
TW-BERT:端到端查询词权重和 Google 搜索的未来
已发表: 2023-09-14正如 Seth Godin 在 2005 年所写的那样,搜索是困难的。
我的意思是,如果我们认为 SEO 很难(确实如此),想象一下,如果您试图在以下世界中构建一个搜索引擎:
- 用户差异很大,并且他们的偏好会随着时间的推移而改变。
- 他们使用的搜索技术每天都在进步。
- 竞争对手不断紧随你的脚步。
最重要的是,您还要应对讨厌的 SEO,他们试图欺骗您的算法,从而深入了解如何最好地为您的访问者进行优化。
这会让事情变得更加困难。
现在想象一下,如果您需要依靠的主要技术有其自身的局限性 - 也许更糟糕的是,成本高昂。
好吧,如果您是最近发表的论文“端到端查询术语权重”的作者之一,您会认为这是一个发光的机会。
什么是端到端查询词权重?
端到端查询术语加权是指将查询中每个术语的权重确定为整体模型的一部分的方法,而不依赖于手动编程或传统的术语加权方案或其他独立模型。
那看起来像什么?
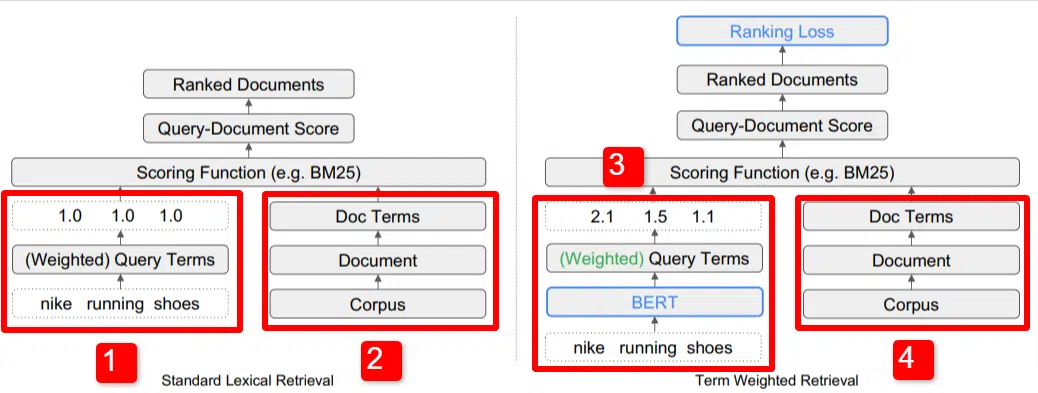
在这里,我们看到了论文中概述的模型的关键区别之一的图示(具体如图 1 所示)。
在标准模型 (2) 的右侧,我们看到与建议模型 (4) 相同的内容,即语料库(索引中的完整文档集),通向文档,通向术语。
这说明了系统的实际层次结构,但您可以随意地从上到下逆向思考它。 我们有条件。 我们寻找包含这些术语的文档。 这些文件包含在我们所知道的所有文件的语料库中。
在标准信息检索 (IR) 架构的左下角 (1),您会注意到没有 BERT 层。 他们的插图(耐克跑鞋)中使用的查询进入系统,权重的计算独立于模型并传递给模型。
在此图中,权重在查询中的三个单词之间均匀传递。 然而,情况并非一定如此。 这只是一个默认且很好的说明。
需要理解的重要一点是,权重是从模型外部分配的,并通过查询输入。 我们稍后将介绍为什么这很重要。
如果我们查看右侧的术语权重版本,您会发现查询“nike running Shoes”输入了 BERT(术语权重 BERT,具体而言是 TW-BERT),用于分配权重最适合该查询。
从那里开始,两者都遵循类似的路径,应用评分函数并对文档进行排名。 但新模型还有一个关键的最后一步,这才是真正的重点,即排名损失计算。
我在上面提到的这种计算使得模型中确定的权重变得非常重要。 为了最好地理解这一点,让我们快速讨论一下损失函数,这对于真正理解这里发生的事情很重要。
什么是损失函数?
在机器学习中,损失函数基本上是计算系统的错误程度,该系统试图学习尽可能接近零损失。
让我们以一个旨在确定房价的模型为例。 如果您输入房屋的所有统计数据,得出的价值为 250,000 美元,但您的房屋售价为 260,000 美元,则差额将被视为损失(这是绝对值)。
通过大量示例,模型被教导通过为给定的参数分配不同的权重来最小化损失,直到获得最佳结果。 在这种情况下,参数可能包括平方英尺、卧室、庭院大小、与学校的距离等。
现在,回到查询词权重
回顾上面的两个例子,我们需要关注的是 BERT 模型的存在,它为排名损失计算的下漏斗项提供权重。
换句话说,在传统模型中,项的加权是独立于模型本身进行的,因此无法响应整体模型的表现。 它无法学习如何提高权重。
在提议的系统中,这种情况发生了变化。 加权是在模型本身内部完成的,因此,当模型寻求提高其性能并减少损失函数时,它具有这些额外的旋钮来将项加权引入方程。 字面上地。
ngrams
TW-BERT 的设计目的不是用单词来操作,而是用 ngram 来操作。

这篇论文的作者很好地说明了为什么他们使用 ngrams 而不是单词,他们指出,在查询“nike running Shoes”中,如果你简单地对单词进行加权,那么提及单词 nike、running 和 Shoes 的页面甚至可以排名很好如果正在讨论“耐克跑步袜”和“滑板鞋”。
传统的 IR 方法使用查询统计和文档统计,并且可能会显示存在此问题或类似问题的页面。 过去解决这个问题的尝试主要集中在共现和排序上。
在这个模型中,ngram 的权重与我们之前示例中的单词相同,因此我们最终得到如下结果:
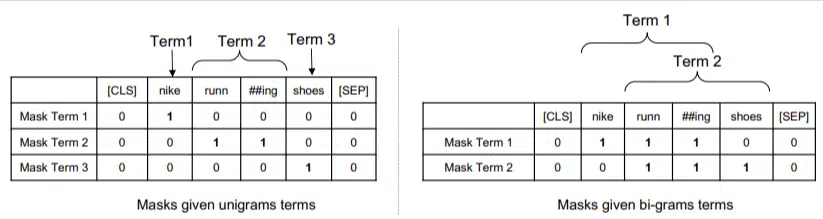
在左边,我们看到查询如何被加权为 uni-gram(1 个单词的 ngram),而在右边,我们看到如何将查询加权为 bi-gram(2 个单词的 ngram)。
该系统由于内置了权重,因此可以对所有排列进行训练,以确定最佳的 ngram 以及每个 ngram 的适当权重,而不是仅依赖于频率等统计数据。
零射击
该模型的一个重要特征是其在零短任务中的性能。 作者测试了:
- MS MARCO 数据集 – 用于文档和段落排名的 Microsoft 数据集
- TREC-COVID 数据集 – COVID 文章和研究
- Robust04 – 新闻文章
- 共同核心 – 教育文章和博客文章
他们只有少量的评估查询,并且没有使用任何微调,这使得这是一个零样本测试,因为该模型没有经过训练来专门对这些领域的文档进行排名。 结果是:
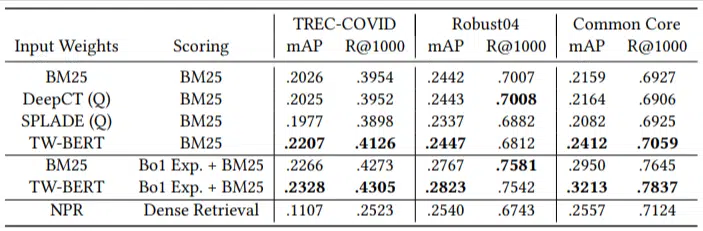
它在大多数任务中都表现出色,并且在较短的查询(1 到 10 个单词)上表现最好。
而且它是即插即用的!
好吧,这可能过于简单化了,但作者写道:
“将 TW-BERT 与搜索引擎评分器结合起来,可以最大限度地减少将其集成到现有生产应用程序中所需的更改,而现有的基于深度学习的搜索方法将需要进一步的基础设施优化和硬件要求。 标准词汇检索器和其他检索技术(例如查询扩展)可以轻松利用学习到的权重。”
由于 TW-BERT 旨在集成到当前系统中,因此集成比其他选项更简单、更便宜。
这一切对你意味着什么
使用机器学习模型,很难预测 SEO 可以采取哪些措施(除了 Bard 或 ChatGPT 等可见部署之外)。
由于该模型的改进和易于部署(假设陈述准确),毫无疑问将部署该模型的排列。
也就是说,这是谷歌生活质量的一项改进,它将以低成本提高排名和零样本结果。
我们真正可以信赖的是,如果实施,更好的结果将会更可靠地浮现。 这对于 SEO 专业人士来说是个好消息。
本文表达的观点是客座作者的观点,并不一定是搜索引擎土地的观点。 此处列出了工作人员作者。