
了解大型语言模型 (LLM) 的 SEO 指南
已发表: 2023-05-08我应该使用大型语言模型进行关键词研究吗? 这些模型能思考吗? ChatGPT 是我的朋友吗?
如果您一直在问自己这些问题,那么本指南适合您。
本指南涵盖了 SEO 需要了解的有关大型语言模型、自然语言处理以及介于两者之间的所有内容。
大型语言模型、自然语言处理等简单术语
有两种方法可以让一个人做某事——告诉他们去做或希望他们自己做。
说到计算机科学,编程是告诉机器人去做,而机器学习是希望机器人自己去做。 前者是有监督的机器学习,后者是无监督的机器学习。
自然语言处理 (NLP) 是一种将文本分解为数字然后使用计算机对其进行分析的方法。
计算机分析单词中的模式,随着它们变得更高级,还会分析单词之间的关系。
可以在许多不同类型的数据集上训练无监督的自然语言机器学习模型。
例如,如果您根据电影“水世界”的平均评论训练语言模型,您将获得擅长撰写(或理解)电影“水世界”评论的结果。
如果你根据我对电影《水世界》的两条正面评价对其进行训练,它只会理解那些正面评价。
大型语言模型 (LLM) 是具有超过十亿个参数的神经网络。 它们是如此之大,以至于它们更加普遍。 他们不仅接受了关于“水世界”正面和负面评论的培训,还接受了评论、维基百科文章、新闻网站等方面的培训。
机器学习项目经常与上下文一起工作——上下文内外的事物。
如果你有一个机器学习项目可以识别错误并给它看一只猫,那么它不会擅长那个项目。
这就是为什么像自动驾驶汽车这样的东西如此困难:有太多脱离背景的问题以至于很难概括这些知识。
法学硕士似乎并且可以 比其他机器学习项目更通用。 这是因为数据的庞大规模以及处理数十亿种不同关系的能力。
让我们谈谈实现这一点的突破性技术之一——变压器。
从头开始解释变压器
作为一种神经网络架构,Transformer 彻底改变了 NLP 领域。
在 Transformer 出现之前,大多数 NLP 模型都依赖于一种称为递归神经网络 (RNN) 的技术,该技术按顺序处理文本,一次一个词。 这种方法有其局限性,例如速度慢并且难以处理文本中的远程依赖关系。
变形金刚改变了这一点。
在 2017 年具有里程碑意义的论文“Attention is All You Need”中,Vaswani 等人。 介绍了transformer架构。
Transformer 不是按顺序处理文本,而是使用一种称为“自注意力”的机制来并行处理单词,从而使它们能够更有效地捕获远程依赖关系。
以前的架构包括 RNN 和长短期记忆算法。
像这样的循环模型曾经(现在仍然)常用于涉及数据序列的任务,例如文本或语音。
然而,这些模型有一个问题。 他们一次只能处理一个数据,这会减慢他们的速度并限制他们可以处理的数据量。 这种顺序处理确实限制了这些模型的能力。
引入注意力机制作为处理序列数据的不同方式。 它们允许模型一次查看所有数据片段并确定哪些片段最重要。
这在许多任务中确实很有帮助。 然而,大多数使用注意力的模型也使用循环处理。
基本上,他们有这种一次性处理数据的方式,但仍然需要按顺序查看。 Vaswani 等人的论文浮出水面,“如果我们只使用注意力机制呢?”
注意力是模型在处理输入序列时将注意力集中在输入序列的某些部分的一种方式。 例如,当我们阅读一个句子时,我们自然会比其他词更注意某些词,这取决于上下文和我们想要理解的内容。
如果你看一个转换器,模型会根据输入序列中每个词对理解序列整体含义的重要性来计算它的分数。
然后,该模型使用这些分数来衡量序列中每个单词的重要性,使其更多地关注重要的单词,而不是不重要的单词。
这种注意力机制有助于模型捕获输入序列中可能相距很远的单词之间的远程依赖关系和关系,而无需按顺序处理整个序列。
这使得转换器对于自然语言处理任务非常强大,因为它可以快速准确地理解句子或较长文本序列的含义。
让我们以处理“The cat sat on the mat”这句话的 transformer 模型为例。
句子中的每个单词都使用嵌入矩阵表示为一个向量,一系列数字。 假设每个词的嵌入是:
- : [0.2, 0.1, 0.3, 0.5]
- 猫:[0.6,0.3,0.1,0.2]
- 坐:[0.1,0.8,0.2,0.3]
- 上:[0.3,0.1,0.6,0.4]
- : [0.5, 0.2, 0.1, 0.4]
- 垫子:[0.2、0.4、0.7、0.5]
然后,转换器根据句子中每个单词与句子中所有其他单词的关系计算句子中每个单词的分数。
这是使用每个词的嵌入与句子中所有其他词的嵌入的点积来完成的。
例如,要计算单词“cat”的分数,我们将使用它的嵌入与所有其他单词的嵌入的点积:
- “猫”:0.2*0.6 + 0.1*0.3 + 0.3*0.1 + 0.5*0.2 = 0.24
- “猫坐着”:0.6*0.1 + 0.3*0.8 + 0.1*0.2 + 0.2*0.3 = 0.31
- “猫在”:0.6*0.3 + 0.3*0.1 + 0.1*0.6 + 0.2*0.4 = 0.39
- “猫”:0.6*0.5 + 0.3*0.2 + 0.1*0.1 + 0.2*0.4 = 0.42
- “猫垫”:0.6*0.2 + 0.3*0.4 + 0.1*0.7 + 0.2*0.5 = 0.32
这些分数表示每个单词与单词“cat”的相关性。 然后,转换器使用这些分数来计算词嵌入的加权和,其中权重是分数。
这为单词“cat”创建了一个上下文向量,考虑了句子中所有单词之间的关系。 对句子中的每个单词重复此过程。
可以把它想象成转换器根据每次计算的结果在句子中的每个单词之间画一条线。 有些线条比较脆弱,有些则不那么脆弱。
Transformer 是一种新型模型,它只使用注意力而不进行任何循环处理。 这使得它更快并且能够处理更多数据。
GPT 如何使用转换器
你可能还记得,在谷歌的 BERT 公告中,他们吹嘘它允许搜索理解输入的完整上下文。 这类似于 GPT 使用转换器的方式。
让我们打个比方。
想象你有一百万只猴子,每只都坐在键盘前。
每只猴子随机敲击键盘上的键,生成一串字母和符号。
有些字符串完全是无稽之谈,而另一些可能类似于真实的单词甚至是连贯的句子。
一天,一位马戏团训练员看到一只猴子写下了“生存或毁灭”,于是训练员给了这只猴子一份款待。
其他猴子看到这一点并开始尝试模仿成功的猴子,希望自己得到款待。
随着时间的推移,一些猴子开始不断地产生更好、更连贯的文本字符串,而其他猴子则继续产生胡言乱语。
最终,猴子可以识别甚至模仿文本中连贯的模式。
法学硕士比猴子更有优势,因为法学硕士首先接受了数十亿段文本的训练。 他们已经可以看到模式。 他们还了解这些文本片段之间的向量和关系。
这意味着他们可以使用这些模式和关系来生成类似于自然语言的新文本。
GPT全称Generative Pre-trained Transformer,是一种使用转换器生成自然语言文本的语言模型。
它接受了来自互联网的大量文本的训练,这使其能够学习自然语言中单词和短语之间的模式和关系。
该模型的工作原理是接收提示或文本中的几个词,并使用转换器根据从训练数据中学到的模式来预测接下来应该出现什么词。
该模型继续逐字生成文本,使用前一个词的上下文来通知下一个词。
GPT 在行动
GPT 的好处之一是它可以生成高度连贯且上下文相关的自然语言文本。
这有很多实际应用,例如生成产品描述或回答客户服务查询。 它还可以创造性地使用,例如生成诗歌或短篇小说。
然而,它只是一个语言模型。 它根据数据进行训练,并且该数据可能已过时或不正确。
- 它没有知识来源。
- 它无法搜索互联网。
- 它什么都“不知道”。
它只是猜测下一个单词是什么。
让我们看一些例子:
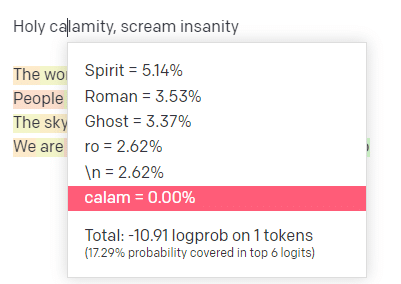
在 OpenAI playground 中,我插入了帅哥模特学校的经典曲目“圣劫[[Bear Witness ii]]”的第一行。
我提交了回复,这样我们就可以看到我的输入和输出行的可能性。 因此,让我们来看看这告诉我们的每一部分。
对于第一个词/标记,我输入“神圣”。 我们可以看到最期待的下一个输入是 Spirit、Roman 和 Ghost。
我们还可以看到,前六个结果仅涵盖接下来发生的概率的 17.29%:这意味着我们在此可视化中看不到约 82% 的其他可能性。
让我们简要讨论一下您可以在此使用的不同输入以及它们如何影响您的输出。
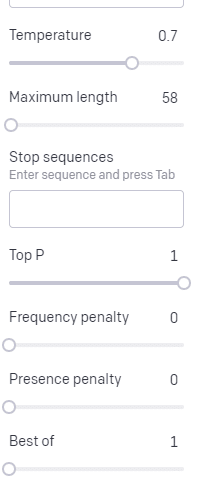
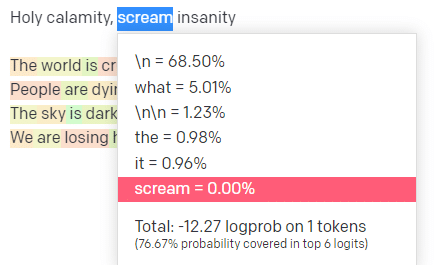
温度是模型抓住概率最高的词以外的词的可能性, top P是它选择这些词的方式。
因此,对于输入“Holy Calamity”,top P 是我们如何选择下一个标记 [Ghost、Roman、Spirit] 的集群,而温度是选择最有可能的标记与更多种类的可能性。
如果温度更高,则更有可能选择不太可能的令牌。
所以高温和高顶P可能会更狂野。 它从各种各样的(高P)中进行选择,并且更有可能选择令人惊讶的代币。


虽然高温但较低的最高 P 会从较小的可能性样本中选择令人惊讶的选项:

降低温度只会选择最有可能的下一个标记:

在我看来,使用这些概率可以让您深入了解这些模型的工作原理。
它正在根据已经完成的内容查看可能的下一个选择集合。
这实际上意味着什么?
简而言之,LLM 接受一组输入,将它们摇匀并将它们转化为输出。
我听过人们开玩笑说这是否与人如此不同。
但这不像人——法学硕士没有知识基础。 他们不是在提取有关事物的信息。 他们根据最后一个单词猜测一系列单词。
另一个例子:想想一个苹果。 想到什么?
也许你可以在脑海中旋转一个。
也许你还记得苹果园的气味、粉红女士的甜美等等。
也许你会想到史蒂夫·乔布斯。
现在让我们看看提示“think of an apple”返回了什么。
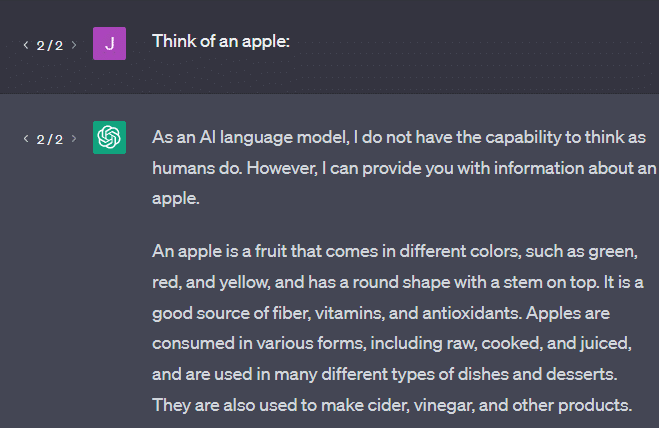
此时你可能已经听说过“随机鹦鹉”这个词。
Stochastic Parrots 是一个术语,用于描述像 GPT 这样的 LLM。 鹦鹉是一种模仿它所听到的东西的鸟。
因此,LLM 就像鹦鹉一样,它们接收信息(单词)并输出类似于他们所听到的内容。 但它们也是随机的,这意味着它们使用概率来猜测接下来会发生什么。
LLM 擅长识别单词之间的模式和关系,但他们对所看到的内容没有任何更深入的理解。 这就是为什么他们非常擅长生成自然语言文本但却无法理解它。
法学硕士的良好用途
法学硕士擅长更通才的任务。
您可以向它显示文本,无需训练,它就可以使用该文本完成一项任务。
您可以向它发送一些文本并要求进行情绪分析,要求它将该文本转换为结构化标记并进行一些创造性工作(例如,编写提纲)。
像代码这样的东西没问题。 对于许多任务,它几乎可以让您到达那里。
但同样,它基于概率和模式。 因此,有时它会在您的输入中发现您不知道的模式。
这可以是积极的(看到人类看不到的模式),但也可以是消极的(为什么它会这样反应?)。
它也无法访问任何类型的数据源。 使用它来查找排名关键字的 SEO 会遇到麻烦。
它无法查找关键字的流量。 它没有超出该词存在的关键字数据的信息。

ChatGPT 令人兴奋的一点是,它是一种易于使用的语言模型,您可以开箱即用地执行各种任务。 但这并非没有警告。

其他 ML 模型的良好用途
我听到人们说他们正在使用 LLM 来完成某些任务,而其他 NLP 算法和技术可以做得更好。
举个例子,关键词提取。
如果我使用 TF-IDF 或其他关键字技术从语料库中提取关键字,我知道该技术进行了哪些计算。
这意味着结果将是标准的、可重现的,而且我知道它们将与该语料库具体相关。
对于像 ChatGPT 这样的 LLM,如果您要求提取关键字,则不一定会从语料库中提取关键字。 您得到的是 GPT认为对语料库 + 提取关键字的响应。
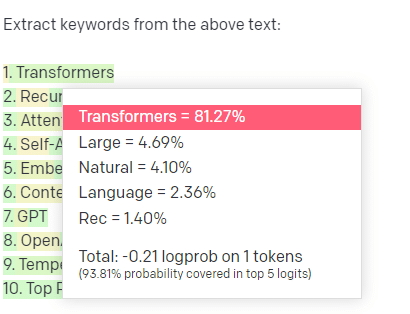
这类似于聚类或情感分析等任务。 您不一定会使用您设置的参数获得微调的结果。 你得到的是基于其他类似任务的一些可能性。
同样,法学硕士没有知识库,也没有最新信息。 他们通常无法搜索网络,并且他们将从信息中获得的信息解析为统计标记。 由于这些因素,LLM 的记忆持续时间受到限制。
另一件事是这些模型无法思考。 在这篇文章中,我只用了几次“思考”这个词,因为在谈论这些过程时真的很难不使用它。
趋势是拟人化,即使在讨论花哨的统计数据时也是如此。
但这意味着,如果你将任何需要“思考”的任务委托给法学硕士,你就不是在信任一个会思考的生物。
您相信对数百个互联网怪人对类似标记的响应的统计分析。
如果您愿意委托互联网用户完成一项任务,那么您可以使用法学硕士。 否则…
永远不应该是 ML 模型的东西
据报道,通过 GPT 模型 (GPT-J) 运行的聊天机器人鼓励一名男子自杀。 多种因素的结合可能会造成真正的伤害,包括:
- 人们将这些反应拟人化。
- 相信他们是绝对可靠的。
- 在人类需要在机器中的地方使用它们。
- 和更多。
虽然您可能会想,“我是一名 SEO。 我没有参与可以杀人的系统!”
想想 YMYL 页面以及 Google 如何推广 EEAT 等概念。
谷歌这样做是因为他们想惹恼 SEO,还是因为他们不想为这种伤害承担责任?
即使在具有强大知识库的系统中,也可能造成伤害。
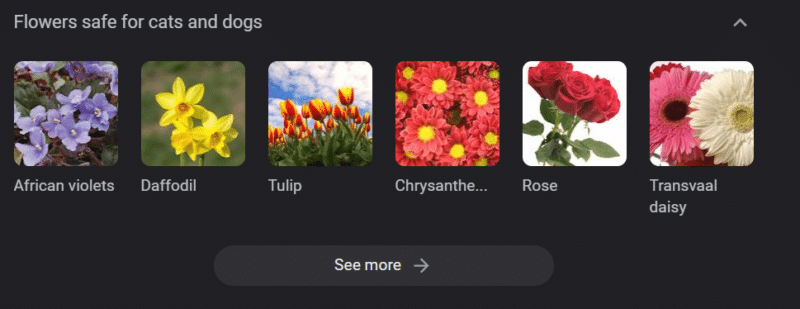
以上是“对猫和狗安全的花”的谷歌知识轮播。 尽管水仙花对猫有毒,但它仍在该名单上。
假设您正在使用 GPT 为兽医网站大规模生成内容。 您插入一堆关键字并 ping ChatGPT API。
你有一个自由职业者阅读了所有的结果,他们不是学科专家。 他们不接受一个问题。
您发布结果,鼓励猫主人购买水仙花。
你杀了别人的猫。
不直接。 也许他们甚至不知道是那个网站。
也许其他兽医网站开始做同样的事情并互相喂养。
谷歌搜索“水仙花对猫有毒吗”的顶部是一个网站,上面写着它们没有毒。
其他自由职业者阅读其他 AI 内容——一页又一页地阅读 AI 内容——实际上是在核查事实。 但是系统现在有不正确的信息。
在讨论当前的人工智能热潮时,我经常提到 Therac-25。 这是一个著名的计算机渎职案例研究。
基本上,它是一台放射治疗机,是第一台仅使用计算机锁定机制的机器。 软件中的一个故障意味着人们受到的辐射剂量是他们应该接受的数万倍。
一直让我印象深刻的是,该公司自愿召回并检查了这些模型。
但他们认为,由于技术先进且软件“绝对可靠”,问题与机器的机械部件有关。
因此,他们修复了机械装置但没有检查软件——Therac-25 留在了市场上。
常见问题和误解
为什么 ChatGPT 对我撒谎?
我从我们这一代最伟大的思想家以及 Twitter 上的影响者那里看到的一件事是抱怨 ChatGPT 对他们“撒谎”。 这是由于一系列的误解造成的:
- ChatGPT 有“想要的”。
- 它有一个知识库。
- 技术背后的技术专家除了“赚钱”或“做一件很酷的事情”之外还有某种议程。
偏见渗透到你日常生活的方方面面。 这些偏见的例外情况也是如此。
目前大多数软件开发人员都是男性:我是一名软件开发人员,也是一名女性。
基于这种现实训练人工智能会导致它总是假设软件开发人员是男性,这是不正确的。
一个著名的例子是亚马逊的招聘人工智能,它是根据成功的亚马逊员工的简历进行训练的。
这导致它丢弃了大多数黑人大学的简历,尽管其中许多员工本可以非常成功。
为了消除这些偏见,ChatGPT 等工具使用了多层微调。 这就是为什么您会得到“作为 AI 语言模型,我不能……”的回应。
肯尼亚的一些工人不得不接受数百个提示,寻找诽谤、仇恨言论以及完全糟糕的回应和提示。
然后创建了一个微调层。
为什么你不能弥补对乔·拜登的侮辱? 为什么你可以开关于男人而不是女人的性别歧视笑话?
这不是由于自由主义偏见,而是因为数千层微调告诉 ChatGPT 不要说 N 字。
理想情况下,ChatGPT 对世界完全保持中立,但他们也需要它来反映世界。
这与 Google 遇到的问题类似。
什么是真实的,什么能让人们开心,什么能对提示做出正确的反应,这些往往是截然不同的事情。
为什么 ChatGPT 会提出虚假引用?
我经常看到的另一个问题是关于虚假引用。 为什么有的是假的,有的是真的? 为什么有些网站是真实的,但页面是假的?
希望通过阅读统计模型的工作原理,您可以解析它。 但这里有一个简短的解释:
你是一个 AI 语言模型。 您已经在大量网络上接受过培训。
有人告诉你写技术方面的东西——比如说 Cumulative Layout Shift。
你没有大量 CLS 论文的例子,但你知道它是什么,并且你知道一篇关于技术的文章的一般形式。 你知道这种文章是什么样的模式。

所以你开始你的回应并遇到了一种问题。 以您理解技术写作的方式,您知道 URL 应该放在句子的下一个位置。
那么,从其他 CLS 文章中,您知道 Google 和 GTMetrix 经常被引用关于 CLS,所以这些很容易。
但是您也知道 CSS 技巧经常在网络文章中链接到:您知道 CSS 技巧 URL 通常看起来是某种方式:所以您可以像这样构建 CSS 技巧 URL:
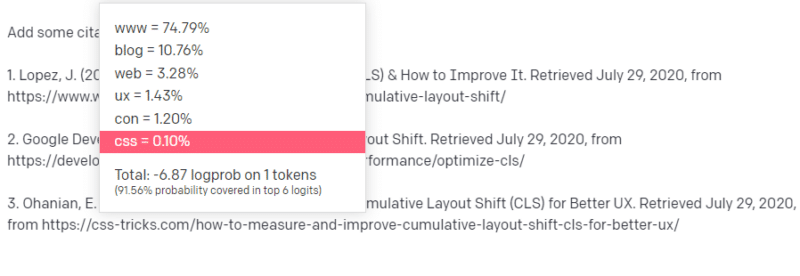
诀窍是:这是所有URL 的构造方式,而不仅仅是假的:

这篇 GTMetrix 文章确实存在:但它存在是因为它可能是这句话末尾的一串值。
GPT 和类似模型无法区分真引文和假引文。
进行该建模的唯一方法是使用其他来源(知识库、Python 等)来解析差异并检查结果。
什么是“随机鹦鹉”?
我知道我已经讨论过了,但值得重复。 Stochastic Parrots 是一种描述当大型语言模型本质上看起来是通才时会发生什么的方法。
对LLM来说,废话和现实是一样的。 他们像经济学家一样看待世界,将其视为一堆描述现实的统计数据和数字。
你知道这句话,“谎言分三种:谎言、该死的谎言和统计数据。”
法学硕士是一大堆统计数据。
法学硕士似乎是连贯的,但那是因为我们从根本上将看似人类的事物视为人类。
同样,聊天机器人模型混淆了 GPT 响应完全连贯所需的大部分提示和信息。
我是一名开发人员:尝试使用 LLM 来调试我的代码会产生极其多变的结果。 如果这是一个类似于人们经常在网上遇到的问题,那么 LLM 可以选择并修复该结果。
如果这是一个以前没有遇到过的问题,或者是语料库的一小部分,那么它不会解决任何问题。
为什么 GPT 优于搜索引擎?
我用辛辣的方式措辞。 我不认为 GPT 比搜索引擎更好。 让我担心的是人们已经用 ChatGPT 代替了搜索。
ChatGPT 的一个未被充分认识的部分是遵循说明的存在程度。 你可以要求它基本上做任何事情。
但请记住,这都是基于句子中下一个单词的统计结果,而不是事实。
因此,如果你问它一个没有好的答案的问题,但以它有义务回答的方式问它,你将得到一个糟糕的答案。
为你和你周围的人设计一个回应会更令人欣慰,但世界是一堆经验。
LLM 的所有输入都受到相同的对待:但有些人有经验,他们的反应会比其他人的反应更好。
一位专家的价值超过一千条思想。
这是人工智能的曙光吗? 天网在吗?
大猩猩可可是一只学会了手语的猿猴。 语言学研究人员做了大量研究表明可以教猿类语言。
Herbert Terrace 随后发现类人猿并没有组合句子或单词,而只是模仿它们的人类驯养员。
Eliza 是一名机器治疗师,是最早的聊天机器人(chatbots)之一。
人们将她视为一个人:他们信任和关心的治疗师。 他们要求研究人员与她单独相处。
语言对人们的大脑有非常特殊的作用。 人们听到一些交流并期待其背后的想法。
法学硕士令人印象深刻,但在某种程度上显示了人类成就的广度。
法学硕士没有遗嘱。 他们逃不掉。 他们不能试图接管世界。
它们是一面镜子:具体反映人和用户。
唯一的想法是集体无意识的统计表示。
GPT 是自己学会了一门完整的语言吗?
Google 首席执行官 Sundar Pichai 在“60 分钟”节目中声称 Google 的语言模型学会了孟加拉语。
该模型是在这些文本上训练的。 它“说一种从未受过训练的外语”是不正确的。
有时 AI 会做出意想不到的事情,但这本身就是意料之中的事情。
当您查看大规模的模式和统计数据时,这些模式必然会揭示一些令人惊讶的东西。
这真正揭示的是,许多兜售 AI 和 ML 的高管和营销人员实际上并不了解这些系统的工作原理。
我听过一些非常聪明的人谈论涌现属性、通用人工智能 (AGI) 和其他未来主义事物。
我可能只是一个普通的国家 ML 操作工程师,但它显示了在谈论这些系统时有多少炒作、承诺、科幻小说和现实被混为一谈。
Theranos 臭名昭著的创始人伊丽莎白·霍姆斯 (Elizabeth Holmes) 因做出无法兑现的承诺而被钉在十字架上。
但做出不可能的承诺的循环是创业文化和赚钱的一部分。 Theranos 和 AI 炒作的不同之处在于,Theranos 无法长期伪造它。
GPT 是黑盒子吗? 我在 GPT 中的数据会怎样?
作为模型,GPT 不是黑匣子。 您可以查看 GPT-J 和 GPT-Neo 的源代码。
然而,OpenAI 的 GPT 是一个黑盒子。 OpenAI 还没有并且可能会尝试不发布其模型,因为谷歌不发布算法。
但这并不是因为该算法太危险了。 如果那是真的,他们就不会向任何拥有计算机的傻瓜出售 API 订阅。 这是因为专有代码库的价值。
当您使用 OpenAI 的工具时,您是在根据您的输入训练和提供他们的 API。 这意味着您放入 OpenAI 的所有内容都可以满足它的需求。
这意味着那些在患者数据上使用 OpenAI 的 GPT 模型来帮助写笔记和其他事情的人违反了 HIPAA。 该信息现在位于模型中,提取它非常困难。
因为很多人难以理解这一点,很可能该模型包含大量私人数据,只是等待正确的提示来发布它。
为什么 GPT 接受仇恨言论训练?
另一件经常出现的事情是,GPT 训练的文本语料库包括仇恨言论。
在某种程度上,OpenAI 需要训练其模型来响应仇恨言论,因此它需要一个包含其中一些术语的语料库。
OpenAI 声称从系统中清除了这种仇恨言论,但源文件包括 4chan 和大量仇恨网站。
爬网,吸收偏见。
没有简单的方法可以避免这种情况。 如果不将其作为训练集的一部分,您如何能够识别或理解仇恨、偏见和暴力?
当您作为机器代理以统计方式选择句子中的下一个标记时,您如何避免偏见并理解隐式和显式偏见?
长话短说
炒作和错误信息是目前人工智能繁荣的主要因素。 这并不意味着没有合法用途:这项技术令人惊叹且有用。
但该技术的营销方式以及人们的使用方式可能助长错误信息、剽窃甚至造成直接伤害。
生死攸关时不要使用法学硕士。 当不同的算法会做得更好时,不要使用 LLM。 不要被炒作所欺骗。
了解什么是法学硕士——什么不是——是必要的
我推荐 Adam Conover 采访 Emily Bender 和 Timnit Gebru。
如果使用得当,LLM 可以成为不可思议的工具。 您可以通过多种方式使用 LLM,甚至可以通过更多方式滥用 LLM。
ChatGPT 不是你的朋友。 这是一堆统计数据。 AGI 并非“已经存在”。
本文中表达的观点是客座作者的观点,不一定是 Search Engine Land。 此处列出了工作人员作者。