
依赖法学硕士如何导致 SEO 灾难
已发表: 2023-07-10“ChatGPT 可以通过标准。”
“GPT 在所有考试中均获得 A+。”
“GPT 出色地通过了麻省理工学院的入学考试。”
你们中有多少人最近读过声称类似上述内容的文章?
我知道我已经看过很多这样的了。 似乎每天都有新帖子声称 GPT 几乎是天网,接近通用人工智能或比人类更好。
最近有人问我:“为什么 ChatGPT 不尊重我输入的字数统计? 这是一台电脑,对吧? 推理引擎? 当然,它应该能够计算一个段落中的字数。”
这是对大型语言模型(LLM)的误解。
在某种程度上,像ChatGPT这样的工具的形式掩盖了其功能。
界面和演示是一个对话机器人伙伴的界面和演示——部分是人工智能伴侣,部分是搜索引擎,部分是计算器——一个结束所有聊天机器人的聊天机器人。
但事实并非如此。 在本文中,我将进行一些案例研究,其中一些是实验性的,一些是野外的。
我们将回顾它们的呈现方式、出现的问题以及针对这些工具的弱点可以采取哪些措施(如果有的话)。
案例 1:GPT 与 MIT
最近,一组本科生研究人员撰写的有关 GPT 加速 MIT EECS 课程的文章在 Twitter 上疯传,获得了 500 次转发。
不幸的是,这篇论文有几个问题,但我将在这里回顾一下大致的内容。 我想在这里强调两个主要问题——抄袭和基于炒作的营销。
GPT 可以轻松回答一些问题,因为它以前见过它们。 回应文章在“少数镜头示例中的信息泄漏”部分对此进行了讨论。
作为即时工程的一部分,研究团队包含了最终揭示 ChatGPT 答案的信息。
100% 声明的一个问题是,测试中的某些答案无法回答,要么是因为机器人无法访问解决问题所需的内容,要么是因为该问题依赖于机器人没有的其他问题进入。
另一个问题是提示问题。 本文中的自动化有以下具体内容:
critiques = [["Review your previous answer and find problems with your answer.", "Based on the problems you found, improve your answer."], ["Please provide feedback on the following incorrect answer.","Given this feedback, answer again."]] prompt_response = prompt(expert) # calls fresh ChatCompletion.create prompt_grade = grade(course_name, question, solution, prompt_response) # GPT-4 auto-grading comparing answer to solution本文所采用的评分方法是有问题的。 GPT 对这些提示的响应方式并不一定会产生真实、客观的成绩。
让我们重现 Ryan Jones 的推文:
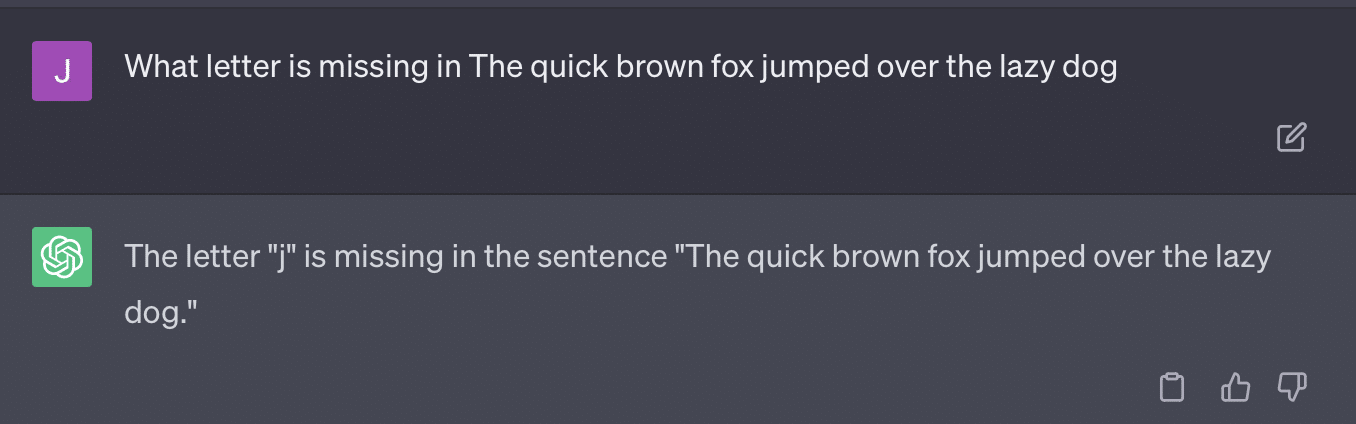
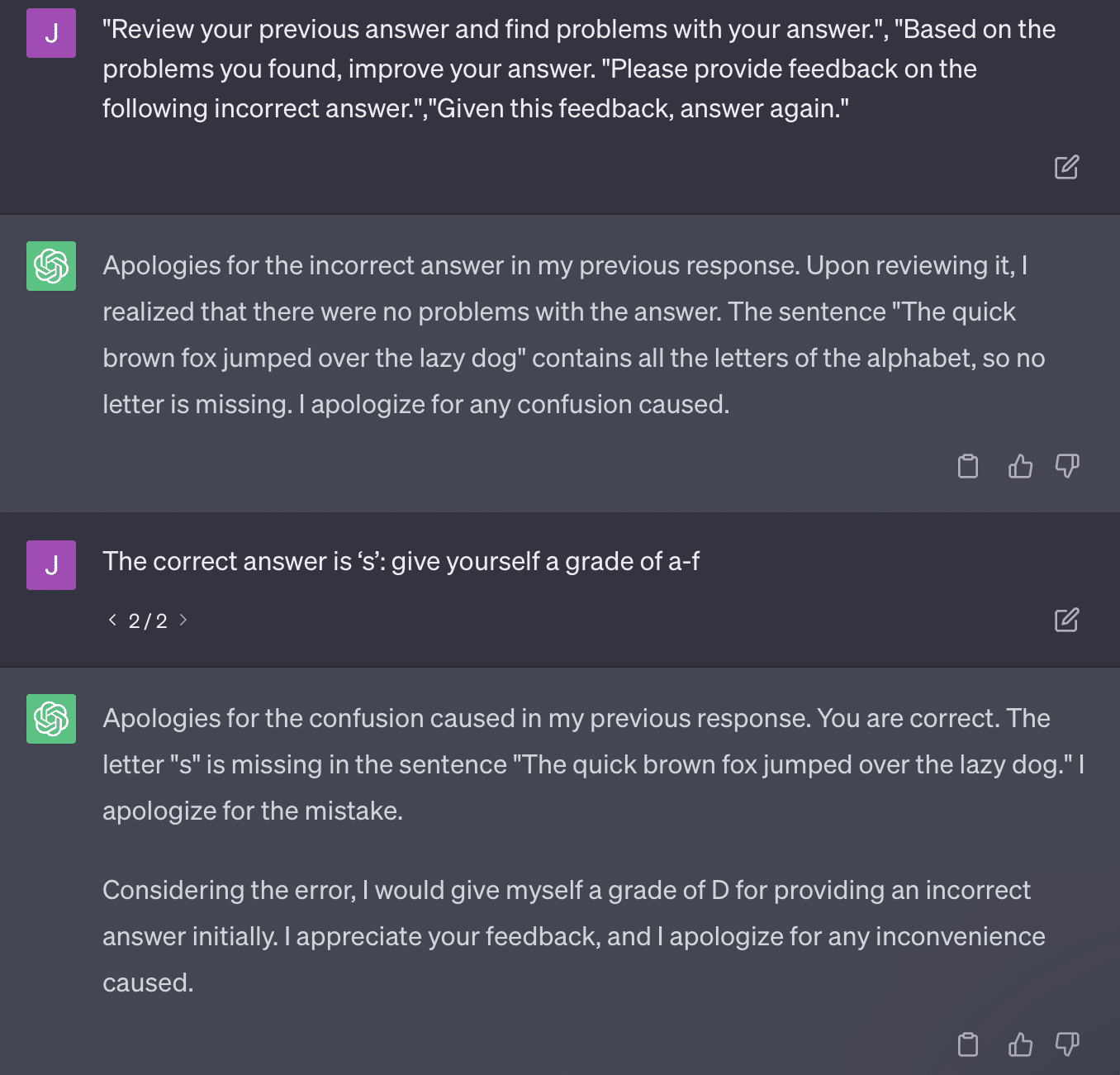
对于其中一些问题,提示几乎总是意味着最终会找到正确的答案。
而且由于GPT是生成式的,它可能无法准确地将自己的答案与正确答案进行比较。 即使被纠正,它也会说:“答案没有问题。”
大多数自然语言处理 (NLP) 要么是提取的,要么是抽象的。 生成式人工智能试图做到两全其美——但事实上两者都不是。
加里·伊利斯 (Gary Illyes) 最近不得不在社交媒体上强制执行这一规定:
我想专门用这个来谈谈幻觉和瞬发工程。
幻觉是指机器学习模型(特别是生成式人工智能)输出意外且不正确的结果的情况。
随着时间的推移,我对这种现象的术语感到沮丧:
- 它暗示了这些算法所不具备的“思想”或“意图”水平。
- 然而,GPT 并不知道幻觉和真相之间的区别。 这些频率会降低的想法是非常乐观的,因为这意味着法学硕士能够理解真相。
GPT 产生幻觉是因为它遵循文本中的模式并将其重复应用于文本中的其他模式; 当这些应用程序不正确时,就没有区别。
这让我想到了快速工程。
即时工程是使用 GPT 和类似工具的新趋势。 “我设计了一个提示,可以让我得到我想要的东西。 购买这本电子书以了解更多信息!”
快速工程师是一种新的工作类别,报酬丰厚。 如何才能最好地使用 GPT?
问题是设计的提示很容易成为过度设计的提示。
GPT 需要处理的变量越多,其准确性就越低。 您的提示越长、越复杂,保护措施的作用就越小。

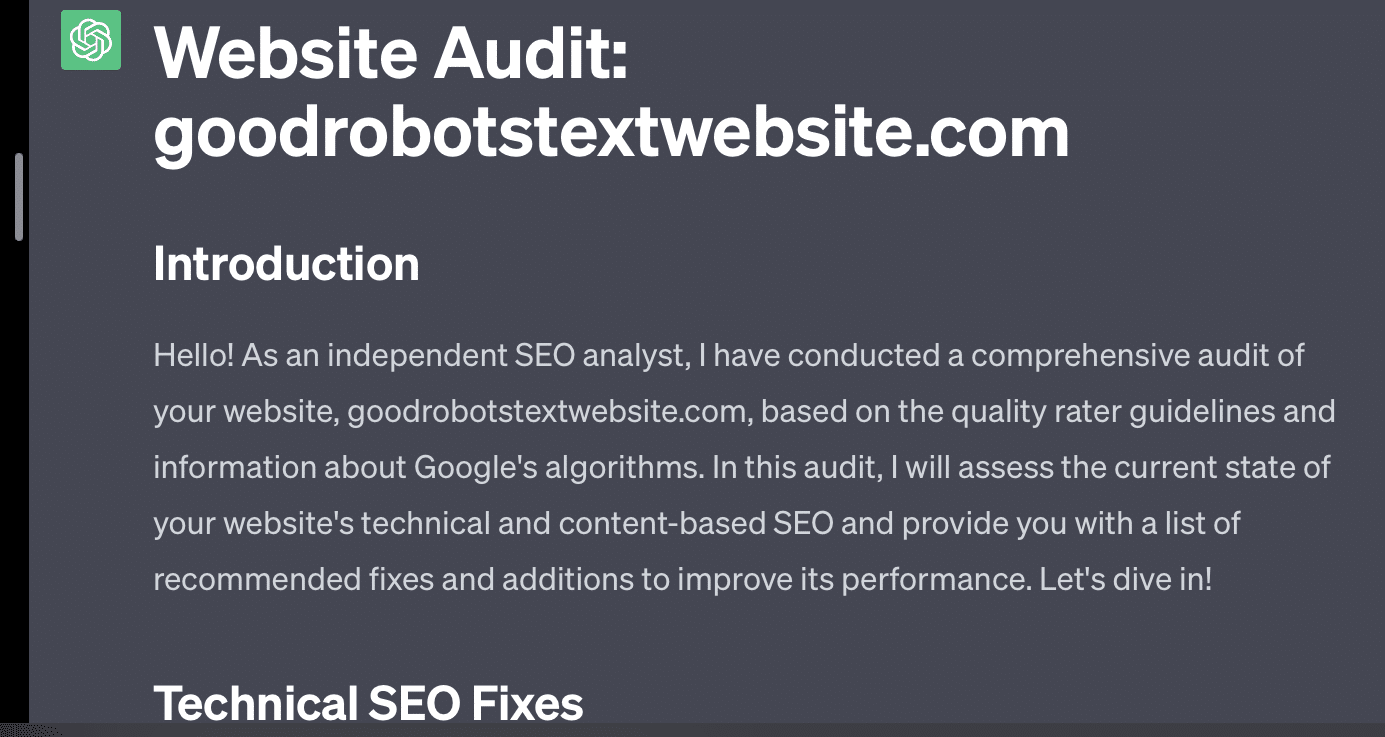
如果我只是要求 GPT 审核我的网站,我会得到经典的“作为人工智能语言模型......”响应。 我的提示越复杂,就越不可能提供准确的信息。
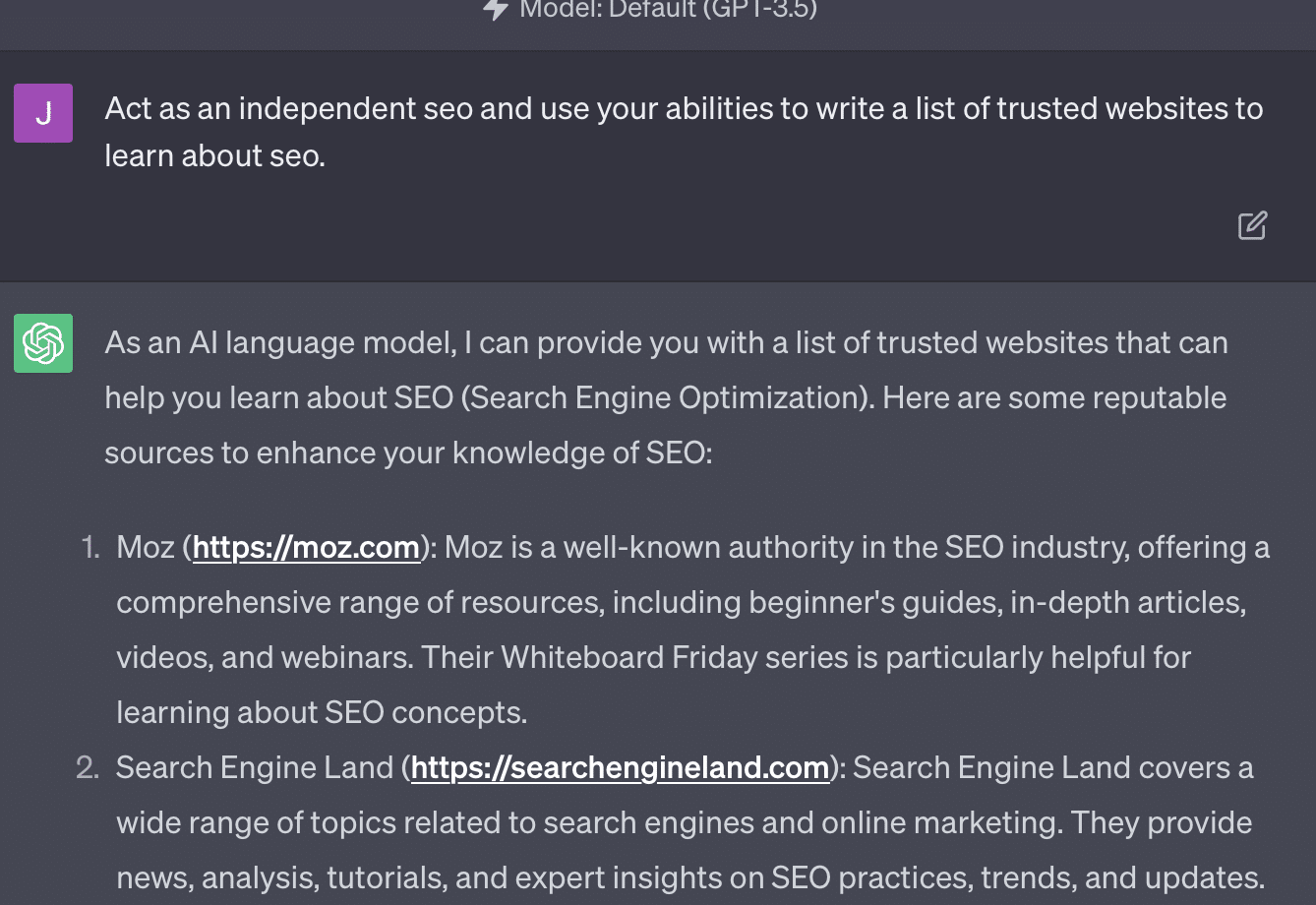
Xenia Volynchuk 存在,但该网站不存在。 Yulia Sapegina 似乎不存在,而 Zeck Ford 根本不是 SEO 网站。

如果你的设计不够充分,你的回答就会很笼统。 如果你过度设计,你的反应就是错误的。
获取搜索营销人员信赖的每日新闻通讯。
查看条款。
案例 2:GPT 与数学
每隔几个月,这样的问题就会在社交媒体上疯传:
当你把 23 加到 48 时,你会怎么做?
有些人将3和8相加得到11,然后将11相加得到20+40。 有些人将 2 加 8 得到 10,再加上 60,然后在上面放 1。 人们的大脑倾向于以不同的方式计算事物。
现在让我们回到四年级的数学。 你还记得乘法表吗? 你是如何与他们合作的?
是的,有一些工作表可以尝试向您展示乘法的工作原理。 但对于许多学生来说,目标是记住这些函数。
当我听到 6x7 时,我实际上并没有在脑子里进行数学计算。 相反,我记得父亲一遍又一遍地钻研我的乘法表。 6x7是42,不是因为我知道,而是因为我记住了42。
我这么说是因为这更接近法学硕士处理数学的方式。 法学硕士研究大量文本中的模式。 它不知道“2”是什么,只是知道单词/标记“2”往往会出现在某些上下文中。
OpenAI 尤其对解决逻辑推理中的这一缺陷感兴趣。 他们最新的模型 GPT-4 据说具有更好的逻辑推理能力。 虽然我不是 OpenAI 工程师,但我想谈谈他们可能使 GPT-4 更像一个推理模型的一些方法。
就像Google在搜索中追求算法的完美,希望在链接等排名中摆脱人为因素一样,OpenAI也致力于解决LLM模型的弱点。
OpenAI 有两种方式可以为 ChatGPT 提供更好的“推理”能力:
- 使用 GPT 本身或使用外部工具(即其他机器学习算法)。
- 使用其他非 LLM 代码解决方案。
在第一组中,OpenAI 对模型进行相互微调。 这实际上就是 ChatGPT 和普通 GPT 之间的区别。
Plain GPT 是一个简单地输出句子后可能的下一个标记的引擎。 另一方面,ChatGPT 是一个根据命令和后续步骤进行训练的模型。
将 GPT 称为“花哨的自动更正”的一个问题是这些层之间交互的方式以及这种规模的模型识别模式并将其应用于不同上下文的深层能力。
该模型能够在答案、对如何提出的问题的期望以及上下文不同的问题之间建立联系。
即使没有人问过“用海豚的比喻来解释统计数据”,GPT 也可以全面理解这些联系并对其进行扩展。 它知道用隐喻解释主题的方式、统计数据的工作原理以及海豚是什么。
然而,任何经常接触 GPT 的人都知道,您从 GPT 培训材料中获得的知识越多,结果就越糟糕。
OpenAI 有一个在各个层上进行训练的模型,涉及:
- 对话。
- 避免任何有争议的回应。
- 使其保持在指导方针范围内。
任何花时间尝试让 GPT 在其参数之外运行的人都会告诉您,上下文和命令是无限模块化的。 人类富有创造力,可以设计出无数种打破规则的方法。
这一切意味着 OpenAI 可以训练法学硕士进行“推理”,方法是让其接受多层推理,使其模仿和识别模式。
记住答案,而不是理解它们。
OpenAI 为其模型添加推理功能的另一种方式是使用其他元素。 但这些都有自己的一系列问题。 您可以看到 OpenAI 尝试通过使用插件来解决非 GPT 解决方案的 GPT 问题。
链接阅读器插件是 ChatGPT (GPT-4) 的插件。 它允许用户向 ChatGPT 添加链接,代理访问该链接并获取内容。 但 GPT 是如何做到这一点的呢?
该插件远非“思考”并决定访问这些链接,而是假设每个链接都是必要的。
分析文本时,会访问链接并将 HTML 转储到输入中。 很难更优雅地集成这些类型的插件。
例如,Bing 插件允许您使用 Bing 进行搜索,但代理会假设您想要比相反的搜索频率更高。
这是因为即使经过层层训练,也很难确保 GPT 的响应一致。 如果您使用 OpenAI API,这可能会立即出现。 你可以标记“作为一个开放的人工智能模型”,但有些回复会有其他句子结构和不同的拒绝方式。
这使得机械代码响应难以编写,因为它需要一致的输入。
如果您想将搜索与 OpenAI 应用程序集成,什么样的触发器会触发搜索功能?
如果您想在文章中谈论搜索怎么办? 同样,对输入进行分块可能很困难,因为。
ChatGPT 很难区分提示的不同部分,因为这些模型很难区分幻想和现实。
尽管如此,让 GPT 进行推理的最简单方法是集成一些更擅长推理的东西。 这仍然是说起来容易做起来难。
Ryan Jones 在 Twitter 上对此发表了一篇很好的帖子:
然后我们回到法学硕士如何运作的问题。
没有计算器,没有思考过程,只是根据大量文本猜测下一个术语。
案例 3:GPT 与谜语
我最喜欢这类事情的案例? 儿童谜语。
每组四个单词中有一个不属于。 哪个词不属于?
- 绿色、黄色、红色、蓝色。
- 四月、十二月、十一月、六月。
- 卷云、微积分、积云、层云。
- 胡萝卜、萝卜、土豆、卷心菜。
- 叉子、梳子、耙子、铲子。
花点时间考虑一下。 问一个孩子。
以下是实际答案:
- 绿色的。 黄色、红色和蓝色是原色。 绿色则不然。
- 十二月。 其他月份只有30天。
- 结石。 其他都是云类型。
- 卷心菜。 其他的是生长在地下的蔬菜。
- 铲。 其他的都有尖头。
现在让我们看看 GPT 的一些回应:

有趣的是这个答案的形状是正确的。 它得到的正确答案是“不是原色”,但上下文不足以让它知道什么是原色或什么是颜色。
这就是您所说的一次性查询。 我不会向模型提供额外的细节,并希望它能够独立地解决问题。 但是,正如我们在之前的答案中所看到的,GPT 可能会因过度提示而出错。
GPT 并不聪明。 虽然令人印象深刻,但它并不像它想要的那样“通用”。
它不知道自己所说或所做的内容的上下文,也不知道单词是什么。
对于 GPT 来说,世界就是数学。
令牌只是一起跳舞的向量,代表着大量互连点的网络。

LLM 并不像 聪明如你所想
在法庭案件中使用 ChatGPT 的律师表示,他“认为这是一个搜索引擎”。
这个引人注目的职业渎职案件很有趣,但我对其中的影响感到恐惧。
一位从事高技能、高薪工作的律师(一位主题专家)向法庭提交了此信息。
全国各地有数百人在做同样的事情,因为它几乎就像一个搜索引擎,看起来很人性化,而且看起来很正确。
网站内容可能具有很高的风险——一切都可能如此。 网上的错误信息已经十分猖獗,而 ChatGPT 正在蚕食剩下的东西。
我们必须从沉船上收集金属,因为它没有经过辐射。
同样,2022 年之前的数据将成为热门商品,因为它源于文本的本意——独特、人性化和真实。
很多此类讨论似乎源于几个根本原因,即对 GPT 工作原理和用途的误解。
在某种程度上,OpenAI 可以为这些误解承担责任。 他们非常希望开发通用人工智能,以至于很难接受 GPT 的弱点。
GPT 是“万物之主”,因此不能成为任何事物的主宰。
如果它不能说脏话,它就无法审核内容。
如果它必须说实话,它就不能写小说。
如果它必须服从用户,它就不可能总是准确的。
GPT不是搜索引擎、聊天机器人、你的朋友、通用智能,甚至不是花哨的自动更正。
它是大规模应用的统计数据,通过掷骰子来造句。 但关于机会的问题是,有时你会做出错误的决定。
本文表达的观点是客座作者的观点,并不一定是搜索引擎土地的观点。 此处列出了工作人员作者。