
爬取效能:如何提升爬取优化
已发表: 2022-10-27不能保证 Googlebot 会抓取它可以在您的网站上访问的每个网址。 相反,绝大多数网站都缺少大量页面。
现实情况是,Google 没有资源来抓取它找到的每个页面。 Googlebot 已发现但尚未抓取的所有 URL 以及它打算重新抓取的 URL 在抓取队列中都具有优先级。
这意味着 Googlebot 只会抓取那些被分配了足够高优先级的内容。 而且由于抓取队列是动态的,它会随着 Google 处理新网址而不断变化。 并不是所有的 URL 都排在队列的后面。
那么如何确保您网站的 URL 是 VIP 并跳线呢?
爬行对SEO至关重要

为了让内容获得可见性,Googlebot 必须首先抓取它。
但好处比这更细微,因为页面从原来的爬取速度越快:
- 已创建,新内容可以越早出现在 Google 上。 这对于限时或率先上市的内容策略尤其重要。
- 更新,更新的内容越早开始影响排名。 这对于内容重新发布策略和技术 SEO 策略都特别重要。
因此,爬行对于您的所有自然流量都是必不可少的。 然而,经常有人说抓取优化只对大型网站有益。
但这与您网站的大小、更新内容的频率或您是否在 Google Search Console 中是否有“已发现 - 当前未编入索引”排除项无关。
抓取优化对每个网站都有好处。 对其价值的误解似乎源于无意义的测量,尤其是爬行预算。
抓取预算无关紧要

很多时候,爬行是根据爬行预算来评估的。 这是 Googlebot 在给定时间内将在特定网站上抓取的 URL 数量。
谷歌表示,这是由两个因素决定的:
- 抓取速度限制(或 Googlebot 可以抓取的速度):Googlebot 在不影响网站性能的情况下获取网站资源的速度。 从本质上讲,响应式服务器会导致更高的爬网率。
- 抓取需求(或 Googlebot 想要抓取的内容):Googlebot 在单次抓取期间访问的 URL 数量,基于对(重新)索引编制的需求,受网站内容的受欢迎程度和陈旧性的影响。
一旦 Googlebot “花费”了它的抓取预算,它就会停止抓取一个网站。
谷歌没有提供抓取预算的数字。 最接近的是在 Google Search Console 抓取统计报告中显示总抓取请求。
包括我自己在内的许多 SEO 都煞费苦心地试图推断抓取预算。
经常出现的步骤大致如下:
- 确定您的网站上有多少可抓取页面,通常建议查看 XML 站点地图中的 URL 数量或运行无限制的抓取工具。
- 通过导出 Google Search Console Crawl Stats 报告或基于日志文件中的 Googlebot 请求来计算每天的平均抓取次数。
- 将页面数除以每天的平均爬网次数。 常说,如果结果在 10 以上,重点是爬取预算优化。
然而,这个过程是有问题的。
不仅因为它假定每个 URL 都被爬取一次,实际上有些 URL 被爬取了多次,而另一些则根本不被爬取。
不仅因为它假定一次爬网等于一页。 实际上,一个页面可能需要多次 URL 爬取来获取加载它所需的资源(JS、CSS 等)。
但最重要的是,因为当它被提炼成一个计算指标时,比如每天的平均抓取次数,抓取预算只不过是一个虚荣指标。
任何针对“抓取预算优化”的策略(又名,旨在不断增加抓取总量)都是徒劳的。
如果它用于没有价值的 URL 或自上次抓取以来未更改的页面,您为什么要关心增加抓取的总数? 这样的抓取不会帮助 SEO 性能。
另外,任何看过爬网统计数据的人都知道,根据多种因素,它们从一天到另一天的波动通常非常剧烈。 这些波动可能与 SEO 相关页面的快速(重新)索引相关,也可能不相关。
抓取的 URL 数量的上升或下降本质上既不好也不坏。
抓取效率是一个 SEO KPI

对于您要编入索引的页面,重点不应该是它是否被抓取,而是它在发布或发生重大变化后被抓取的速度。
本质上,目标是最大限度地缩短创建或更新与 SEO 相关的页面与下一次 Googlebot 抓取之间的时间。 我把这个时间称为延迟爬行功效。
衡量抓取效率的理想方法是计算数据库创建或更新日期时间与下一次 Googlebot 从服务器日志文件抓取 URL 之间的差异。
如果难以访问这些数据点,您还可以使用 XML 站点地图 lastmod 日期作为代理,并在 Google Search Console URL Inspection API 中查询 URL 以了解其上次抓取状态(每天最多 2,000 次查询)。
此外,通过使用 URL 检查 API,您还可以跟踪索引状态何时更改,以计算新创建的 URL 的索引效率,这是发布和成功索引之间的区别。
因为在不影响索引状态或处理页面内容刷新的情况下进行爬网只是一种浪费。
抓取效率是一个可操作的指标,因为随着它的降低,越多的 SEO 关键内容可以通过 Google 呈现给您的受众。
您还可以使用它来诊断 SEO 问题。 深入研究 URL 模式,了解网站各个部分的内容被抓取的速度有多快,以及这是否是阻碍有机性能的原因。
如果您发现 Googlebot 需要数小时、数天或数周的时间来抓取并索引您新创建或最近更新的内容,您能做些什么呢?
获取营销人员所依赖的每日通讯搜索。
见条款。
优化爬取的 7 个步骤
抓取优化就是引导 Googlebot 抓取重要的 URL 当它们(重新)发布时很快。 请遵循以下七个步骤。
1. 确保快速、健康的服务器响应
高性能服务器至关重要。 在以下情况下,Googlebot 会减慢或停止抓取:

- 抓取您的网站会影响性能。 例如,它们爬得越多,服务器响应时间就越慢。
- 服务器响应大量错误或连接超时。
另一方面,提高页面加载速度以提供更多页面可以导致 Googlebot 在相同时间内抓取更多网址。 这是页面速度作为用户体验和排名因素之外的另一个好处。
如果您还没有,请考虑支持 HTTP/2,因为它允许在服务器上请求更多具有类似负载的 URL。
但是,性能和爬取量之间的相关性只是在一定程度上。 一旦您跨越了因站点而异的阈值,服务器性能的任何额外提升都不太可能与爬网的增加相关联。
如何检查服务器健康
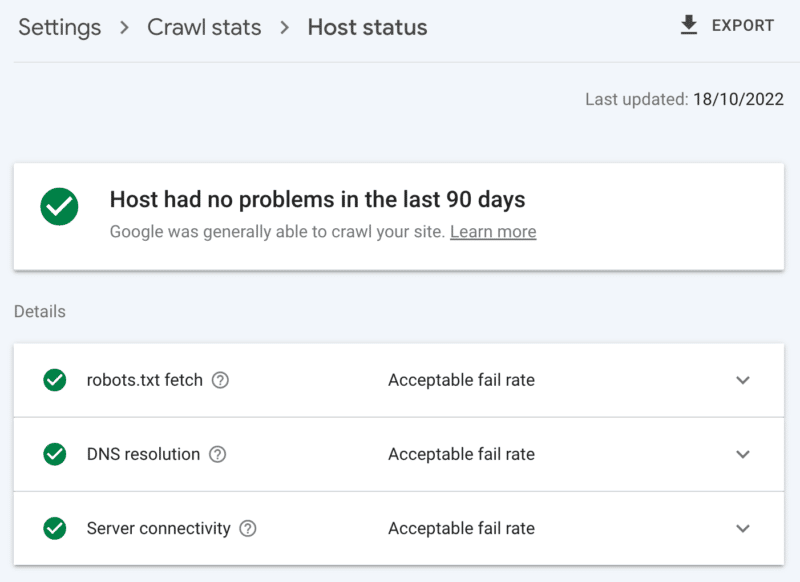
Google Search Console 抓取统计报告:
- 主机状态:显示绿色勾号。
- 5xx 错误:占不到 1%。
- 服务器响应时间图表:趋势低于 300 毫秒。
2.清理低价值内容
如果大量网站内容已过时、重复或质量低下,则会导致对爬网活动的竞争,可能会延迟新内容的索引或更新内容的重新索引。
加上定期清理低价值内容还可以减少索引膨胀和关键字蚕食,并且有利于用户体验,这是 SEO 的明智之举。
当您有另一个可以被视为明显替代的页面时,将内容与 301 重定向合并; 理解这一点将使您的处理爬网成本增加一倍,但对于链接资产而言,这是值得的牺牲。
如果没有等效内容,使用 301 只会导致软 404。使用 410(最佳)或 404(次之)状态码删除此类内容,以发出强烈信号,不再抓取该 URL。
如何检查低价值内容
Google Search Console 页面中报告“已抓取 - 当前未编入索引”排除项的 URL 数量。 如果这很高,请查看为文件夹模式或其他问题指标提供的示例。
3. 查看索引控制
Rel=规范链接 是避免索引问题的有力提示,但通常过度依赖并最终导致爬网问题,因为每个规范化 URL 至少需要两次爬网,一次为自己,一次为合作伙伴。
类似地,noindex robots 指令对于减少索引膨胀很有用,但大量的指令会对爬网产生负面影响——因此仅在必要时使用它们。
在这两种情况下,问问自己:
- 这些索引指令是处理 SEO 挑战的最佳方式吗?
- 可以在 robots.txt 中合并、删除或阻止某些 URL 路由吗?
如果您正在使用它,请认真重新考虑将 AMP 作为长期技术解决方案。
随着页面体验更新的重点是核心网络生命力,并且只要您满足网站速度要求,所有 Google 体验中都包含非 AMP 页面,请仔细研究 AMP 是否值得双重抓取。
如何检查对索引控件的过度依赖
Google Search Console 覆盖率报告中归类于排除项但没有明确原因的 URL 数量:
- 具有适当规范标签的替代页面。
- 被 noindex 标签排除。
- 重复,谷歌选择了与用户不同的规范。
- 重复的、提交的 URL 未被选为规范。
4. 告诉搜索引擎蜘蛛要抓取什么以及何时抓取
XML 站点地图是帮助 Googlebot 确定重要站点 URL 优先级并在此类页面更新时进行通信的重要工具。
要获得有效的爬虫引导,请务必:
- 仅包含可索引且对 SEO 有价值的 URL——通常是 200 个状态代码、规范的原始内容页面,带有“索引,关注”机器人标签,您关心它们在 SERP 中的可见性。
- 在各个 URL 和站点地图本身上包含准确的 <lastmod> 时间戳标记,尽可能接近实时。
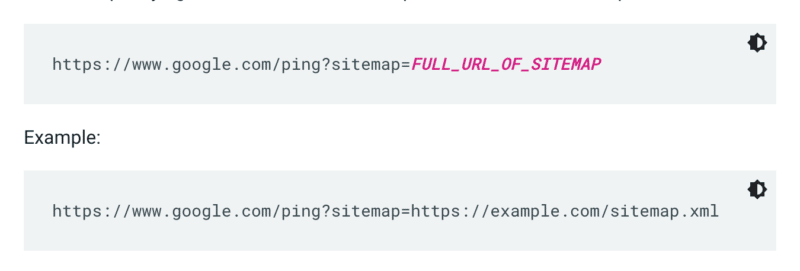
Google 不会在每次抓取网站时检查站点地图。 因此,每当它更新时,最好将其 ping 以引起 Google 的注意。 为此,请在浏览器或命令行中发送 GET 请求至:
此外,在 robots.txt 文件中指定站点地图的路径,并使用站点地图报告将其提交到 Google Search Console。
通常,Google 会比其他网站更频繁地抓取站点地图中的网址。 但是,即使站点地图中的一小部分 URL 质量低下,它也可以阻止 Googlebot 使用它来抓取建议。
XML 站点地图和链接将 URL 添加到常规爬网队列中。 还有一个优先级爬取队列,有两种进入方式。
首先,对于那些有职位发布或直播视频的人,您可以将 URL 提交到 Google 的 Indexing API。
或者,如果您想引起 Microsoft Bing 或 Yandex 的注意,您可以将 IndexNow API 用于任何 URL。 但是,在我自己的测试中,它对 URL 的抓取影响有限。 因此,如果您使用 IndexNow,请务必监控 Bingbot 的抓取效率。
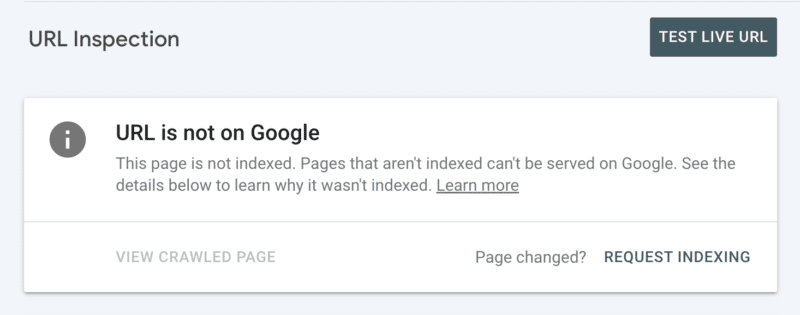
其次,您可以在 Search Console 中检查 URL 后手动请求索引。 尽管请记住,每天有 10 个 URL 的配额,并且抓取仍然需要相当长的时间。 在您挖掘以发现爬行问题的根源时,最好将此视为临时补丁。
如何检查基本的 Googlebot 抓取指南
在 Google Search Console 中,您的 XML 站点地图显示“成功”状态并且最近被读取。
5.告诉搜索引擎蜘蛛什么不要爬
某些页面可能对用户或网站功能很重要,但您不希望它们出现在搜索结果中。 防止此类 URL 路由使用 robots.txt 禁止分散抓取工具的注意力。 这可能包括:
- API 和 CDN 。 例如,如果您是 Cloudflare 的客户,请务必禁止将文件夹 /cdn-cgi/ 添加到您的站点。
- 不重要的图像、脚本或样式文件,如果在没有这些资源的情况下加载的页面不会受到损失的显着影响。
- 功能页面,例如购物车。
- 无限空间,例如由日历页面创建的空间。
- 参数页。 尤其是那些来自过滤(例如,?price-range=20-50)、重新排序(例如,?sort=)或搜索(例如,?q=)的分面导航,因为每个单独的组合都被爬虫计为单独的页面。
请注意不要完全阻止分页参数。 对于 Googlebot 发现内容和处理内部链接资产而言,可抓取的分页通常是必不可少的。 (查看有关分页的 Semrush 网络研讨会,了解有关原因的更多详细信息。)
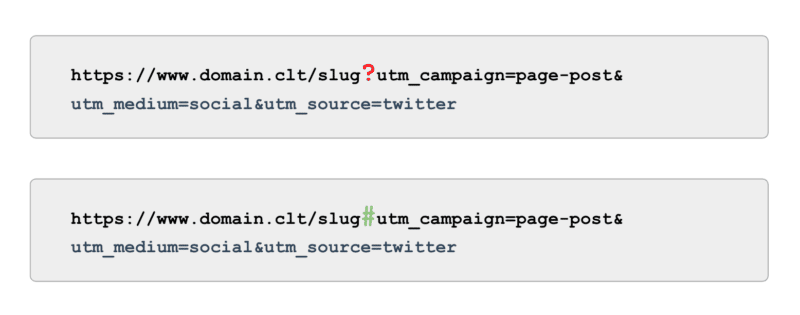
当涉及到跟踪时,不要使用由参数驱动的 UTM 标签(又名“?”),而是使用锚点(又名“#”)。 它在 Google Analytics(分析)中提供了相同的报告优势,但无法被抓取。
如何检查 Googlebot 不抓取指南
在 Google Search Console 中查看“已编入索引,未在站点地图中提交”网址示例。 忽略分页的前几页,您还发现了哪些其他路径? 它们应该被包含在 XML 站点地图中,被阻止被抓取还是让它被抓取?
此外,查看“已发现 - 当前未编入索引”列表 - 在 robots.txt 中阻止任何对 Google 提供低价值或没有价值的 URL 路径。
要将此提升到一个新的水平,请查看服务器日志文件中所有 Googlebot 智能手机抓取的无价值路径。
6.策划相关链接
页面的反向链接对于 SEO 的许多方面都很有价值,抓取也不例外。 但是对于某些页面类型,获取外部链接可能具有挑战性。 例如,产品、站点架构中较低级别的类别甚至文章等深层页面。
另一方面,相关的内部链接是:
- 技术上可扩展。
- 向 Googlebot 发出强有力的信号,以优先抓取页面。
- 对深度页面抓取特别有影响。
面包屑、相关内容块、快速过滤器和精心策划的标签的使用对爬网效率都有很大的好处。 由于它们是 SEO 关键内容,请确保此类内部链接不依赖于 JavaScript,而是使用标准的、可抓取的 <a> 链接。
请记住,此类内部链接还应为用户增加实际价值。
如何检查相关链接
使用像 ScreamingFrog 的 SEO 蜘蛛这样的工具对您的整个网站进行手动抓取,寻找:
- 孤立的 URL。
- robots.txt 阻止的内部链接。
- 任何非 200 状态代码的内部链接。
- 内部链接的不可索引 URL 的百分比。
7.审核剩余的爬取问题
如果上述所有优化都已完成,并且您的爬网效率仍然不理想,请进行深入审核。
首先查看所有剩余的 Google Search Console 排除示例,以确定抓取问题。
解决这些问题后,使用手动抓取工具更深入地抓取网站结构中的所有页面,就像 Googlebot 那样。 将此与缩小到 Googlebot IP 的日志文件进行交叉引用,以了解哪些页面正在被抓取,哪些页面未被抓取。
最后,启动日志文件分析将范围缩小到 Googlebot IP 至少四个星期的数据,最好是更多。
如果您不熟悉日志文件的格式,请利用日志分析器工具。 最终,这是了解 Google 如何抓取您的网站的最佳来源。
完成审核并获得已识别的爬网问题列表后,按每个问题的预期工作量和对性能的影响对其进行排名。
注意:其他 SEO 专家提到,来自 SERP 的点击会增加对着陆页 URL 的抓取。 但是,我还无法通过测试确认这一点。
将爬网效率优先于爬网预算
爬取的目的不是为了获得最高的爬取量,也不是为了让网站的每个页面都被重复爬取,它是在尽可能接近创建或更新页面时吸引与 SEO 相关的内容的爬取。
总的来说,预算并不重要。 你投资的东西才是最重要的。
本文中表达的观点是客座作者的观点,不一定是 Search Engine Land。 工作人员作者在这里列出。