
为期一年的 SEO 案例研究:关于 Googlebot 您需要了解的内容
已发表: 2019-08-30编者注: JetOctopus 爬虫 Serge Bezborodov 的首席执行官就如何使您的网站对 Googlebot 具有吸引力提供了专家建议。 本文中的数据基于长达一年的研究和 3 亿个已抓取的页面。
几年前,我试图增加我们拥有 500 万页的工作聚合网站的访问量。 我决定使用 SEO 代理服务,预计流量会飙升。 但是我错了。 我没有进行全面审核,而是阅读了塔罗牌。 这就是为什么我回到原点并创建了一个网络爬虫来进行全面的页面搜索引擎优化分析。
一年多以来,我一直在监视 Googlebot,现在我准备分享有关其行为的见解。 我希望我的观察至少可以阐明网络爬虫的工作原理,最多可以帮助您有效地进行页面优化。 我收集了对新网站或拥有数千页的网站有用的最有意义的数据。
您的页面是否出现在 SERP 中?
要确定哪些页面在搜索结果中,您应该检查整个网站的索引能力。 然而,在一个超过 1000 万页的网站上分析每个 URL 的成本很高,大约相当于一辆新车的价格。
让我们改用日志文件分析。 我们以下列方式与网站合作:我们像搜索机器人一样抓取网页,然后分析半年收集的日志文件。 日志显示机器人是否访问网站、抓取了哪些页面以及机器人访问页面的时间和频率。
抓取是搜索机器人访问您的网站、处理网页上的所有链接并将这些链接放入索引中的过程。 在抓取过程中,机器人会将刚刚处理的 URL 与索引中已有的 URL 进行比较。 因此,机器人会刷新数据并从搜索引擎数据库中添加/删除一些 URL,为用户提供最相关和最新的结果。
现在,我们可以很容易地得出以下结论:
- 除非搜索机器人位于 URL 上,否则该 URL 可能不会出现在索引中。
- 如果 Googlebot 一天多次访问该网址,则该网址具有高优先级,因此需要您特别注意。
总而言之,这些信息揭示了是什么阻碍了您网站的有机增长和发展。 现在,您的团队可以明智地优化网站,而不是盲目操作。
我们主要与大型网站合作,因为如果您的网站很小,Googlebot 迟早会抓取您的所有网页。
相反,当爬虫访问网站管理员看不到的页面时,拥有 100,000 多个页面的网站会面临问题。 宝贵的抓取预算可能会浪费在这些无用甚至有害的页面上。 同时,由于网站结构混乱,机器人可能永远找不到您的盈利页面。
抓取预算是 Googlebot 准备在您的网站上花费的有限资源。 它的创建是为了确定分析内容和分析时间的优先顺序。 抓取预算的大小取决于很多因素,例如您网站的大小、网站结构、用户查询量和频率等。
请注意,搜索机器人对完全抓取您的网站不感兴趣。
搜索引擎机器人的主要目的是以最小的资源损失为用户提供最相关的答案。Bot 会根据主要目的抓取尽可能多的数据。 因此,帮助机器人挑选最有用和最有利可图的内容是您的任务。
监视 Googlebot
在过去的一年里,我们在大型网站上扫描了超过 3 亿个 URL 和 60 亿条日志行。 根据这些数据,我们追踪了 Googlebot 的行为以帮助回答以下问题:
- 哪些类型的页面会被忽略?
- 哪些页面被频繁访问?
- bot需要注意什么?
- 什么没有价值?
以下是我们的分析和发现,而不是对 Google 网站管理员指南的重写。 事实上,我们不会给出任何未经证实和不合理的建议。 为方便起见,每个点都基于事实统计数据和图表。
让我们切入正题,找出答案:
- 对 Googlebot 真正重要的是什么?
- 什么决定了机器人是否访问该页面?
我们确定了以下因素:
与索引的距离
DFI 代表与索引的距离,是您的 URL 在点击中与主/根/索引 URL 的距离。 这是影响 Googlebot 访问频率的最重要标准之一。 这是一个教育视频,可以了解有关 DFI 的更多信息。
请注意,DFI 不是 URL 目录中斜杠的数量,例如:
site.com/shop/iphone/iphoneX.html – DFI– 3__ _
因此,DFI 是由主页上的 CLICKS 准确计算的
https://site.com/shop/iphone/iphoneX.html
https://site.com iPhone 目录 → https://site.com/shop/iphone iPhone X → https://site.com/shop/iphone/iphoneX.html – DFI – 2
您可以在下面看到 Googlebot 对带有 DFI 的 URL 的兴趣在上个月和过去六个月中是如何逐渐减少的。
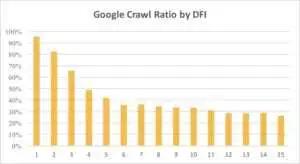
如您所见,如果 DFI 为 5 t0 6,则 Googlebot 仅抓取了一半的网页。 如果 DFI 较大,则处理页面的百分比会降低。 表中指标统一为1800万页。 请注意,数据可能因特定网站的利基市场而异。
该怎么办?
很明显,在这种情况下最好的策略是避免长度超过 5 的 DFI,构建易于导航的网站结构,特别注意链接等。
事实上,这些措施对于 100,ooo-plus 页面的网站来说真的很耗时。 通常大型网站都有很长的重新设计和迁移历史。 这就是为什么网站管理员不应该只删除 DFI 为 10、12 甚至 30 的页面。此外,从经常访问的页面插入一个链接也不能解决问题。
应对长 DFI 的最佳方法是检查和估计这些 URL 是否相关、是否有利可图以及它们在 SERP 中的位置。
DFI 较长但在 SERP 中排名较高的页面具有很高的潜力。 为了增加高质量页面的流量,网站管理员应该从下一页插入链接。 一到两个链接不足以取得切实进展。
从下图中可以看出,如果页面上的链接超过 10 个,Googlebot 会更频繁地访问 URL。
链接
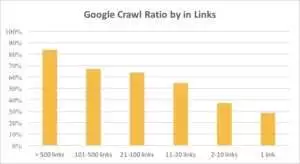
事实上,网站越大,网页上的链接数量就越多。 该数据实际上来自 100 万多个页面的网站。

如果您发现盈利页面上的链接少于 10 个,请不要惊慌。 首先,检查这些页面是否优质且有利可图。 当你这样做时,不要急于在高质量的页面上插入链接,迭代要短,在每个步骤后分析日志。
内容大小
内容是 SEO 分析中最受欢迎的方面之一。 当然,您网站上的相关内容越多,您的抓取率就越高。 您可以在下面看到 Googlebot 对少于 500 字的页面的兴趣是如何急剧下降的。
该怎么办?
根据我的经验,所有少于 500 字的页面中有将近一半是垃圾页面。 我们看到一个案例,一个网站有 70,000 个页面,只列出了衣服的尺寸,所以只有部分页面被索引。
因此,首先检查您是否真的需要这些页面。 如果这些网址很重要,你应该在上面添加一些相关的内容。 如果您没有什么要添加的,请放松并保持这些 URL 不变。 有时什么都不做比发布无用的内容更好。
其他因素
以下因素会显着影响抓取率:
加载时间
网页速度对于抓取和排名至关重要。 Bot 就像人一样:它讨厌等待网页加载的时间过长。 如果您的网站上有超过 100 万个页面,搜索机器人可能会在 1 秒的加载时间内下载 5 个页面,而不是等待 5 秒内加载的一个页面。
该怎么办?
事实上,这是一项技术任务,并没有“一刀切”的解决方案,例如使用更大的服务器。 主要思想是找到问题的瓶颈。 您应该了解为什么网页加载缓慢。 只有揭露原因后,你才能采取行动。
独特内容和模板内容的比例
独特数据和模板化数据之间的平衡很重要。 例如,您有一个包含各种宠物名称的网站。 您真的可以收集到多少关于该主题的相关且独特的内容?
Luna 是最受欢迎的“名人”狗名,其次是 Stella、Jack、Milo 和 Leo。
搜索机器人不喜欢将资源花在这些类型的页面上。
该怎么办?
保持平衡。 用户和机器人不喜欢访问具有复杂模板、一堆外向链接和很少内容的页面。
孤立页面
孤立页面是不在网站结构中的 URL,您不知道这些页面,但这些孤立页面可能会被机器人抓取。 为了说清楚,看下图中的欧拉圆:

可以看到young网站的正常情况,结构已经有一段时间没有改动了。 您和爬虫可以分析 900,000 个页面。 大约 500,000 个页面由爬虫处理但不为 Google 所知。 如果您使这 500,000 个 URL 可索引,您的流量肯定会增加。
注意:即使是一个年轻的网站也包含一些不在网站结构中但经常被机器人访问的页面(图中蓝色部分)。
这些页面可能包含垃圾内容,例如无用的自动生成的访问者查询。
但是大网站很少这么准确。 有历史的网站通常是这样的:

另一个问题是:Google 比您更了解您的网站。 可能有被删除的页面、基于 JavaScript 或 Ajax 的页面、损坏的重定向等等。 曾经我们遇到这样一种情况,由于程序员的失误,站点地图中出现了 500,000 个损坏链接的列表。 三天后,错误被发现并修复,但 Googlebot 已经访问这些损坏的链接半年了!
通常,您的抓取预算经常浪费在这些孤立页面上。
该怎么办?
有两种方法可以解决这个潜在的问题:第一种是规范的:清理混乱。 组织网站结构,正确插入内部链接,通过添加来自索引页面的链接将孤立页面添加到 DFI,为程序员设置任务并等待下一次 Googlebot 访问。
第二种方法是提示:收集孤立页面列表并检查它们是否相关。 如果答案是“是”,则使用这些 URL 创建站点地图并将其发送给 Google。 这种方式更简单快捷,但只有一半的孤立页面会在索引中。
下一个级别
搜索引擎算法已经改进了二十年,认为搜索爬行可以用几张图来解释是天真的想法。
我们为每个页面收集了 200 多个不同的参数,我们预计到今年年底这个数字将会增加。 想象一下您的网站是一个包含 100 万行(页面)的表格,并将这些行乘以 200 列,简单的示例不足以进行全面的技术审核。 你同意?
我们决定深入研究并使用机器学习来找出在每种情况下影响 Googlebots 抓取的因素。

一方面,网站链接至关重要,而内容是另一个关键因素。
这项任务的主要目的是从复杂而庞大的数据中获得简单的答案:您网站上的什么对索引化影响最大? 哪些 URL 集群与相同的因素相关联? 这样您就可以全面地与他们合作。
在我们的 HotWork 聚合器网站上下载和分析日志之前,关于机器人可见但我们不可见的孤立页面的故事对我来说似乎是不现实的。 但真实情况更让我吃惊:Crawl 显示了 500 个带有 301 重定向的页面,但是 Yandex 发现了 700,000 个具有相同状态代码的页面。
通常,技术极客不喜欢存储日志文件,因为这些数据会使磁盘“超载”。 但客观地说,在大多数月访问量高达 1000 万的网站上,日志存储的基本设置是完美的。
说到日志量,最好的解决方案是创建一个存档并在 Amazon S3-Glacier 上下载它(您只需 1 美元就可以存储 250 GB 的数据)。 对于系统管理员来说,这个任务就像泡一杯咖啡一样简单。 将来,历史日志将有助于揭示技术错误并估计 Google 更新对您网站的影响。