
在我们结束 2016 年的同时,让我们谈谈结束 CRO 测试
已发表: 2021-10-23当我们接近又一年结束时,而“这个测试什么时候可以结束?”的问题。 仍然每周至少出现一次在我的谈话中,我觉得是时候坐下来写下我的测试结论过程以及影响这个决定的所有变量。
今天,我会用两个提示让你暖和起来,当你接近结论的决定时要记住,然后我会进入我在接近这个决定时看到的四个变量。 吹掉你很久以前埋藏的那本统计教科书的灰尘,让我们开始吧。
前言提示#1:确保您的数据美观且健壮
在设置测试之前,您应该已经知道自己的目标是什么。 请注意我在那里所说的“目标”。 是的,我们都知道您应该进行集中转换; 您正在推动用户进行的一件大事。 但是,我们可以跟踪与任何站点的许多其他交互,以观察我们的更改是否也影响了这些交互。 有关几个示例,请参见下图。

在分析任何测试数据之前,请仔细检查您的数据是否都在平等的竞争环境中。 确保您为每个目标提取了同一确切日期范围内的数据,以便您可以适当地比较数据点,而不会歪曲一串数据。 当您在这里时,还要确保您的所有目标数据看起来都“正常”,并且您不会怀疑任何从未看到任何动作的错误目标或无效目标。
前言提示#2:永远不要对单一变量下结论
做出结论决定不能依赖于任何一个变量。 考虑这四个变量中的每一个,如果大多数变量相互补充,那么您可以自信地得出结论。
如果所有变量都相互矛盾,您可能会看到多种不同的情况。 但在那个时候,如果你得出结论,你可能会做出一个不合逻辑的决定,并带来代价高昂的后果。
这些变量中的每一个都受至少一个其他变量的影响或影响。 因此,互补数据支持自身,而矛盾数据迫使您将点与谎言联系起来。 不要这样做!
变量#1:样本量
样本量很重要。 样本量使我们能够根据我们的人口(总用户数)和可接受的误差范围(100 个目标的统计显着性)自信地概括行为。
这实际上是关于比例的,但如果您一直在查看流量波动很小的同一个站点,那么您可以设置一个底线目标来工作。
一个测试的每个部分有 100 个用户是一个合理的最低限度。 即使在低流量的网站上,也很难根据少数用户的数据来概括行为。 因此,越多越好。 更大的样本量还有助于消除我们可以从异常值中看到的任何偏差。
然而,在一个相当大的电子商务网站上,每天至少有 1000 个用户,我不可能考虑 100 个合适的用户样本量。 这完全取决于比例以及您网站的典型用户量是多少。
此变量包括转化次数以及您将考虑的目标的用户。 即使您有一个低转化率的网站,如果您将 0 次转化与 2 次转化进行比较,2 次转化的变体绝对会获胜,因为它是技术上唯一的变体。
确保您的转化次数至少达到两位数; 如果这是您的最低要求(两位数),请确保您对其他三个变量有强烈的赞美行为。
或者,如果您对统计设置中的样本量没有太多经验,则可以使用这个方便的样本量计算器来确定适合您的样本量。
变量 #2:测试持续时间
理想情况下,我会在 2-6 周的任何地方运行测试。
两周是最低限度,因为您消除了任何变量具有“好”或“坏”周的可能性,并且要么拖着愉快的交通要么赶走低动机的交通。 六周是一个可爱的最大值,因为它是一个足够宽的时间网,可以捕捉您可以看到的任何波动。
但是,请注意,永远运行测试也可能对您的测试有害。 测试结果中的一个重要因素是用户对新刺激的反应。 因此,当我们第一次启动测试时,我们往往会看到巨大的飞跃,其中一个变体正在大幅失败,而其他变体则在其连续获胜的道路上滑行。 随着时间的推移,变化之间的这种巨大差距趋于正常化和缩小,因为“新”已经消失,而返回的用户不像以前那样受到新变化的影响。 因此,测试运行的时间越长,改动就越不新颖,对那些返回用户的行为的影响也就越小。
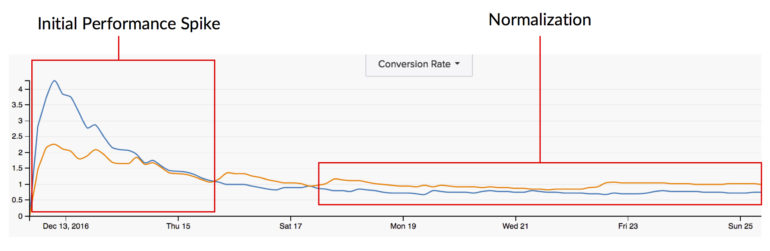
变量 #3:统计显着性
虽然统计显着性对于在您的结论中声明“可信度”至关重要,但它也可能非常具有误导性。
统计显着性确定两个比率的变化是由于正态方差还是由于外部因素。 因此,理论上,当我们达到很强的统计显着性时,我们知道我们的更改对用户产生了影响。
理想情况下,您希望统计显着性尽可能接近 100%。 越接近 100%,误差幅度就越小。 这意味着可以在更一致的基础上重现您的结果。 如果您实施获胜变体,您的统计显着性越高,保持该转化率提升的机会就越大。 95% 是一个很好的高目标。 90% 是一个定居的好地方。 任何低于 90% 的值,您实际上都可能“自信地”得出结论。
这里的威胁是样本量真的很重要。 您可以在几天内达到 98% 的统计显着性,并且实际上只查看总共 16 个用户,这显然不是一个值得信赖的样本量。
统计显着性还可以捕捉到我之前在首次启动测试时提到的巨大性能峰值。 测试具有所有的触发能力,我们也知道随着时间的推移数据会标准化。 因此,过早地衡量统计显着性可能会让我们完全错误地了解这种变化最有可能如何在更长期的基础上影响我们的用户。
此外,并非每个测试都会获得统计显着性。 您所做的一些更改可能不会对用户行为产生足够大的影响,以至于被视为超出正常差异。 没关系! 这只是意味着您需要测试更大的更改以更多地吸引用户的注意力。
变量 #4:数据一致性
这个适用于所有那些触发器测试。 有一些测试拒绝正常化并拒绝为您提供明显的赢家。 他们会花每一天的时间向您展示不同的获胜者,他们会绝对让您发疯。
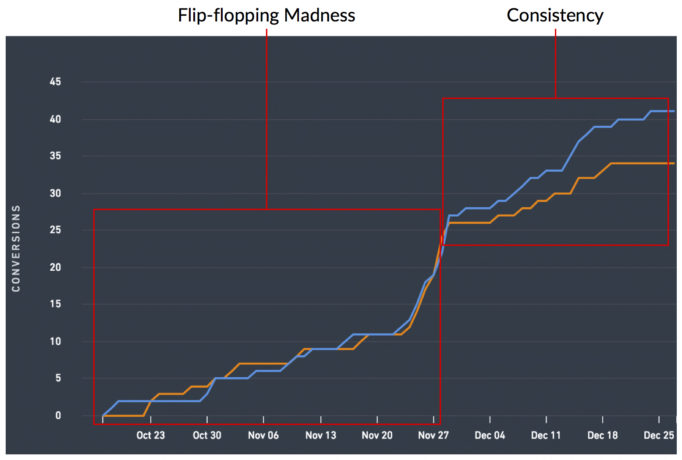
但它们确实存在,这正是寻找一致的数据方向性如此重要的原因。 您宣布获胜者的变体是否一直是获胜者? 如果没有,为什么它不总是赢家? 如果你不能自信地回答“为什么?” 那么,如果您以赢家的身份实施变体,那么实施赢家可能会损害您的底线。
我还测量了控件的转化率和变体的转化率(又名“提升”或“下降”)之间的差异。 我也希望这个指标保持一致,以便我可以确保测试不在初始峰值阶段。
定期计算统计显着性以查看该指标的一致性也很有用。
最后的想法
结束任何类型的测试都不是开玩笑,而且充满压力。 如果您做出错误的决定并实施了您“认为”是赢家而数据表明情况并非如此,那么您的底线和您的用户都会受到影响。
从每个可行的角度得出一个结论,这样你就可以确保你有一个由数据驱动的真正自信的结论!