
SEO 中的人工智慧:如何應對法律挑戰並確保合規
已發表: 2023-09-26人工智慧 (AI) 有望成為品牌提升線上形象的重要工具。
然而,將人工智慧融入行銷策略不可避免地會產生法律考慮和新法規,各機構必須謹慎應對。
在本文中,您將發現:
- 企業、搜尋引擎優化和媒體機構如何最大限度地降低實施人工智慧增強策略的法律風險。
- 減少人工智慧偏見的有用工具和審查人工智慧生成內容品質的便利流程。
- 各機構如何應對主要的人工智慧實施挑戰,以確保客戶的效率和合規性。
法律合規考慮因素
智慧財產權和版權
在搜尋引擎優化和媒體中使用人工智慧時,一個重要的法律問題是遵守智慧財產權和版權法。
人工智慧系統經常抓取和分析大量數據,包括受版權保護的材料。
已經有多起針對 OpenAI 的版權和隱私侵犯訴訟。
該公司面臨訴訟,指控其未經授權使用受版權保護的書籍來訓練 ChatGPT,並使用其機器學習模型非法收集網路使用者的個人資訊。
對 OpenAI 處理和保存用戶資料的隱私擔憂也導致義大利在 3 月底完全阻止 ChatGPT 的使用。
在該公司做出改變以提高聊天機器人用戶資料處理的透明度並添加選擇退出用於訓練演算法的 ChatGPT 對話的選項後,該禁令現已取消。
然而,隨著 OpenAI 爬蟲 GPTBot 的推出,可能會出現進一步的法律考量。
為了避免潛在的法律問題和侵權索賠,各機構必須確保所有人工智慧模型都接受授權資料來源的培訓並遵守版權限制:
- 確保資料是合法取得的,並且該機構擁有使用這些資料的適當權利。
- 過濾掉不具備所需法律權限或品質較差的資料。
- 對數據和人工智慧模型進行定期審計,以確保它們遵守數據使用權和法律。
- 進行資料權利和隱私的法律諮詢,以確保不與法律政策發生衝突。
在將人工智慧模型整合到工作流程和專案中之前,機構和客戶法律團隊可能都需要參與上述討論。
資料隱私和保護
人工智慧技術嚴重依賴數據,其中可能包括敏感的個人資訊。
收集、儲存和處理使用者資料必須符合相關隱私權法,例如歐盟的《一般資料保護規範》(GDPR)。
此外,最近推出的歐盟人工智慧法案也強調解決與人工智慧系統相關的資料隱私問題。
這並非沒有道理。 由於上傳到 ChatGPT 的機密數據被曝光,三星等大公司已完全禁止人工智慧。
因此,如果機構將客戶資料與人工智慧技術結合使用,他們應該:
- 優先考慮資料收集的透明度。
- 徵得用戶同意。
- 實施強而有力的安全措施來保護敏感資訊。
在這些情況下,機構可以透過向使用者明確傳達將收集哪些資料、如何使用資料以及誰有權存取這些資料來優先考慮資料收集的透明度。
為了獲得用戶同意,請確保透過清晰且易於理解的同意書來解釋資料收集的目的和好處,並自由地給予同意。
此外,強大的安全措施包括:
- 資料加密。
- 存取控制。
- 數據匿名化(如果可能)。
- 定期審核和更新。
例如,OpenAI 的政策符合資料隱私和保護的需求,並專注於提高人工智慧應用程式的透明度、使用者同意和資料安全。
公平與偏見
搜尋引擎優化和媒體中使用的人工智慧演算法有可能無意中延續偏見或歧視某些個人或群體。
各機構必須積極主動地識別和減輕演算法偏差。 根據新的歐盟人工智慧法案,這一點尤其重要,該法案禁止人工智慧系統不公平地影響人類行為或表現出歧視行為。
為了減輕這種風險,各機構應確保人工智慧模型的設計包含不同的數據和觀點,並持續監控結果是否有潛在的偏見和歧視。
實現這一目標的一種方法是使用有助於減少偏見的工具,例如 AI Fairness 360、IBM Watson Studio 和 Google 的 What-If Tool。
虛假或誤導性內容
包括 ChatGPT 在內的人工智慧工具可以產生可能不準確、具有誤導性或虛假的合成內容。
例如,人工智慧經常創建虛假的線上評論來宣傳某些地方或產品。 這可能會為依賴人工智慧生成內容的企業帶來負面後果。
在發布之前實施明確的政策和程序來審查人工智慧產生的內容對於防止這種風險至關重要。
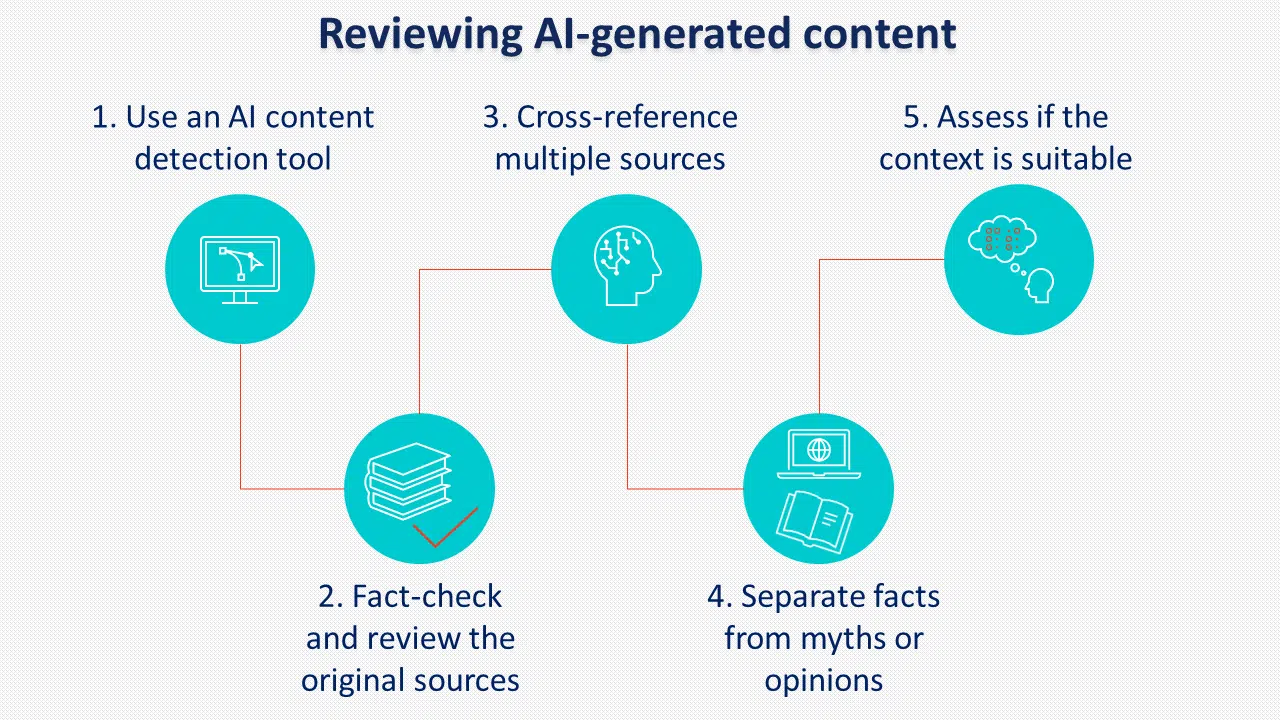
另一個需要考慮的做法是標記人工智慧產生的內容。 儘管谷歌似乎沒有強制執行,但許多政策制定者支持人工智慧標籤。
責任和問責制
隨著人工智慧系統變得越來越複雜,責任問題也隨之出現。
使用人工智慧的機構必須準備好對因使用人工智慧而產生的任何意外後果承擔責任,包括:
- 使用人工智慧對招聘候選人進行排序時存在偏見和歧視。
- 濫用人工智慧的力量用於惡意目的(例如網路攻擊)的可能性。
- 如果未經同意收集信息,則會喪失隱私。
歐盟人工智慧法案引入了關於高風險人工智慧系統的新規定,可能會嚴重影響用戶的權利,強調了為什麼機構和客戶在使用人工智慧技術時必須遵守相關條款和政策。
OpenAI 的一些最重要的條款和政策涉及用戶提供的內容、回應的準確性以及個人資料的處理。
內容策略規定 OpenAI 將產生內容的權利分配給使用者。 它還指定生成的內容可以用於任何目的,包括商業目的,前提是遵守法律限制。
然而,它也指出,輸出可能既不完全獨特也不準確,這意味著人工智慧生成的內容在使用前應始終進行徹底審查。
在個人資料方面,OpenAI 收集用戶輸入的所有信息,包括文件上傳。
在使用服務處理個人資料時,使用者必須提供合法的充分隱私權聲明並填寫表格以請求資料處理。
各機構必須主動解決問責問題,監控人工智慧輸出,並實施強而有力的品質控制措施,以減輕潛在的法律責任。
取得搜尋行銷人員信賴的每日電子報。

查看條款。
機構面臨的人工智慧實施挑戰
自從 OpenAI 去年發布 ChatGPT 以來,已經有很多關於生成式 AI 將如何改變 SEO 作為一個職業及其對媒體產業的整體影響的討論。
儘管變化伴隨著日常工作量的增強,但機構在將人工智慧實施到客戶策略時應考慮一些挑戰。
教育和意識
許多客戶可能缺乏對人工智慧及其影響的全面了解。
因此,各機構面臨著讓客戶了解與人工智慧實施相關的潛在利益和風險的挑戰。
不斷變化的監管環境需要與客戶就確保法律合規所採取的措施進行清晰的溝通。
為了實現這一目標,各機構必須:
- 清楚了解客戶的目標。
- 能夠解釋好處。
- 展示實施人工智慧的專業知識。
- 應對挑戰和風險。
一種方法是與客戶分享一份包含所有必要資訊的情況說明書,並在可能的情況下提供案例研究或其他範例,說明他們如何從使用人工智慧中受益。
資源分配
將人工智慧整合到搜尋引擎優化和媒體策略中需要大量資源,包括財務投資、技術人員和基礎設施升級。
各機構必須仔細評估客戶的需求和能力,以確定在預算限制內實施人工智慧解決方案的可行性,因為他們可能需要能夠有效合作的人工智慧專家、數據分析師、搜尋引擎優化和內容專家。
基礎設施需求可能包括人工智慧工具、數據處理和分析平台以提取見解。 是否提供服務或促進外部資源取決於每個機構現有的能力和預算。
外包其他機構可能會導致更快的實施,而投資內部人工智慧能力可能更適合對所提供服務的長期控制和客製化。
技術專長
人工智慧的實施需要專門的技術知識和專業知識。
各機構可能需要招募或提高其團隊的技能,以根據新的監管要求有效地開發、部署和管理人工智慧系統。
為了充分利用人工智慧,團隊成員應該具備:
- 良好的程式設計知識。
- 用於管理大量資料的資料處理和分析技能。
- 機器學習的實用知識。
- 優秀的解決問題的能力。
道德考慮
各機構必須考慮人工智慧使用對其客戶的道德影響。
應建立道德框架和指南,以確保整個過程中負責任的人工智慧實踐,解決更新法規中提出的問題。
這些包括:
- 使用人工智慧時的透明度、揭露和問責。
- 尊重用戶隱私和智慧財產權。
- 獲得客戶同意使用人工智慧。
- 人類對人工智慧的控制,不斷致力於改進和適應新興人工智慧技術。
問責很重要:應對人工智慧實施的法律挑戰
雖然人工智慧為改善搜尋引擎優化和媒體實踐提供了令人興奮的機會,但各機構必須應對法律挑戰並遵守與其實施相關的最新法規。
企業和機構可以透過以下方式最大限度地降低法律風險:
- 確保資料是合法取得的,並且該機構擁有使用這些資料的適當權利。
- 過濾掉不具備所需法律權限或品質較差的資料。
- 對數據和人工智慧模型進行審計,確保其遵守數據使用權和法律。
- 就資料權利和隱私進行法律諮詢,以確保不與法律政策發生衝突。
- 優先考慮資料收集的透明度,並透過清晰易懂的同意書獲得使用者同意。
- 使用有助於減少偏見的工具,例如 AI Fairness 360、IBM Watson Studio 和 Google 的 What-If Tool。
- 實施明確的政策和程序,在發布前審查人工智慧產生的內容的品質。
本文表達的觀點是客座作者的觀點,不一定是搜尋引擎土地的觀點。 此處列出了工作人員作者。