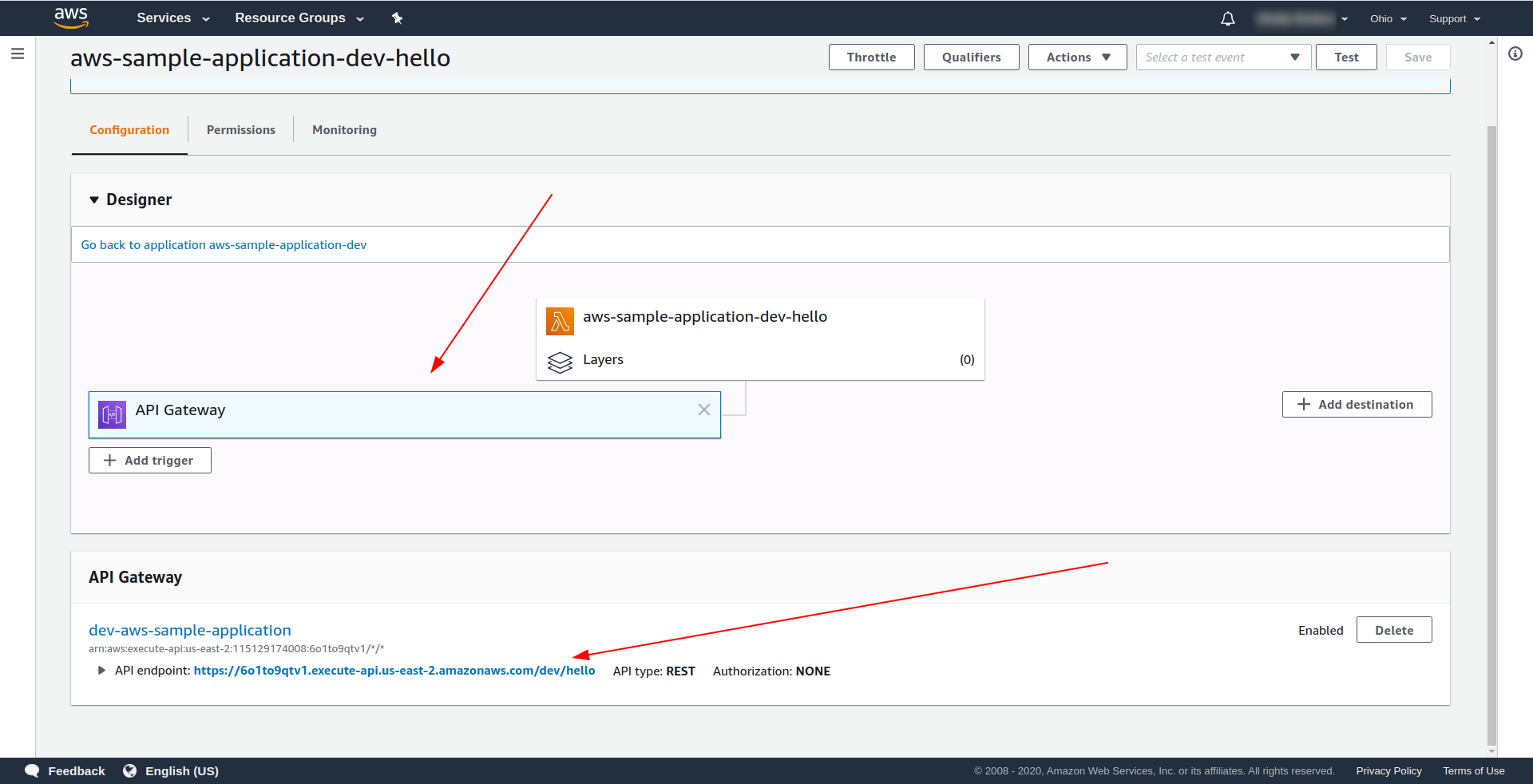
我们在“ Designer ”选项卡下看到我们已将API Gateway附加到我们的 Lambda 和 API Endpoint。
伟大的! 您已经创建了一个超级简单的无服务器应用程序,将其部署到 AWS Lambda,并测试了它的功能。 此外,我们还使用AWS API Gateway添加了一个端点。
4. 如何离线运行应用程序
到目前为止,我们知道我们可以在本地调用函数,而且我们可以使用 serverless-offline 插件离线运行整个应用程序。
该插件在您的本地/开发机器上模拟 AWS Lambda 和 API Gateway。 它启动一个 HTTP 服务器来处理请求并调用您的处理程序。
要安装插件,请在 app 目录中运行以下命令
npm install serverless-offline --save-dev
然后在项目的serverless.yml中打开文件并添加plugins属性:
插件: - 无服务器离线
配置应如下所示:
服务:aws-sample-application
提供者:
名称:aws
运行时:nodejs12.x
个人资料:无服务器管理员
地区:us-east-2
职能:
你好:
处理程序:handler.hello
事件:
- 网址:
路径:/你好
方法:获取
插件:
- 无服务器离线
要检查我们是否已成功安装和配置插件运行
sls --verbose
你应该看到这个:
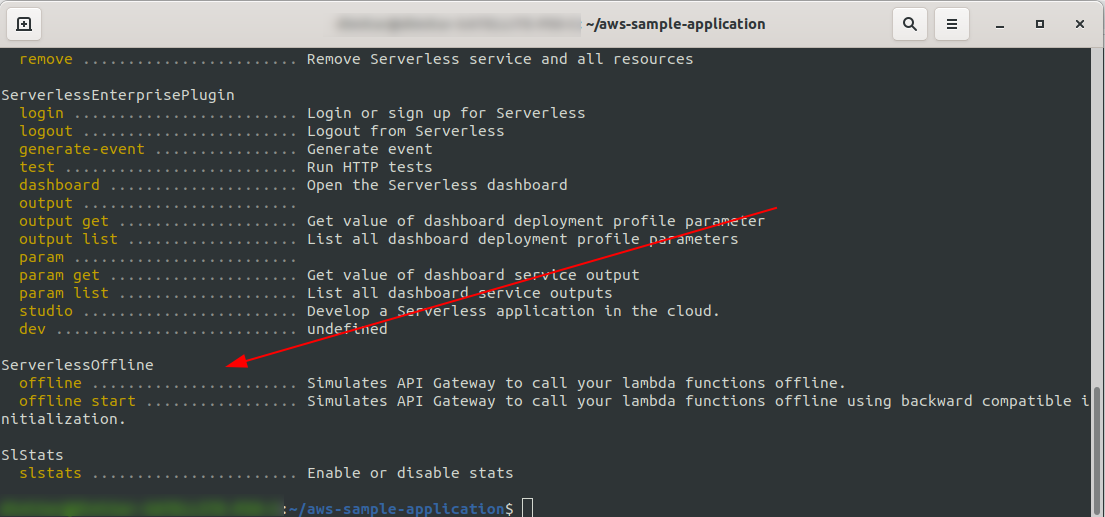
现在在项目的根目录中,运行命令
sls offline
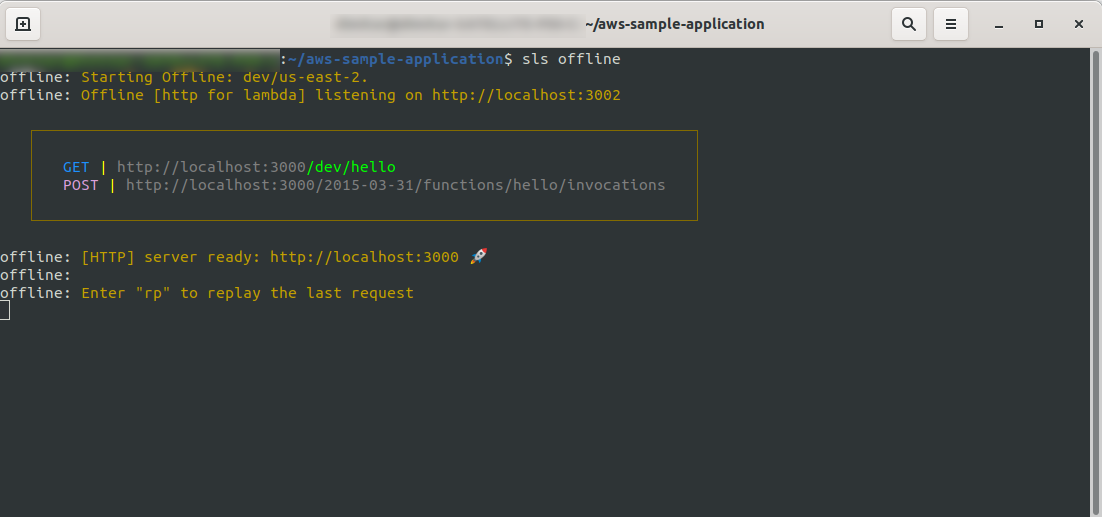
如您所见, HTTP服务器正在侦听端口 3000,您可以访问您的函数,例如,这里我们的 hello 函数有 http://localhost:3000/dev/hello。 打开我们有与我们之前创建的API Gateway相同的响应。
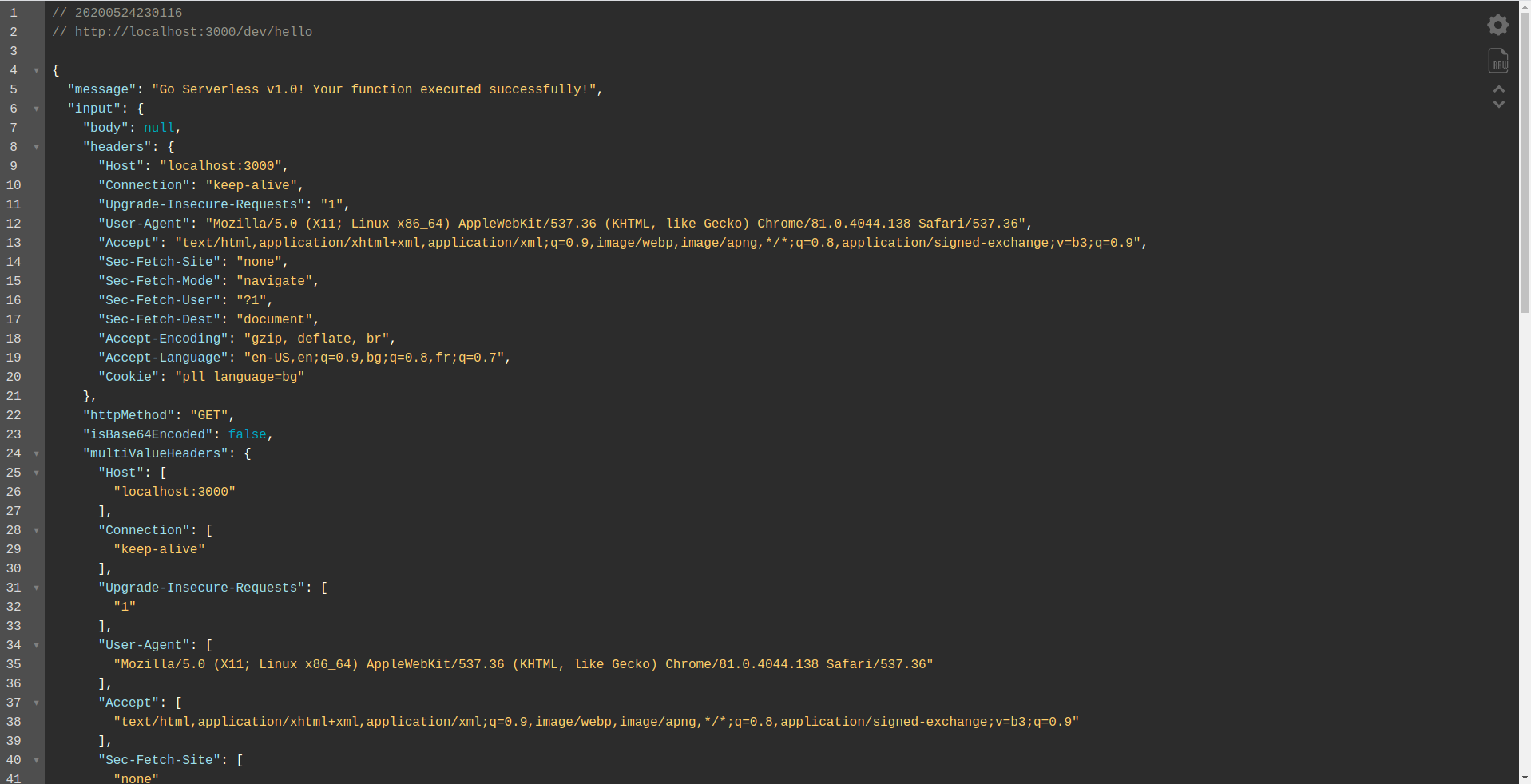
添加 Google BigQuery 集成

到目前为止,你做得很好! 你有一个使用无服务器的完整工作应用程序。 让我们扩展我们的应用并向其添加BigQuery集成,看看它是如何工作的以及如何完成集成。
BigQuery 是一种无服务器软件即服务 (SaaS),它是一种支持查询的经济高效且快速的数据仓库。 在我们继续将它与我们的 NodeJS 应用程序集成之前,我们必须创建一个帐户,所以让我们继续。
1. 设置谷歌云控制台
转到 https://cloud.google.com 并使用您的帐户登录(如果您尚未登录) - 创建一个帐户并继续。

当您登录 Google Cloud Console 时,您必须创建一个新项目。 单击徽标旁边的三个点,它将打开一个模式窗口,您可以在其中选择“新建项目。 ”
输入项目的名称。 我们将使用bigquery-example 。 创建项目后,使用抽屉导航到BigQuery :
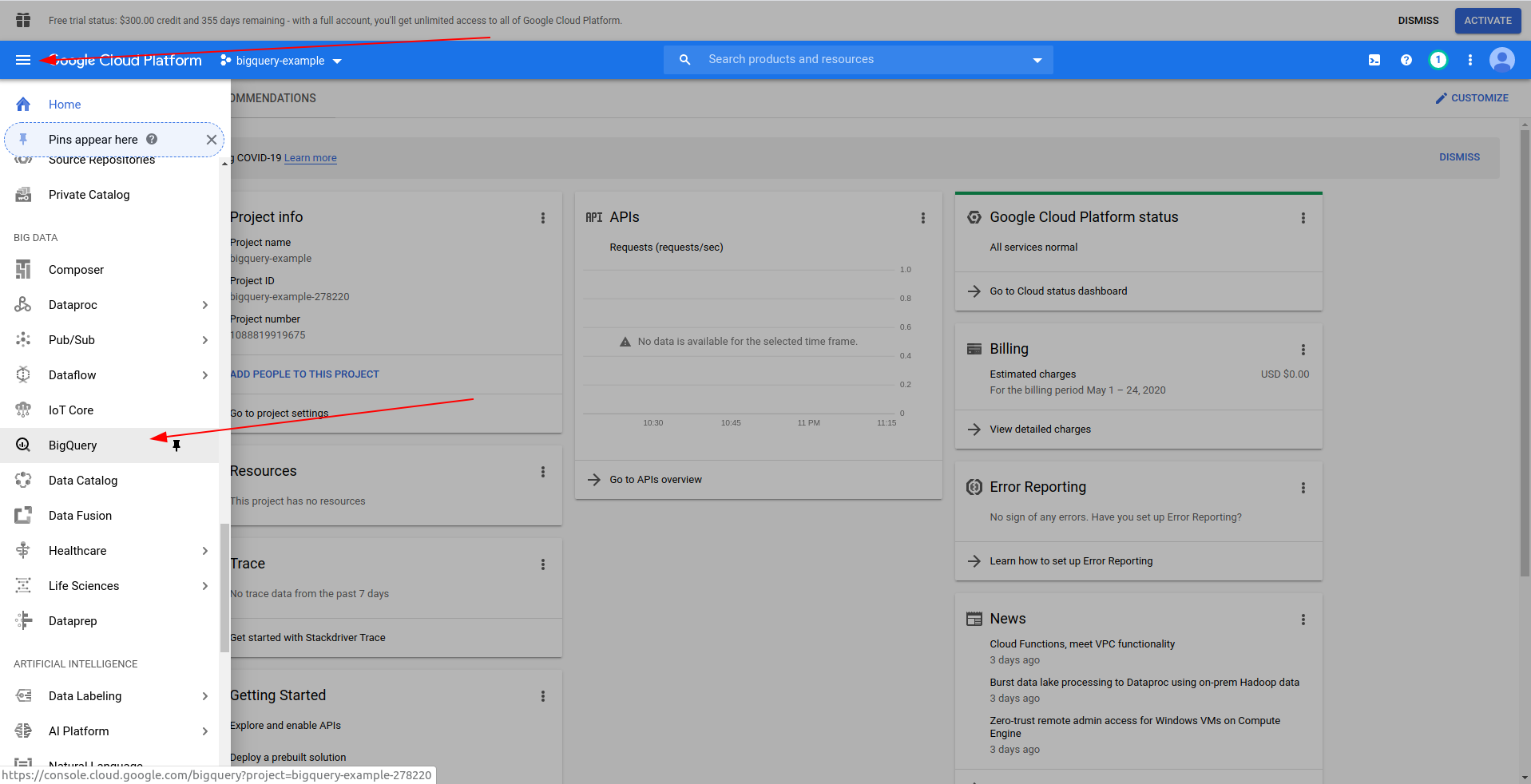
当 BigQuery 加载时,您将在左侧看到您有权访问的项目数据以及公共数据集。 我们在这个例子中使用了一个公共数据集。 它被命名为covid19_ecdc :
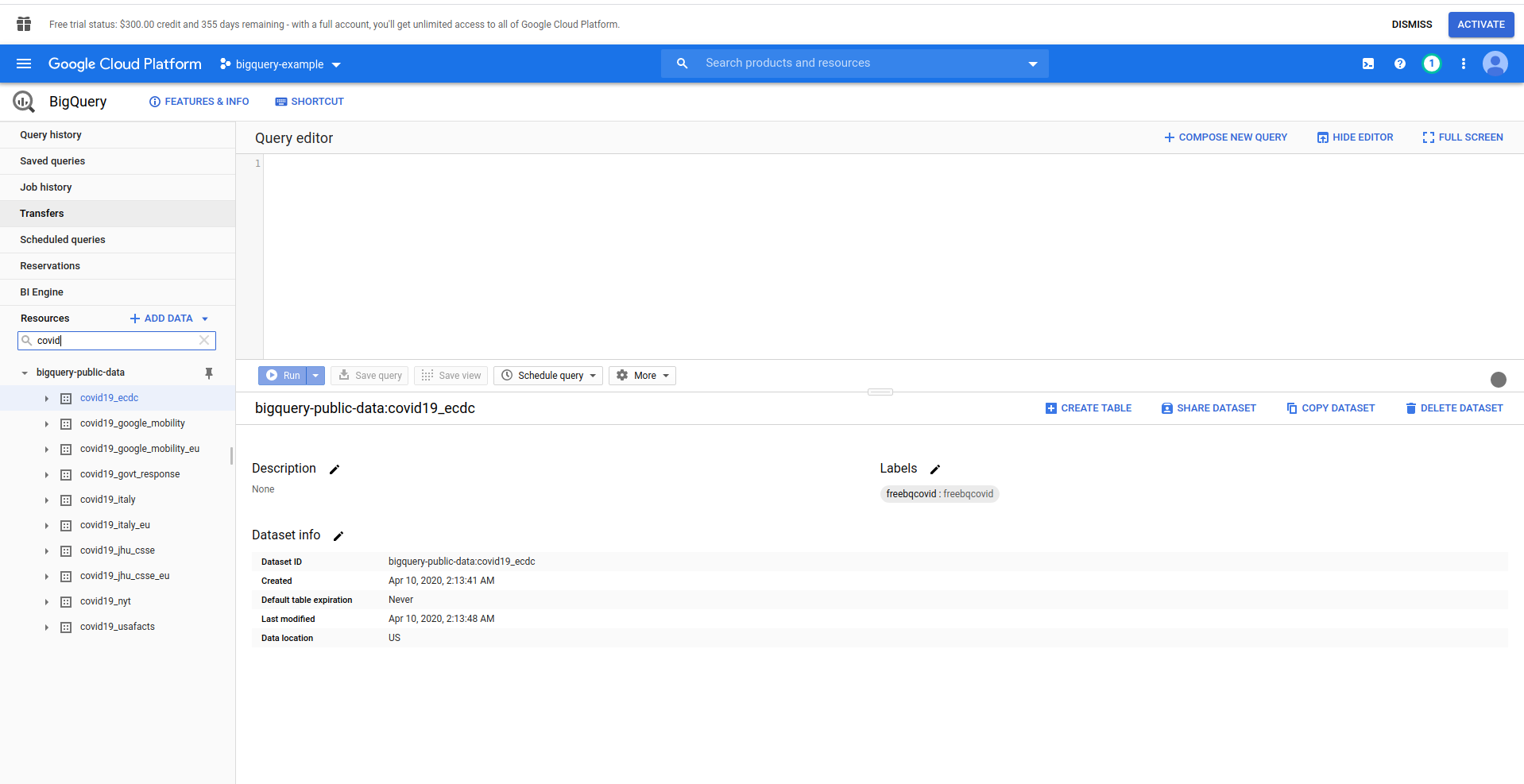
玩转数据集和可用表。 预览其中的数据。 这是一个公共数据集,每小时更新一次,包含有关COVID-19全球数据的信息。
我们必须创建一个 IAM 用户 -> 服务帐户才能访问数据。 因此,在菜单中,点击“IAM & Admin”,然后点击“Service Accounts”。
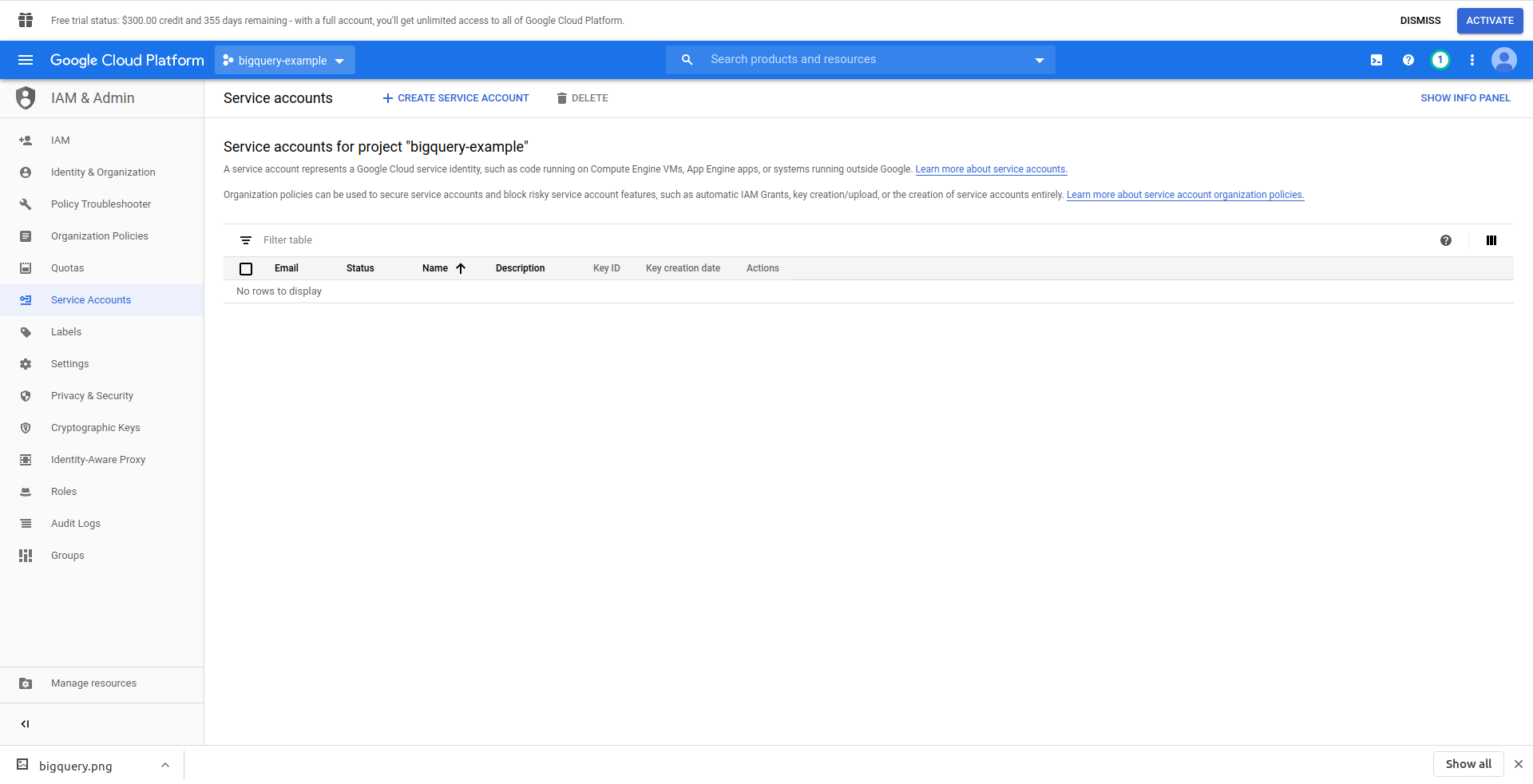
单击“创建服务帐户”按钮,输入服务帐户名称,然后单击“创建”。 接下来,转到“服务帐户权限” ,搜索并选择“BigQuery Admin” 。
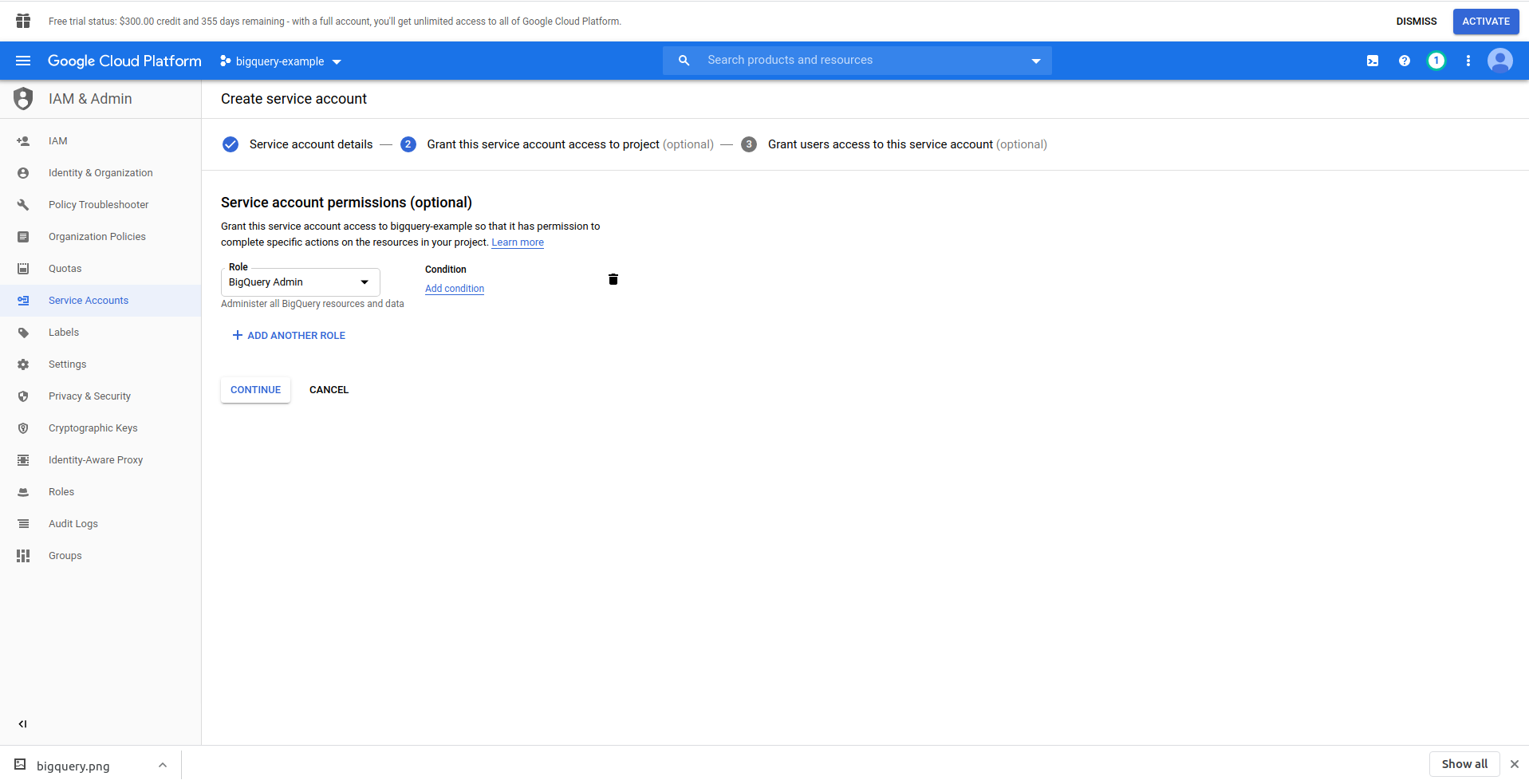
点击“继续”,这是最后一步,这里你需要你的密钥,所以点击“密钥”下的创建按钮并导出为JSON 。 将它安全地保存在某个地方,我们稍后会需要它。 单击完成以完成服务帐户的创建。
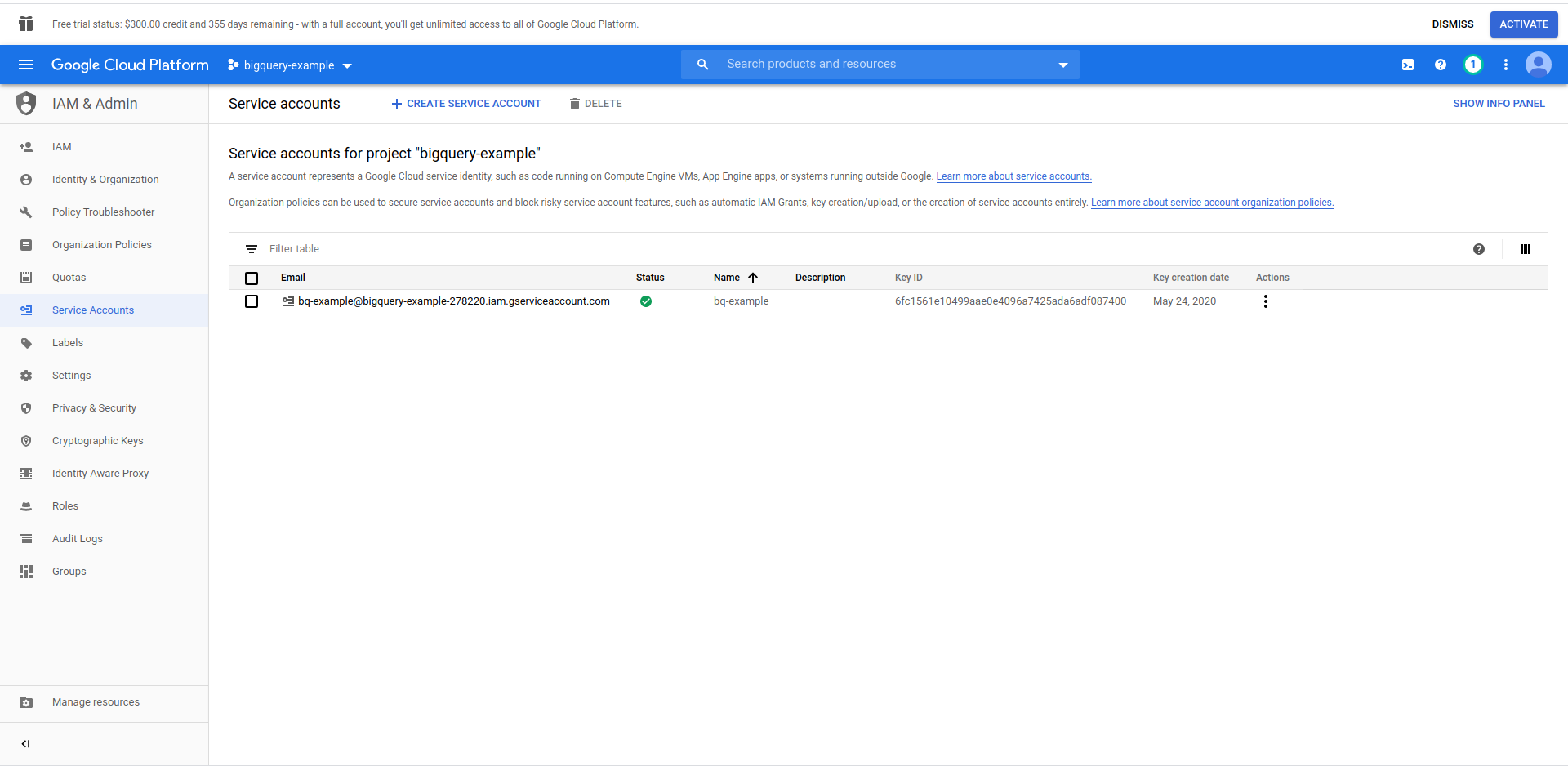
现在,我们将使用此处生成的凭据连接 NodeJS BigQuery 库。
2. 安装 NodeJS BigQuery 库
您需要安装BigQuery NodeJS 库才能在您刚刚创建的项目中使用它。 在应用程序目录中运行以下命令:
首先,通过运行npm init来初始化 npm
填写所有问题并继续安装BigQuery库:
npm install @google-cloud/bigquery
在我们继续更改我们的函数处理程序之前,我们必须从我们之前创建的 JSON 文件中携带私钥。 我们将使用无服务器环境变量来执行此操作。 您可以在此处获取更多信息。
打开serverless.yml ,并在提供者属性中添加环境属性,如下所示:
环境:
PROJECT_ID:${file(./config/bigquery-config.json):project_id}
CLIENT_EMAIL: ${file(./config/bigquery-config.json):client_email}
PRIVATE_KEY: ${file(./config/bigquery-config.json):private_key}
创建PROJECT_ID、PRIVATE_KEY和CLIENT_EMAIL环境变量,它们从我们生成的 JSON 文件中获取相同的属性(小写)。 我们已将它放在config文件夹中,并将其命名为bigquery-config.json 。
现在,您最终应该得到如下所示的 serverless.yml 文件:
服务:aws-sample-application
提供者:
名称:aws
运行时:nodejs12.x
个人资料:无服务器管理员
地区:us-east-2
环境:
PROJECT_ID:${file(./config/bigquery-config.json):project_id}
CLIENT_EMAIL: ${file(./config/bigquery-config.json):client_email}
PRIVATE_KEY: ${file(./config/bigquery-config.json):private_key}
职能:
你好:
处理程序:handler.hello
事件:
- 网址:
路径:/你好
方法:获取
插件:
- 无服务器离线
现在打开handler.js并让我们导入 BigQuery 库,在文件顶部的“use strict”下添加以下行:
const {BigQuery} = require('@google-cloud/bigquery');
现在我们必须告诉 BigQuery 库凭据。 为此,创建一个使用凭据实例化BigQuery的新常量:
常量 bigQueryClient = 新 BigQuery({
projectId:process.env.PROJECT_ID,
证书: {
client_email:process.env.CLIENT_EMAIL,
private_key:process.env.PRIVATE_KEY
}
});
接下来,让我们创建 BigQuery SQL 查询。 我们要检索有关保加利亚COVID-19病例的最新信息。 在继续之前,我们正在使用 BigQuery 查询编辑器对其进行测试,因此我们创建了一个自定义查询:
SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` WHERE geo_ ORDER BY date DESC LIMIT 1
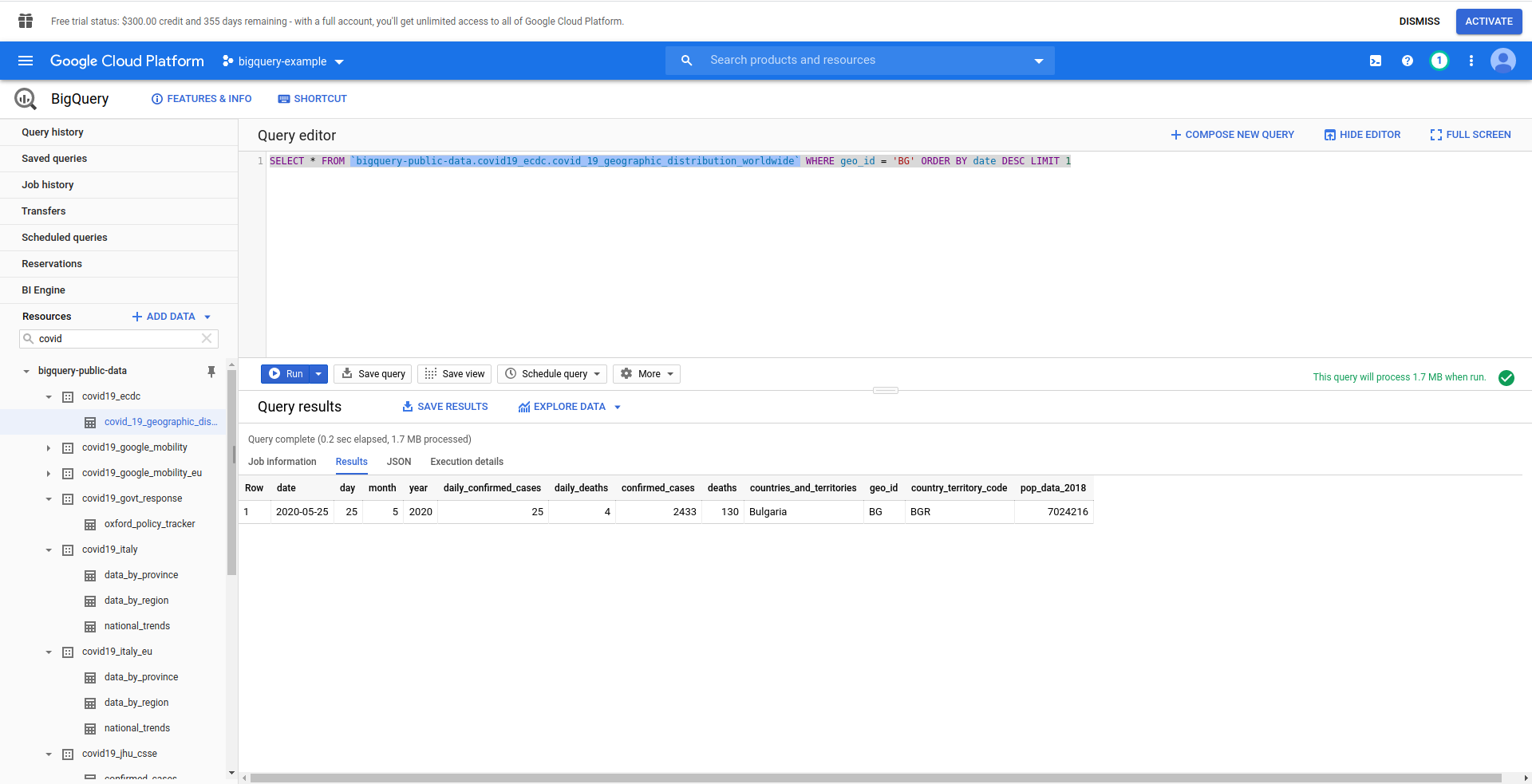
好的! 现在让我们在我们的 NodeJS 应用程序中实现它。
打开handler.js并粘贴下面的代码
const query = 'SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` WHERE geo_id = \'BG\' ORDER BY date DESC LIMIT 1';
常量选项 = {
查询:查询
}
const [job] = await bigQueryClient.createQueryJob(options);
const [rows] = 等待 job.getQueryResults();
我们已经创建了查询和选项常量。 然后我们继续将查询作为作业运行并从中检索结果。
让我们还更改我们的返回处理程序以从查询中返回生成的行:
返回 {
状态码:200,
正文: JSON.stringify(
{
行
},
空值,
2
),
};
让我们看看完整的handler.js :
'使用严格';
常量 {BigQuery} = 要求('@google-cloud/bigquery');
常量 bigQueryClient = 新 BigQuery({
projectId:process.env.PROJECT_ID,
证书: {
client_email:process.env.CLIENT_EMAIL,
private_key:process.env.PRIVATE_KEY
}
});
module.exports.hello = 异步事件 => {
const query = 'SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` WHERE geo_id = \'BG\' ORDER BY date DESC LIMIT 1';
常量选项 = {
查询:查询
}
const [job] = await bigQueryClient.createQueryJob(options);
const [rows] = 等待 job.getQueryResults();
返回 {
状态码:200,
正文: JSON.stringify(
{
行
},
空值,
2
),
};
};
好的! 让我们在本地测试我们的功能:
sls invoke local -f hello
我们应该看到输出:
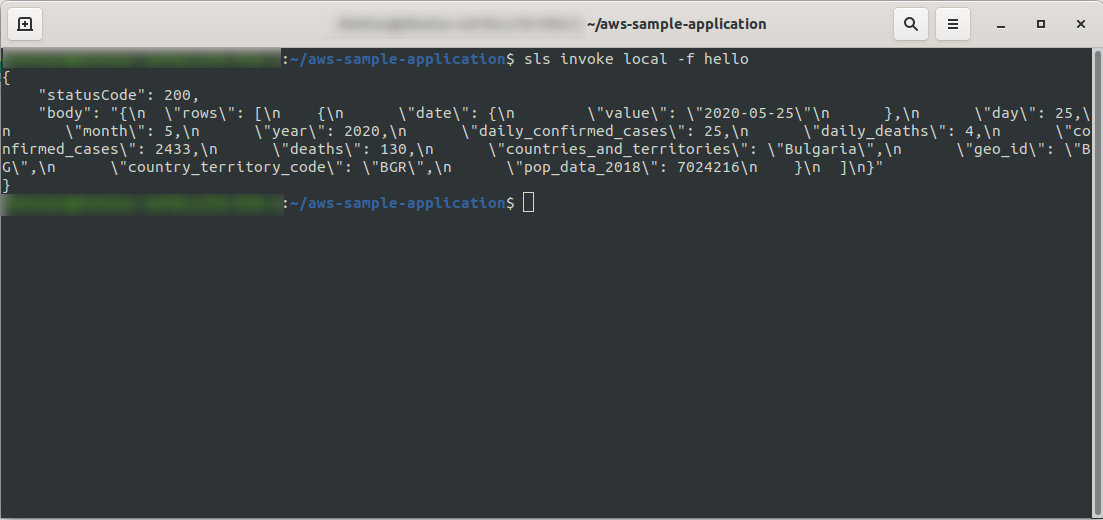
继续部署应用程序以通过 HTTP 端点对其进行测试,因此运行sls deploy -v
等待它完成并打开端点。 结果如下:
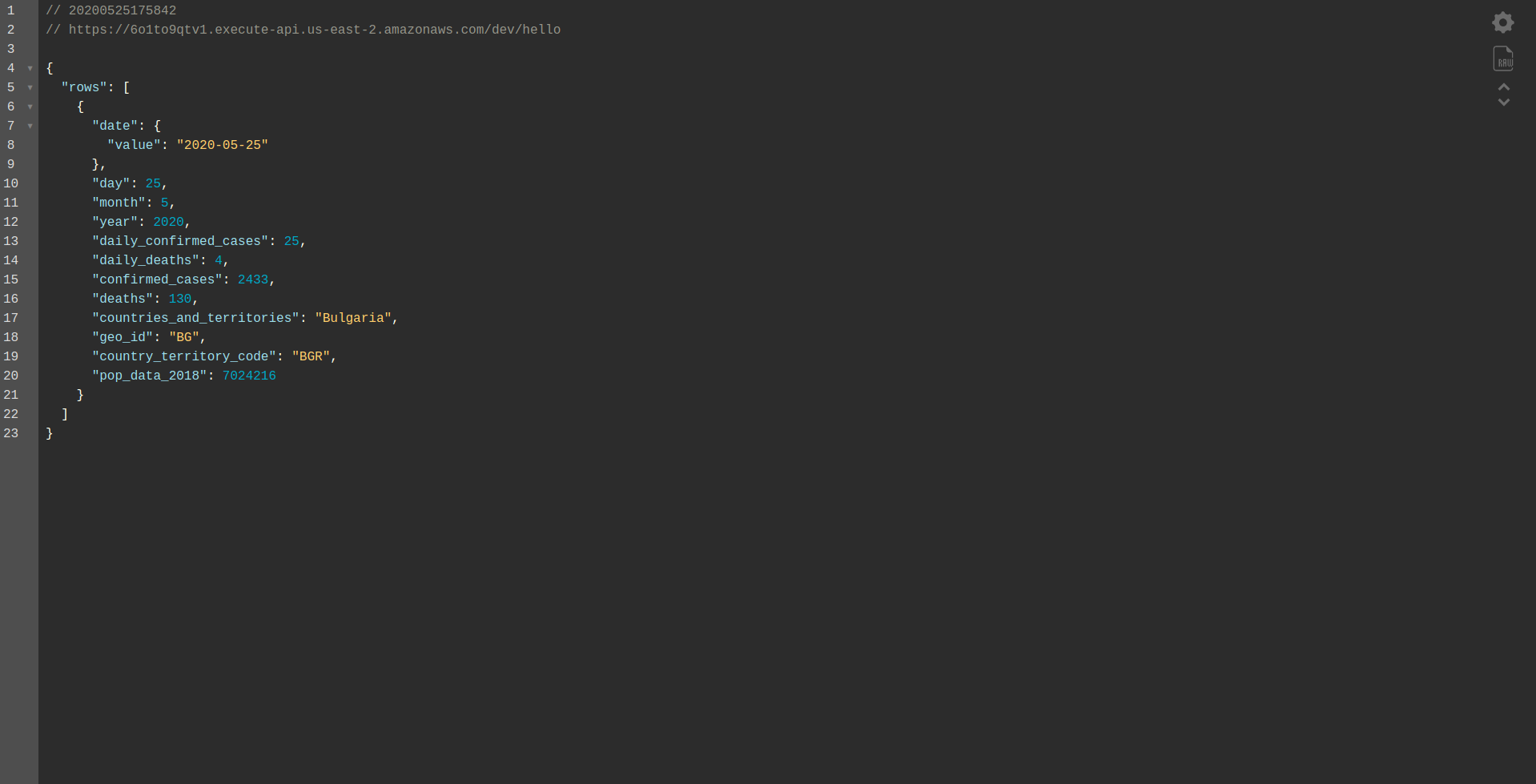
做得好! 我们现在有一个应用程序可以从 BigQuery 检索数据并返回响应! 最后让我们检查一下它是否离线工作。 sls offline
并加载本地端点:
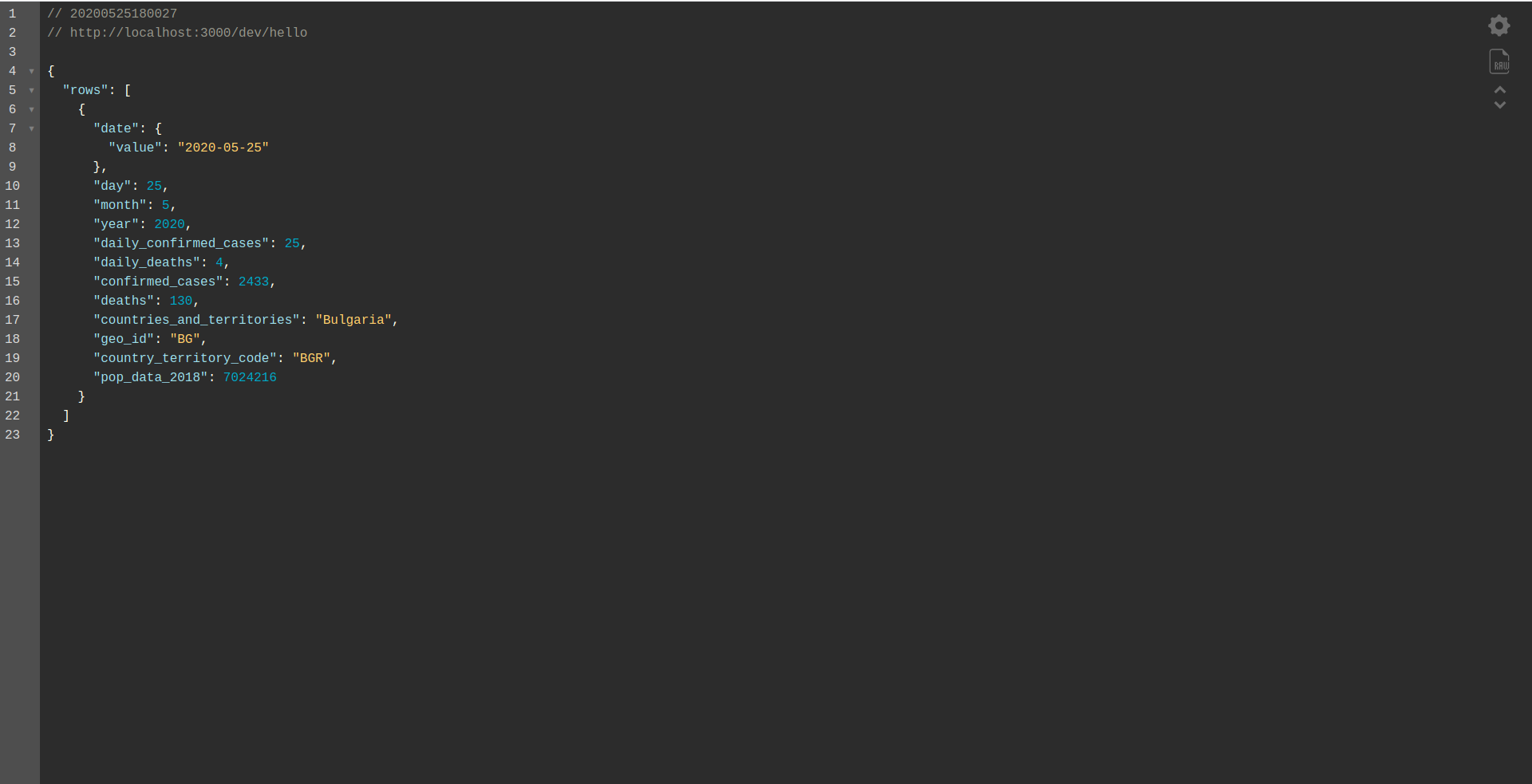
干得好。 我们快要结束这个过程了。 最后一步是稍微更改应用程序和行为。 我们想使用Application Load Balancer而不是AWS API Gateway 。 让我们看看如何在下一章中实现这一点。
ALB – AWS 中的应用程序负载均衡器
我们已经使用AWS API Gateway 创建了我们的应用程序。 在本章中,我们将介绍如何将 API Gateway 替换为Application Load Balancer (ALB)。
首先,让我们看看应用程序负载均衡器与 API 网关相比如何工作:
在应用程序负载均衡器中,我们将特定路径(例如/hello/ )映射到目标组——一组资源,在我们的例子中是Lambda函数。
一个目标组只能有一个与之关联的 Lambda 函数。 每当目标组需要响应时,应用程序负载均衡器都会向 Lambda 发送请求,并且函数必须使用响应对象进行响应。 与 API 网关一样, ALB处理所有 HTTP(s) 请求。
ALB 和API Gateway之间存在一些差异。 一个主要区别是 API Gateway 仅支持 HTTPS (SSL),而 ALB 同时支持 HTTP 和 HTTPS。
但是,让我们看看 API Gateway 的一些优缺点:
API网关:
优点:
- 出色的安全性。
- 实施起来很简单。
- 部署迅速,一分钟内即可完成。
- 可扩展性和可用性。
缺点:
- 面对高流量时,它可能会变得非常昂贵。
- 它需要更多的编排,这给开发人员增加了一定的难度。
- 由于 API 场景,性能下降会影响应用程序的速度和可靠性。
让我们继续创建 ALB 并切换到它,而不是使用 API Gateway:
1.什么是ALB?
应用程序负载均衡器允许开发人员配置和路由传入流量。 这是“ Elastic Load Balancing”的一个特性。 它充当客户端的单一联系点,将传入的应用程序流量分配给多个目标,例如多个区域中的 EC2 实例。
2. 使用 AWS UI 创建应用程序负载均衡器
让我们通过 Amazon AWS 中的 UI 创建我们的应用程序负载均衡器 (ALB)。 在“查找服务”中登录 AWS 控制台。 ” 键入“ EC2 ”并找到“负载均衡器”。 ”
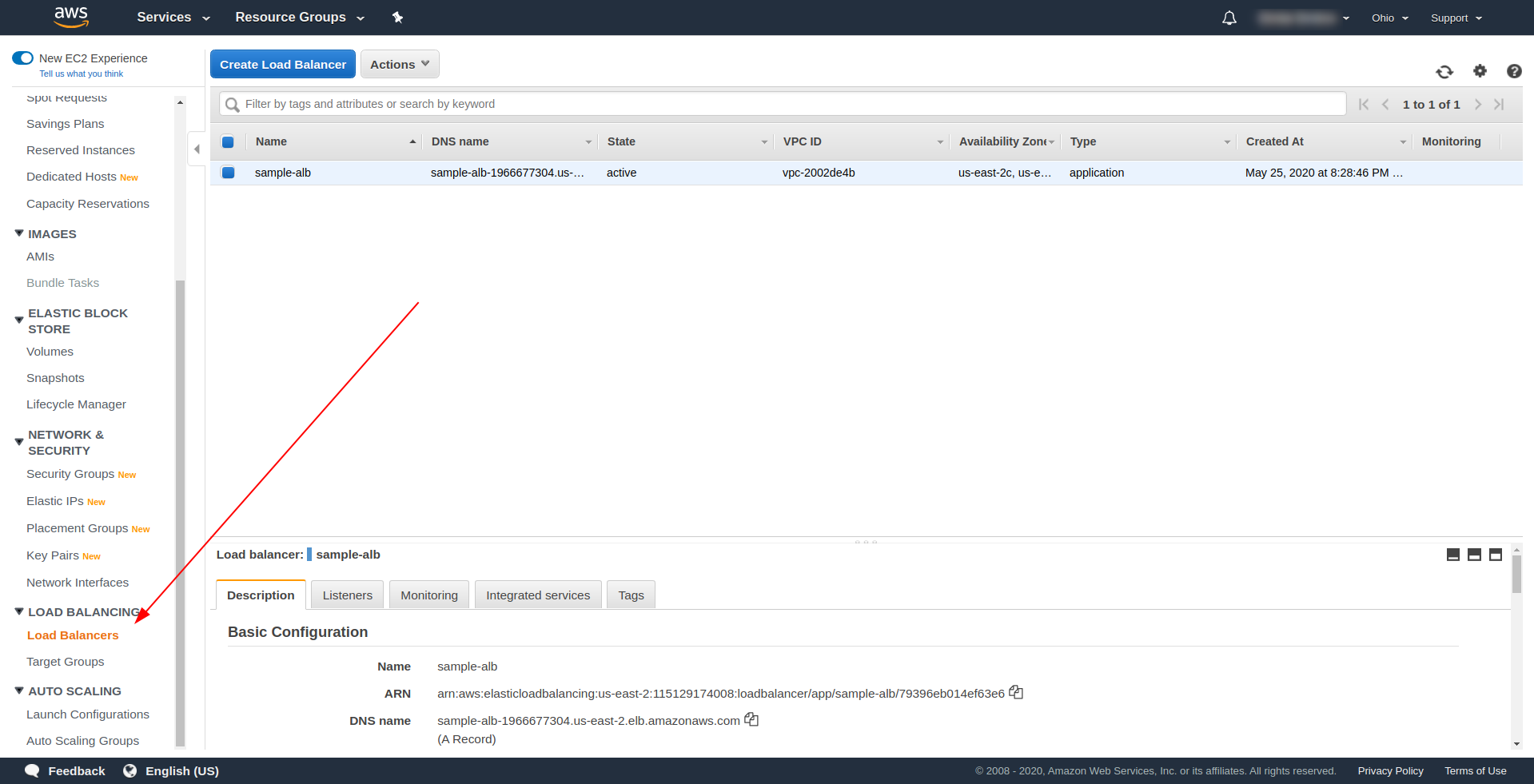
单击“应用程序负载均衡器”下的“创建负载均衡器”,选择“创建”。 对于名称,输入您的选择,我们使用“ sample-alb”,选择方案“ internet-facing ”, IP 地址类型为ipv4。
在“ Listeners ”上,保持原样 - HTTP 和端口 80。它可以配置为 HTTPS,尽管您必须有一个域并确认它才能使用 HTTPS。
可用区 – 对于VPC ,从下拉列表中选择您拥有的一个并标记所有“可用区” :
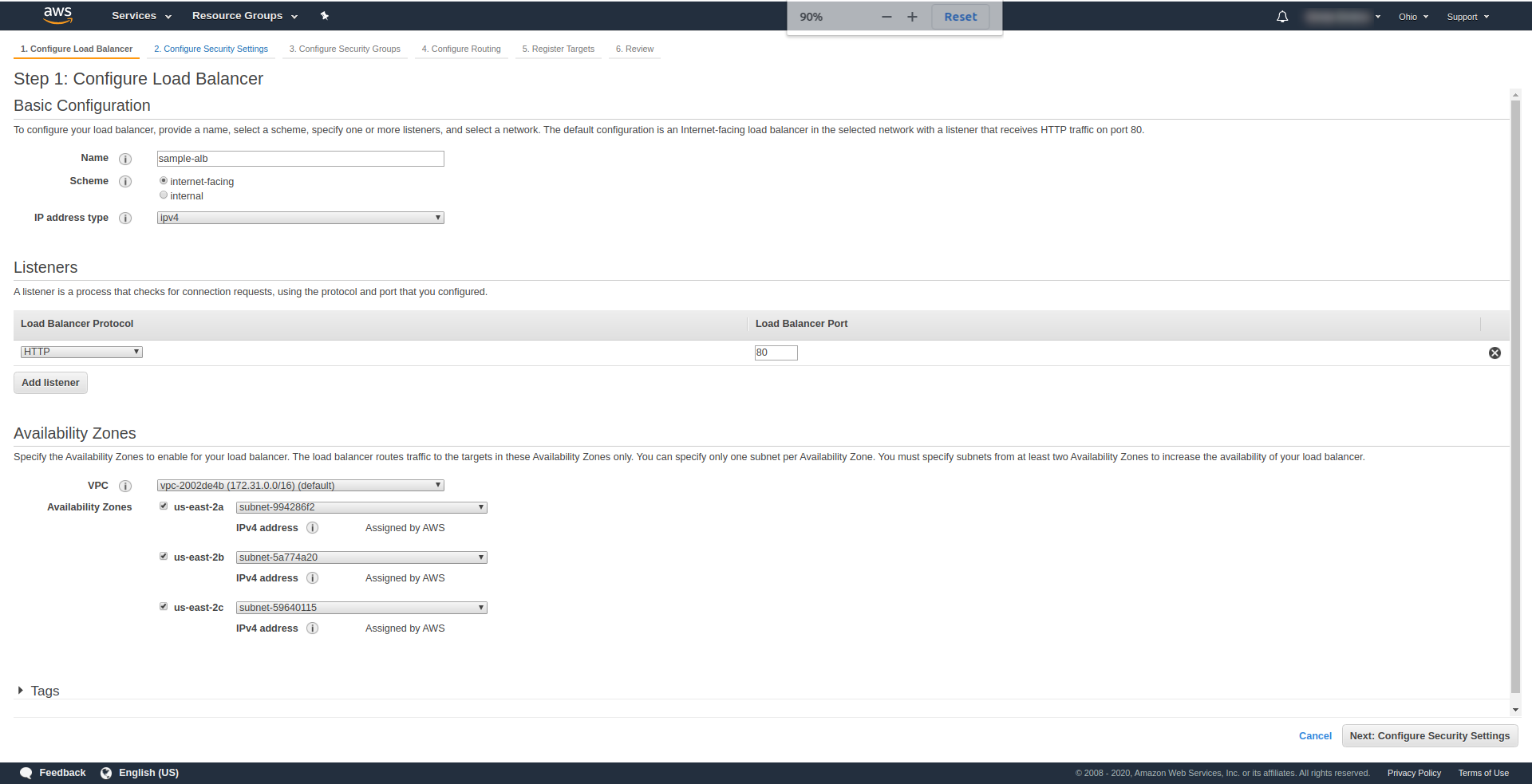
单击“下一步配置安全设置”以提示您提高负载均衡器的安全性。 点击下一步。
在“步骤 3.Configure Security Groups ”中,在“ Assign a security group ”中选择“Create a new security group”。 单击“下一步:配置路由”继续下一步。 “。 在第 4 步配置它,如上面的屏幕截图所示:
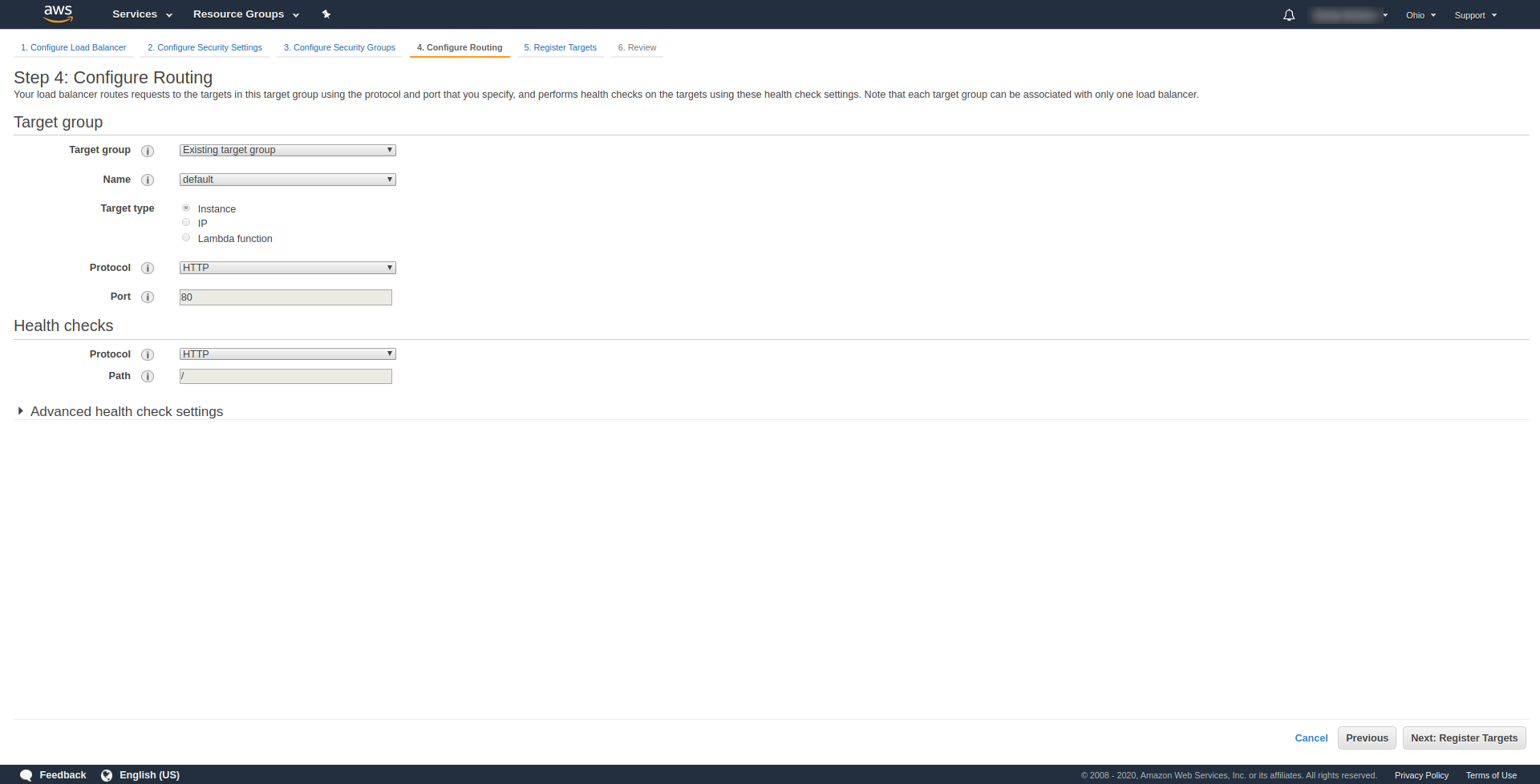
单击下一步、下一步和创建。
返回负载均衡器并复制 ARN,如屏幕截图所示:
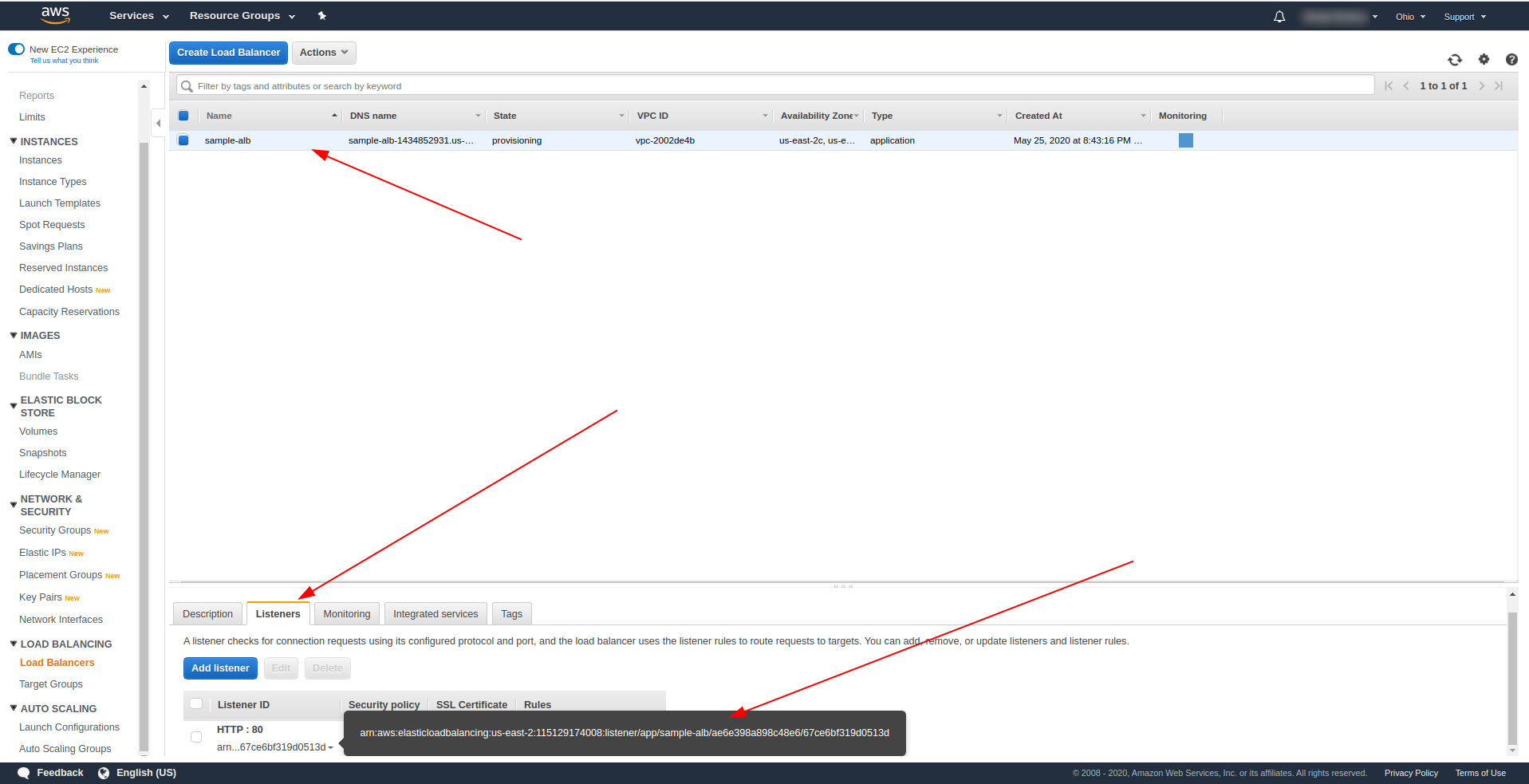
现在我们必须更改我们的 serverless.yml 并删除 API Gateway http 属性。 在 events 属性下,删除 http 属性并添加 alb 属性。 函数对象应该这样结束:
你好:
处理程序:handler.hello
事件:
- 白:
listenerArn: arn:aws:elasticloadbalancing:us-east-2:115129174008:listener/app/sample-alb/ae6e398a898c48e6/67ce6bf319d0513d
优先级:1
状况:
路径:/你好
保存文件并运行部署应用程序的命令sls deploy -v
成功部署后返回 AWS 负载均衡器并找到您的 DNS 名称,如屏幕截图所示:
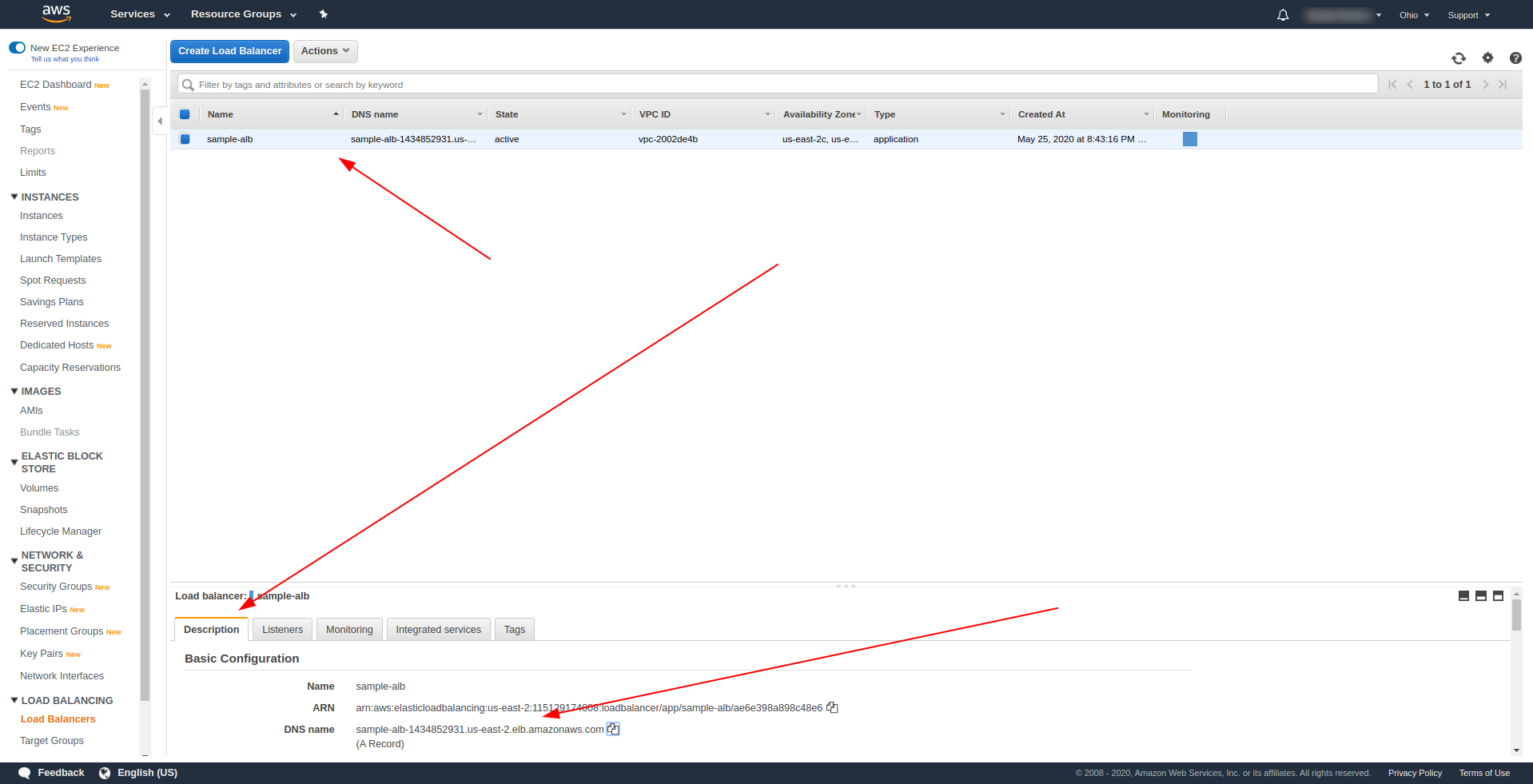
复制 DNS 名称并输入路径/hello 。
它应该可以工作并最终为您提供下载内容的选项:)。 到目前为止,应用程序负载均衡器运行良好,但应用程序需要为我们的最终用户返回正确的响应。 为此,请打开handler.js并将 return 语句替换为以下语句:
返回 {
状态码:200,
statusDescription: "200 OK",
标题:{
“内容类型”:“应用程序/json”
},
isBase64Encoded:假,
正文:JSON.stringify(行)
}
ALB 的不同之处在于响应必须包含容器状态描述、标头和 isBase64Encoded。 请保存文件,然后再次部署,但这次不是整个应用程序,而是我们更改的功能。 运行以下命令:
sls deploy -f hello
这样,我们只定义要部署的函数hello 。 部署成功后,再次访问带有路径的DNS名称,应该会有正确的响应了!
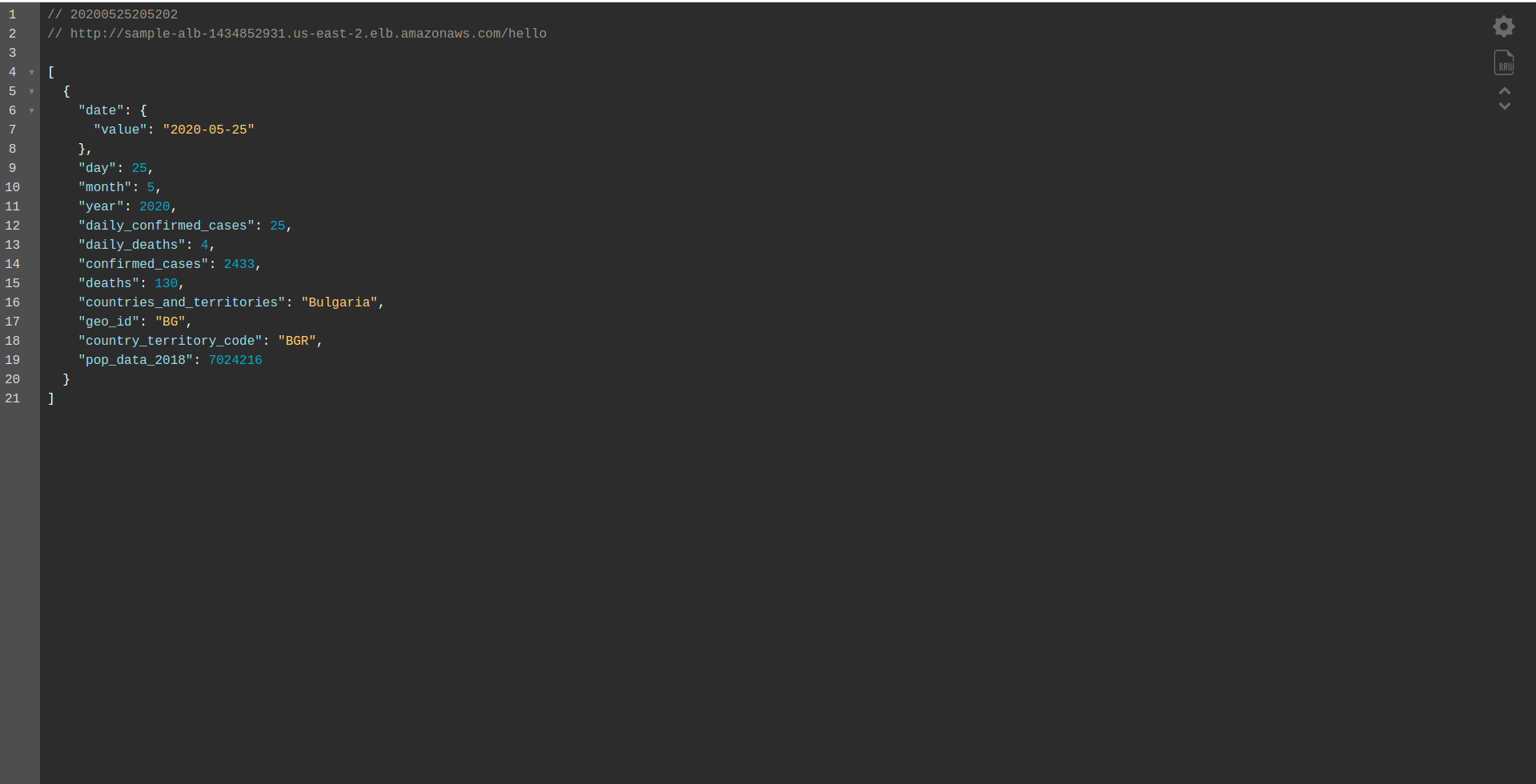
伟大的! 现在我们已将 API Gateway 替换为 Application Load Balancer。 应用程序负载均衡器比 API Gateway 便宜,我们现在可以扩展我们的应用程序以满足我们的需求,特别是如果我们期望有更高的流量。
最后的话
我们使用无服务器框架、AWS和BigQuery创建了一个简单的应用程序,并介绍了它的主要用途。 无服务器是未来,用它来处理应用程序很容易。 继续学习并深入研究无服务器框架,以探索其所有功能和其中的秘密。 它也是一个非常简单和方便的工具。