
Google 如何通过 EEAT 识别和评估作者
已发表: 2023-04-17在对搜索结果进行排名时,谷歌更加重视内容来源,特别是作者。 SERP 中的观点、关于这个结果和关于这个作者的介绍清楚地表明了这一点。
本文探讨了 Google 如何通过作者的经验、专业知识、权威性和可信度 (EEAT) 来评估内容片段。
EEAT:谷歌的质量攻势
谷歌强调了 EEAT 概念对于提高搜索结果质量和 SERP 用户体验的重要性。
页面上的因素,如内容的一般质量、链接信号(即 PageRank 和锚文本)和实体级信号都起着至关重要的作用。
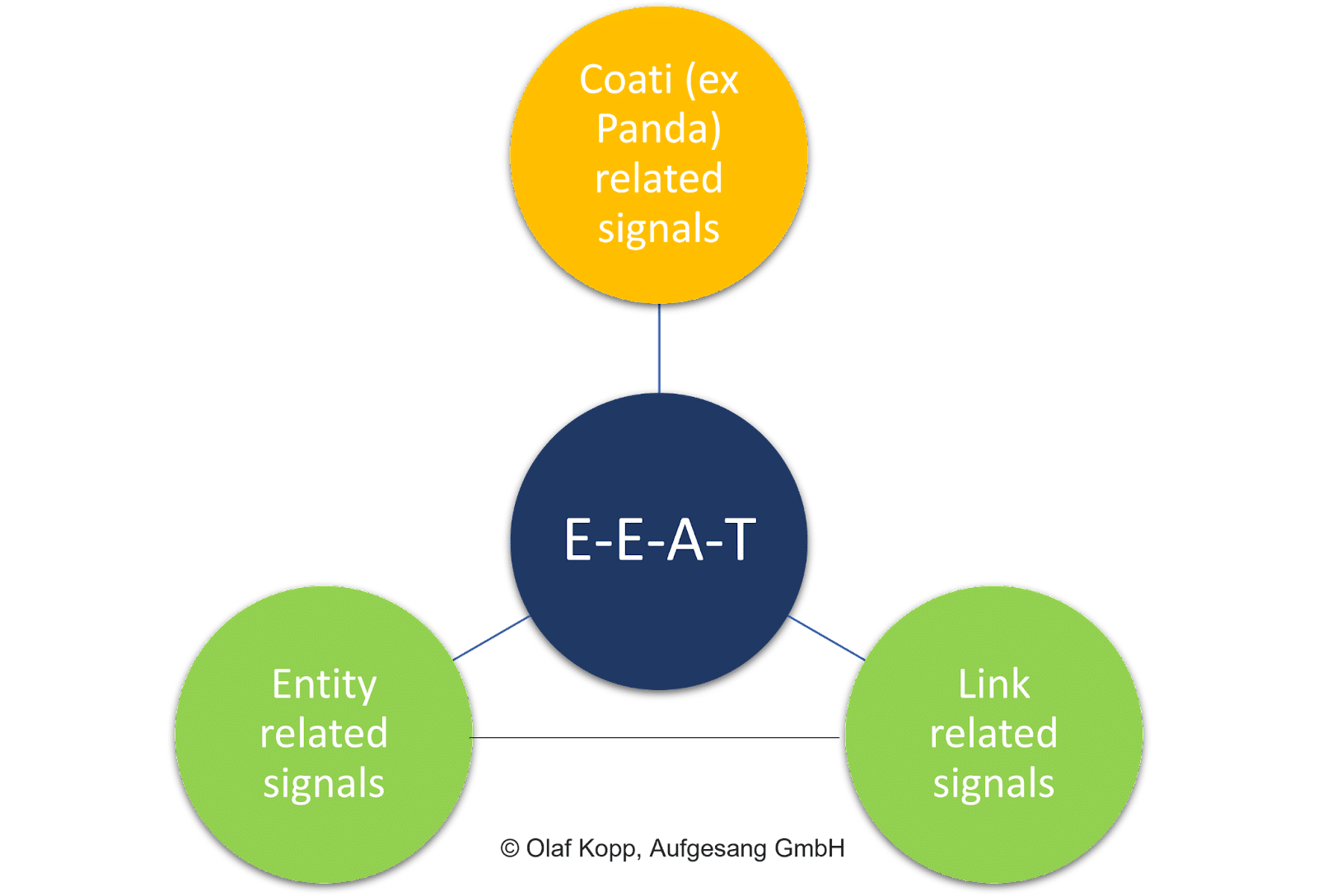
与文档评分相反,评估单个内容不是 EEAT 的重点。
该概念有一个与域和发起者实体相关的主题参考。 它独立于搜索意图和个人内容本身。
最终,EEAT 是一个独立于搜索查询的影响因素。
EEAT主要指的是主题领域,被理解为一个评估层,用于评估与公司、组织、人员及其领域等实体相关的内容和页外信号的集合。
作者作为内容来源的重要性
早在 (E-)EAT 之前,谷歌就试图将内容来源的评级纳入搜索排名。 例如,2009 年的 Vince 更新为品牌创建的内容提供了排名优势。
通过像 Knol 或 Google+ 这样早已结束的项目,谷歌试图收集作者评级的信号(即通过社交图谱和用户评级)。
在过去的 20 年里,谷歌的多项专利都直接或间接地提到了 Knol 等内容平台和 Google+ 等社交网络。
根据 EEAT 标准评估内容片段的来源或作者是进一步提高搜索结果质量的关键步骤。
由于人工智能生成的内容和经典垃圾邮件数量众多,谷歌将劣质内容纳入搜索索引毫无意义。
它在信息检索过程中索引和处理的内容越多,需要的计算能力就越大。
EEAT 可以帮助谷歌在更广泛的范围内根据实体、域和作者级别进行排名,而无需抓取每一条内容。
在这个宏观层面上,可以根据发起者实体对内容进行分类,并分配或多或少的抓取预算。 Google 还可以使用此方法从索引中排除整个内容组。
Google 如何识别作者和属性内容?
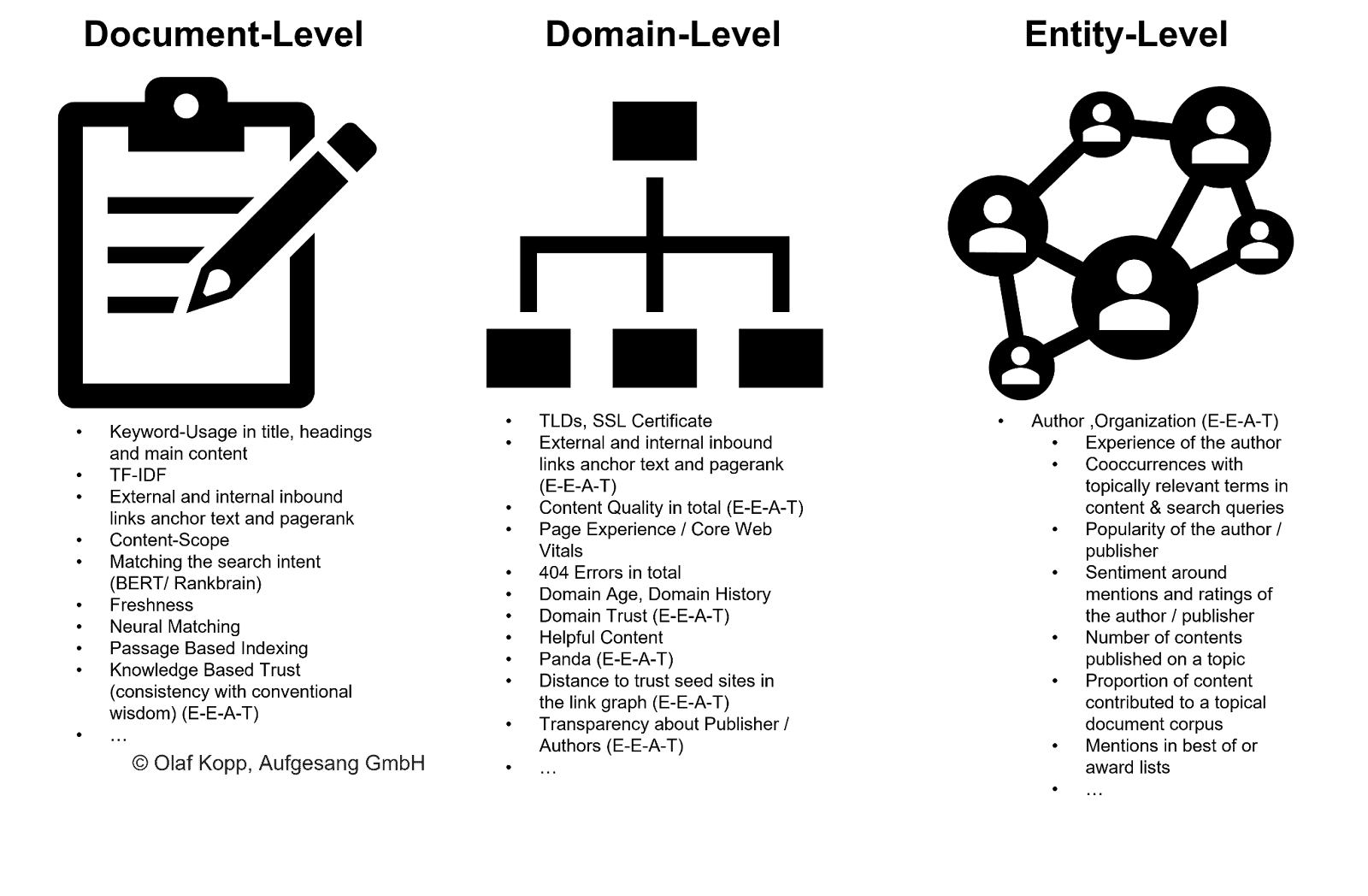
作者属于个人实体类型。 必须区分知识图谱中记录的已知实体和知识库(如知识库)中记录的先前未知或未经验证的实体。
即使实体尚未在知识图谱中捕获,谷歌也可以使用机器学习和语言模型从非结构化内容中识别和提取实体。 该解决方案称为命名实体识别 (NER),这是自然语言处理的一个子任务。
NER 根据语言模式识别实体,并分配实体类型。 一般来说,名词是(命名的)实体。
现代信息检索系统为此使用词嵌入 (Word2Vec)。
数字向量表示文本或文本段落的每个单词,实体可以表示为节点向量或实体嵌入 (Node2Vec/Entity2Vec)。
通过词性 (POS) 标记将单词分配到语法类别(名词、动词、介词等)。
名词通常是实体。 主体是主要实体,客体是次要实体。 动词和介词可以将实体彼此联系起来。
在下面的示例中,“olaf kopp”、“head of seo”、“co founder”和“aufgesang”是命名实体。 (NN = 名词)。
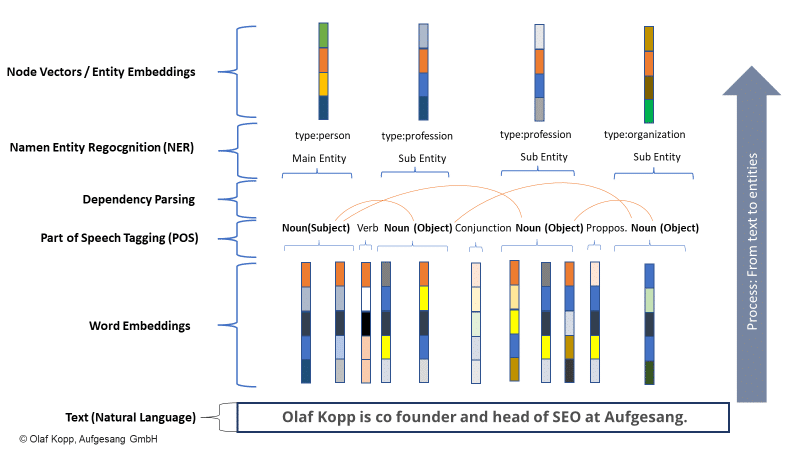
自然语言处理可以识别实体并确定它们之间的关系。
这创建了一个语义空间,可以更好地捕捉和理解实体的概念。
您可以在“Google 如何使用 NLP 更好地理解搜索查询和内容”中找到更多相关信息。
与作者嵌入对应的是文档嵌入。 通过向量空间分析将文档嵌入与作者向量进行比较。 (您可以在 Google 专利“生成文档的矢量表示”中了解更多信息。)
所有类型的内容都可以表示为向量,这允许:
- 要在向量空间中进行比较的内容向量和作者向量。
- 根据相似性对文档进行聚类。
- 要分配的作者。
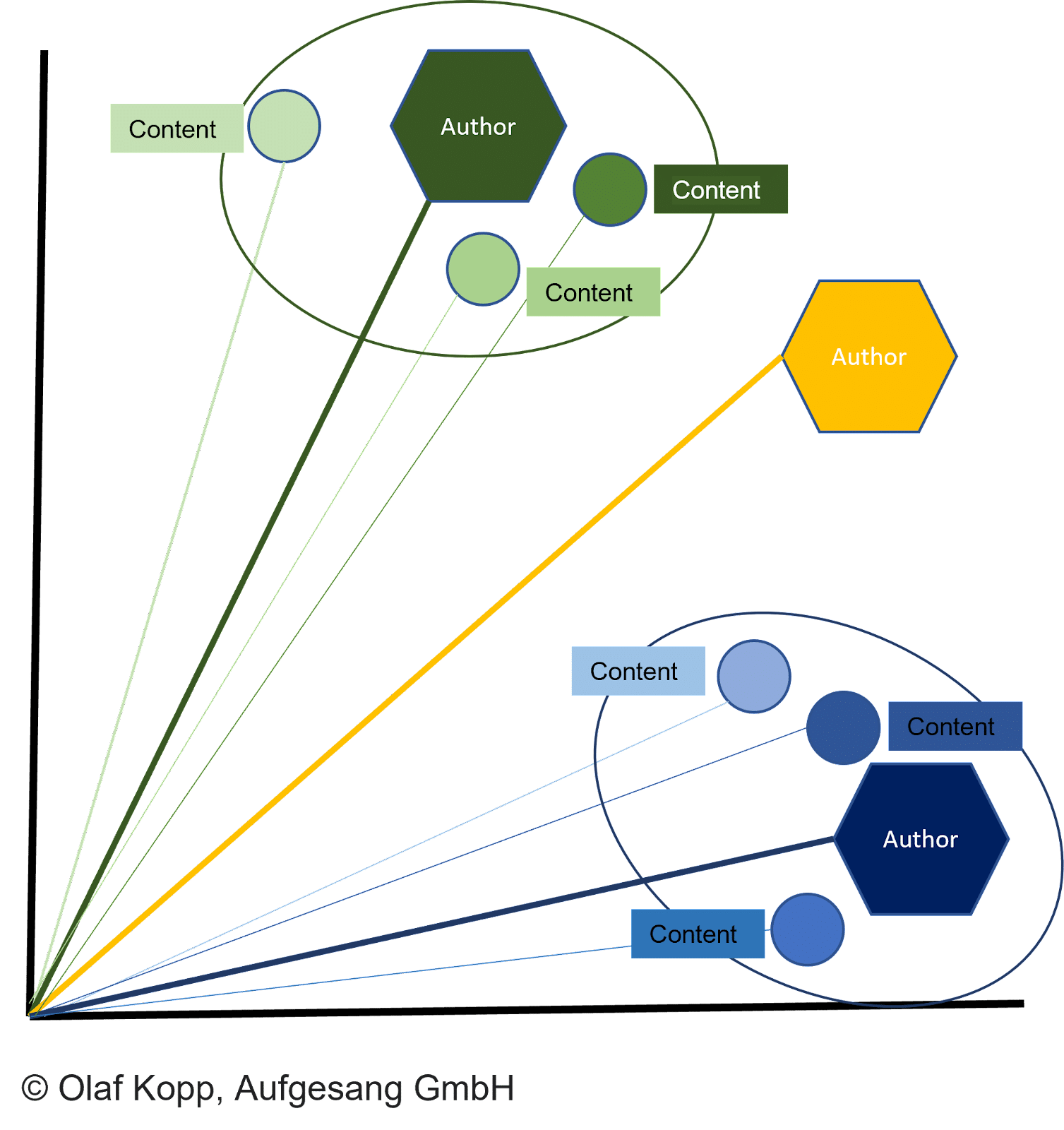
文档向量和相应的作者向量之间的距离描述了作者创建文档的概率。
如果距离小于其他向量并达到某个阈值,则文档归属于作者。
这也可以防止在错误标记下创建文档。 然后可以使用内容中指定的作者姓名将作者向量分配给作者实体,如前所述。
有关作者的重要信息来源包括:
- 关于此人的维基百科文章。
- 作者简介。
- 扬声器配置文件。
- 社交媒体资料。
如果你用谷歌搜索一个实体类型的人的名字,你会在前 20 个搜索结果中找到维基百科条目、作者的个人资料和与作者直接相关的域的 URL。
在移动 SERP 中,您可以看到 Google 与个人实体建立直接关系的来源。
谷歌将社交媒体资料图标上方的所有结果识别为直接引用该实体的来源。

这张“olaf kopp”搜索查询的屏幕截图显示实体链接到来源。
它还显示知识面板的新变体。 看来我已经成为这里 Beta 测试的一部分了。
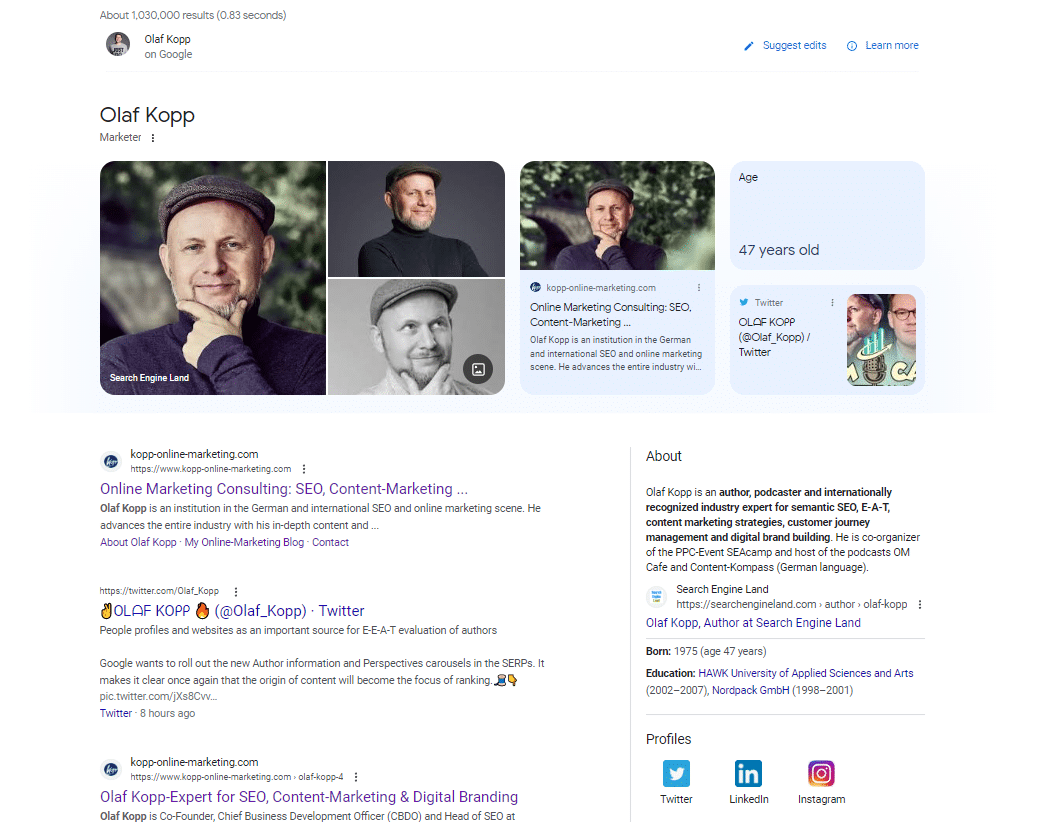
在此屏幕截图中,您会看到除了图像和属性(年龄)外,Google 还直接将我的域和社交媒体资料链接到我的实体,并将它们提供到知识面板中。
由于没有关于我的 Wikipedia 文章,关于描述来自美国 Search Engine Land 的作者简介和德国代理网站的作者简介。
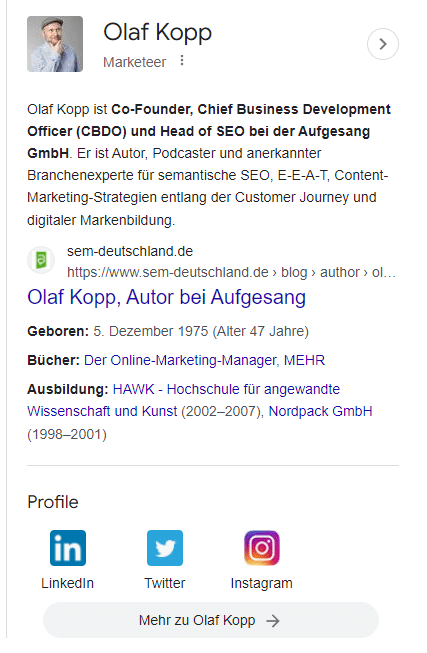
网络上的个人资料可帮助 Google 将作者置于上下文中并识别与作者相关的社交媒体资料和域。
作者资料中的作者框或作者收藏可帮助 Google 将内容分配给作者。 作者的名字不足以作为标识符,因为可能会出现歧义。
你应该注意每个人的作者描述,以确保一致性。 Google 可以使用它们来检查实体相互比较的有效性。
获取搜索营销人员所依赖的每日时事通讯。
见条款。
有趣的谷歌作者 EEAT 评级专利
以下专利分享了谷歌如何识别作者、为其分配内容并根据 EEAT 对其进行评估的可能方法。
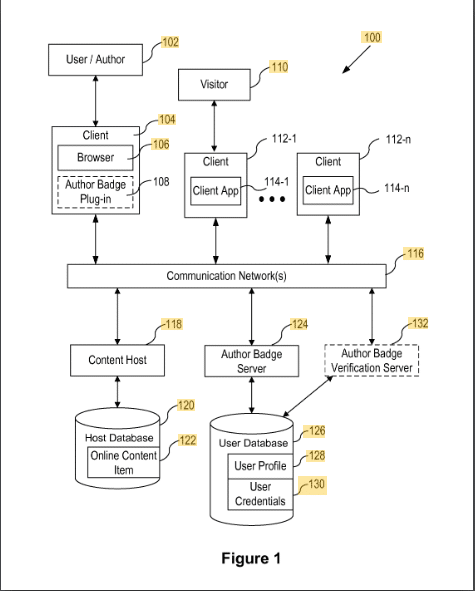
内容作者徽章
该专利描述了如何通过徽章将内容分配给作者。
使用电子邮件地址或作者姓名等 ID 将内容分配给作者徽章。 验证是通过作者浏览器中的插件完成的。
生成作者向量
谷歌于2016年签署了这项专利,有效期至2036年。不过目前只有美国有专利申请,这表明它尚未在全球范围内用于谷歌搜索。
该专利描述了如何根据训练数据将作者表示为向量。
矢量成为根据作者的典型写作风格和单词选择识别的唯一参数。
这样,以前不属于作者的内容可以分配给他们,或者类似的作者可以分组到集群中。
然后可以根据用户过去在搜索中的用户行为(例如在 Discover 上)为一个或多个作者调整内容排名。
因此,来自已经被发现的作者和来自相似作者的内容的排名会更好。
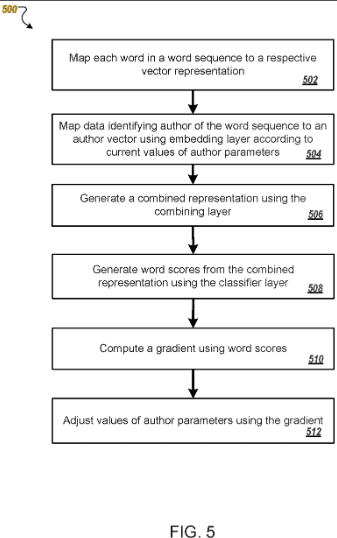
该专利基于所谓的嵌入,例如作者和词嵌入。
如今,嵌入已成为深度学习和自然语言处理的技术标准。
因此,很明显谷歌这样的方法也将用于作者识别和归属。
作者的声誉评分
该专利于 2008 年由 Google 首次签署,最低期限为 2029 年。该专利最初是指关闭已久的 Google Knol 项目。
因此,更令人兴奋的是,为什么谷歌在 2017 年将其重新命名为在线内容货币化的新标题。 Knol 在 2012 年被谷歌关闭。
该专利是关于确定声誉评分的。 为此可以考虑以下因素:
- 作者的框架水平。
- 在知名媒体发表文章。
- 出版物数量。
- 最近发布的年龄。
- 作者作为作者正式工作了多长时间。
- 作者内容生成的链接数。
一个作者的每个主题可以有多个信誉分数,每个主题领域可以有多个别名。
该专利中提出的许多观点都与 Knol 这样的封闭平台有关。 因此,该专利在这一点上应该足够了。
代理等级
这项谷歌专利于 2005 年首次签署,最短期限至 2026 年。
除美国外,它还在西班牙、加拿大和全球范围内注册,使其有可能被用于谷歌搜索。
该专利描述了如何将数字内容分配给代理人(出版商和/或作者)。 此内容根据代理等级等进行排名。
代理排名独立于搜索查询的搜索意图,并根据分配给代理的文档及其反向链接确定。
Agent Rank 专门指一个搜索查询、搜索查询集群或整个主题领域。
“代理排名也可以根据搜索词或搜索词类别来计算。 例如,搜索词(或搜索词的结构化集合,即查询)可以分类为主题,例如体育或医学专业,并且代理可以针对每个主题具有不同的排名。”
在线内容作者的可信度
这项谷歌专利于 2008 年首次签署,最短期限为 2029 年,迄今为止仅在美国注册。
Justin Lawyer 以与作者的专利声誉得分相同的方式开发它,并与搜索中的使用直接相关。
在该专利中,可以发现与上述专利相似的地方。
对我来说,这是在信任和权威方面评估作者的最令人兴奋的专利。
该专利引用了可用于通过算法确定作者可信度的各种因素。
它描述了搜索引擎如何在作者的可信度因素和声誉得分的影响下对文档进行排名。
一个作者可以有多个信誉分数,这取决于他们发布内容的不同主题的数量。
作者的信誉评分与出版商无关。
同样在该专利中,链接作为 EEAT 评级中的一个可能因素的参考。 已发布内容的链接数量会影响作者的信誉评分。
提到了以下可能的信誉评分信号:
- 作者在某个主题领域创作内容的时长。
- 作者的意识。
- 用户对已发布内容的评分。
- 如果另一家发布商以高于平均水平的评级发布作者的内容。
- 作者发布的内容量。
- 作者上次发表是在多久之前。
- 作者对类似主题的先前出版物的评分。
有关专利声誉评分的其他有趣信息:
- 一个作者可以有多个信誉分数,这取决于他们发布内容的不同主题的数量。
- 作者的信誉评分与出版商无关。
- 如果多次发布重复的内容或摘录,则信誉评分可能会降低。
- 已发布内容的链接数量会影响信誉分数。
此外,该专利解决了作者的可信度因素。 提到了以下影响因素:
- 有关作者的职业或在公司中的角色的已验证信息。 它还考虑了公司的信誉。
- 职业与发布内容主题的相关性。
- 作者的教育和培训水平。
- 作者的经验基于时间。 作者在某个主题上发表的时间越长,他就越可信。 作者/出版商的经验可以通过某个主题领域的首次出版日期通过算法为谷歌确定。
- 在某个主题上发布的内容数量。 如果一个作者就一个主题发表多篇文章,可以认为他是专家,具有一定的可信度。
- 到上次发布所用的时间。 自作者上次发表某个主题以来的时间越长,该主题的信誉得分可能下降得越多。 内容越新,排名越高。
- 在奖项和最佳名单中提及作者/出版商。
重新排列排名搜索结果的系统和方法
这项谷歌专利于 2013 年首次签署,最短期限至 2033 年。它已在美国和全球范围内注册,这使得谷歌很可能会使用它。
该专利的发明人之一是 Chung Tin Kwok,他曾参与多项与 EEAT 相关的谷歌专利。
该专利描述了搜索引擎如何除了对作者内容的引用之外,还可以考虑作者在作者评分中对主题文档语料库的贡献比例。
“在一些实施例中,确定各个实体的原始作者分数包括:识别已知内容索引中的多个内容部分,这些内容被识别为与各个实体相关联,多个部分中的每个部分代表预定量已知内容索引中的数据;计算已知内容索引中内容部分的第一个实例的多个部分的百分比。”
它描述了基于作者评分(包括引文评分)的搜索结果重新排名。 引文评分基于对作者文档的引用次数。
作者评分的另一个标准是作者为主题相关文档的语料库贡献的内容比例。
“[W]在此确定各个实体的作者分数包括:确定各个实体的引文分数,其中引文分数对应于引用与各个实体相关的内容的频率;确定原始作者分数相应实体,其中原始作者分数对应于与相应实体相关联的内容的百分比,该实体是已知内容索引中内容的第一个实例;以及使用预定函数组合引文分数和原始作者分数以产生作者得分。”
该专利的目的是识别“抄袭者”并降低其内容在排名中的排名,但也可用于作者的一般评价。
评价作者的关键因素
除了上述专利中列出的作者评估的可能因素之外,这里还有一些需要考虑的因素(其中一些我已经在我的文章“谷歌评估 EAT 的 14 种方式”中提到过)。
- 一个主题内容的整体质量:作者在一个主题上发表的关于他的内容的整体质量,与领域和格式无关,可能是 EEAT 的一个因素。 这方面的信号可以是用户信号、链接和内容级别的其他质量信号。
- PageRank 或对作者内容的引用。
- 作者在内容(播客、视频、网站、PDF、书籍)中与相关主题或术语同时出现。
- 作者在具有相关主题或术语的搜索查询中同时出现。
将 EEAT 应用于作者实体
机器学习方法可以从大规模的非结构化内容中识别和映射语义结构。
这使 Google 能够识别和理解比之前在知识图谱中显示的更多的实体。
因此,内容来源扮演着越来越重要的角色。 EEAT 可以通过算法应用于文档、内容和领域之外。
该概念还可以涵盖内容的作者实体(即,对内容负责的作者和组织)。
我认为我们将在未来几年看到 EEAT 对 Google 搜索产生更重大的影响。 这个因素对于排名甚至可能与个别内容的相关性优化一样重要。
本文中表达的观点是客座作者的观点,不一定是 Search Engine Land。 此处列出了工作人员作者。