
Spark vs Hadoop:哪个大数据框架将提升您的业务?
已发表: 2019-09-24“数据是数字经济的燃料”
随着现代企业依靠大量数据来更好地了解他们的消费者和市场,大数据等技术正在获得巨大的发展势头。
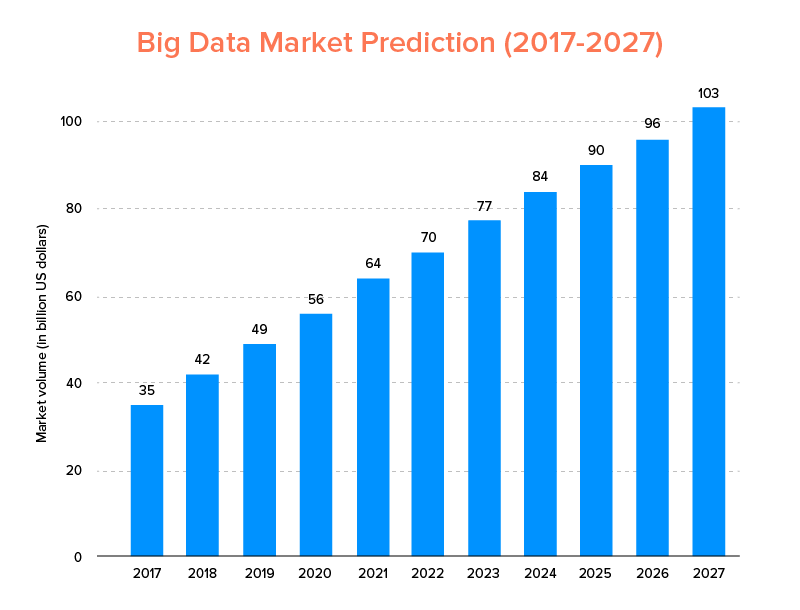
大数据,就像人工智能一样,不仅进入了2020 年的顶级技术趋势,而且预计将被初创公司和财富 500 强公司所接受,以享受指数级的业务增长并确保更高的客户忠诚度。 一个明确的迹象是,到 2027 年,大数据市场预计将达到 $103B。
现在,虽然一方面每个人都非常有动力用大数据取代他们的传统数据分析工具——大数据为区块链和人工智能的发展奠定了基础,但他们也对选择正确的大数据工具感到困惑。 他们面临着在大数据世界的两大巨头 Apache Hadoop 和 Spark 之间进行选择的困境。
因此,考虑到这个想法,今天我们将介绍一篇关于 Apache Spark 与 Hadoop 的文章,并帮助您确定哪一个是满足您需求的正确选择。
但是,首先让我们简单介绍一下什么是 Hadoop 和 Spark。
Apache Hadoop 是一个开源、分布式和基于 Java 的框架,使用户能够使用简单的编程结构跨多个计算机集群存储和处理大数据。 它由各种模块组成,这些模块协同工作以提供增强的体验,它们是:-
- Hadoop 通用
- Hadoop 分布式文件系统 (HDFS)
- Hadoop 纱线
- Hadoop MapReduce
鉴于 Apache Spark 是一个开源分布式集群计算大数据框架,它“易于使用”并提供更快的服务。
由于它们提供的一系列机会,这两个大数据框架得到了众多大公司的支持。
Hadoop大数据框架的优势
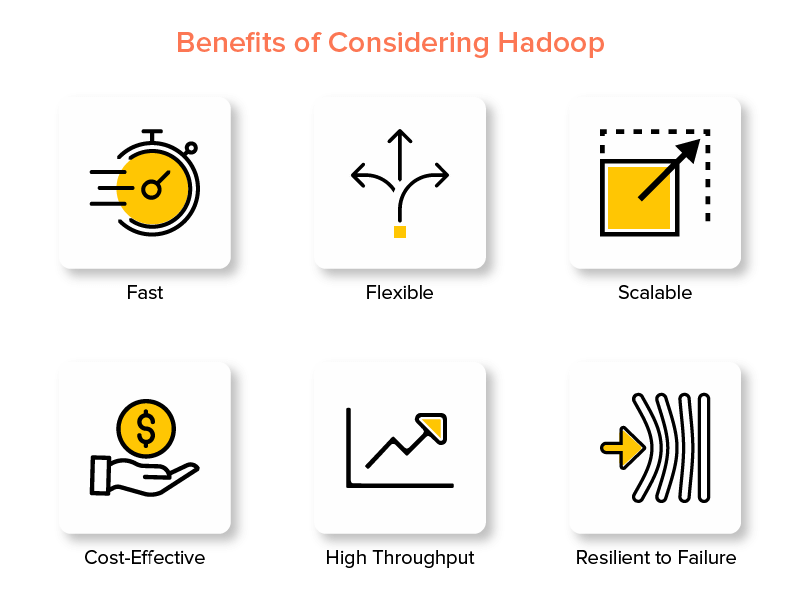
1.快
Hadoop 在大数据世界中流行的特点之一是速度快。
它的存储方法基于分布式文件系统,该系统主要“映射”位于集群上任何位置的数据。 此外,用于数据处理的数据和工具通常在同一台服务器上可用,这使得数据处理成为一项轻松快捷的任务。
事实上,已经发现 Hadoop 可以在短短几分钟内处理 TB 级的非结构化数据,而 PB 级的数据则需要几小时。
2.灵活
与传统的数据处理工具不同,Hadoop 提供了高端的灵活性。
它允许企业从不同来源(如社交媒体、电子邮件等)收集数据,使用不同的数据类型(结构化和非结构化),并获得有价值的见解以进一步用于各种目的(如日志处理、市场活动分析、欺诈检测等)。
3.可扩展
Hadoop 的另一个优点是它具有高度可扩展性。 与传统的关系数据库系统 (RDBMS)不同,该平台使企业能够存储和分发来自数百台并行运行的服务器的大型数据集。
4.具有成本效益
与其他大数据分析工具相比,Apache Hadoop 便宜得多。 这是因为它不需要任何专门的机器; 它在一组商品硬件上运行。 此外,从长远来看,添加更多节点更容易。
这意味着,一种情况很容易增加节点,而不会受到任何预先计划要求的停机时间的影响。
5.高吞吐量
在 Hadoop 框架的情况下,数据以分布式方式存储,以便将一个小作业并行拆分为多个数据块。 这使企业更容易在更短的时间内完成更多工作,最终提高吞吐量。
6.对失败有弹性
最后但同样重要的是,Hadoop 提供了高容错选项,有助于减轻失败的后果。 它存储每个块的副本,以便在任何节点出现故障时恢复数据。
Hadoop框架的缺点
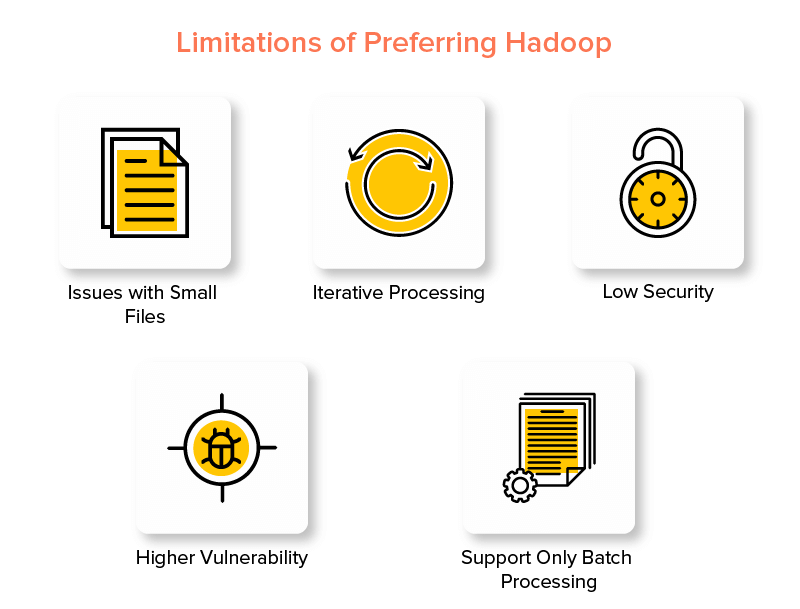
1.小文件的问题
考虑使用 Hadoop 进行大数据分析的最大缺点是它缺乏支持有效地随机读取小文件的潜力。
这背后的原因是,小文件的内存大小比 HDFS 块大小要小。 在这种情况下,如果存储了大量的小文件,那么存储 HDFS 命名空间的NameNode很可能会过载,这实际上不是一个好主意。
2.迭代处理
大数据Hadoop框架中的数据流是链式的,一个阶段的输出成为另一个阶段的输入。 而迭代处理中的数据流本质上是循环的。
因此,Hadoop 不适合机器学习或基于迭代处理的解决方案。
3.安全性低
使用 Hadoop 框架的另一个缺点是提供了较低的安全功能。
例如,该框架默认禁用安全模型。 如果使用此大数据工具的人不知道如何启用它,他们的数据可能会面临更高的被盗/滥用风险。 此外,Hadoop 不提供存储和网络级别的加密功能,这再次增加了数据泄露威胁的可能性。
4.更高的脆弱性
Hadoop 框架是用 Java 编写的,Java 是最流行但被大量利用的编程语言。 这使网络犯罪分子更容易轻松访问基于 Hadoop 的解决方案并滥用敏感数据。
5.仅支持批处理
与其他各种大数据框架不同,Hadoop 不处理流数据。 它只支持批处理,其背后的原因是 MapReduce 未能最大限度地利用 Hadoop Cluster 的内存。
虽然这都是关于 Hadoop 及其特性和缺点的,但让我们来看看 Spark 的优缺点,以便轻松理解两者之间的区别。
Apache Spark 框架的好处
1.本质上是动态的
由于 Apache Spark 提供了大约 80 个高级运算符,因此可以用于动态处理数据。 它可以被认为是开发和管理并行应用程序的正确大数据工具。
2.强大
由于其低延迟的内存数据处理能力和各种用于机器学习和图形分析算法的内置库的可用性,它可以应对各种分析挑战。 这使其成为市场上强大的大数据选项。
3.高级分析
Spark 的另一个显着特点是它不仅鼓励“MAP”和“reduce”,还支持机器学习(ML)、SQL 查询、图算法和流式数据。 这使其适合享受高级分析。
4.可重用性
与 Hadoop 不同,Spark 代码可以重用于批处理、对流状态运行临时查询、针对历史数据加入流等等。
5.实时流处理
使用 Apache Spark 的另一个优点是它可以实时处理和处理数据。
6.多语言支持
最后但同样重要的是,这个大数据分析工具支持多种编码语言,包括 Java、Python 和 Scala。
Spark 大数据工具的局限性

1.无文件管理流程
使用 Apache Spark 的主要缺点是它没有自己的文件管理系统。 它依赖于 Hadoop 等其他平台来满足这一要求。
2.少数算法
在考虑谷本距离等算法的可用性时,Apache Spark 也落后于其他大数据框架。
3.小文件问题
使用 Spark 的另一个缺点是它不能有效地处理小文件。
这是因为它使用 Hadoop 分布式文件系统 (HDFS) 运行,它发现管理有限数量的大文件而不是大量小文件更容易。
4.没有自动优化过程
与其他各种大数据和基于云的平台不同,Spark 没有任何自动代码优化过程。 只需手动优化代码。
5.不适合多用户环境
由于 Apache Spark 无法同时处理多个用户,因此在多用户环境中运行效率不高。 这再次增加了它的局限性。
了解了这两个大数据框架的基础知识后,您可能希望熟悉 Spark 和 Hadoop 之间的区别。
因此,让我们不要再等了,直接进行比较,看看哪一个引领了“Spark 与 Hadoop”之战。
Spark vs Hadoop:两种大数据工具如何相互叠加
[表id=38 /]
1.建筑
当谈到 Spark 和 Hadoop 架构时,即使两者都在分布式计算环境中运行,后者也处于领先地位。
之所以如此,是因为 Hadoop 的架构——与 Spark 不同——有两个主要元素——HDFS(Hadoop 分布式文件系统)和 YARN(又一个资源协商器)。 在这里,HDFS 处理跨不同节点的大数据存储,而 YARN 通过资源分配和作业调度机制处理任务。 然后将这些组件进一步划分为更多组件,以提供具有容错等服务的更好解决方案。
2.易用性
Apache Spark 使开发人员能够在他们的开发环境中引入各种用户友好的 API,例如 Scala、Python、R、Java 和 Spark SQL。 此外,它还加载了支持用户和开发人员的交互模式。 这使其易于使用且学习曲线低。
然而,在谈到 Hadoop 时,它提供了支持用户的附加组件,但不是交互模式。 这使得 Spark 在这场“大数据”之战中战胜了 Hadoop。
3.容错性和安全性
虽然 Apache Spark 和 Hadoop MapReduce 都提供容错功能,但后者赢得了战斗。
这是因为必须从头开始,以防进程在 Spark 环境中的运行过程中崩溃。 但是,当谈到 Hadoop 时,他们可以从崩溃本身继续。
4.性能
在考虑 Spark 与 MapReduce 的性能时,前者胜过后者。
Spark 框架能够在磁盘上运行速度提高 10 倍,在内存中运行速度提高 100 倍。 这使得管理 100 TB 数据的速度比 Hadoop MapReduce 快 3 倍。
5.数据处理
在 Apache Spark 与 Hadoop 比较期间要考虑的另一个因素是数据处理。
虽然 Apache Hadoop 仅提供批处理的机会,但其他大数据框架支持使用交互式、迭代、流、图形和批处理。 证明 Spark 是享受更好的数据处理服务的更好选择。
6.兼容性
Spark 和 Hadoop MapReduce 的兼容性有些相同。
虽然有时,两个大数据框架都充当独立的应用程序,但它们也可以一起工作。 Spark 可以在 Hadoop YARN 之上高效运行,而 Hadoop 可以轻松与Sqoop和 Flume 集成。 因此,两者都支持彼此的数据源和文件格式。
7.安全
Spark 环境加载了不同的安全功能,例如事件日志记录和使用 javax servlet 过滤器来保护 Web UI。 此外,它鼓励通过共享密钥进行身份验证,并且在与 YARN 和 HDFS 集成时可以利用 HDFS 文件权限、跨模式加密和 Kerberos 的潜力。
而 Hadoop 支持Kerberos身份验证、第三方身份验证、常规文件权限和访问控制列表等,最终提供了更好的安全结果。
因此,在安全性方面考虑 Spark 与 Hadoop 的比较时,后者领先。
8.成本效益
在比较 Hadoop 和 Spark 时,前者需要更多的磁盘内存,而后者需要更多的 RAM。 此外,由于 Spark 与 Apache Hadoop 相比是相当新的,因此使用 Spark 的开发人员较少。
这使得使用 Spark 成为一件昂贵的事情。 这意味着,当人们关注 Hadoop 与 Spark 成本时,Hadoop 提供了具有成本效益的解决方案。
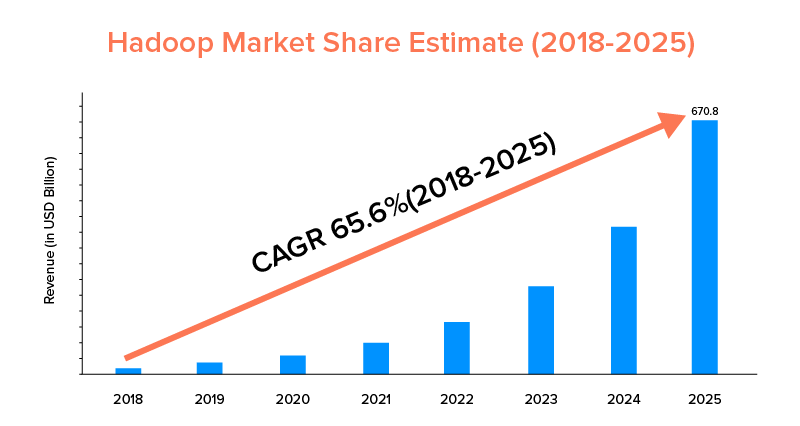
九、市场范围
虽然 Apache Spark 和 Hadoop 都得到大公司的支持,并且被用于不同的目的,但后者在市场范围方面处于领先地位。
根据市场统计,Apache Hadoop 市场预计在 2018 年至 2025 年期间的复合年增长率为 65.6%,而 Spark 的复合年增长率仅为 33.9%。
虽然这些因素将有助于为您的企业确定合适的大数据工具,但熟悉它们的用例是有利可图的。 所以,让我们在这里介绍一下。
Apache Spark 框架的用例
当企业希望:
- 实时流式传输和分析数据。
- 享受机器学习的力量。
- 使用交互式分析。
- 将雾和边缘计算引入他们的商业模式。
Apache Hadoop 框架的用例
当初创公司和企业想要:-
- 分析存档数据。
- 享受更好的金融交易和预测选项。
- 执行包含商品硬件的操作。
- 考虑线性数据处理。
有了这个,我们希望您已经决定哪一个是与您的业务相关的“Spark 与 Hadoop”之战的赢家。 如果没有,请随时与我们的大数据专家联系,以消除所有疑虑并获得更高成功率的模范服务。
经常问的问题
1. 选择哪种大数据框架?
选择完全取决于您的业务需求。 如果你关注性能、数据兼容性和易用性,Spark 比 Hadoop 更好。 然而,当您专注于架构、安全性和成本效益时,Hadoop 大数据框架会更好。
2. Hadoop和Spark有什么区别?
Spark 和 Hadoop 之间存在各种差异。 例如:-
- Spark 是 Hadoop MapReduce 的 100 倍。
- 虽然 Hadoop 用于批处理,但 Spark 用于批处理、图形、机器学习和迭代处理。
- Spark 比 Hadoop 大数据框架更紧凑、更简单。
- 与 Spark 不同,Hadoop 不支持数据缓存。
3. Spark 比 Hadoop 更好吗?
当您的主要关注点是速度和安全性时,Spark 比 Hadoop 更好。 然而,在其他情况下,这个大数据分析工具落后于 Apache Hadoop。
4. 为什么 Spark 比 Hadoop 快?
Spark 比 Hadoop 更快,因为磁盘的读/写周期数较少,并且将中间数据存储在内存中。
5. Apache Spark 是做什么用的?
Apache Spark 用于数据分析,当人们想要 -
- 实时分析数据。
- 将 ML 和雾计算引入您的业务模型。
- 使用交互式分析。