
为什么损坏的书签会损害 SEO 以及如何查找和修复它们
已发表: 2023-04-12用户体验对客户旅程有着深远的影响。 这包括您的网站导航的难易程度、页面加载速度,以及指向相关页面的链接是否会影响客户是否会完成他们的购买旅程或离开您的网站。
不用说,断开的链接会很快将潜在客户变成流失客户。
更重要的是,它还会影响您的排名,特别是您网站上的链接资产流量。 因此,您必须确保所有链接都正常工作。
但在我们深入研究如何修复您网站上的任何损坏链接之前,让我们仔细看看什么是书签或跳转链接。
什么是书签链接?
HTML 链接可用于创建书签(也称为“跳转链接”、“命名锚点”、“跳过链接”和“碎片链接”),以便您网站的访问者可以跳转到页面的特定部分。 简单地说,URL 中的井号 (#) 称为书签。 通常,井号 (#) 后有一些单词。 它们可以称为片段标识符/片段 ID 或锚标记。 单击这些链接时,网页将滚动网页到书签所在的位置。
跳转链接的功能不同于其他类型的URI 或统一资源标识符:它们的处理仅在客户端进行,服务器端不进行任何协作。 服务器通常有助于理解多用途 Internet 邮件扩展或MIME类型以及在处理碎片标识符时的 MIME 类型。 在 URL 的源代码中,用户代理将搜索由包含 ID= 属性等于片段标识符的 HTML 标记标识的锚点。
我们为什么要关心跳转链接?
想象一下,您正在书店挑选一本百科全书。 您打开目录以浏览最重要的章节。 当您跳转到您最感兴趣的页面时,您会看到另一个不符合您期望的标题和段落。 您可能会返回目录或尝试翻几页以找到相关主题,但最后,您会把书放回书架上并找到结构更完整的百科全书。
书签是在您的网页上为用户提供特定信息的一种简单有效的方式。 虽然跳转链接对您的受众很有用,但在设置中很容易出错,并且随着内容和 ID 的更新,它可能会“损坏”。
Googlebot 如何处理跳转链接?
虽然 Googlebot 会将这些 URL 视为同一网页(因为机器人会忽略 URL 的 # 部分中的任何内容),但它可以使用命名锚点来为SERP 中的“跳转到”链接进行页面排名。
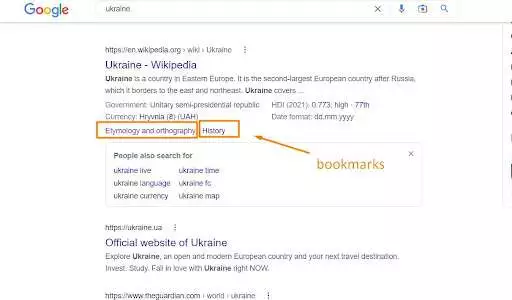
和往常一样,谷歌的算法说了算。 当搜索机器人请求页面时,它总是忽略“ # ”字符后的 URL 部分。 浏览器只使用书签——它们不影响从服务器返回的资源。 如果您从以下内容更新 URL 的“#”部分:
https://www.example#old-heading到这个:
https://www.example#new-heading ,
浏览器会将页面滚动到新标题,但不会重新加载 URL。 然而,浏览器确实会在浏览器的历史记录中创建一条记录,以便单击浏览器菜单中的“后退”按钮会将访问者引导至之前打开的源代码。
碎片化链接是否显示在搜索引擎结果页面 (SERP) 中将在很大程度上取决于访问者在每种情况下的搜索意图。 另外,您应该知道,当您创建书签时,不会传递任何PageRank信号。 网站页面不会在分散的链接之间拆分 PageRank。
如何创建 SEO 友好的书签?
1.首先,使用ID属性创建一个书签:
<h2 id=”seo-answer”>视情况而定</h2>
2.其次,在同一页面内添加指向书签的链接(“跳转到有史以来最好的 SEO 答案”):
例子:
<a href=”#seo-answer”>跳转到有史以来最好的 SEO 答案</a>您还可以在另一个页面上添加指向书签的链接:
<a href=”the-new-page.html#link-to-another-page”>跳转到新页面</a>
关于如何创建 SEO 友好书签的提示
– 创建描述性锚点/替代文本:超链接显示的可见字符和文字应该是描述性的,让访问者知道他们将被导航到哪里。
– 在易于访问的部分添加书签:书签通常在长篇页面中用作目录,允许访问者快速跳转到他们想要阅读的部分。
– 避免在片段中使用特殊字符和空格:必要时为了可读性,使用/下划线分隔单词。
– 仔细插入书签:如果您使用过多的碎片化链接,访问者可能会感到困惑,并使您的内容显得杂乱无章。
要检查结果,请将 URL 插入浏览器并单击碎片链接。 如果任何跳转链接没有将您链接到正确的内容部分,请检查 HTML 源代码以确定问题所在。 书签非常简单,但需要特定格式才能正常运行。
如何链接到外部碎片化 URL?
如果你想链接到外部网站的页面,并且内容在网页的特定部分有相关信息,那么插入到页面的链接以及标题的标识符(例如,htt p s : //xxx.com/post-title/#section )。

这样,一旦页面加载完毕,访问者就会自动导航到相应的内容部分。 为了使书签起作用,外部网站的标题必须包含用于页面跳转的标识符(例如,<h2 id=” section”>)。
如何使用 SEO Spider 查找损坏的书签?
棘手的是,无法以与 SEO 爬虫中的跳转链接断开链接相同的方式找到断开的跳转链接,因为它们不会触发 404 Not Found 响应状态代码。 这就是为什么碎片化链接问题经常被忽视的原因。 让我们来看看如何使用SF spider检测这些错误。 请注意,您应该切换到爬虫的付费版本来设置下面描述的配置。
1. 前往“配置”>“蜘蛛”>“高级”ta
在这里你应该勾选“抓取碎片标识符”功能。 不要忘记按“确定”绿色按钮保存设置。
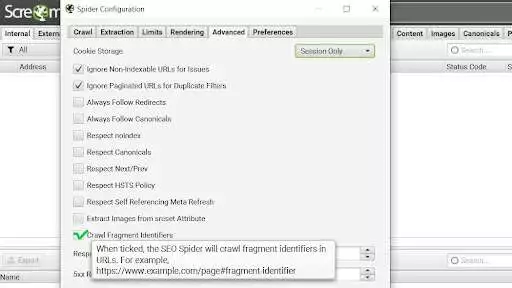
图片来源:尖叫蛙爬虫-配置
2.爬行
现在插入您要分析的站点的 URL,然后按“开始”启动爬网。
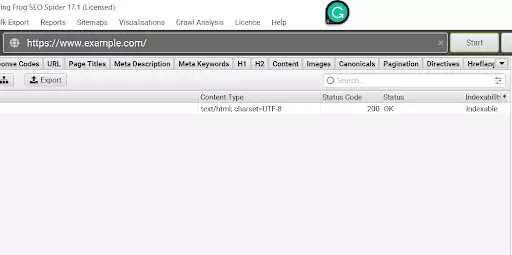
图片来源:顺丰爬虫-起始页
3.找到“损坏的书签”部分
抓取完成后,您可以单击顶部的下拉过滤器或浏览右侧窗口抓取的“概述”部分,然后单击“URL”部分下的相关行。 选择什么方式并不重要; 他们都显示相同的数据。
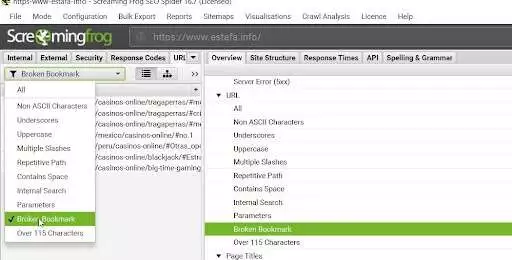
图片来源:顺丰爬虫-Filters
现在您可以看到哪些跳转链接损坏了,是时候解决这个问题了。
如何修复损坏的书签
所以,你已经找到了所有不正确的跳转链接; 做得好! 下一个问题是如何处理这些数据。
现在,您应该检测网站上的哪些页面会导致断开的碎片化链接,以便您可以打开这些 URL 并修复不正确的 ID。
为此,请突出显示报告上部的所有 URL (Cntrl/Command +A),然后在底部的“Inlinks”选项卡上突出显示。 现在您可以在“收件人”列中看到发现损坏书签的页面(“发件人”列)以及哪个书签和哪个锚点/替代文本(如果损坏的链接在图像中)被损坏。
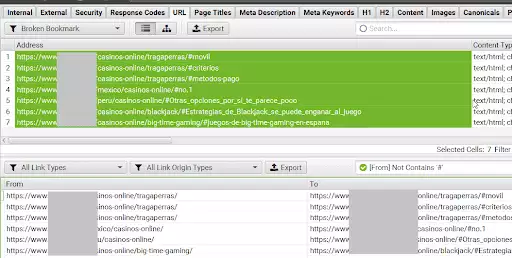
图片来源:顺丰爬虫-Tabs
为了简化分析,使用过滤器“From”>“Not contain”>“#”来去除重复的报告案例。
那么过程就简单了。 您知道哪个 ID 不正确(提醒:ID = # 之后的 URL 的一部分)以及哪个锚点/替代文本导致损坏的书签。 在页面上找到,分析哪里出了问题。 例如,在下面的示例中,使用了大写字母而不是小写字母。
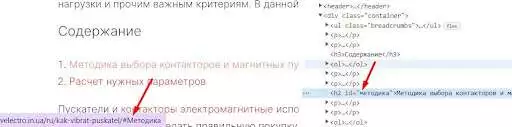
图片来源:HTML代码截图
不幸的是,没有一种万能的解决方案来修复破碎的碎片。 有时,由于开发团队的失误,错误会出现在页脚、页眉或导航菜单中。 在这种情况下,您可能需要额外的开发人员帮助来修复代码中的问题。 按 LinkPosition 列对包含损坏片段的表进行排序始终是一个好习惯,这样可以更轻松地找到模式。
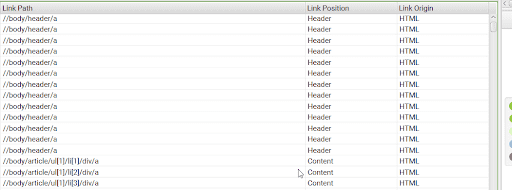
图片来源:顺丰爬虫-友情链接
包起来
书签可帮助用户轻松滚动和浏览长篇内容。 虽然搜索机器人会将这些链接视为相同的 URL,但它们可以使用碎片标识符作为 SERP 中的“跳转到”链接。
断开的跳转链接将意味着访问者仍在正确的页面上着陆,但他们不会被发送到内容的预期部分。 可以手动或使用 SEO 爬虫批量发现跳转链接问题。
要使跳转链接正常工作,您应该找到哪些页面链接到损坏的书签,然后更新属性 ID。 不正确的跳转链接会导致糟糕的用户体验。 这就是为什么您应该尽一切可能找到并修复它们。 您在修复碎片化标识符方面有何经验? 请在下面的评论中告诉我们。