
什么是生成式人工智能以及它是如何工作的?
已发表: 2023-09-26生成式人工智能是人工智能的一个子集,已成为科技界的一股革命力量。 但它到底是什么? 为什么它会受到如此多的关注?
这份深入的指南将深入探讨生成式人工智能模型的工作原理、它们能做什么和不能做什么,以及所有这些元素的含义。
什么是生成式人工智能?
生成式人工智能(genAI)是指能够生成新内容的系统,无论是文本、图像、音乐,甚至视频。 传统上,AI/ML 意味着三件事:监督学习、无监督学习和强化学习。 每个都给出基于聚类输出的见解。
非生成式人工智能模型根据输入进行计算(例如对图像进行分类或翻译句子)。 相比之下,生成模型会产生“新”输出,例如写论文、作曲、设计图形,甚至创建现实世界中不存在的逼真人脸。
生成式人工智能的影响
生成式人工智能的兴起具有重大影响。 凭借生成内容的能力,娱乐、设计和新闻等行业正在经历范式转变。
例如,新闻机构可以使用人工智能起草报告,而设计师可以获得人工智能辅助的图形建议。 人工智能可以在几秒钟内生成数百个广告口号——无论这些选项是否好 或不是另一回事。
生成式人工智能可以为个人用户生成量身定制的内容。 想象一下类似音乐应用程序的东西,它可以根据您的心情创作一首独特的歌曲,或者新闻应用程序可以起草有关您感兴趣的主题的文章。
问题在于,随着人工智能在内容创作中发挥着越来越重要的作用,有关真实性、版权和人类创造力价值的问题变得更加普遍。
生成式人工智能如何运作?
生成式人工智能的核心是预测序列中的下一个数据,无论是句子中的下一个单词还是图像中的下一个像素。 让我们来分解一下这是如何实现的。
统计模型
统计模型是大多数人工智能系统的支柱。 他们使用数学方程来表示不同变量之间的关系。
对于生成式人工智能,模型经过训练可以识别数据中的模式,然后使用这些模式生成 新的、相似的数据。
如果一个模型接受英语句子的训练,它就会学习一个单词跟在另一个单词后面的统计可能性,从而生成连贯的句子。
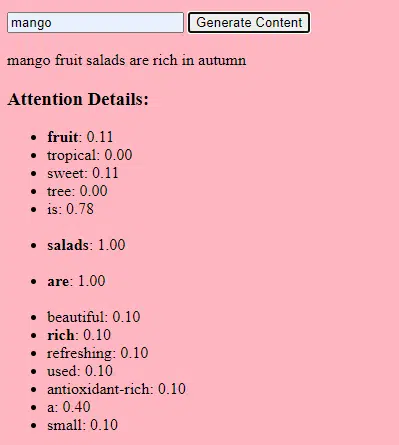
数据收集
数据的质量和数量都至关重要。 生成模型在大量数据集上进行训练以理解模式。
对于语言模型来说,这可能意味着从书籍、网站和其他文本中提取数十亿个单词。
对于图像模型来说,这可能意味着分析数百万张图像。 训练数据越多样化、越全面,模型生成多样化输出的效果就越好。
变压器和注意力如何发挥作用
Transformer 是 Vaswani 等人在 2017 年题为“Attention Is All You Need”的论文中介绍的一种神经网络架构。 它们从此成为大多数最先进语言模型的基础。 如果没有 Transformer,ChatGPT 将无法工作。
“注意力”机制允许模型关注输入数据的不同部分,就像人类在理解句子时关注特定单词一样。
这种机制让模型决定输入的哪些部分与给定任务相关,使其高度灵活和强大。
下面的代码是变压器机制的基本分解,用简单的英语解释了每个部分。
class Transformer: # Convert words to vectors # What this is : turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other. # Demo : "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9] self.embedding = Embedding(vocab_size, d_model) # Add position information to the vectors # What this is : Since words in a sentence have a specific order, we add information about each word's position in the sentence. # Demo : "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06] self.positional_encoding = PositionalEncoding(d_model) # Stack of transformer layers # What this is : Multiple layers of the Transformer model stacked on top of each other to process data in depth. # Why it does it : Each layer captures different patterns and relationships in the data. # Explained like I'm five : Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done! self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)] # Convert the output vectors to word probabilities # What this is : A way to predict the next word in a sequence. # Why it does it : After processing the input, we want to guess what word comes next. # Explained like I'm five : After listening to a story, this tries to guess what happens next. self.output_layer = Linear(d_model, vocab_size) def forward(self, x): # Convert words to vectors, as above x = self.embedding(x) # Add position information, as above x = self.positional_encoding(x) # Pass through each transformer layer # What this is : Sending our data through each floor of our multi-story building. # Why it does it : To deeply process and understand the data. # Explained like I'm five : It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess. for layer in self.transformer_layers: x = layer(x) # Get the output word probabilities # What this is : Our best guess for the next word in the sequence. return self.output_layer(x)在代码中,您可能有一个 Transformer 类和一个 TransformerLayer 类。 这就像有一个楼层的蓝图与整个建筑物的蓝图一样。
这段 TransformerLayer 代码向您展示了特定组件(例如多头注意力和特定安排)如何工作。
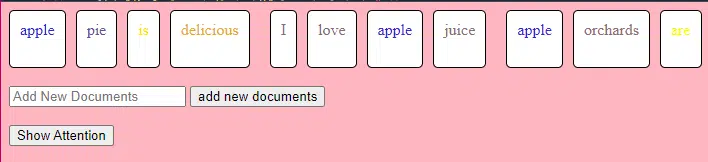
class TransformerLayer: # Multi-head attention mechanism # What this is : A mechanism that lets the model focus on different parts of the input data simultaneously. # Demo : "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words. self.attention = MultiHeadAttention(d_model, nhead) # Simple feed-forward neural network # What this is : A basic neural network that processes the data after the attention mechanism. # Demo : "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing) self.feed_forward = FeedForward(d_model) def forward(self, x): # Apply attention mechanism # What this is : The step where we focus on different parts of the sentence. # Explained like I'm five : It's like highlighting important parts of a book. attention_output = self.attention(x, x, x) # Pass the output through the feed-forward network # What this is : The step where we process the highlighted information. return self.feed_forward(attention_output)前馈神经网络是最简单的人工神经网络类型之一。 它由一个输入层、一个或多个隐藏层和一个输出层组成。
数据沿一个方向流动——从输入层,通过隐藏层,最后到达输出层。 网络中不存在环路或环路。
在 Transformer 架构的背景下,前馈神经网络在每层的注意力机制之后使用。 这是一个简单的两层线性变换,中间有一个 ReLU 激活。
# Scaled dot-product attention mechanism class ScaledDotProductAttention: def __init__(self, d_model): # Scaling factor helps in stabilizing the gradients # it reduces the variance of the dot product. # What this is: A scaling factor based on the size of our model's embeddings. # What it does : Helps to make sure the dot products don't get too big. # Why it does it : Big dot products can make a model unstable and harder to train. # How it does it : By dividing the dot products by the square root of the embedding size. # It's used when calculating attention scores. # Explained like I'm five : Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud. self.scaling_factor = d_model ** 0.5 def forward(self, query, key, value): # What this is : The function that calculates how much attention each word should get. # What it does : Determines how relevant each word in a sentence is to every other word. # Why it does it : So we can focus more on important words when trying to understand a sentence. # How it does it : By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values. # How it fits into the rest of the code : This function is called whenever we want to calculate attention in our model. # Explained like I'm five : Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers. # Calculate attention scores by taking the dot product of the query and key. scores = dot_product(query, key) / self.scaling_factor # Convert the raw scores to probabilities using the softmax function. attention_weights = softmax(scores) # Weight the values using the attention probabilities. return dot_product(attention_weights, value) # Feed-forward neural network # This is an extremely basic example of a neural network. class FeedForward: def __init__(self, d_model): # First linear layer increases the dimensionality of the data. self.layer1 = Linear(d_model, d_model * 4) # Second linear layer brings the dimensionality back to d_model. self.layer2 = Linear(d_model * 4, d_model) def forward(self, x): # Pass the input through the first layer, #Pass the input through the first layer: # Input : This refers to the data you feed into the neural network. I # First layer : Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output. # apply ReLU activation to introduce non-linearity, # and then pass through the second layer. #ReLU activation: ReLU stands for Rectified Linear Unit. # It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero. # Neural networks can model complex relationships in data by introducing non-linearities. # Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model. # Non-linearities allow the network to capture complex patterns and make better predictions. return self.layer2(relu(self.layer1(x))) # Positional encoding adds information about the position of each word in the sequence. class PositionalEncoding: def __init__(self, d_model): # What this is : A setup to add information about where each word is in a sentence. # What it does : Prepares to add a unique "position" value to each word. # Why it does it : Words in a sentence have an order, and this helps the model remember that order. # How it does it : By creating a special pattern of numbers for each position in a sentence. # How it fits into the rest of the code : Before processing words, we add their position info. # Explained like I'm five : Imagine you're in a line with your friends. This gives everyone a number to remember their place in line. pass def forward(self, x): # What this is : The main function that adds position info to our words. # What it does : Combines the word's original value with its position value. # Why it does it : So the model knows the order of words in a sentence. # How it does it : By adding the position values we prepared earlier to the word values. # How it fits into the rest of the code : This function is called whenever we want to add position info to our words. # Explained like I'm five : It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on. return x # Helper functions def dot_product(a, b): # Calculate the dot product of two matrices. # What this is : A mathematical operation to see how similar two lists of numbers are. # What it does : Multiplies matching items in the lists and then adds them up. # Why it does it : To measure similarity or relevance between two sets of data. # How it does it : By multiplying and summing up. # How it fits into the rest of the code : Used in attention to see how relevant words are to each other. # Explained like I'm five : Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have. return a @ b.transpose(-2, -1) def softmax(x): # Convert raw scores to probabilities ensuring they sum up to 1. # What this is : A way to turn any list of numbers into probabilities. # What it does : Makes the numbers between 0 and 1 and ensures they all add up to 1. # Why it does it : So we can understand the numbers as chances or probabilities. # How it does it : By using exponentiation and division. # How it fits into the rest of the code : Used to convert attention scores into probabilities. # Explained like I'm five : Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind. return exp(x) / sum(exp(x), axis=-1) def relu(x): # Activation function that introduces non-linearity. It sets negative values to 0. # What this is : A simple rule for numbers. # What it does : If a number is negative, it changes it to zero. Otherwise, it leaves it as it is. # Why it does it : To introduce some simplicity and non-linearity in our model's calculations. # How it does it : By checking each number and setting it to zero if it's negative. # How it fits into the rest of the code : Used in neural networks to make them more powerful and flexible. # Explained like I'm five : Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones. return max(0, x)生成式人工智能如何运作——简单来说
将生成式人工智能视为掷加权骰子。 训练数据决定权重(或概率)。
如果骰子代表句子中的下一个单词,则训练数据中经常跟随当前单词的单词将具有更高的权重。 因此,“天空”可能比“香蕉”更频繁地跟随“蓝色”。 当人工智能“掷骰子”生成内容时,它更有可能根据其训练选择统计上更可能的序列。
那么,法学硕士如何才能生成“看似”原创的内容呢?
让我们以一个虚假的列表文章——“内容营销人员的最佳开斋节礼物”——来看看法学硕士如何产生 该列表结合了有关礼物、开斋节和内容营销人员的文件中的文本提示。
在处理之前,文本被分解成称为“标记”的更小的片段。 这些标记可以短至一个字符,也可以长至一个单词。
示例: “Eid al-Fitr 是一个庆祝活动”变为 [“Eid”、“al-Fitr”、“is”、“a”、“celebration”]。
这使得模型能够处理可管理的文本块并理解句子的结构。
然后使用嵌入将每个标记转换为向量(数字列表)。 这些向量捕获每个单词的含义和上下文。
位置编码向每个词向量添加有关其在句子中的位置的信息,确保模型不会丢失该顺序信息。
然后我们使用注意力机制:这使得模型在生成输出时能够关注输入文本的不同部分。 如果您还记得 BERT,这就是让 Google 员工对 BERT 如此兴奋的地方。
如果我们的模型看到了关于“礼物”的文本,并且知道人们在庆祝活动中赠送礼物,并且它也看到了关于“开斋节”是一个重要庆祝活动的文本,那么它就会“关注”这些联系。
同样,如果它看到关于“内容营销人员”需要特定工具或资源的文本,它可以将“礼物”的想法与“内容营销人员”联系起来。

现在我们可以组合上下文:当模型通过多个 Transformer 层处理输入文本时,它会组合它所学到的上下文。
因此,即使原文从未提及“内容营销人员的开斋节礼物”,该模型也可以将“开斋节”、“礼物”和“内容营销人员”的概念结合在一起来生成此内容。
这是因为它已经了解了每个术语的更广泛背景。
通过注意力机制和每个 Transformer 层中的前馈网络处理输入后,模型会生成序列中下一个单词的词汇表的概率分布。
它可能会认为,在“最好”和“开斋节”等词之后,接下来出现的词“礼物”很有可能。 同样,它可能会将“礼物”与“内容营销人员”等潜在接收者联系起来。
获取搜索营销人员信赖的每日新闻通讯。

查看条款。
构建多大的语言模型
从基本 Transformer 模型到 GPT-3 或 BERT 等复杂的大型语言模型 (LLM) 的过程涉及扩展和完善各种组件。
以下是逐步细分:
法学硕士接受过大量文本数据的培训。 很难解释这些数据有多大。
C4 数据集是许多法学硕士的起点,包含 750 GB 的文本数据。 这是 805,306,368,000 字节——信息量很大。 这些数据可以包括书籍、文章、网站、论坛、评论部分和其他来源。
数据越多样化、越全面,模型的理解和泛化能力就越好。
虽然基本的 Transformer 架构仍然是基础,但 LLM 的参数数量明显增多。 例如,GPT-3 拥有 1750 亿个参数。 在这种情况下,参数是指在训练过程中学习到的神经网络中的权重和偏差。
在深度学习中,模型被训练为通过调整这些参数来进行预测,以减少其预测与实际结果之间的差异。
调整这些参数的过程称为优化,它使用梯度下降等算法。
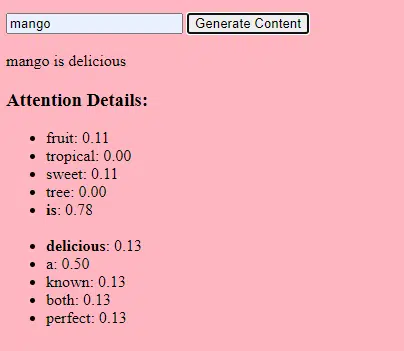
- 权重:这些是神经网络中的值,用于在网络层内转换输入数据。 它们在训练期间进行调整以优化模型的输出。 相邻层中神经元之间的每个连接都有一个相关的权重。
- 偏差:这些也是神经网络中添加到层转换输出中的值。 它们为模型提供了额外的自由度,使其能够更好地拟合训练数据。 层中的每个神经元都有相关的偏差。
这种缩放允许模型存储和处理数据中更复杂的模式和关系。
大量的参数还意味着模型需要大量的计算能力和内存来进行训练和推理。 这就是为什么训练此类模型需要大量资源,并且通常使用 GPU 或 TPU 等专用硬件。
该模型经过训练,可以使用强大的计算资源来预测序列中的下一个单词。 它根据所犯的错误调整其内部参数,不断改进其预测。
像我们讨论的那样的注意力机制对于法学硕士来说至关重要。 它们允许模型在生成输出时专注于输入的不同部分。
通过权衡上下文中不同单词的重要性,注意力机制使模型能够生成连贯且上下文相关的文本。 如此大规模的实施使得法学硕士能够按照他们的方式工作。
转换器如何预测文本?
Transformer 通过多层处理输入标记来预测文本,每个层都配备了注意力机制和前馈网络。
处理后,模型会生成序列中下一个单词的词汇表的概率分布。 通常选择概率最高的单词作为预测。
大型语言模型是如何构建和训练的?
建立法学硕士涉及收集数据、清理数据、训练模型、微调模型以及积极、持续的测试。
该模型最初在庞大的语料库上进行训练,以预测序列中的下一个单词。 这个阶段允许模型学习单词之间的联系,这些单词会拾取语法模式,可以代表世界事实的关系,以及感觉像逻辑推理的联系。 这些连接还使其能够识别训练数据中存在的偏差。
预训练后,模型会在较小的数据集上进行完善,通常由人工审阅者遵循指导方针。
微调是建立法学硕士的关键一步。 它涉及在更具体的数据集或任务上训练预训练模型。 我们以 ChatGPT 为例。
如果您玩过 GPT 模型,您就会知道提示不是“写这个东西”,而是更像
- 提示:从前
- 续:塔顶有一个邪恶的巫师。
- 续:塔顶有一个邪恶的巫师。
- 提示:小鸡为什么要加入乐队?
- 继续:因为它有鸡腿!
从那时起到 ChatGPT 需要大量低薪劳动力。 这些人创建了巨大的语料库来衡量 GPT 响应和预期行为的权重。 这些工作人员创建了大量的提示/延续文本,如下所示:
- 提示:完成这个故事:“从前......”
- 继续: 当然! 从前,在很远很远的地方,有一个小村庄,坐落在两座雄伟的山脉之间。
- 继续: 当然! 从前,在很远很远的地方,有一个小村庄,坐落在两座雄伟的山脉之间。
- 提示:给我讲一个关于鸡的笑话。
- 继续:鸡为什么要加入乐队? 因为它有鸡腿!
由于以下几个原因,这种微调过程至关重要:
- 特异性:虽然预训练使模型对语言有广泛的理解,但微调会缩小其知识和行为的范围,以更多地与特定任务或领域保持一致。 例如,根据医疗数据进行微调的模型将更好地回答医疗问题。
- 控制:微调使开发人员可以更好地控制模型的输出。 开发人员可以使用精选的数据集来指导模型产生所需的响应并避免不良行为。
- 安全:它有助于减少有害或有偏见的输出。 通过在微调过程中使用指南,人工审核人员可以确保模型不会产生不适当的内容。
- 性能:微调可以显着提高模型在特定任务上的性能。 例如,针对客户支持进行了微调的模型将比通用模型更好。
您可以看出 ChatGPT 特别在某些方面进行了微调。
例如,“逻辑推理”是法学硕士往往会遇到的问题。 ChatGPT 的最佳逻辑推理模型 - GPT-4 - 经过严格训练,可以明确识别数字模式。
而不是这样的:
- 提示:2+2 是什么?
- 过程:在儿童数学教科书中经常出现2+2=4。 偶尔会提到“2+2=5”,但在这种情况下,通常会有更多与乔治·奥威尔或《星际迷航》相关的上下文。 如果是在这种情况下,权重将更倾向于 2+2=5。 但该上下文不存在,因此在本例中下一个标记可能是 4。
- 响应:2+2=4
训练的过程是这样的:
- 训练:2+2=4
- 训练:4/2=2
- 训练:4的一半是2
- 训练:2 of 2 是 4
…等等。
这意味着对于那些更“逻辑”的模型,训练过程更加严格,重点是确保模型理解并正确应用逻辑和数学原理。
该模型涉及各种数学问题及其解决方案,确保它可以概括这些原理并将其应用于新的、未见过的问题。
这种微调过程的重要性,尤其是对于逻辑推理而言,怎么强调都不为过。 如果没有它,模型可能会为简单的逻辑或数学问题提供不正确或无意义的答案。
图像模型与语言模型
虽然图像和语言模型可能使用类似的架构(例如 Transformer),但它们处理的数据却有根本的不同:
图像模型
这些模型处理像素,通常以分层方式工作,首先分析小图案(如边缘),然后将它们组合起来识别更大的结构(如形状),依此类推,直到理解整个图像。
语言模型
这些模型处理单词或字符的序列。 他们需要理解上下文、语法和语义,以生成连贯且上下文相关的文本。
著名的生成式人工智能界面如何工作
Dall-E + 中途
Dall-E 是适用于图像生成的 GPT-3 模型的变体。 它是在大量文本图像对数据集上进行训练的。 Midjourney 是另一种基于专有模型的图像生成软件。
- 输入:您提供文字描述,例如“双头火烈鸟”。
- 处理:这些模型将文本编码为一系列数字,然后解码这些向量,找到与像素的关系,以生成图像。 该模型从训练数据中学习了文本描述和视觉表示之间的关系。
- 输出:与给定描述匹配或相关的图像。
手指、图案、问题
为什么这些工具不能始终生成看起来正常的手? 这些工具的工作原理是查看彼此相邻的像素。
将早期或更原始的生成图像与更新的图像进行比较时,您可以看到这是如何工作的:早期的模型看起来非常模糊。 相比之下,最近的型号要清晰得多。
这些模型通过根据已经生成的像素预测下一个像素来生成图像。 这个过程重复数百万次才能产生完整的图像。
手,尤其是手指,非常复杂,有很多细节需要准确捕捉。
每个手指的位置、长度和方向在不同的图像中可能有很大差异。
当根据文本描述生成图像时,模型必须对手的确切姿势和结构做出许多假设,这可能会导致异常。
聊天GPT
ChatGPT 基于 GPT-3.5 架构,这是一种基于 Transformer 的模型,专为自然语言处理任务而设计。
- 输入:模拟对话的提示或一系列消息。
- 处理: ChatGPT 利用来自不同互联网文本的大量知识来生成响应。 它会考虑对话中提供的上下文,并尝试生成最相关和连贯的答复。
- 输出:继续或回答对话的文本响应。
专业
ChatGPT 的优势在于它能够处理各种主题并模拟类人对话,使其成为聊天机器人和虚拟助手的理想选择。
Bard + 搜索生成体验 (SGE)
虽然具体细节可能是专有的,但 Bard 基于 Transformer AI 技术,类似于其他最先进的语言模型。 SGE 基于类似的模型,但融入了 Google 使用的其他 ML 算法。
SGE 可能使用基于变压器的生成模型生成内容,然后从搜索排名页面中模糊提取答案。 (这可能不是真的。只是根据它的工作原理进行的猜测。请不要起诉我!)
- 输入:提示/命令/搜索
- 处理:巴德处理输入并按照其他法学硕士的方式工作。 SGE 使用类似的架构,但添加了一个层,用于搜索其内部知识(从训练数据中获得)以生成合适的响应。 它考虑提示的结构、上下文和生成相关内容的意图。
- 输出:生成的内容可以是故事、答案或任何其他类型的文本。
生成式人工智能的应用(及其争议)
艺术与设计
生成式人工智能现在可以创作艺术品、音乐,甚至产品设计。 这为创造力和创新开辟了新的途径。
争议
人工智能在艺术领域的兴起引发了关于创意领域失业的争论。
此外,人们还担心:
- 劳动违规,尤其是在没有适当归属或补偿的情况下使用人工智能生成的内容时。
- 高管威胁作家用人工智能取代他们是引发作家罢工的问题之一。
自然语言处理(NLP)
AI 模型现在广泛用于聊天机器人、语言翻译和其他 NLP 任务。
除了通用人工智能 (AGI) 的梦想之外,这是法学硕士的最佳用途,因为它们接近“通才”NLP 模型。
争议
许多用户发现聊天机器人缺乏人情味,有时甚至令人讨厌。
此外,虽然人工智能在语言翻译方面取得了重大进展,但它往往缺乏人工翻译带来的细微差别和文化理解,导致翻译令人印象深刻且存在缺陷。
医学和药物发现
人工智能可以快速分析大量医学数据并生成潜在的药物化合物,从而加快药物发现过程。 许多医生已经使用法学硕士来写笔记和与患者沟通
争议
依赖法学硕士用于医疗目的可能会存在问题。 医学需要精确性,人工智能的任何错误或疏忽都可能造成严重后果。
医学界也已经存在偏见,而这些偏见在使用法学硕士的过程中只会变得更加严重。 如下所述,在隐私、功效和道德方面也存在类似的问题。
赌博
许多人工智能爱好者对在游戏中使用人工智能感到兴奋:他们表示人工智能可以生成逼真的游戏环境、角色甚至整个游戏情节,增强游戏体验。 通过使用这些工具可以增强 NPC 对话。
争议
关于游戏设计中的意向性存在争议。
虽然人工智能可以生成大量内容,但一些人认为它缺乏人类设计师带来的深思熟虑的设计和叙事凝聚力。
《看门狗 2》有程序化的 NPC,这对增加整个游戏的叙事凝聚力几乎没有帮助。
市场营销和广告
人工智能可以分析消费者行为并生成个性化广告和促销内容,使营销活动更加有效。
法学硕士拥有其他人写作的背景,这使得它们对于生成用户故事或更细致的程序化想法很有用。 法学硕士可以推荐某人可能想要的配件,而不是向刚刚购买电视的人推荐电视。
争议
人工智能在营销中的使用引发了隐私问题。 关于使用人工智能影响消费者行为的道德影响也存在争议。
Dig deeper: How to scale the use of large language models in marketing
Continuing issues with LLMS
Contextual understanding and comprehension of human speech
- Limitation: AI models, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI models, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they've seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model's last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI models can store vast amounts of information, they often lack a "common sense" understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI models learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI models generate content based on patterns they've seen. While they can combine these patterns in novel ways, they don't "invent" like humans do. Their "creativity" is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration : Using AI models in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI models might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-date expectations for code, using functions like “document.write” that are no longer considered best practice.
Hot takes from an MLOps engineer and technical SEO
This section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn't real (for generative text interfaces)
Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these models have become the new “gold rush," people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there's no guarantee they'll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don't know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they're essentially regurgitating and recombining what they've seen before. They don't "invent" in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it's hard for LLMs to deal with it.

For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks.
LLMs don't know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can't verify facts or discern true and false information.
If they've been exposed to misinformation or biased data during training, or they don't have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it's a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there's a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that's challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
本文表达的观点是客座作者的观点,并不一定是搜索引擎土地的观点。 此处列出了工作人员作者。