
Apache Spark:大數據蒼穹中的耀眼明星。
已發表: 2015-09-24- 向合適的客戶推薦數百萬種產品。
- 跟踪搜索歷史並提供航班旅程的折扣價。
- 比較人員的技術技能並適當地建議與您所在領域的人員建立聯繫。
- 了解數十億移動對象、網絡塔和呼叫交易的模式,計算電信網絡優化或查找網絡漏洞。
- 研究數以百萬計的傳感器特徵並分析傳感器網絡中的故障。
為上述所有任務獲得正確結果所需的基礎數據相對較大。 傳統系統無法有效地處理它(在空間和時間方面)。
這些都是大數據場景。
為了收集、存儲和計算這種海量數據,我們需要一個專門的集群計算系統。 Apache Hadoop為我們解決了這個問題。
它提供了分佈式存儲系統(HDFS)和並行計算平台(MapReduce)。
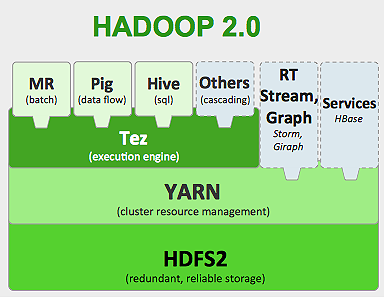
Hadoop 框架的工作原理如下:
- 將大數據文件分解成更小的塊,由單個機器處理(分佈式存儲)。
- 將較長的作業分成較小的任務以並行方式執行(並行計算)。
- 自動處理故障。
Hadoop的局限性
Hadoop在其生態系統中有專門的工具來執行不同的任務。 因此,如果您想運行應用程序的端到端生命週期,您需要使用多種工具。 例如,對於SQL查詢,您將使用hive/pig ,對於流式源,您必須使用Hadoop 內置流或 Apache Storm (它不是 Hadoop 生態系統的一部分),或者對於機器學習算法,您必須使用Mahout 。 將所有這些系統集成在一起以構建單個數據管道用例是一項艱鉅的任務。
在MapReduce作業中,
- 所有地圖任務輸出都被轉儲到本地磁盤(或 HDFS)上。
- Hadoop 將所有溢出文件合併為一個更大的文件,該文件根據減速器的數量進行排序和分區。
- 並且減少任務必須再次將其加載到內存中。
此過程使作業變慢,導致磁盤 I/O 和網絡 I/O。 這也使得 Mapreduce 不適合迭代處理,您必須一遍又一遍地將機器學習算法應用於同一組數據。
進入 Apache Spark 的世界:
Apache Spark於 2009 年在加州大學伯克利分校 AMPLAB開發,並在 2010 年成為 Apache 迄今為止貢獻最大的開源項目。
Apache Spark是更通用的系統,您可以在其中一次運行批處理和流式作業。 它通過添加在內存中更快地處理數據的功能,在速度上取代了其前身 MapReduce。 它在磁盤上的效率也更高。 它利用其基本數據單元RDD(彈性分佈式數據集)進行內存處理。 它們在內存中保存盡可能多的數據集,以實現作業的完整生命週期,從而節省磁盤 I/O。 在內存上限之後,某些數據可能會溢出磁盤。
下圖顯示了 Apache Hadoop 和 Spark 用於計算邏輯回歸的運行時間(以秒為單位)。 Hadoop 用了 110 秒,而 spark 只用了 0.9 秒完成了同樣的工作。
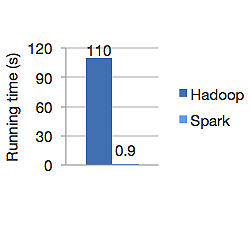
Spark 不會將所有數據存儲在內存中。 但是如果數據在內存中,它會充分利用 LRU 緩存來更快地處理它。 在內存中計算數據時,它比 Hadoop 在磁盤上快 100 倍。
Spark 的分佈式數據存儲模型,彈性分佈式數據集 (RDD),保證容錯,從而最大限度地減少網絡 I/O。 火花紙 說:

“RDD 通過沿襲的概念實現容錯:如果 RDD 的一個分區丟失,RDD 有足夠的信息來說明它是如何從其他 RDD 派生的,以便能夠僅重建該分區。”
所以你不需要復制數據來實現容錯。
在 Spark MapReduce 中,mappers 的輸出保存在 OS 緩衝區緩存中,reducers 將其拉到自己的一側並直接寫入內存,這與 Hadoop 不同,Hadoop 的輸出會溢出到磁盤並再次讀取。
Spark 的內存緩存使其適用於需要反複使用相同數據的機器學習算法。 Spark 可以使用直接無環圖 (DAG) 運行複雜的作業、多步驟數據管道。
Spark 是用 Scala 編寫的,它運行在 JVM(Java 虛擬機)上。 Spark 為 Java、Scala、Python 和 R 語言提供開發 API。 Spark 在 Hadoop YARN、Apache Mesos 上運行,並且擁有自己的獨立集群管理器。
2014 年,它在短短 23 分鐘內獲得了對 100TB 數據(1 萬億條記錄)基准進行排序的世界紀錄第一名,而雅虎之前的 Hadoop 記錄約為 72 分鐘。 這證明 spark 排序數據的速度提高了 3 倍,機器數量減少了 10 倍。 所有排序都發生在磁盤 (HDFS) 上,實際上沒有使用 spark 內存緩存功能。
星火生態系統
Spark 旨在一次性進行高級分析,以實現它提供以下組件:
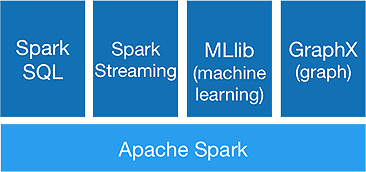
1.火花芯:
Spark 核心 API 是 Apache Spark 框架的基礎,它處理作業調度、任務分配、內存管理、I/O 操作和故障恢復。 Spark中主要的邏輯數據單元稱為RDD(Resilient Distributed Dataset),它以分佈式的方式存儲數據,以供以後並行處理。 它懶惰地計算操作。 因此,內存不必一直被佔用,其他作業可以使用它。
2.火花SQL:
它提供了低延遲的交互式查詢功能。 新的DataFrame API 可以保存結構化和半結構化數據,並允許所有 SQL 操作和函數進行計算。
3.火花流:
它提供實時流 API ,以微批次的形式收集和處理數據。
它使用Dstreams ,它只是 RDD 的連續序列,來計算傳入數據的業務邏輯並立即生成結果。
4.MLlib :
它是spark 的機器學習庫(幾乎比 Mahout 快 9 倍),提供機器學習以及分類、回歸、協同過濾等統計算法。
5.GraphX :
GraphX API 提供處理圖形和執行圖形並行計算的功能。 它包括像 PageRank 這樣的圖算法和各種分析圖的函數。
Spark 會標誌著 Hadoop 時代的終結嗎?
Spark 仍然是一個年輕的系統,不如 Hadoop 成熟。 沒有像 HBase 這樣的 NOSQL 工具。 考慮到更快的數據處理需要高內存,你不能說它在商用硬件上運行。 Spark 沒有自己的存儲系統。 它依賴於 HDFS。
因此,Hadoop MapReduce 仍然適用於某些不包含太多數據管道的批處理作業。
“新技術永遠不會完全取代舊技術; 他們都寧願共存。”
結論
在這篇博客中,我們探討了為什麼需要像 Spark 這樣的工具,是什麼讓它更快的集群計算系統及其核心組件。 下一部分我們將深入了解 Spark 核心 API RDD、轉換和操作。