
使用互聯網檔案網站的 5 種方法?
已發表: 2021-10-25Internet Archive 是一個非營利性數字圖書館,擁有最大的在線資產收藏。 它始於 1996 年,聲稱使用其 WaybackMachine 存檔了超過 6000 億個網頁。 您可以通過不同方式將這些存檔頁面用於您的項目。 在本文中,我們將解釋如何使用 Internet Archive 內容並提交您的網站進行存檔。
互聯網檔案內容
許多人認為 arhive.org 只託管存檔網頁。 但是,除了網頁之外,您還可以從他們的網站上找到書籍、音頻、視頻、軟件和圖像。 以下是您可以使用 Internet Archive 網站的一些方法。
1. 查找已刪除和不可用的網頁內容
Internet Archive 最簡單和最有用的方法是查找當前網絡上不可用的內容。 讓我們用一個例子來解釋這一點。 一些網站建設者(如 Weebly)不提供將您的文章保存在“垃圾箱”中的選項。 如果您錯誤地刪除了一個頁面,它將從您的網站上永久消失。 問題是他們的博客頁面是索引頁面,刪除該單個博客頁面將永久刪除您多年來創建的所有博客文章。 我們的一位讀者向我們發送電子郵件,詢問如何檢索 100 多篇 Weebly 博客文章,因為他錯誤地刪除了博客索引頁。
查看 Internet Archive 是檢索已刪除內容的最簡單選項。 儘管 Internet Archive 不會提供快速解決方案,但至少您可以從存檔頁面查看和檢索您的內容。
- 轉到 Internet Archive 網站的 WaybackMachine 部分。
- 輸入要查看歷史記錄的站點或頁面 URL,然後單擊“瀏覽歷史記錄”按鈕。

- 您將看到一個日曆,其中突出顯示了日期,表明這些日期有可用的檔案。
- 單擊日期並選擇要查看的快照。
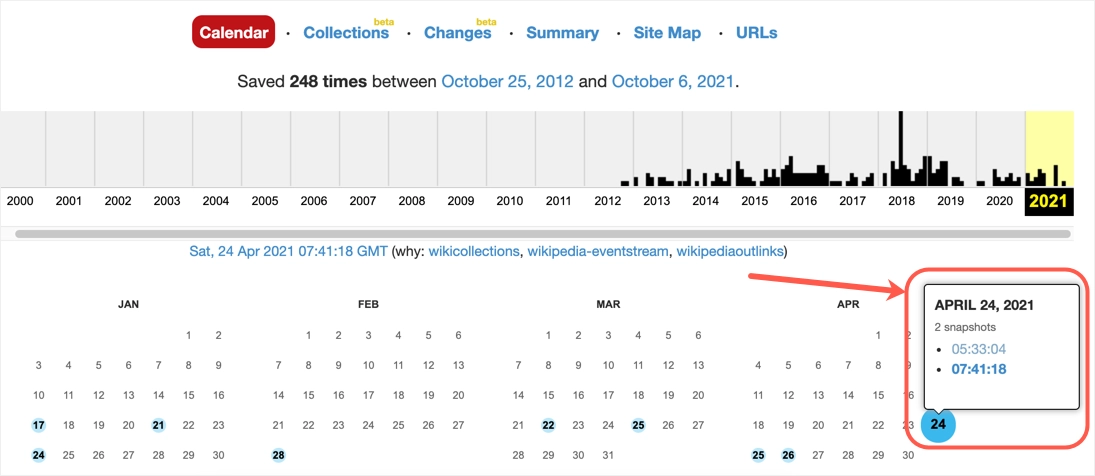
- 您可以查看所選日期的網頁內容。 您可以更改頂部欄上的日期以將快照更改為不同的日期。
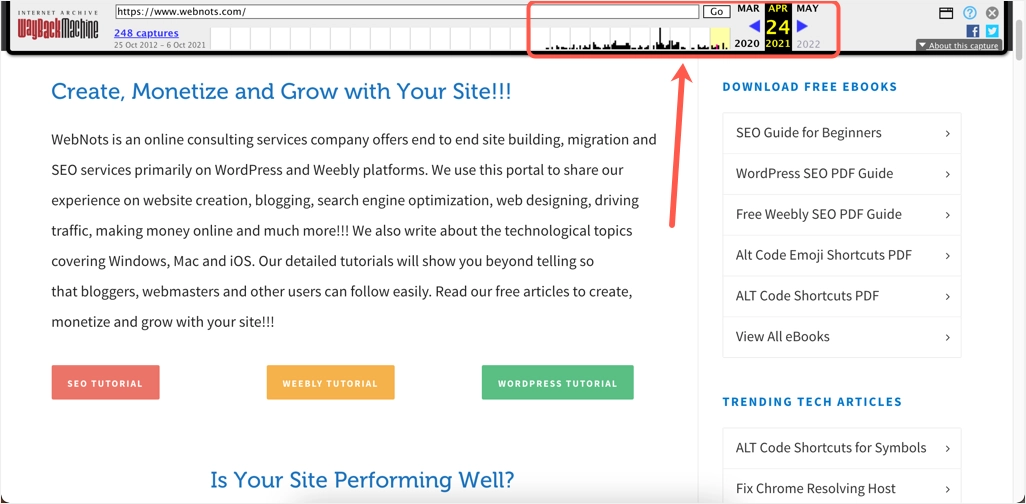
- 現在,如果您在實時站點上錯誤地刪除或修改了內容,您可以復制和使用該內容。
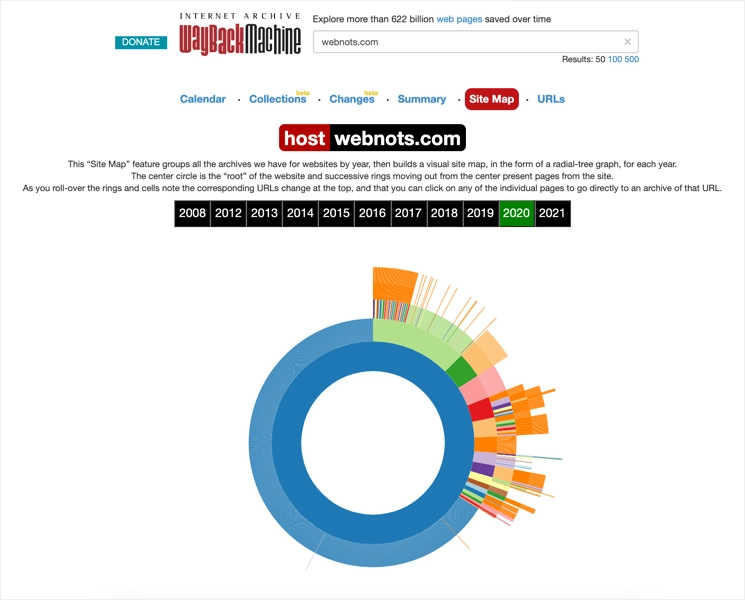
除了作為日曆查看之外,您還可以將視圖更改為集合、更改、摘要、站點地圖和 URL。 您會驚訝地看到 Internet Archive 中關於您的站點的可用信息數量。 下面是“站點地圖”視圖的外觀,您可以將鼠標懸停在圖表上以選擇 URL 來查看快照。
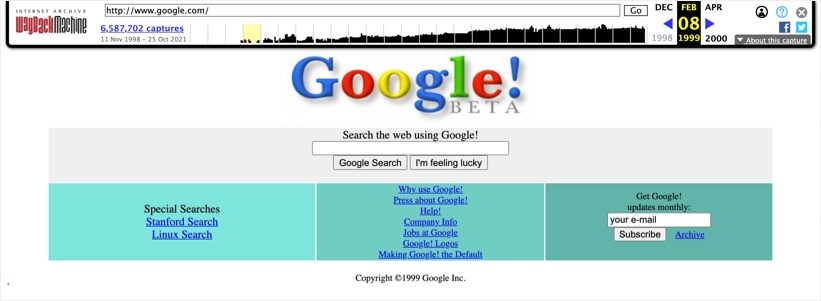
當您想了解某個特定站點十年前的樣子時,快照對於文檔也很有用。 例如,以下是 1999 年 Google 網站的外觀。
SEO 優惠:使用 Semrush Pro 14 天特別免費試用優化您的網站。
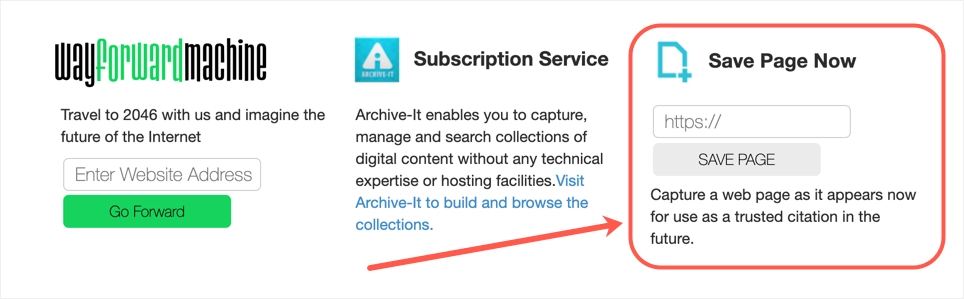
2. 提交您的網站快照
也可以將網頁內容保存到 Internet Archive。 您可以提交您自己的網站或您喜歡的任何網頁,但在 archive.org 網站中找不到。
- 轉到 Internet Archive 的 web 部分並向下滾動一點。
- 您將看到“立即保存頁面”選項,如下所示。
- 輸入您的 URL 並單擊“保存頁面”按鈕以捕獲頁面的當前快照。
3. 從集合中查看和收聽
如前所述,網頁只是 Internet Archive 網站的一部分。 您可以在線閱讀或收聽大量電子書、音頻和視頻。
- 當您在 Internet Archive 主頁中時,向下滾動並單擊您最喜歡的收藏。
- 例如,您可以找到“歐洲圖書館”並單擊它。

- 您會找到超過 700K 的數字圖書,然後點擊您想閱讀或聆聽的圖書。
- 它將打開一個電子書閱讀器界面; 您可以簡單地放大或更改為一頁視圖以放大書籍並在線閱讀。 也可以為您閱讀本書並在您完成另一項任務時聆聽。
您甚至可以找到 1900 年代出版的書籍,而這些書籍在實體圖書館中很難找到。

4. 檢查互聯網檔案項目
Internet Archive 有許多有用的項目,您可以根據需要使用它們。
- 組織可以將檔案用作 Internet Archive 的 arhive-it.org 項目部分的訂閱服務。
- 從他們的 openlibrary.org 項目借書。
- 獲取您喜歡的軟件的存檔。
您可以查看他們的項目頁面以獲取有關當前項目的更多詳細信息。
5. 從檔案重建您的網站
運行一個網站需要很大的耐心,許多博主在中間刪除了他們的網站,並因為沒有獲得足夠的流量而沮喪地退出博客。 然而,一段時間後,他們後悔並沒有辦法繼續他們的博客之旅。 如果您是刪除站點的人,請不要擔心!!! 有許多第三方服務提供商可以幫助您從 Internet Archive 內容重建您的站點。 您必須為內容檢索和恢復所需格式支付象徵性費用。 例如,您只需 45 美元即可重建您的原始 WordPress 博客,然後從您離開的地方繼續。

查看此 Internet Archive 頁面中的重建服務提供商列表。
阻止 WaybackMachine Crawler
最後,您可能不希望您的網站內容成為 Internet 檔案館的一部分,這是有充分理由的。 可能您想保持站點的個人信息,或者發現一些已從站點中刪除的敏感信息已存檔。 簡單的選擇是使用 robots.txt 文件並阻止 Internet Archive 的爬蟲訪問。 在您的 robots.txt 文件中添加以下行以阻止整個站點存檔。
User-agent: ia_archiver Disallow: /另一種選擇是通過電子郵件與他們聯繫並請求排除。
使用 Internet Archive 的常見問題
是的,如果您的頁面之前已存檔。
是的,如果可用,您可以找到稱為快照的歷史版本。
是的,您只需轉到 WaybackMachine 部分並保存您的頁面內容即可。
不,用於查看快照。 但是,您需要一個來上傳您的資產。
使用 robots.txt 阻止網站或頁面,或通過電子郵件聯繫他們以排除網站。
壞主意,即使是簡單的抄襲檢查器也會比較 Internet Archive 中可用的內容。 在花費大量時間後,您很可能會收到侵犯版權 (DMCA) 的通知,或者因竊取他人的內容而受到搜索引擎的懲罰。 如果是自己的站點,可以自己重建或者使用第三方服務。 出於 SEO 的目的,如果您仍然持有舊域名,則可能需要設置重定向。
大量電子書、音頻、視頻、軟件等。
存檔頁面只是像屏幕截圖一樣的快照。 您無法登錄、訪問數據庫、查看受密碼保護的內容。