
Hadoop 生态系统及其组件
已发表: 2015-04-23大数据是从 2008 年开始在 IT 行业流行的流行词。社交网络、制造、零售、股票、电信、保险、银行和医疗保健行业产生的数据量远远超出我们的想象。
在 Hadoop 出现之前,大数据的存储和处理是一个巨大的挑战。 但既然 Hadoop 可用,公司已经意识到大数据的业务影响以及理解这些数据将如何推动增长。 例如:
• 银行业有更好的机会了解忠诚客户、贷款违约者和欺诈交易。
• 零售业现在有足够的数据来预测需求。
• 制造业不必依赖昂贵的质量检测机制。 捕获传感器数据并对其进行分析将揭示许多模式。
• 电子商务、社交网络可以根据客户兴趣对页面进行个性化设置。
• 股票市场产生海量数据,不时关联将揭示美丽的见解。
大数据有许多有用且富有洞察力的应用。
Hadoop 是处理大数据的直接答案。 Hadoop生态系统是在解决业务问题方面具有熟练优势的技术组合。
让我们了解 Hadoop Ecosytem 中的组件,以便为给定的业务问题构建正确的解决方案。
Hadoop生态系统:
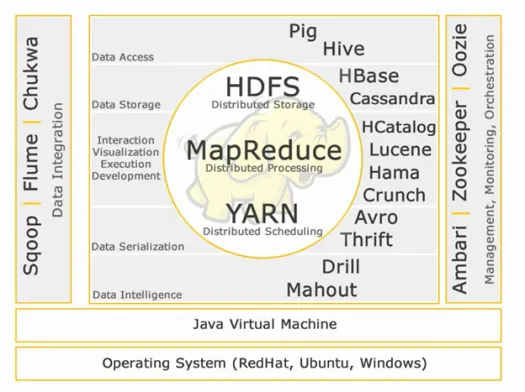

核心Hadoop:
HDFS:
HDFS 代表 Hadoop 分布式文件系统,用于管理具有高容量、速度和多样性的大数据集。 HDFS 实现了主从架构。 主节点是名称节点,从节点是数据节点。
特征:
• 可扩展
• 可靠的
• 商品硬件
HDFS 以大数据存储而闻名。
地图缩减:
Map Reduce 是一种旨在处理大量分布式数据的编程模型。 平台是使用 Java 构建的,以便更好地处理异常。 Map Reduce 包括两个守护进程,Job tracker 和 Task Tracker。
特征:
• 函数式编程。
• 非常适用于大数据。
• 可以处理大型数据集。
Map Reduce 是处理大数据的主要组件。
纱:
YARN 代表又一个资源谈判者。 它也被称为 MapReduce 2(MRv2)。 MRv1 中 Job Tracker 的两个主要功能,资源管理和作业调度/监控被拆分为独立的守护进程,即 ResourceManager、NodeManager 和 ApplicationMaster。
特征:
• 更好的资源管理。
• 可扩展性
• 集群资源的动态分配。
数据访问:
猪:
Apache Pig 是一种建立在 MapReduce 之上的高级语言,用于使用简单的即席数据分析程序分析大型数据集。 Pig 也称为数据流语言。 它与python很好地集成在一起。 它最初是由雅虎开发的。
猪的显着特点:
• 易于编程
• 优化机会
• 可扩展性。
内部的 Pig 脚本将被转换为 map reduce 程序。

蜂巢:
Apache Hive 是另一种建立在 Hadoop 之上的高级查询语言和数据仓库基础架构,用于提供数据汇总、查询和分析。 它最初由雅虎开发并开源。
蜂巢的显着特点:
• 类似于 SQL 的查询语言,称为 HQL。
• 分区和分桶以加快数据处理速度。
• 与Tableau 等可视化工具集成。
Hive 查询内部将被转换为 map reduce 程序。
如果你想成为一名大数据分析师,这两种高级语言是必须知道的!!

数据存储:
数据库:
Apache HBase 是一个 NoSQL 数据库,用于在 Hadoop 商品硬件机器上托管具有数十亿行和数百万列的大型表。 当您需要对大数据进行随机、实时的读/写访问时,请使用 Apache Hbase。
特征:
• 严格一致的读取和写入。 在内存操作中。
• 易于使用的Java API 进行客户端访问。
• 与猪、蜂巢和sqoop 完美集成。
• 是 CAP 定理中的一致和分区容忍系统。

卡桑德拉:
Cassandra 是一个 NoSQL 数据库,专为线性可扩展性和高可用性而设计。 Cassandra 基于键值模型。 由 Facebook 开发,以更快响应查询而闻名。
特征:
• 列索引
• 支持去规范化
• 物化视图
• 强大的内置缓存。

交互-可视化-执行-开发:
目录:
HCatalog 是一个表管理层,它为其他 Hadoop 应用程序提供配置单元元数据的集成。 它使使用 Apache pig、Apache MapReduce 和 Apache Hive 等不同数据处理工具的用户能够更轻松地读取和写入数据。
特征:
• 不同格式的表格视图。
• 数据可用性通知。
• 用于外部系统访问元数据的 REST API。

卢森:
Apache LuceneTM 是一个完全用 Java 编写的高性能、功能齐全的文本搜索引擎库。 它是一种适用于几乎所有需要全文搜索的应用程序的技术,尤其是跨平台的应用程序。
特征:
• 可扩展的高性能索引。
• 强大、准确和高效的搜索算法。
• 跨平台解决方案。
哈马:
Apache Hama 是一个基于 Bulk Synchronous Parallel (BSP) 计算的分布式框架。 以矩阵、图形和网络算法等大规模科学计算能力和知名。
特征:
• 简单的编程模型
• 非常适合迭代算法
• 支持纱线
• 协同过滤无监督机器学习。
• K-Means 聚类。
紧缩:
Apache crunch 是为简单高效的流水线化 MapReduce 程序而构建的。 该框架用于编写、测试和运行 MapReduce 管道。
特征:
• 以开发者为中心。
• 最少的抽象
• 灵活的数据模型。
数据序列化:
阿夫罗:
Apache Avro 是一个语言中立的数据序列化框架。 专为语言可移植性而设计,允许数据在读取和写入时可能比语言寿命更长。

节约:
Thrift 是一种开发用于构建接口以与基于 Hadoop 构建的技术进行交互的语言。 它用于为多种语言定义和创建服务。
数据智能:
钻头:
Apache Drill 是一个用于 Hadoop 和 NoSQL 的低延迟 SQL 查询引擎。
特征:
• 敏捷性
• 灵活性
• 熟悉度。

马豪:
Apache Mahout 是一个可扩展的机器学习库,设计用于在大数据上构建预测分析。 Mahout 现在已经实现了 apache spark 以更快地进行内存计算。
特征:
• 协同过滤。
• 分类
• 聚类
• 降维

数据整合:
Apache Sqoop:

Apache Sqoop 是为关系数据库和 Hadoop 之间的批量数据传输而设计的工具。
特征:
• 从HDFS 导入和导出。
• 从Hive 导入和导出。
• 导入和导出到 HBase。
阿帕奇水槽:
Flume 是一种分布式、可靠且可用的服务,用于高效收集、聚合和移动大量日志数据。
特征:
• 强壮的
• 容错
• 基于流数据流的简单灵活的架构。

阿帕奇楚夸:
用于监控大型分布式文件系统的可扩展日志收集器。
特征:
• 扩展到数千个节点。
• 可靠的交付。
• 应该能够无限期地存储数据。

管理、监控和编排:
阿帕奇安巴里:
Ambari 旨在通过提供用于配置、管理和监控 Apache Hadoop 集群的接口来简化 hadoop 管理。
特征:
• 配置Hadoop 集群。
• 管理Hadoop 集群。
• 监控Hadoop 集群。

阿帕奇动物园管理员:
Zookeeper 是一个集中式服务,旨在维护配置信息、命名、提供分布式同步和提供组服务。
特征:
• 序列化
• 原子性
• 可靠性
• 简单的 API

阿帕奇奥齐:
Oozie 是一个用于管理 Apache Hadoop 作业的工作流调度系统。
特征:
• 可扩展、可靠和可扩展的系统。
• 支持多种类型的Hadoop 作业,例如Map-Reduce、Hive、Pig 和Sqoop。
• 简单易用。

我们将在接下来的文章中详细讨论这些组件。 敬请关注。