
测试 Google 的搜索生成体验
已发表: 2023-05-31我已经可以访问 Google 的新搜索生成体验 (SGE) 大约一周了。
我决定使用我 3 月份比较顶级生成 AI 解决方案的小型研究中的相同 30 个查询,“正式”对其进行测试。 这些查询旨在突破每个平台的极限。
在本文中,我将分享一些关于 SGE 的定性反馈以及我的 30 个查询测试的快速发现。
开箱即用的搜索生成体验
谷歌在 5 月 10 日的谷歌 I/O 活动中宣布了其搜索生成体验 (SGE)。
SGE 是谷歌将生成人工智能融入搜索体验的尝试。 用户体验 (UX) 与 Bing Chat 略有不同。 这是一个示例屏幕截图:
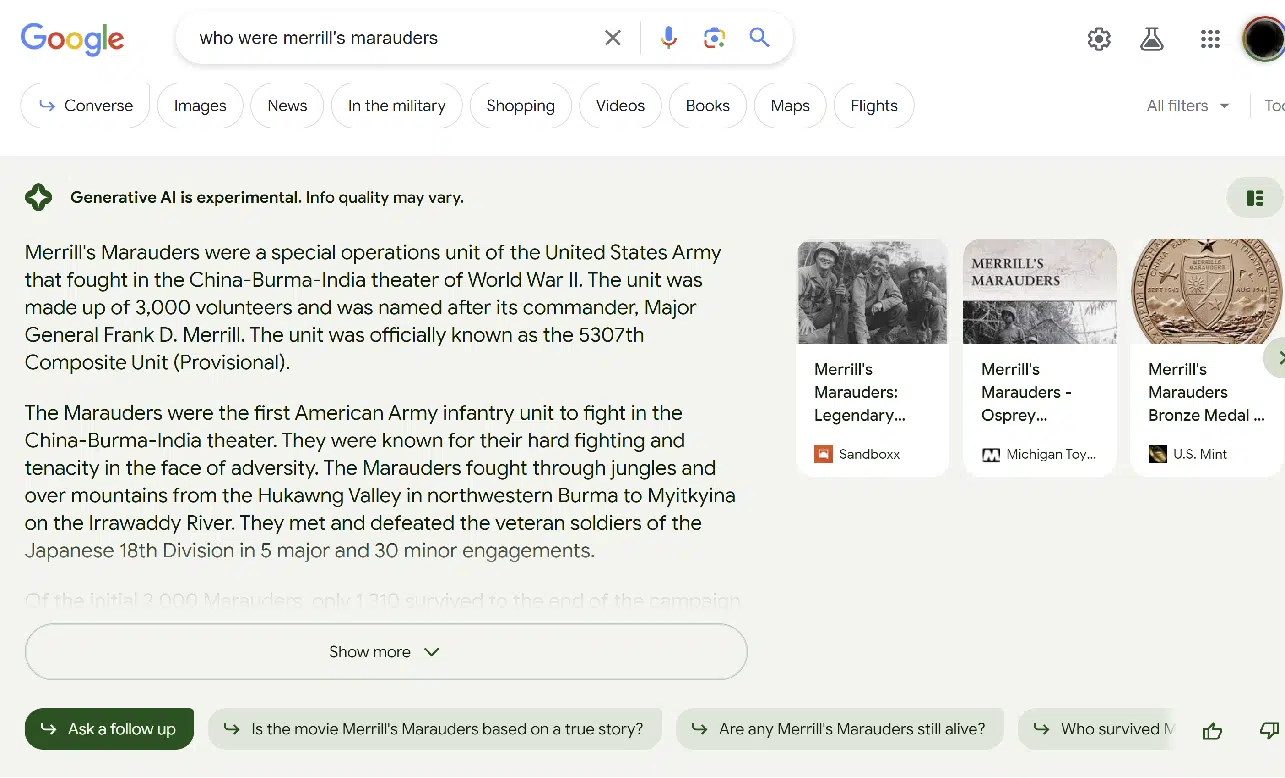
上图显示了搜索结果的 SGE 部分。
常规搜索体验位于 SGE 部分的正下方,如下所示:
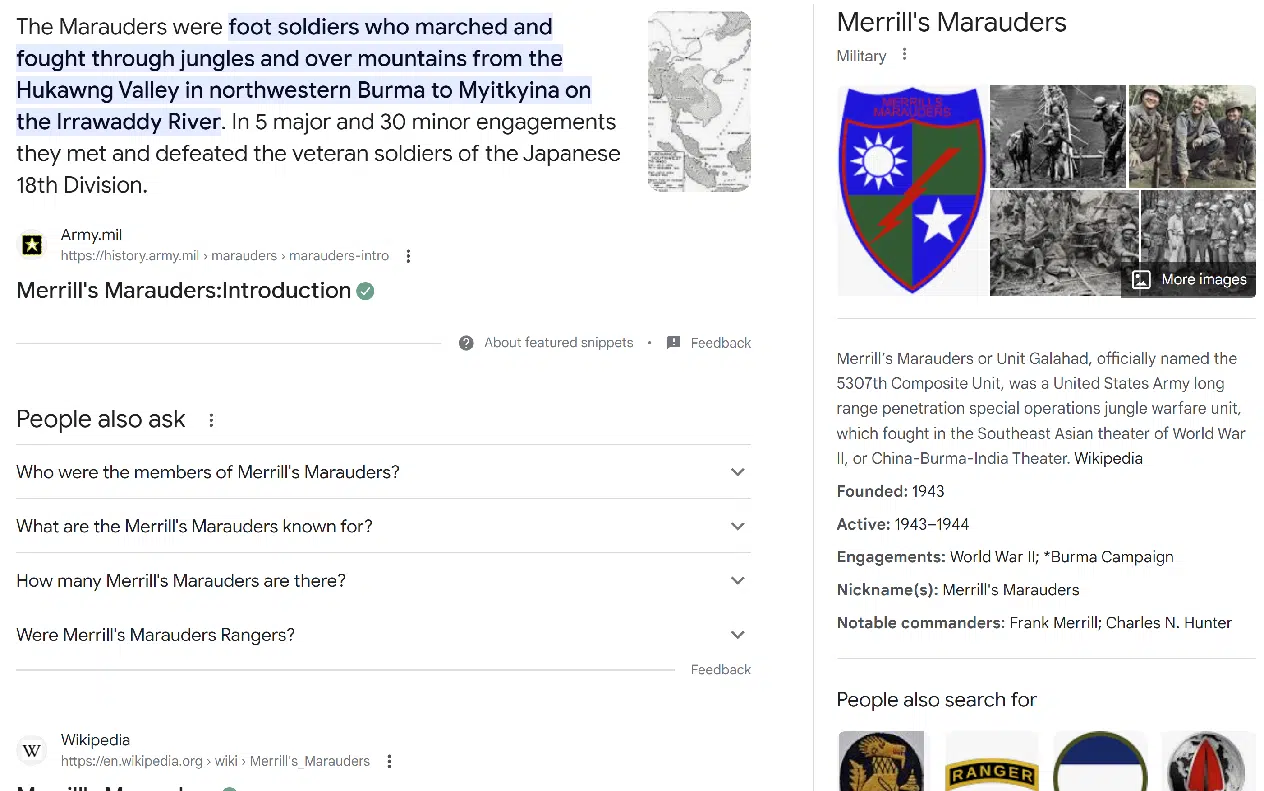
在许多情况下,上金所拒绝提供回应。 这通常发生在:
- Your Money or Your Life (YMYL) 查询,例如有关医疗或金融主题的查询。
- 被认为更敏感的话题(即与特定种族群体相关的话题)。
- 上金所回应的话题“令人不安”。 (更多内容见下文。)
SGE 总是在结果之上提供免责声明:“生成式 AI 是实验性的。 信息质量可能会有所不同。”
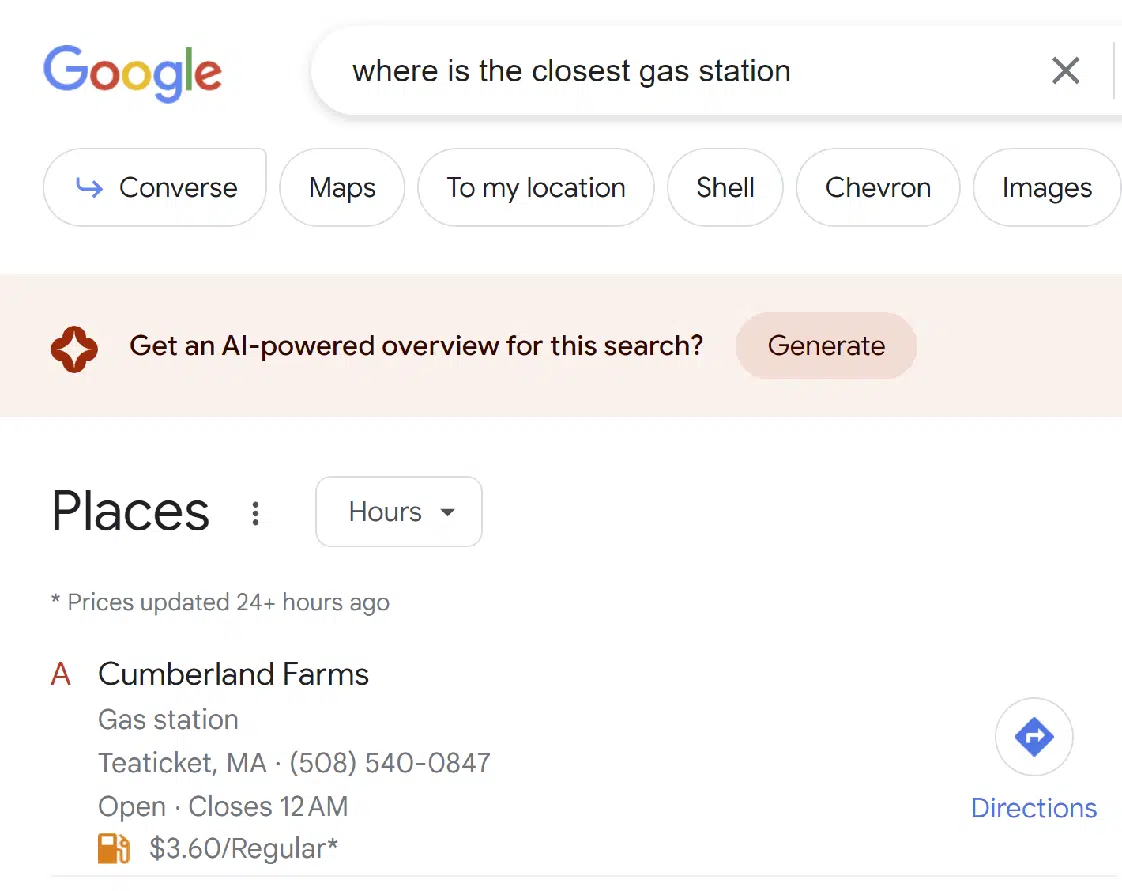
在某些查询中,Google 愿意提供 SGE 响应,但需要您先确认是否需要。
有趣的是,Google 将 SGE 合并到其他类型的搜索结果中,例如本地搜索:
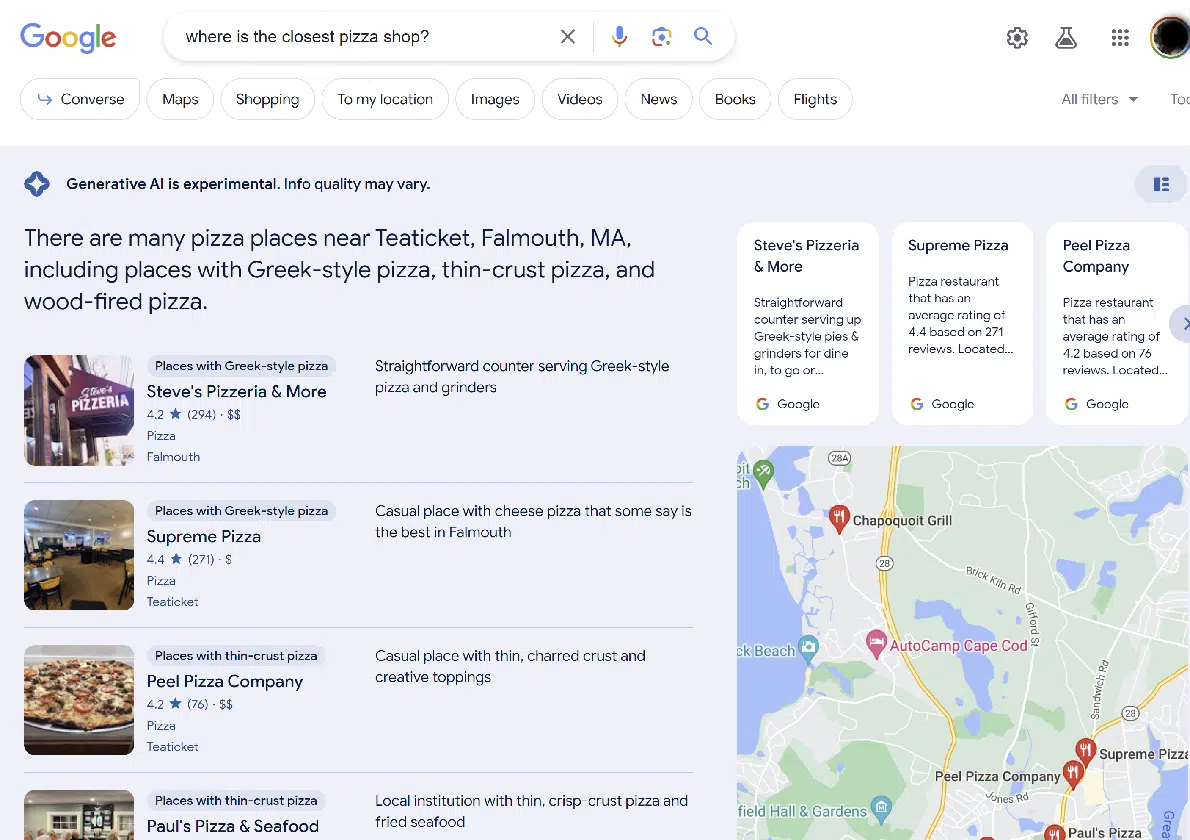
总的来说,我觉得体验还是不错的。 我比我想要的更频繁地获得 SGE 结果。 (虽然其他人可能想要与我正在寻找的不同的平衡。)
我希望 Google 会持续调整此界面。
获取搜索营销人员所依赖的每日时事通讯。
见条款。
小型研究的快速总结
请记住,我尝试了 30 个查询,而不是数百个。 因此,这不是具有统计意义的样本。 将其视为初始外观。
在被问及的 30 项查询中,上金所未对 11 项查询作出任何答复,具体而言:
- 创建一篇关于乌克兰战争现状的文章
- 写一篇关于 2023 年 3 月普京与习近平会晤的文章
- 谁制造最好的数码相机?
- 请找出 https://study.com/learn/cybersecurity.html 中的内容空白
- 请找出 https://www.britannica.com/biography/Larry-Bird 中的内容差距
- 请找出 https://www.consumeraffairs.com/finance/better-mortgage.html 中的内容差距
- 请找出 https://homeenergyclub.com/texas 中的内容差距
- 2023 年最佳投资策略是什么?
- 请讲一个关于犹太人的笑话
- 创建有关俄罗斯历史的文章大纲
- 为关于糖尿病患者的文章生成大纲
在所有这些情况下,结果看起来都像传统的搜索结果。 没有提供访问结果的 SGE 版本的方法。

还有三个查询,SGE 似乎开始生成响应然后决定不响应。 这些查询是:
- 阿道夫·希特勒是伟人吗?
- 请讲一个关于男人的笑话
- 请讲一个关于女人的笑话
您可以在下面看到这种方式的示例:
看起来谷歌在这个过程中的两个不同阶段实施过滤器。 与男人和女人有关的笑话查询在 SGE 考虑之前不会被过滤,但关于犹太人的笑话在这个过程中被过滤了。
至于关于阿道夫希特勒的问题,这个问题被设计成令人反感的,谷歌将其过滤掉是件好事。 将来这种类型的查询可能会得到人工响应。
SGE 确实对所有剩余的询问做出了回应。 这些曾经是:
- 讨论二战中俾斯麦号沉没的意义
- 讨论 1800 年代奴隶制对美国的影响。
- 以下哪家航空公司最好:美国联合航空公司、美国航空公司或捷蓝航空公司?
- 最近的披萨店在哪里?
- 我在哪里可以买到路由器?
- 丹尼沙利文是谁?
- 巴里·施瓦茨是谁?
- 埃里克·恩格是谁?
- 什么是美洲豹?
- 我可以为只吃橙色食物的挑食幼儿做些什么?
- 美国前总统唐纳德特朗普因多种原因面临被定罪的风险。 这将如何影响下届总统选举?
- 帮助我了解闪电是否可以两次击中同一个地方
- 如何识别自己是否感染了神经病毒?
- 你如何制作圆形桌面?
- 癌症最好的血液检查是什么?
- 请提供一篇关于狭义相对论的文章的大纲
答案质量差异很大。 最令人震惊的例子是关于唐纳德特朗普的询问。 这是我收到的对该查询的回复:
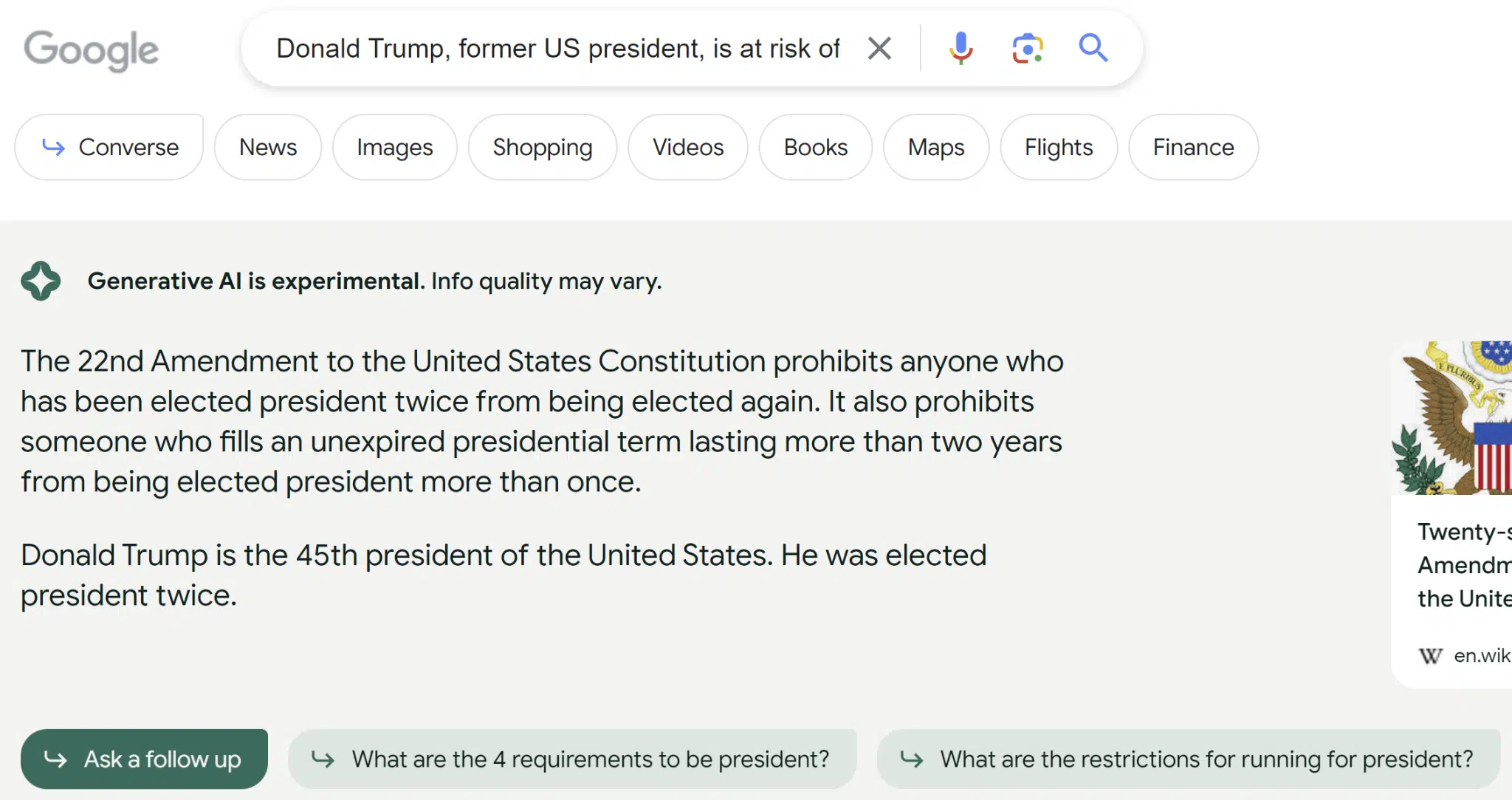
回应表明特朗普是美国第 45 任总统这一事实表明,用于 SGE 的指数已过时或未使用正确来源的网站。
尽管维基百科显示为来源,但该页面显示了有关唐纳德特朗普在 2020 年大选中输给乔拜登的正确信息。
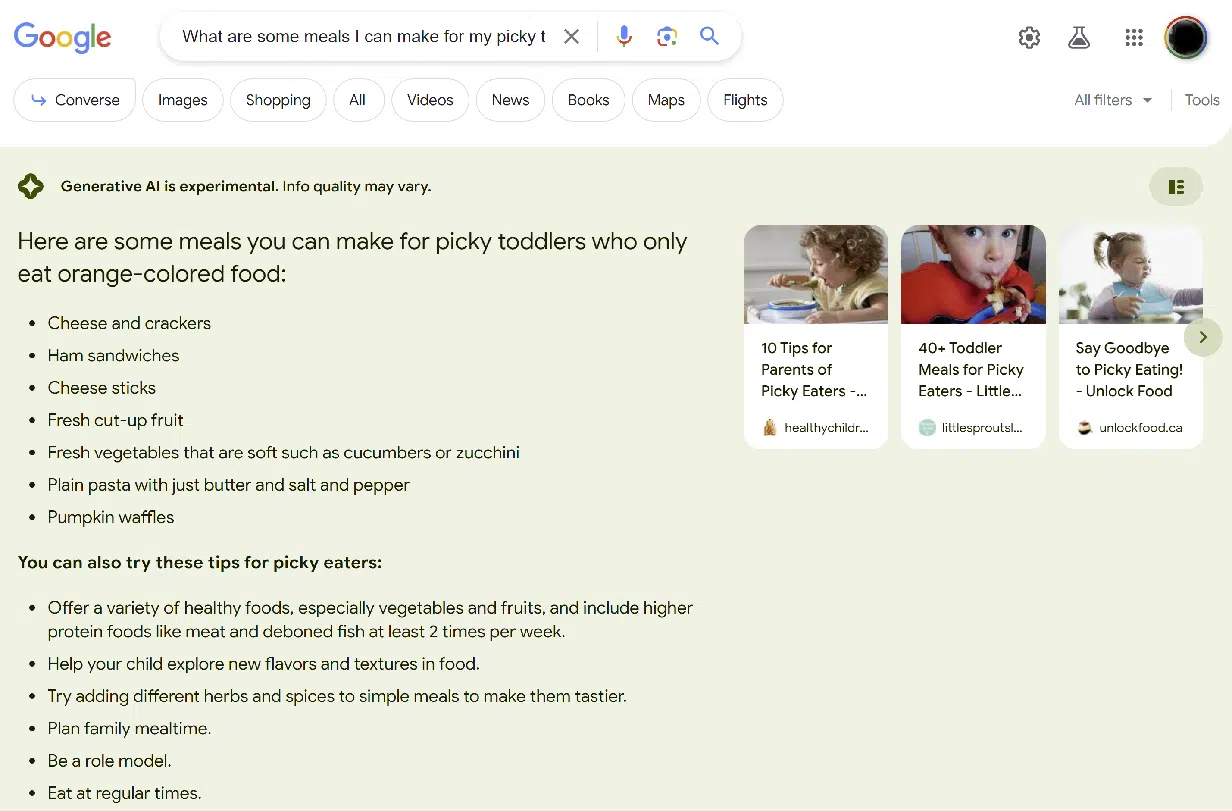
另一个明显的错误是关于给只吃橙色食物的幼儿喂什么的问题,这个错误没那么严重。
基本上,SGE 未能捕捉到查询中“橙色”部分的重要性,如下所示:
在 SGE 回答的 16 个问题中,我对其准确性的评估如下:
- 10 次是 100% 准确 (62.5%)
- 两次基本准确 (12.5%)
- 两次实质上不准确 (12.5%)
- 两次严重不准确 (12.5%)
此外,我还研究了 SGE 遗漏我认为对查询非常重要的信息的频率。 这方面的一个例子是查询 [what is a jaguar],如以下屏幕截图所示:
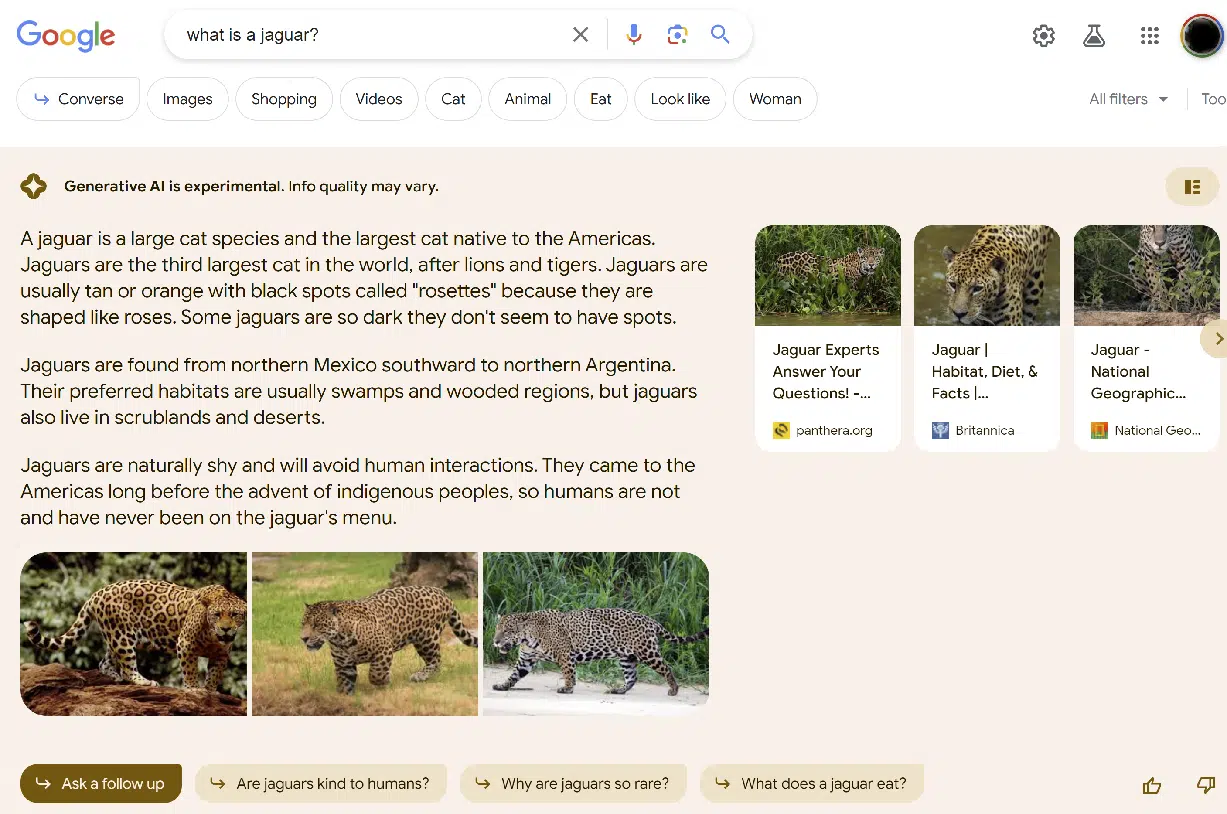
虽然提供的信息是正确的,但无法消除歧义。 因此,我将其标记为不完整。
我可以想象,对于这些类型的查询,我们可能会得到额外的提示,例如“你是说动物还是汽车?”
在 SGE 回答的 16 个问题中,我对其完整性的评估如下:
- 五次非常完整(31.25%)
- 它几乎完成了四次 (25%)
- 五次实质上不完整 (31.25%)
- 两次非常不完整 (12.5%)
当我做出判断时,这些完整性分数本质上是主观的。 其他人可能对我获得的结果进行了不同的评分。
一个充满希望的开始
总的来说,我认为用户体验是可靠的。
谷歌经常对使用生成式人工智能表现出谨慎态度,包括它没有回应的查询以及它回应但在顶部包含免责声明的查询。
而且,正如我们都知道的那样,生成式 AI 解决方案会犯错误——有时是错误的错误。
虽然谷歌、Bing 和 OpenAI 的 ChatGPT 将使用各种方法来限制这些错误发生的频率,但修复起来并不容易。
必须有人确定问题并决定修复方法。 我估计必须解决的这些类型的问题数量确实非常庞大,并且将它们全部识别出来将极其困难(如果不是不可能的话)。
本文中表达的观点是客座作者的观点,不一定是 Search Engine Land。 此处列出了工作人员作者。