
Apache Spark 如何为航空公司分析提供支持?
已发表: 2015-10-30全球航空业继续快速增长,但持续强劲的盈利能力仍有待观察。 根据国际航空运输协会 (IATA) 的数据,该行业的收入在过去十年中翻了一番,从 2005 年的 3690 亿美元增至 2015 年的预期 7270 亿美元。

在商业航空领域,价值链中的每个参与者——机场、飞机制造商、喷气发动机制造商、旅行社和服务公司都获得了可观的利润。
由于较高的航班交易流失率,所有这些参与者都单独生成了非常大量的数据。 识别和捕捉需求是这里的关键,它为航空公司提供了更大的差异化机会。 因此,航空业可以利用大数据洞察力来提高销售额并提高利润率。
大数据是一个数据集集合的术语,该数据集如此庞大和复杂,以至于传统的数据处理系统或现有的 DBMS 工具无法处理其计算。
Apache Spark 是一个开源的分布式集群计算框架,专为交互式查询和迭代算法而设计。
Spark DataFrame 抽象是一个表格数据对象,类似于 R 的原生 dataframe 或 Pythons pandas 包,但存储在集群环境中。
根据《财富》最新调查,Apache Spark 是 2015 年最流行的技术。
最大的 Hadoop 供应商 Cloudera 也在向 Hadoop MapReduce 说再见,向 Spark 说你好。
真正让 Spark 优于 Hadoop 的是速度。 Spark在内存中处理其大部分操作——将它们从分布式物理存储复制到速度更快的逻辑 RAM 内存中。 这减少了需要在 Hadoops MapReduce 系统下完成的缓慢、笨重的机械硬盘驱动器的写入和读取所消耗的时间。
此外,Spark 还包括精心设计的工具(实时处理、机器学习和交互式 SQL),用于支持业务目标,例如通过结合来自连接设备(也称为物联网)的历史数据来分析实时数据。
今天,让我们收集一些关于使用Apache Spark的示例机场数据的见解。
在之前的博客中,我们看到了如何使用新的 Dataframes API 在 Spark 中处理结构化和半结构化数据,还介绍了如何有效地处理 JSON 数据。
在这篇博客中,我们将了解如何使用 SQL 查询 DataFrames 中的数据,以及如何将输出以 CSV 格式保存到文件系统。
使用 Databricks CSV 解析库
为此,我将使用 Databricks 提供的 CSV 解析库,Databricks 是一家由 Apache Spark 的创建者创立的公司,目前负责处理 Spark 开发和分发。
Spark 社区由大约 600 名贡献者组成,就贡献者的数量而言,他们使其成为整个 Apache 软件基金会(开源软件的主要管理机构)中最活跃的项目。
Spark-csv 库帮助我们在 spark 中解析和查询 csv 数据。 我们可以使用这个库来读取和写入任何 Hadoop 兼容文件系统的 csv 数据。
将数据加载到 Spark DataFrames
让我们使用来自 Databricks 的 spark-csv 解析库将我们的输入文件加载到 Spark DataFrames 中。
您可以通过指定–packages com.databricks 在 Spark shell 中使用此库:spark-csv_2.10:1.0.3
启动shell时如下所示:
$ bin/spark-shell –packages com.databricks:spark-csv_2.10:1.0.3
请记住,您应该连接到互联网,因为当您发出此命令时,会自动下载 spark-csv 包。 我正在使用 spark 1.4.0 版本
让我们用已经创建的 SparkContext(sc) 对象创建 sqlContext
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
现在让我们从 airports.csv (airport csv github) 文件加载我们的 csv 数据,其架构如下
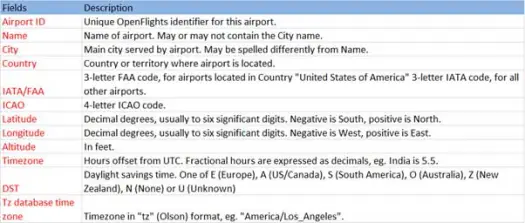
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))加载操作将使用 Databricks spark-csv 库解析 *.csv 文件,并返回一个列名与文件中第一个标题行相同的数据框。
以下是传递给 load 方法的参数。
- 来源: “com.databricks.spark.csv”告诉 spark 我们要加载为 csv 文件。
- 选项:
- path – 文件的路径,它所在的位置。
- Header : "header" -> "true"告诉 spark 将文件的第一行映射到结果数据帧的列名。
让我们看看我们的 Dataframe 的架构是什么
查看我们数据框中的示例数据
scala> airportDF.show

使用临时表查询 CSV 数据:
要对表执行查询,我们调用 SQLContext 上的 sql() 方法。
我们创建了 airports DataFrame 并加载了 CSV 数据,要查询这个 DF 数据,我们必须将其注册为名为 airports 的临时表。
>
scala> airportDF.registerTempTable("airports")
让我们找出数据集中东南部有多少个机场
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]

我们可以在 Spark 上的 sql 查询中进行聚合
我们将找出每个国家有多少个独特的城市有机场
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
每个国家/地区机场的平均海拔高度(英尺)是多少?
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
现在要了解每个时区有多少个机场正在运营?
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
我们还可以计算每个国家/地区这些机场的平均纬度和经度
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
让我们计算一下有多少不同的 DST
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
以 CSV 格式保存数据
到目前为止,我们加载并查询了 csv 数据。 现在我们将看到如何将结果以 CSV 格式保存回文件系统。
假设我们要向客户发送有关所有国家西北部所有机场的报告。
让我们先计算一下。
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
并将其保存为 CSV 文件
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
以下是传递给 save 方法的参数。
- 来源:它与加载方法com.databricks.spark.csv相同,它告诉 spark 将数据保存为 csv。
- SaveMode :如果给定的输出路径已经存在,这允许用户提前指定需要做什么。 这样现有数据就不会被错误地丢失/覆盖。 您可以抛出错误、追加或覆盖。 在这里,我们抛出了一个错误ErrorIfExists ,因为我们不想覆盖任何现有文件。
- 选项:这些选项与我们传递给加载方法的选项相同。 选项:
- path – 文件的路径,它应该被存储在哪里。
- Header : "header" -> "true"告诉 spark 将数据帧的列名映射到结果输出文件的第一行。
将其他数据格式转换为 CSV
我们还可以使用此库将任何其他数据格式(如 JSON、parquet、文本)转换为 CSV。
在之前的博客中,我们创建了 json 数据。 你可以在github上找到它
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
让我们将其保存为 CSV。
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
结论:
在这篇文章中,我们使用SparkSQL交互式查询收集了一些关于机场数据的见解
并探索了Spark 的 csv 解析库
下一篇博客我们将探讨 Spark 中非常重要的组件,即 Spark Streaming。
Spark Streaming 允许用户将实时数据收集到 Spark 中并在发生时对其进行处理并立即给出结果。