
如何使用 Google 实体和 GPT-4 创建文章大纲
已发表: 2023-06-06在本文中,您将学习如何使用一些抓取和 Google 的知识图来进行自动提示工程,为一篇文章生成大纲和摘要,如果写得好,将包含许多获得良好排名的关键要素。
从根本上讲,我们告诉 GPT-4 根据关键字和他们在您选择的排名良好的页面上找到的顶级实体生成文章大纲。
实体按其显着性分数排序。
“为什么显着性得分?” 你可能会问。
Google 在他们的 API 文档中将显着性描述为:
“实体的显着性分数提供了有关该实体对整个文档文本的重要性或中心性的信息。 接近 0 的分数不太显着,而接近 1.0 的分数非常显着。”
似乎是一个很好的指标,可以用来影响哪些实体应该存在于您可能想要编写的一段内容中,不是吗?
入门
有两种方法可以解决这个问题:
- 花大约 5 分钟(如果您需要设置计算机,则可能需要 10 分钟)并从您的机器上运行脚本,或者……
- 跳转到我创建的 Colab 并立即开始尝试。
我偏爱第一个,但我也跳到一两个 Colab。 😀
假设您还想在自己的机器上进行设置,但还没有安装 Python 或 IDE(集成开发环境),我将首先指导您快速阅读如何设置机器以供使用木星笔记本。 时间不应超过 5 分钟。
现在,是时候开始了!
使用 Google 实体和 GPT-4 创建文章大纲
为了让这更容易理解,我将按如下方式格式化说明:
- 步骤:我们正在进行的步骤的简要说明。
- 代码:完成该步骤的代码。
- Explanation :对代码正在做什么的简短说明。
第一步:告诉我你想要什么
在我们深入创建大纲之前,我们需要定义我们想要的东西。
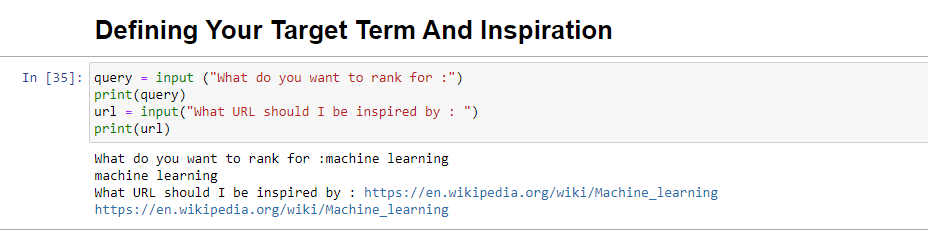
query = input ("What do you want to rank for :") print(query) url = input("What URL should I be inspired by : ") print(url)运行时,此块将提示用户(可能是您)输入您希望文章排名/关于的查询,并为您提供一个放置您想要的文章的 URL 的位置一块受到启发。
我会建议一篇排名不错的文章,其格式适合您的网站,并且您认为仅凭文章的价值而不仅仅是网站的实力就值得排名。
运行时,它看起来像:
第 2 步:安装所需的库
接下来,我们必须安装所有我们将用来实现奇迹的库。
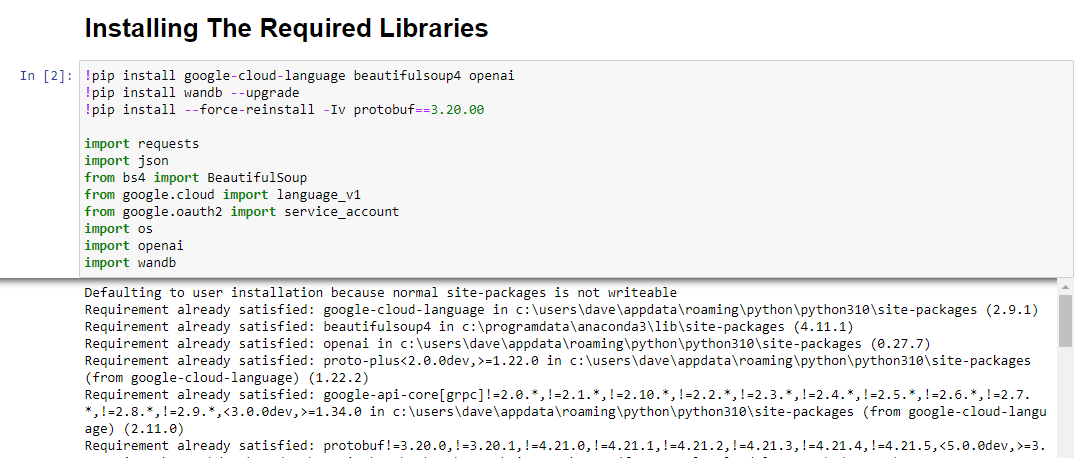
!pip install google-cloud-language beautifulsoup4 openai !pip install wandb --upgrade !pip install --force-reinstall -Iv protobuf==3.20.00 import requests import json from bs4 import BeautifulSoup from google.cloud import language_v1 from google.oauth2 import service_account import os import openai import pandas as pd import wandb我们正在安装以下库:
- Requests :该库允许发出 HTTP 请求以从网站或 Web API 检索内容。
- JSON :它提供了处理 JSON 数据的功能,包括将 JSON 字符串解析为 Python 对象以及将 Python 对象序列化为 JSON 字符串。
- BeautifulSoup :这个库用于网络抓取目的。 它有助于解析和导航 HTML 或 XML 文档并从中提取相关信息。
- Google.cloud.language_v1 :它是来自谷歌云的库,提供自然语言处理能力。 它允许对文本数据执行各种任务,如情感分析、实体识别和语法分析。
- Google.oauth2.service_account :这个库是 Google OAuth2 Python 包的一部分。 它支持使用服务帐户通过 Google API 进行身份验证,这是一种授予对 Google Cloud 项目资源的有限访问权限的方法。
- 操作系统:这个库提供了一种与操作系统交互的方法。 它允许访问各种功能,如文件操作、环境变量和进程管理。
- OpenAI :这个库是 OpenAI Python 包。 它提供了一个与 OpenAI 的语言模型交互的接口,包括 GPT-4(和 3)。 它允许开发人员生成文本、执行文本完成等。
- Pandas :它是一个强大的数据处理和分析库。 它提供数据结构和函数以有效地处理和分析结构化数据,例如表格或 CSV 文件。
- WandB :这个库代表“权重和偏差”,是一个用于实验跟踪和可视化的工具。 它有助于记录和可视化机器学习实验的指标、超参数和其他重要方面。
运行时,它看起来像这样:
获取搜索营销人员所依赖的每日时事通讯。
见条款。
第 3 步:身份验证
我将不得不暂时转移我们的注意力,以便让我们的身份验证到位。 我们需要一个 OpenAI API 密钥和谷歌知识图谱搜索凭证。
这只需要几分钟。
获取您的 OpenAI API
目前,您可能需要加入候补名单。 我很幸运能够及早访问 API,因此我写这篇文章是为了帮助您在获得 API 后尽快进行设置。
注册图像来自 GPT-3,一旦流程对所有人可用,将针对 GPT-4 进行更新。
在您可以使用 GPT-4 之前,您需要一个 API 密钥来访问它。
要获得一个,只需转到 OpenAI 的产品页面,然后单击“开始” 。
选择您的注册方式(我选择了 Google)并完成验证过程。 您需要使用可以接收此步骤文本的电话。
完成后,您将创建一个 API 密钥。 这样 OpenAI 就可以将您的脚本连接到您的帐户。
他们必须知道谁在做什么,并确定他们是否应该向您收取费用以及收取多少费用。
OpenAI 定价
注册后,您将获得 5 美元的信用额度,如果您只是进行试验,这将使您走得更远。
在撰写本文时,过去的定价是:

创建您的 OpenAI 密钥
要创建您的密钥,请单击右上角的个人资料并选择View API keys 。
...然后您将创建您的密钥。
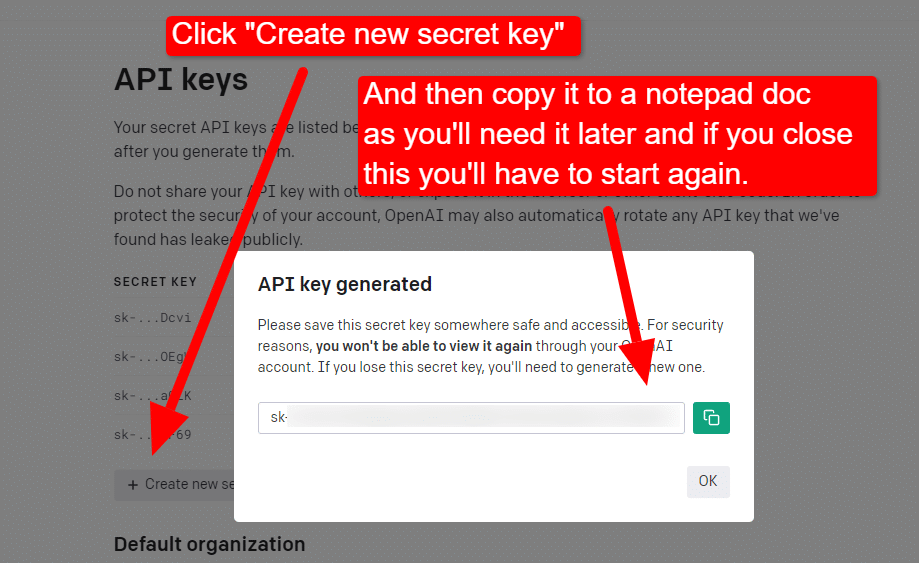
关闭灯箱后,您将无法查看您的密钥并且必须重新创建它,因此对于此项目,只需将其复制到记事本文档中即可使用。
注意:不要保存您的密钥(桌面上的记事本文档不是很安全)。 一旦你暂时使用它,关闭记事本文档而不保存它。
获取您的 Google Cloud 身份验证
首先,您需要登录您的 Google 帐户。 (你在一个 SEO 网站上,所以我假设你有一个。🙂)
完成此操作后,如果您愿意,可以查看知识图谱 API 信息,或者直接跳转到 API 控制台并开始使用。
一旦你在控制台:
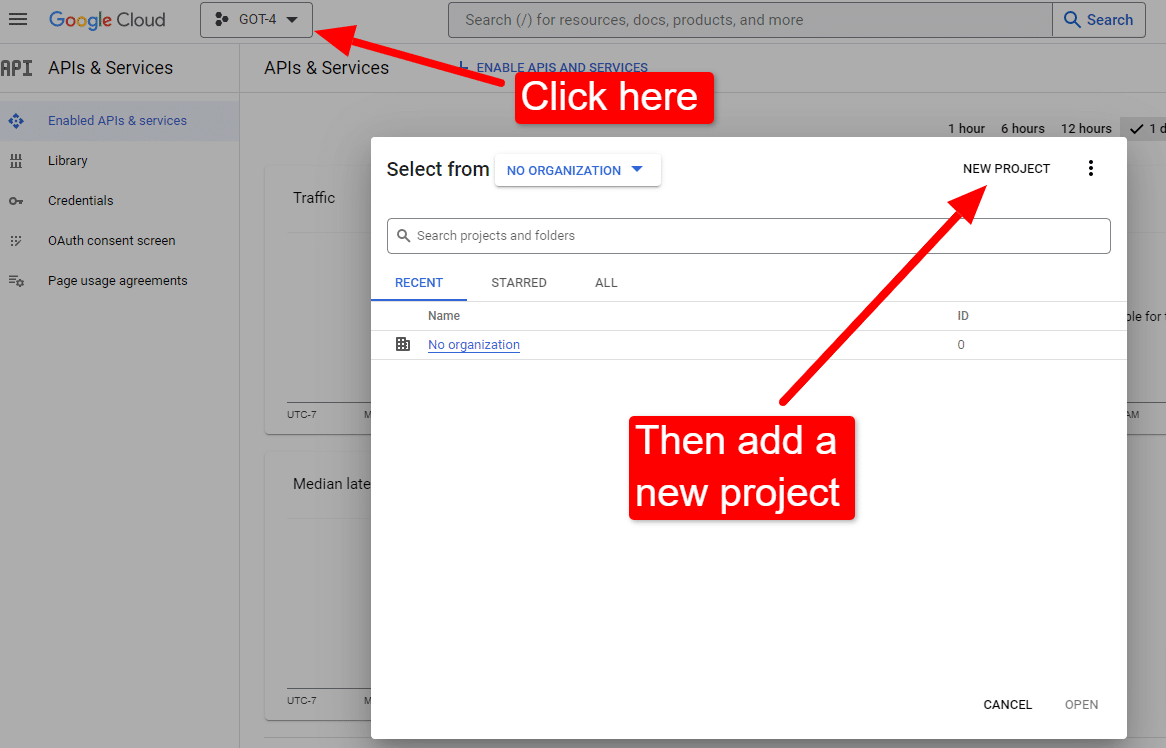
将其命名为“戴夫的精彩文章”。 你知道……很容易记住。
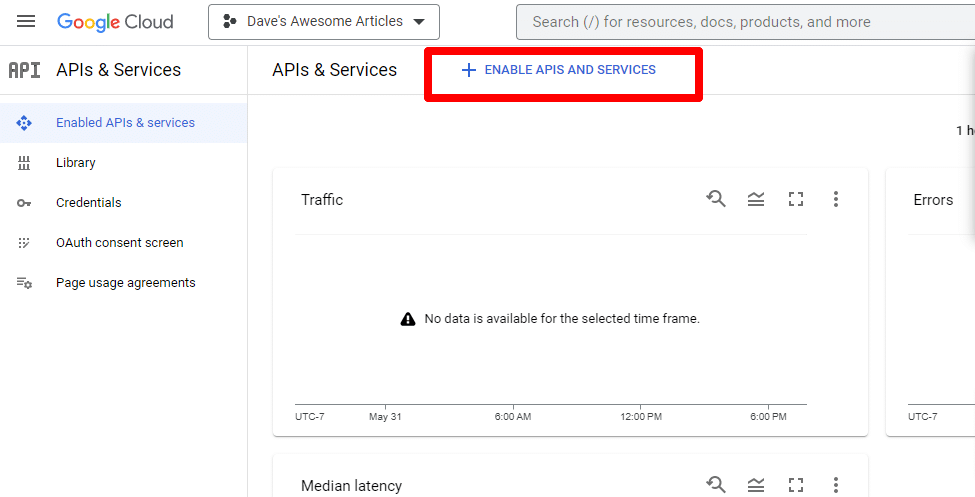
接下来,您将通过单击启用 API 和服务来启用 API。
找到 Knowledge Graph Search API,并启用它。
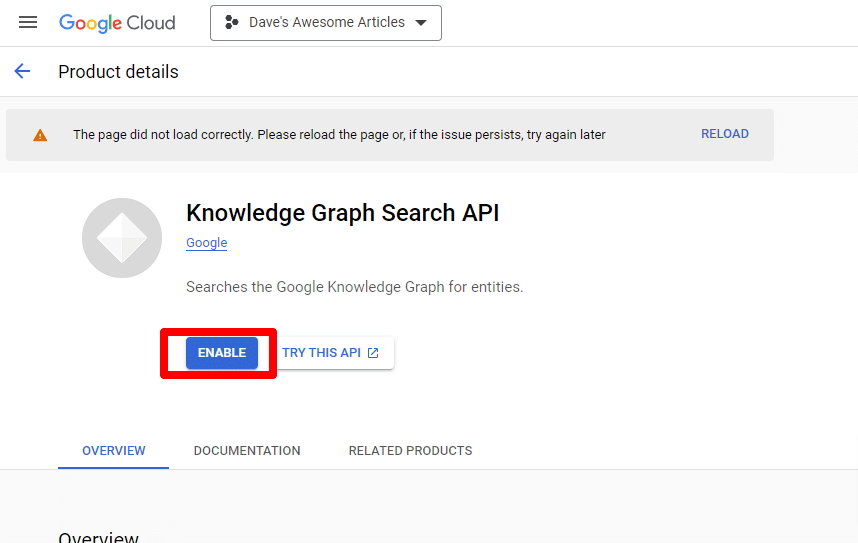
然后您将被带回主 API 页面,您可以在其中创建凭据:
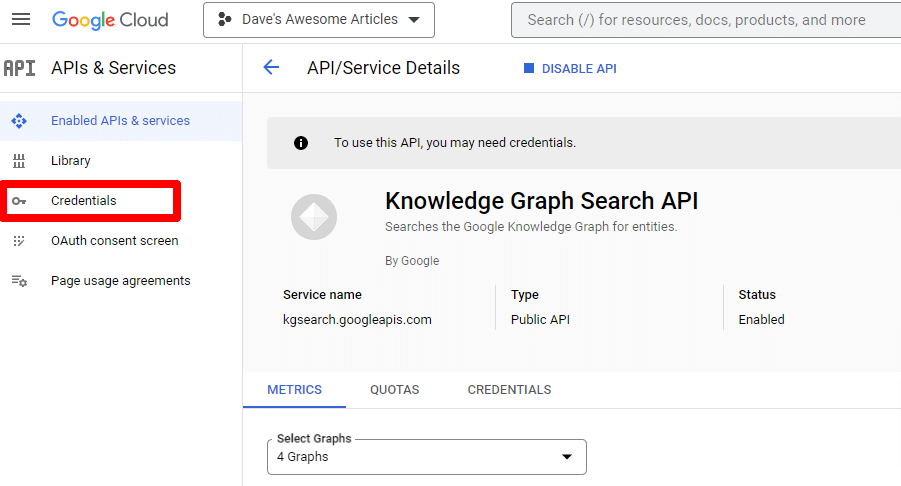
我们将创建一个服务帐户。
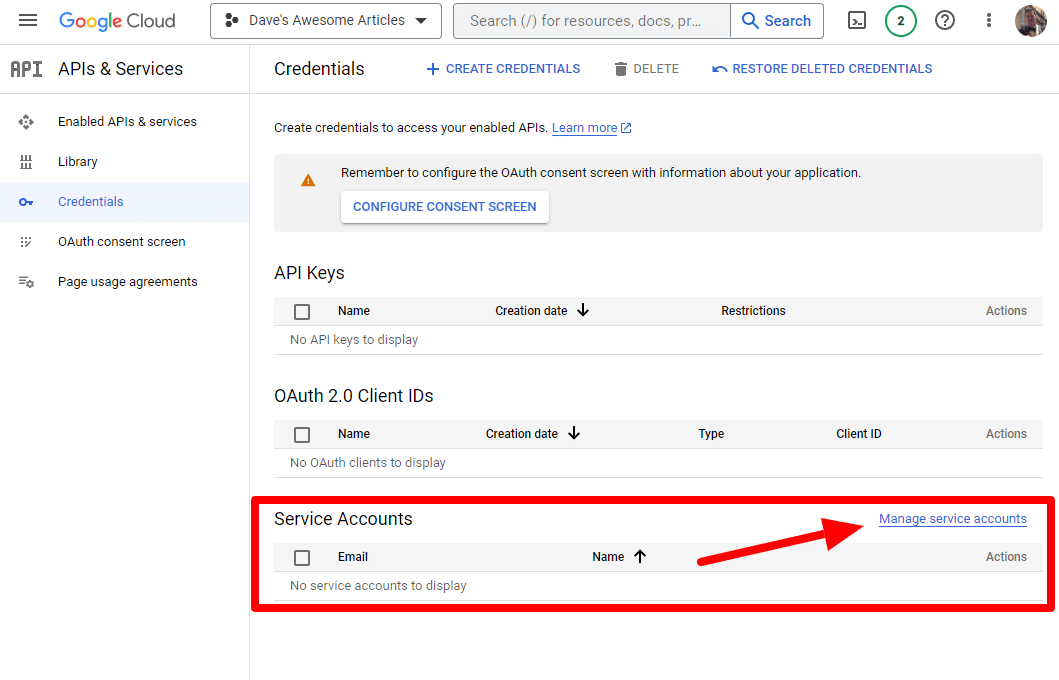
只需创建一个服务帐户:

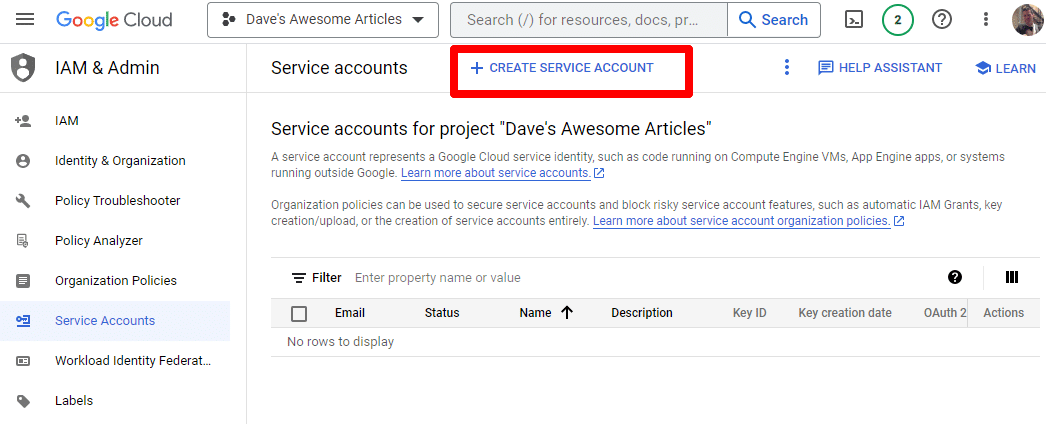
填写必填信息:
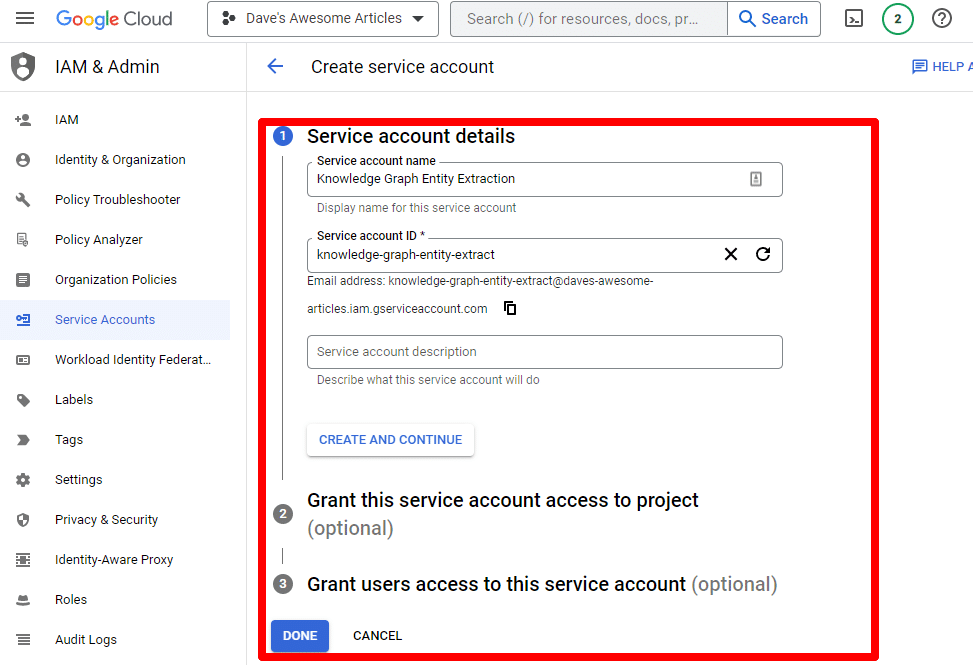
(您需要为其命名并授予其所有者权限。)
现在我们有了我们的服务帐户。 剩下的就是创建我们的密钥。
单击Actions下的三个点,然后单击Manage keys 。
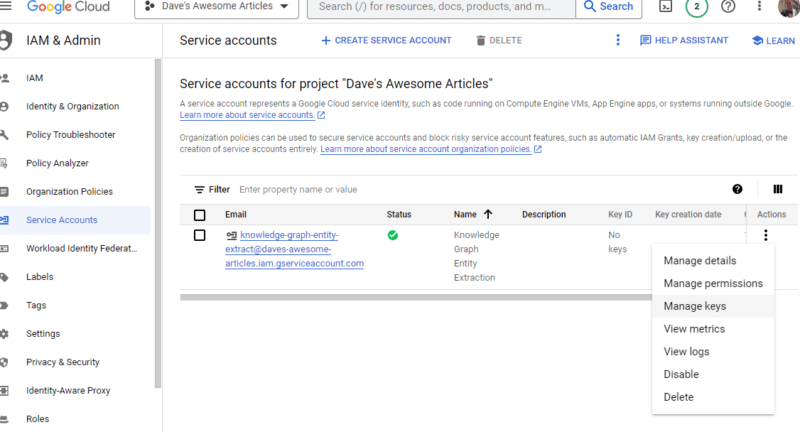
单击添加密钥然后创建新密钥:
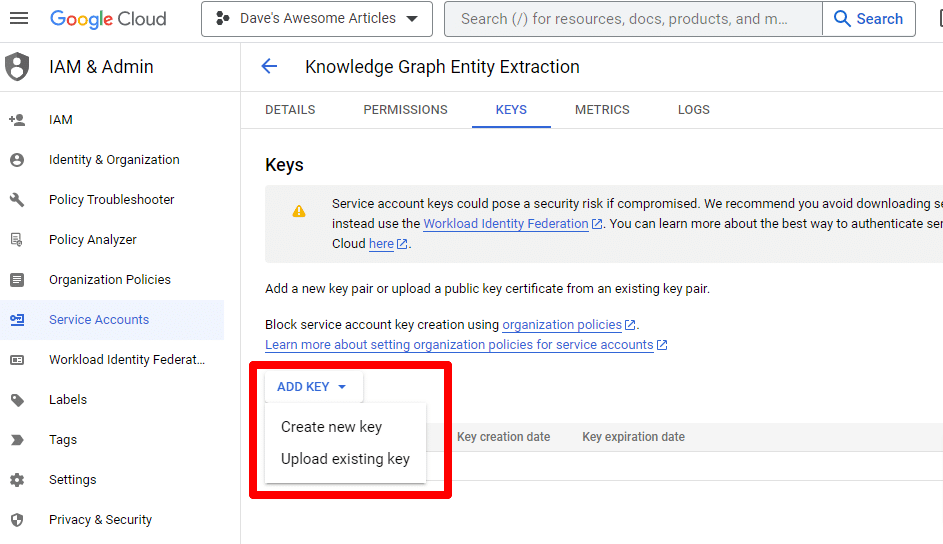
密钥类型将是 JSON。
您会立即看到它下载到您的默认下载位置。
此密钥将提供对您的 API 的访问权限,因此请妥善保管它,就像您的 OpenAI API 一样。
好吧……我们回来了。 准备好继续我们的脚本了吗?
现在我们有了它们,我们需要定义我们的 API 密钥和下载文件的路径。 执行此操作的代码是:
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/PATH-TO-FILE/FILENAME.JSON' %env OPENAI_API_KEY=YOUR_OPENAI_API_KEY openai.api_key = os.environ.get("OPENAI_API_KEY") 您将用您自己的密钥替换YOUR_OPENAI_API_KEY 。
您还将/PATH-TO-FILE/FILENAME.JSON替换为刚刚下载的服务帐户密钥的路径,包括文件名。
运行单元,您就可以继续了。
第 4 步:创建函数
接下来,我们将创建函数来:
- 抓取我们上面输入的网页。
- 分析内容并提取实体。
- 使用 GPT-4 生成文章。
#The function to scrape the web page def scrape_url(url): response = requests.get(url) soup = BeautifulSoup(response.content, "html.parser") paragraphs = soup.find_all("p") text = " ".join([p.get_text() for p in paragraphs]) return text #The function to pull and analyze the entities on the page using Google's Knowledge Graph API def analyze_content(content): client = language_v1.LanguageServiceClient() response = client.analyze_entities( request={"document": language_v1.Document(content=content, type_=language_v1.Document.Type.PLAIN_TEXT), "encoding_type": language_v1.EncodingType.UTF8} ) top_entities = sorted(response.entities, key=lambda x: x.salience, reverse=True)[:10] for entity in top_entities: print(entity.name) return top_entities #The function to generate the content def generate_article(content): openai.api_key = os.environ["OPENAI_API_KEY"] response = openai.ChatCompletion.create( messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, {"role": "user", "content": content}], model="gpt-4", max_tokens=1500, #The maximum with GPT-3 is 4096 including the prompt n=1, #How many results to produce per prompt #best_of=1 #When n>1 completions can be run server-side and the "best" used stop=None, temperature=0.8 #A number between 0 and 2, where higher numbers add randomness ) return response.choices[0].message.content.strip()这几乎正是评论所描述的。 我们正在为上述目的创建三个函数。
敏锐的眼睛会注意到:
messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, 你可以编辑内容( You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well. )并描述你希望 ChatGPT 扮演的角色。 您还可以添加语气(例如,“您是一位友善的作家……”)。
第 5 步:抓取 URL 并打印实体
现在我们开始动手了。 是时候:
- 抓取我们在上面输入的 URL。
- 提取段落标签中的所有内容。
- 通过 Google Knowledge Graph API 运行它。
- 输出实体以进行快速预览。
基本上,您想在这个阶段看到任何东西。 如果您什么也没看到,请检查其他站点。
content = scrape_url(url) entities = analyze_content(content)你可以看到第一行调用了抓取我们第一次输入的 URL 的函数。 第二行分析内容以提取实体和关键指标。
analyze_content 函数的一部分还打印找到的实体列表,以供快速参考和验证。
第 6 步:分析实体
当我第一次开始玩这个脚本时,我从 20 个实体开始,但很快发现这通常太多了。 但是默认值 (10) 对吗?
为了找出答案,我们会将数据写入 W&B 表以便于评估。 它将无限期地保留数据以供将来评估。
首先,您需要花大约 30 秒的时间进行注册。 (别担心,这类事情是免费的!)你可以在 https://wandb.ai/site 上这样做。
完成后,执行此操作的代码是:
run = wandb.init(project="Article Summary With Entities") columns=["Name", "Salience"] ent_table = wandb.Table(columns=columns) for entity in entities: ent_table.add_data(entity.name, entity.salience) run.log({"Entity Table": ent_table}) wandb.finish()运行时,输出如下所示:
当您单击链接查看您的跑步时,您会发现:
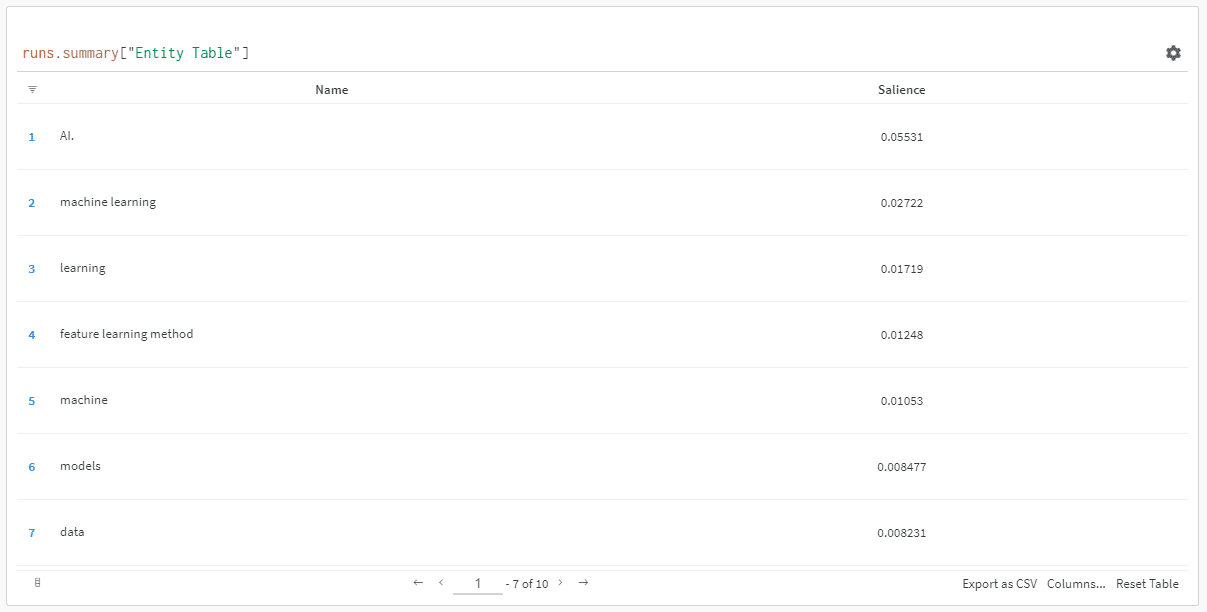
您可以看到显着性分数下降。 请记住,此分数计算的是该术语对页面而非查询的重要性。
查看此数据时,您可以选择根据显着性调整实体数量,或者仅在看到不相关的术语弹出时调整实体数量。
要调整实体的数量,您可以前往功能单元格并编辑:
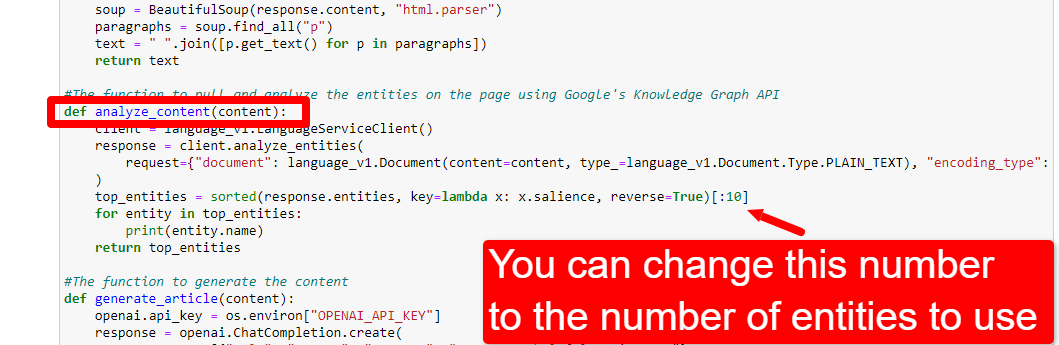
然后,您需要再次运行该单元格以及您运行的单元格以抓取和分析内容以使用新的实体计数。
第七步:生成文章大纲
您一直在等待的那一刻,就是生成文章大纲的时候了。
这分两部分完成。 首先,我们需要通过添加单元格来生成提示:
entity_names = [entity.name for entity in entities] gpt_prompt = f"Create an outline for an article about {query} that includes the following entities: {', '.join(entity_names)}." print(gpt_prompt)这实质上创建了生成文章的提示:

然后,剩下的就是使用以下内容生成文章大纲:
generated_article = generate_article(gpt_prompt) print(generated_article)这将产生类似的东西:
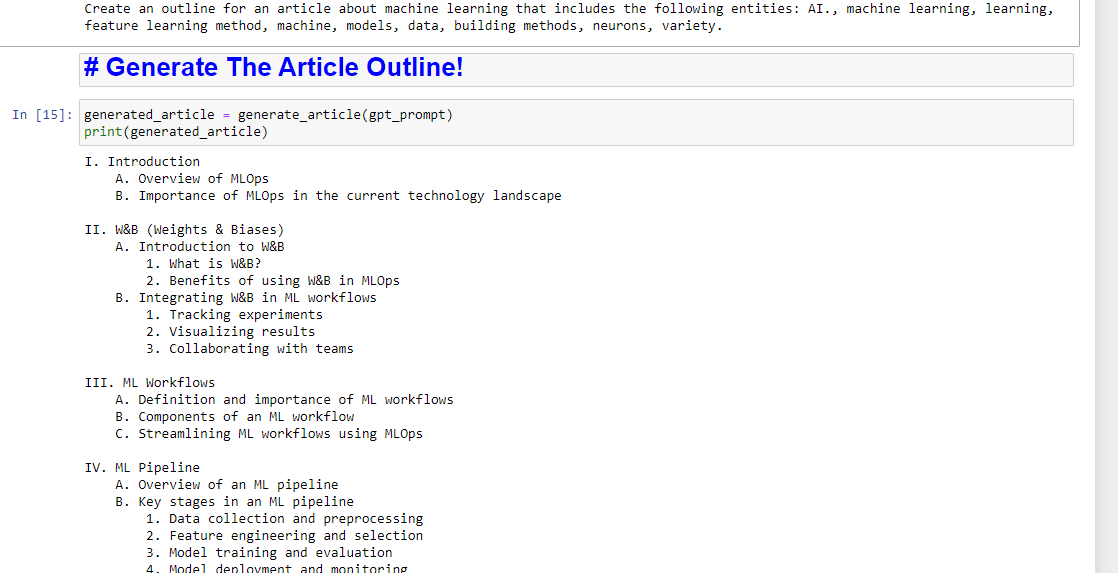
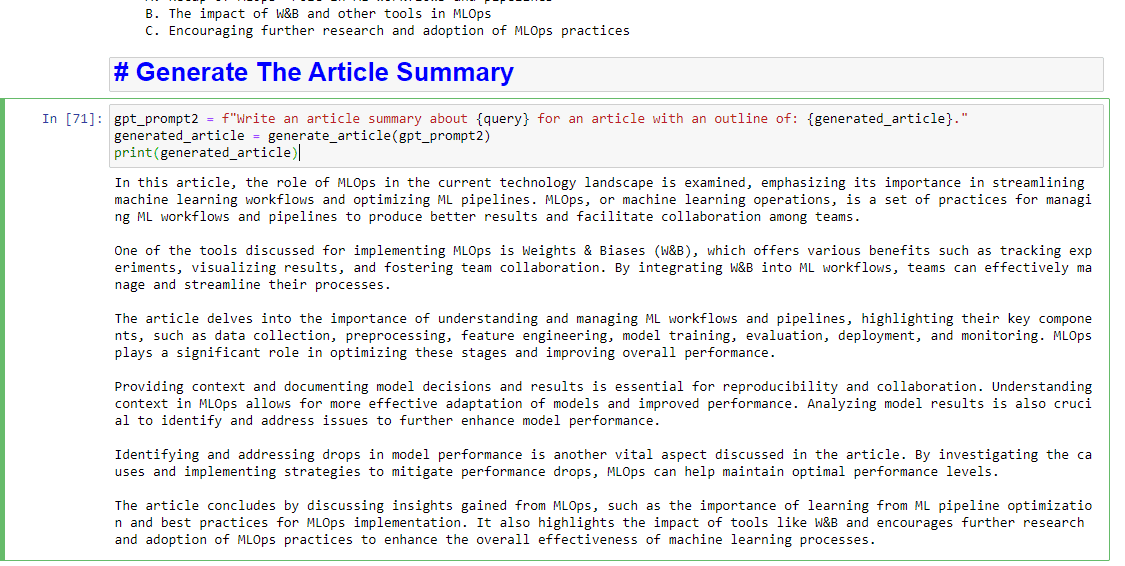
如果你还想写一个总结,你可以添加:
gpt_prompt2 = f"Write an article summary about {query} for an article with an outline of: {generated_article}." generated_article = generate_article(gpt_prompt2) print(generated_article)这将产生类似的东西:
本文中表达的观点是客座作者的观点,不一定是 Search Engine Land。 此处列出了工作人员作者。