
使用 Ambari 安装 Hadoop
已发表: 2015-12-11关于使用 Ambari 安装 Hadoop 你想知道的一切
Apache Hadoop 已成为可靠、可扩展、分布式和大规模计算的事实上的软件框架。 与其他计算系统不同,它将计算带入数据,而不是将数据发送给计算。 Hadoop 于 2006 年由 Doug Cutting 在雅虎根据谷歌发表的一篇论文创建。 随着 Hadoop 的成熟,多年来,许多新组件和工具被添加到其生态系统中,以增强其可用性和功能。 Hadoop HDFS、Hadoop MapReduce、Hive、HCatalog、HBase、ZooKeeper、Oozie、Pig、Sqoop 等等。
为什么是安巴里?
随着 Hadoop 的日益普及,许多开发人员跳入这项技术来体验它。 但正如他们所说,Hadoop 不适合胆小的人,许多开发人员甚至无法跨越安装 Hadoop 的障碍。 许多发行版都提供了预装的虚拟机沙箱来尝试一些东西,但它并没有给你分布式计算的感觉。 然而,安装多节点并不是一件容易的事,而且随着组件数量的增加,处理如此多的配置参数非常棘手。 谢天谢地,Apache Ambari 来到这里来拯救我们!
什么是安巴里?
Apache Ambari 是一个基于 Web 的工具,用于配置、管理和监控 Apache Hadoop 集群。 Ambari 提供了一个仪表板,用于查看集群健康状况,例如热图,并能够直观地查看 MapReduce、Pig 和 Hive 应用程序以及以用户友好的方式诊断其性能特征的功能。 它有一个非常简单和交互式的 UI 来安装各种工具并执行各种管理、配置和监控任务。 下面我们将带您完成在多节点集群上安装 Hadoop 及其各种生态系统组件的各个步骤。
Ambari 架构如下图所示
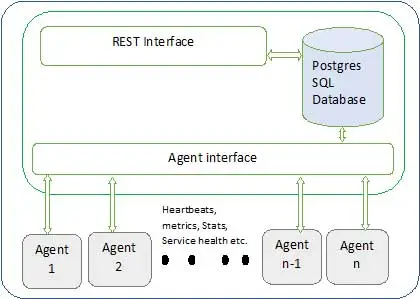
Ambari 有两个组件
- Ambari 服务器——这是与安装在参与集群的每个节点上的 Ambari 代理进行通信的主进程。 这具有 postgres 数据库实例,用于维护所有与集群相关的元数据。
- Ambari 代理- 这些是每个节点上 Ambari 的代理代理。 每个代理都会定期发送自己的健康状态以及不同的指标、已安装的服务状态等等。 根据 master 决定下一个动作并传回给 agent 动作。
如何安装安巴里?
Ambari 安装很容易,只需几个命令即可完成。
我们将介绍 Ambari 安装和集群设置。 我们假设有 4 个节点。 节点 1、节点 2、节点 3 和节点 4。 我们选择 Node1 作为我们的 Ambari 服务器。
这些是在基于 RHEL 的系统上的安装步骤,对于 debian 和其他系统的步骤会有所不同。
- Ambari 的安装:-
从 Ambari 服务器节点(我们决定的节点 1)
一世。 下载 Ambari 公共回购

此命令会将 Hortonworks Ambari 存储库添加到 yum 中,yum 是 RHEL 系统的默认包管理器。
ii.安装 Ambari RPMS

这将需要一些时间,并将在此系统上安装 Ambari。

iii. 配置 Ambari 服务器
安装 Ambari 后要做的下一件事是配置 Ambari 并将其设置为供应集群。
以下步骤将解决此问题


iv. 启动服务器并登录到 Web UI
启动服务器

现在我们可以访问 Ambari Web UI(托管在 8080 端口上)。
使用默认用户名“admin”和默认密码“admin”登录 Ambari
搭建Hadoop集群
1.登陆页面
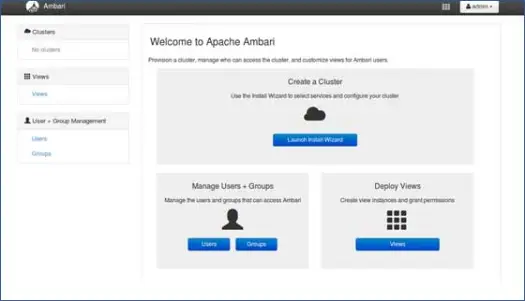
单击“启动安装向导”开始集群设置
2.集群名称
给你集群起个好听的名字。
注意:这只是集群的一个简单名称,意义不大,所以不要担心,随便取一个名字。
3.栈选择
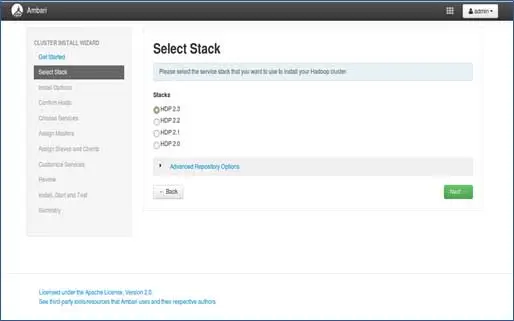
此页面将列出可安装的堆栈。 每个堆栈都预先打包了 Hadoop 生态系统组件。 这些堆栈来自 Hortonworks。 (我们也可以安装普通的 Hadoop。我们将在后面的文章中介绍)。
4.Hosts入口和SSH密钥入口
在进一步执行此步骤之前,我们应该为所有参与节点设置无密码 SSH。
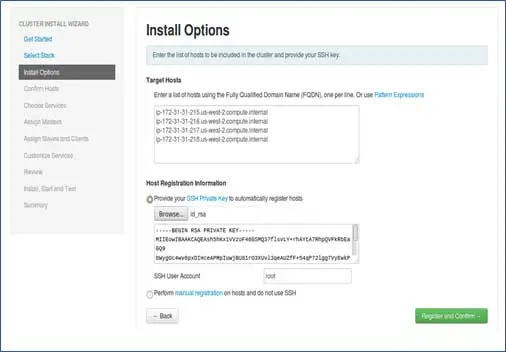

添加节点的主机名,每行单个条目。 [添加可以通过hostname –f命令获取的FQDN]。 选择设置无密码 SSH 时使用的私钥和创建私钥的用户名。
5. 主机注册状态
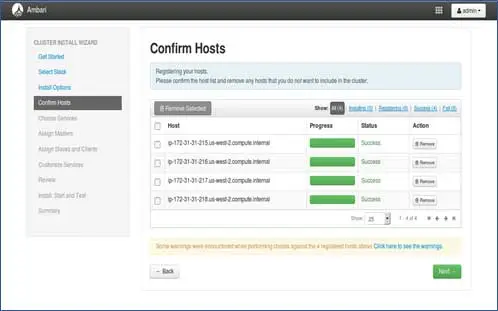
您可以看到正在执行的一些操作,这些操作包括在每个节点上设置 Ambari-agent,在每个节点上创建基本设置。 一旦我们看到 ALL GREEN,我们就可以继续前进了。 有时这可能需要一些时间,因为它安装的软件包很少。

6.选择您要安装的服务
根据步骤 3 中选择的堆栈,我们拥有可以在集群中安装的服务数量。 你可以选择你想要的。 如果您没有选择依赖服务,Ambari 会智能地选择它。 例如,您选择了 HBase 但未选择 Zookeeper,它会提示相同并将 Zookeeper 也添加到集群中。
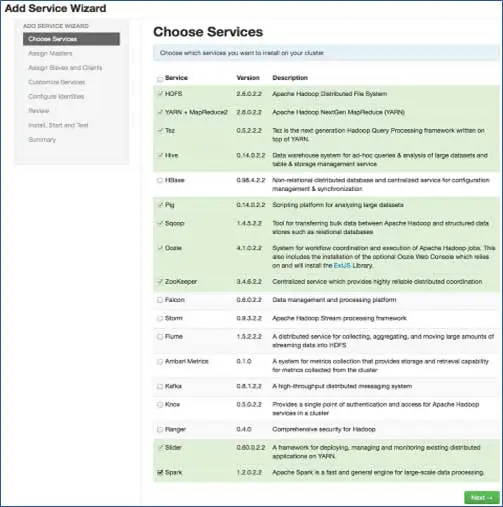
7. 与节点的主服务映射
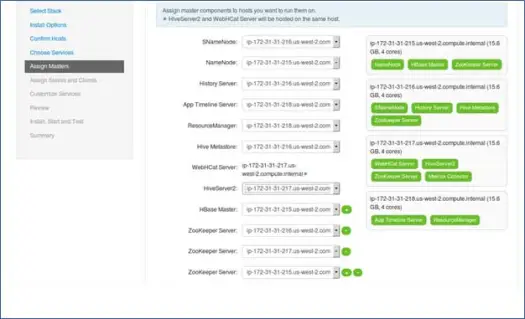
如您所知,Hadoop 生态系统拥有基于主从架构的工具。 在这一步中,我们将主进程与节点相关联。 在这里确保您正确平衡您的集群。 另外,请记住主要和辅助服务,如 Namenode 和辅助 Namenode 不在同一台机器上。

8. 从节点与节点的映射
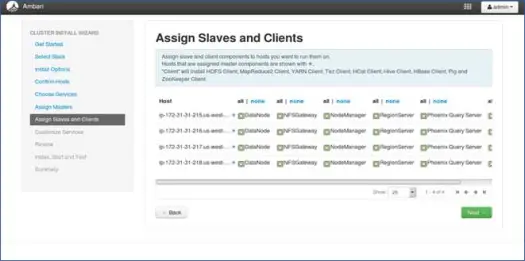
与 master 类似,在节点上映射 slave 服务。 一般来说,所有节点都会有一个至少为 Datanodes 和 Nodemanagers 运行的从属进程。
9.定制服务
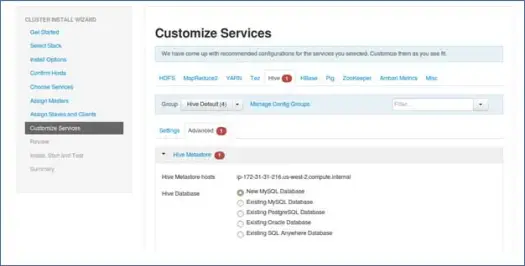
这对于管理员来说是非常重要的页面。
您可以在此处为集群配置属性,使其最适合您的用例。
它还将具有一些必需的属性,例如 Hive Metastore 密码(如果选择了 hive)等。这些将用红色错误(如符号)指出。
10. 查看并开始配置
确保在启动之前检查集群配置,因为这将避免在不知不觉中设置错误的配置。
11. 启动并停留,直到状态变为绿色。
下一步
耶! 我们已经在集群的所有节点上成功安装了 Hadoop 和所有组件。 现在我们可以开始使用 Hadoop。
Ambari 运行 MapReduce wordcount 作业来验证一切是否运行良好。 让我们检查 ambari-qa 用户运行的作业的日志。
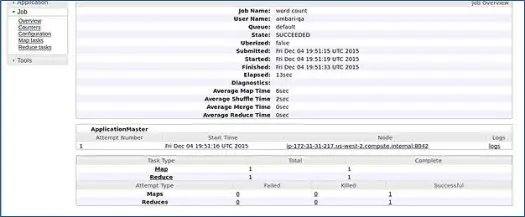
如您在上面的屏幕截图中所见,WordCount 作业已成功完成。 这证实了我们的集群工作正常。
结论
就是这样,我们现在已经学习了如何使用一个名为 Apache Ambari 的简单的基于 Web 的工具在多节点集群上安装 Hadoop 及其组件。 Apache Ambari 为我们提供了一个更简单的界面,并节省了我们在安装、监控和管理方面的大量工作,如果有如此多的组件及其不同的安装步骤和监控控制,这些工作将非常繁琐。
让我留给你一个黑客

Ambari 安装程序检查 /etc/lsb-release 以获取操作系统详细信息。 在 Linux Mint 中,Ubuntu 版本的相同文件位于 /etc/upstream-release/lsb-release 下。 为了欺骗安装程序,只需将前者替换为后者(您应该先备份文件)。

在安装完成后的某个时间点,您可以使用以下命令恢复原始文件:

PS这是一个没有任何保证的hack,它对我有用,所以我想和你分享。
您是开发人员/开发人员,需要快速安装 Hadoop。 我们有一个好消息要告诉您,Ambari 提供了一种方法,您可以使用单个脚本跳过完整的向导过程和完成的安装过程,我将在下一篇文章中带来它,敬请期待,直到那时快乐 Hadooping!