
搜索引擎可以检测人工智能内容吗?
已发表: 2023-08-04去年人工智能工具的爆炸式增长对数字营销人员产生了巨大影响,尤其是搜索引擎优化领域的营销人员。
鉴于内容创建耗时且成本高昂,营销人员转向人工智能寻求帮助,但结果好坏参半
尽管存在道德问题,但反复出现的一个问题是:“搜索引擎可以检测到我的人工智能内容吗?”
这个问题被认为特别重要,因为如果答案是否定的,那么关于是否以及如何使用人工智能的许多其他问题就变得无效。
机器生成内容的悠久历史
虽然机器生成或辅助内容创建的频率是前所未有的,但这并不是全新的,也并不总是负面的。
对于新闻网站来说,首先报道新闻是当务之急,他们长期以来一直利用股票市场和地震仪等各种来源的数据来加快内容创作。
例如,发布一篇机器人文章实际上是正确的:
- “今天早上[时间]/[日期]在[地点、城市]检测到[震级]地震,这是自[上次事件日期]以来的第一次地震。 更多消息敬请关注。”
这样的更新对于需要尽快获取此信息的最终读者也很有帮助。
另一方面,我们看到了许多机器生成内容的“黑帽”实现。
多年来,谷歌一直在“自动生成不提供附加值的页面”的旗帜下谴责使用马尔可夫链来生成文本以轻松旋转内容。
特别有趣的是“无附加值”的含义,这对某些人来说主要是一个混淆点或灰色地带。
LLM 如何增加价值?
由于 GPTx 大语言模型 (LLM) 和改进对话交互的微调人工智能聊天机器人 ChatGPT 引起的关注,人工智能内容的受欢迎程度飙升。
在不深入研究技术细节的情况下,关于这些工具有几个要点需要考虑:
生成的文本基于概率分布
- 例如,如果您写道,“成为 SEO 很有趣,因为……”,法学硕士会查看所有标记,并尝试根据其训练集计算下一个最可能的单词。 总的来说,您可以将其视为手机预测文本的真正高级版本。
ChatGPT 是一种生成式人工智能
- 这意味着输出是不可预测的。 有一个随机元素,它可能对相同的提示做出不同的反应。
当您理解这两点时,就会发现像 ChatGPT 这样的工具没有任何传统知识或“知道”任何东西。 这个缺点是所有错误或所谓的“幻觉”的基础。
大量记录的输出证明了这种方法如何产生不正确的结果并导致 ChatGPT 反复自相矛盾。
考虑到频繁出现幻觉的可能性,这引发了人们对人工智能书写文本“增值”的一致性的严重怀疑。
根本原因在于法学硕士生成文本的方式,如果没有新的方法,这个问题就很难解决。
这是一个至关重要的考虑因素,特别是对于“你的金钱,你的生活”(YMYL) 主题,如果不准确,可能会严重损害人们的财务或生活。
今年,Men's Health 和 CNET 等主要出版物被发现发布了人工智能生成的与事实不符的信息,凸显了这一担忧。
出版商并不是唯一面临这个问题的人,因为 Google 很难用 YMYL 内容来控制其搜索生成体验 (SGE) 内容。
尽管谷歌表示将谨慎生成答案,并具体给出了一个例子“不会显示有关给孩子服用泰诺的问题的答案,因为它属于医疗领域”,但 SGE 显然会这样做只需简单地问它这个问题即可。
获取搜索营销人员信赖的每日新闻通讯。
查看条款。

Google 的 SGE 和 MUM
显然,谷歌相信机器生成的内容可以回答用户的查询。 自 2021 年 5 月发布 MUM(多任务统一模型)以来,谷歌就已经暗示了这一点。
MUM 着手解决的一项挑战是基于人们对复杂任务平均发出八次查询的数据。
在初始查询中,搜索者将了解一些附加信息,提示相关搜索并显示新网页来回答这些查询。
谷歌提出:如果他们可以接受初始查询,预测用户后续问题,并使用他们的索引知识生成完整的答案,会怎么样?
如果它有效,虽然这种方法对用户来说可能很棒,但它本质上消除了 SEO 赖以在 SERP 中立足的许多“长尾”或零量关键词策略。
假设谷歌可以识别适合人工智能生成答案的查询,那么许多问题都可以被视为“解决”。
这就提出了一个问题……
- 当 Google 可以将用户保留在其搜索生态系统中并自行生成答案时,为什么要向搜索者展示您的网页以及预先生成的答案呢?
谷歌有经济激励措施将用户保留在其生态系统中。 我们已经看到了实现这一目标的各种方法,从特色片段到让人们在 SERP 中搜索航班。
假设 Google 认为您生成的文本无法提供超出其已经提供的价值。 在这种情况下,这只是搜索引擎的成本与收益的问题。
从长远来看,他们能否通过吸收生成费用并让用户等待答案而不是快速而廉价地将用户发送到他们知道已经存在的页面来产生更多收入?
检测 AI 内容
随着 ChatGPT 使用量的激增,出现了数十种“人工智能内容检测器”,它们允许您输入文本内容并输出百分比分数 - 这就是问题所在。
尽管不同的检测器标记这个百分比分数的方式存在一些差异,但它们几乎总是给出相同的输出:整个提供的文本是人工智能生成的百分比确定性。
当百分比被标记为“75% AI / 25% Human”时,这会导致混乱。
许多人会误解这意味着“该文本 75% 由人工智能编写,25% 由人类编写”,而它的意思是“我 75% 确定该文本 100% 是由人工智能编写的”。
这种误解导致一些人就如何调整文本输入以使其“通过”人工智能检测器提供建议。
例如,使用双感叹号 (!!) 是一种非常人性化的特征,因此将其添加到某些 AI 生成的文本中将导致 AI 检测器给出“99%+ 人类”分数。
这会被误解为您“欺骗”了探测器。
但这是探测器完美运行的一个例子,因为提供的通道不再 100% 由人工智能生成。
不幸的是,这种能够“欺骗”人工智能检测器的误导性结论通常也与谷歌等搜索引擎未检测到人工智能内容相混淆,从而给网站所有者带来错误的安全感。
Google 关于 AI 内容的政策和行动
谷歌关于人工智能内容的声明历来都很模糊,这给他们在执行方面留下了回旋余地。
然而,今年谷歌搜索中心发布了更新的指南,其中明确指出:
“我们的重点是内容的质量,而不是内容的制作方式。”
甚至在此之前,谷歌搜索联络员丹尼·沙利文(Danny Sullivan)也加入了推特保守派,确认他们“没有说过人工智能内容不好”。
谷歌列出了人工智能如何生成有用内容的具体示例,例如体育比分、天气预报和成绩单。
很明显,谷歌更关心的是输出结果,而不是实现目标的手段,加倍努力“以操纵搜索结果排名为主要目的生成内容违反了我们的垃圾邮件政策。”
谷歌在打击 SERP 操纵方面拥有多年经验,声称其系统的进步(例如 SpamBrain)已使 99% 的搜索“无垃圾内容”,其中包括 UGC 垃圾内容、抓取、伪装和所有各种形式的内容一代。
许多人都进行了测试,看看谷歌对人工智能内容有何反应,以及他们在质量方面的界限。
在 ChatGPT 推出之前,我创建了一个包含 10,000 页内容的网站,主要由无监督的 GPT3 模型生成,回答人们也提出的有关视频游戏的问题。
通过最少的链接,该网站很快被索引并稳步增长,每月提供数千名访问者。
在 2022 年的两次 Google 系统更新(有用内容更新和后来的垃圾邮件更新)期间,Google 突然几乎完全压制了该网站。
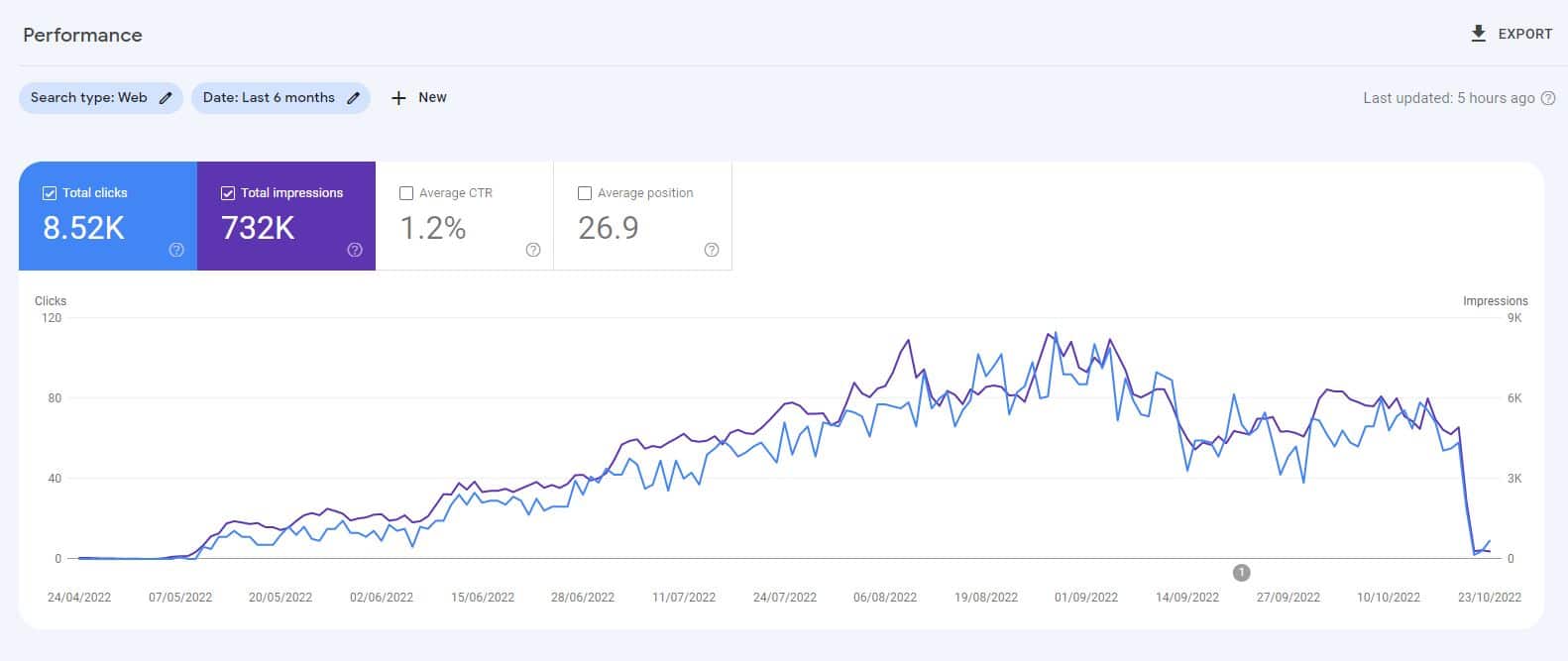
从这样的实验中得出“人工智能内容不起作用”的结论是错误的。
然而,这向我表明,在那个特定时间,谷歌:
- 没有将不受监督的 GPT-3 内容归类为“质量”。
- 可以通过大量其他信号检测并消除此类结果。
为了得到最终的答案,你需要一个更好的问题
根据 Google 的指导方针、我们对搜索系统的了解、SEO 实验和常识,“搜索引擎可以检测 AI 内容吗?” 可能是错误的问题。
充其量,这只是一种非常短期的观点。
在大多数主题中,法学硕士很难在事实准确性和满足 Google EEAT 标准方面始终如一地生成“高质量”内容,尽管他们可以实时访问网络以获取训练数据之外的信息。
人工智能在为以前内容稀缺的查询生成答案方面取得了重大进展。 但随着谷歌与 SGE 一起实现更崇高的长期目标,这种趋势可能会消退。
预计重点将回归到较长形式的专家内容,谷歌的知识系统将提供答案来满足许多长尾查询,而不是引导用户访问众多小网站。
本文表达的观点是客座作者的观点,并不一定是搜索引擎土地的观点。 此处列出了工作人员作者。