
Wikipedia Web Scraping 2023:提取数据进行分析
已发表: 2023-03-29在线抓取使您能够从网站收集开放数据,用于价格比较、市场研究、广告验证等目的。
通常会提取大量必要的公共数据,但当您遇到封锁时,提取可能会变得具有挑战性。
限制可能是速率阻塞或 IP 阻塞(请求的 IP 地址受到限制,因为它来自禁止区域、禁止类型的 IP 等)。 (该 IP 地址被阻止,因为它发出了多次请求)。

现在,如果您想抓取一些有用的知识和信息,那么我相信您一定考虑过抓取维基百科,这是包含大量信息的知识百科全书。
让我们了解一些关于网络抓取维基百科的事情。
目录
维基百科网页抓取
Web 抓取是一种从 Internet 收集数据的自动化方法。 本文提供了有关网络抓取的深入信息、与网络抓取的比较以及支持网络抓取的论据。
目标是使用各种网络抓取方法从维基百科主页收集数据,然后对其进行解析。
您将更加熟悉各种网络抓取方法、Python 网络抓取库以及数据提取和处理过程。
Web 抓取和 Python
Web 抓取本质上是使用以编程语言创建的软件从大量网站的大量数据中提取结构化数据并将其保存在我们设备本地的过程,最好是 Excel 工作表、JSON 或电子表格。
这有助于程序员为小型和大型项目创建合乎逻辑、易于理解的代码。
Python 主要被认为是网络抓取的最佳语言。 它可以有效地处理大多数与网络爬虫相关的任务,更像是一个多面手。
如何从维基百科抓取数据?
可以通过多种方式从网页中提取数据。
例如,您可以使用 Python 等计算机语言自己实现它。 但是,除非您精通技术,否则您需要大量学习才能在此过程中做很多事情。
这也很耗时,可能需要与手动梳理维基百科页面一样长的时间。 此外,还可以在线访问免费的网络抓取工具。 然而,他们经常缺乏可靠性,而且他们的供应商可能有不正当的意图。
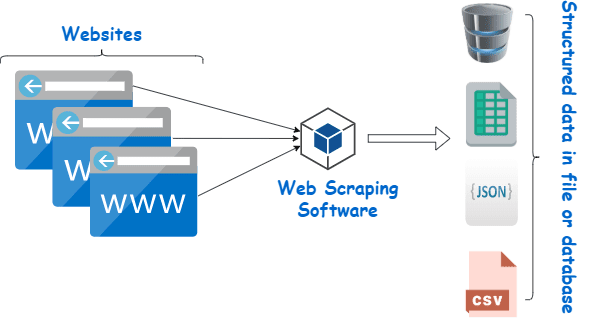
从信誉良好的供应商那里投资一个像样的网络抓取工具是收集 Wiki 数据的最佳方法。
下一步通常很简单,因为提供商会向您提供有关如何安装和使用刮板的说明。
代理是一种工具,您可以将其与 wiki 抓取工具结合使用,以更有效地抓取数据。 基于 Python 的框架,如 Scrapy、Scraping Robot 和 Beautiful Soup 只是使用这种语言进行抓取是多么容易的几个例子。
从维基百科抓取数据的代理
您需要速度极快、使用安全且保证不会在您需要时出现故障的代理,以便有效地抓取数据。 Rayobyte 以合理的价格提供此类代理。
我们努力提供各种代理,因为我们知道每个用户都有不同的偏好和用例。
用于网络抓取维基百科的旋转代理
代理实例是定期轮换其 IP 地址的实例。 此外,为了防止中断,IP 地址会在发生禁令时立即更改。 这使得这个特定的代理成为网站抓取的绝佳选择。
相比之下,静态代理只有一个 IP 地址。 如果您的 ISP 没有启用自动替换,您将遇到一堵砖墙,如果您只能访问一个 IP 地址并被阻止。 因此,静态代理不是网络抓取的最佳选择。
用于网络抓取 Wiki 数据的住宅代理
住宅代理是互联网服务提供商 (ISP) 分配并与特定家庭相关联的代理 IP 地址。 因为它们来自真实的人,所以获取它们非常具有挑战性。 因此,它们稀缺且相对昂贵。


当您使用住宅代理来抓取数据时,您似乎是一个日常用户,因为它们链接到真实个人的地址。
因此,使用住宅代理可以显着降低被发现和阻止的机会。 因此,它们是数据抓取的优秀候选者。
用于收集 wiki 数据的旋转住宅代理
结合了我们刚才谈到的两种类型的旋转住宅代理是网络抓取维基百科的最佳代理。
您可以使用频繁轮换的代理访问大量家庭 IP。
这一点很重要,因为尽管难以识别住宅代理,但它们生成的请求量最终会引起被抓取网站的注意。
轮换确保即使 IP 地址不可避免地被列入黑名单,项目也可以继续进行。
因此,无论您决定使用多个数据中心代理还是更愿意投资一些住宅代理,我们都能满足您的需求。
通过以 1GBS 速度运行的代理、无限带宽和全天候客户帮助,您将享受到最好的网络抓取体验。
你也可以阅读
- 最佳网页抓取技术:实用指南
- Octoparse 评论 真的是很好的网页抓取工具吗?
- 最好的网页抓取工具
- 什么是网页抓取? - 它是如何使用的? 它如何使您的业务受益
为什么要抓取维基百科?
维基百科是目前在线世界中最受信任和信息最丰富的服务之一。 在这个平台上,几乎所有你能想到的话题都有答案和信息。
所以,维基百科自然是一个很好的数据来源。 让我们讨论一下您应该抓取维基百科的主要原因。
用于学术研究的网页抓取
数据收集是研究中最痛苦的活动之一。 正如已经讨论过的,网络抓取工具使这个过程更快更容易,同时也为您节省了大量的时间和精力。
使用网络抓取工具,您可以快速扫描大量 wiki 页面并以有组织的方式收集您需要的所有数据。
暂时假设您的目标是确定抑郁症和阳光照射是否因国家/地区而异。
您可以使用维基爬虫来查找信息,例如不同国家的抑郁症患病率和他们的晴天时间,而不是浏览大量的维基百科条目。
声誉管理
制作维基百科页面已成为现代许多不同类型企业必须做的营销策略,因为维基百科帖子经常出现在谷歌的首页。
但是,在维基百科上拥有一个页面不应该是您营销工作的终点。 维基百科是一个众包平台,所以故意破坏是经常发生的事情。
因此,有人可能会向您公司的页面添加不利信息并损害您的声誉。 或者,他们可能会在相关的 wiki 文章中诽谤您的企业。
因此,您必须密切关注您的 Wiki 页面以及提及您的业务的其他页面。 您可以借助 wiki 抓取工具轻松完成此操作。
您可以定期搜索维基百科页面以查找有关您的业务的参考资料,并指出那里的任何破坏行为。
提升搜索引擎优化
您可以利用维基百科来增加您网站的访问量。
通过使用 Wiki 数据抓取器找到与您的业务和目标受众相关的页面,创建您想要更改的文章列表。
首先阅读文章并进行一些有用的调整,以获得作为网站贡献者的信誉。
一旦建立了一定的可信度,您就可以在链接断开或需要引用的地方添加到您网站的链接。
快速链接
- 最佳法国代理人
- 顶级最佳 Spotify 代理
- 最佳耐克代理
用于网络抓取的 Python 库
如前所述,Python 是世界上最流行、最负盛名的编程语言和网络抓取工具。 现在让我们看看现在可用的 Python 网络抓取库。
用于 Web 抓取的请求(HTTP for Humans)库
它用于发送不同的 HTTP 请求,例如 GET 和 POST。 在所有库中,它是最基础的,也是最关键的。
用于网页抓取的 lxml 库
lxml 包提供了对来自网站的 HTML 和 XML 文本的非常快速和高性能的解析。 如果你打算抓取庞大的数据库,这是一个选择。
用于网页抓取的漂亮汤库
它的工作是构建用于内容解析的解析树。 对于初学者来说是一个很好的起点,并且对用户非常友好。
用于网页抓取的 Selenium 库
这个库解决了上面提到的所有库都有的问题,即从动态填充的网页中抓取内容。
它最初是为 Web 应用程序的自动化测试而设计的。 因此,它速度较慢且不适合工业级任务。
用于网页抓取的 Scrapy
一个完整的使用异步使用的网络抓取框架是所有包的BOSS。 这提高了效率并使其非常快。
结论
所以这几乎是您需要了解的关于维基百科网页抓取的最重要的方面。 请继续关注我们,以获取更多有关 Web Scraping 的信息性帖子以及更多内容!
快速链接
- 旅行费用汇总的最佳代理
- 最佳法国代理人
- 最佳 Tripadvisor 代理
- 最佳 Etsy 代理
- IPRoyal 优惠券代码
- 最佳 TikTok 代理