
與十億封電子郵件共進早餐
已發表: 2020-02-05我們只要求一個順利的黑色星期五
當我在黑色星期五週末每天早上 8 點左右在太平洋標準時間 (PST) 吃早餐時,Twilio SendGrid 已經處理了超過 1B 封以美國東部標準時間 (EST) 計算的電子郵件。
查看統計數據,我們從感恩節到網絡星期一處理了超過 16.5B 的電子郵件,從感恩節前的星期二開始的一周處理了超過 22.3B 的電子郵件。 這些對企業來說確實是很好的數字。 從工程組織的角度來看,在沒有任何警報觸發或任何降級客戶體驗的情況下這樣做是非常令人滿意的。
我建議閱讀這篇由我的同事 Sara Saedinia 撰寫的博客文章,在一天內為超過 40 億封電子郵件擴展我們的基礎架構,其中談到了以這種規模順利運營對我們的業務和依賴我們的企業的重要性。 在這裡,我將重點介紹我們的準備工作,這些準備工作使我們的電子郵件客戶今年最關鍵的周末成為迄今為止最順利的周末。
我們是如何讓這成為一個無縫的黑色星期五週末? 在我們根據遙測觀測驗證系統改進時,處理我們最大的發送日需要勤奮的計劃、大量的區域擺動測試、數十人分析數據以及收緊反饋循環。 我們仍將進行更多自動化和改進,以確保我們繼續讓客戶滿意,並確保我們迅速將正確的通信發送給正確的收件人。
了解我們的業務
SendGrid 的業務模型要求我們始終處於運行狀態——我們沒有用於接收和傳遞郵件的維護窗口。 我們的客戶需要可靠的服務,能夠不間斷地接收和遞送郵件。 這意味著我們所有的基礎設施更改、硬件和軟件都需要在我們繼續處理和發送電子郵件的同時完成,沒有任何明顯的延遲。
如下圖所示,我們處理的電子郵件數量在過去幾年中大幅增長。
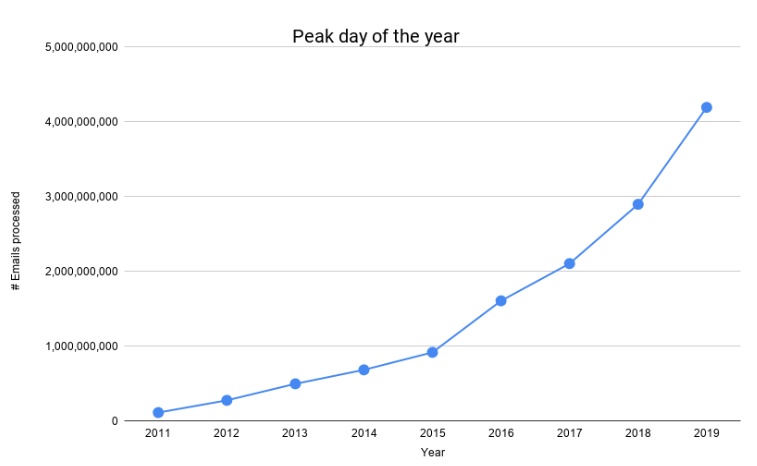
我們在 2016 年年中度過了第一個 1B 日,而在這個黑色星期五我們度過了第一個 4B 日。 在不到 4 年的時間裡增長了 400%。 考慮到我們不斷擴大的規模,保持我們的成本可控,並為我們的客戶提供更高的可靠性,我們不得不重新設計和發展我們的郵件處理管道。
黑色星期五來了
人們問我,“為什麼黑色星期五和網絡星期一對你如此重要?” 這個網絡星期一,我們處理的電子郵件比去年的峰值多 45%。 黑色星期五是美國最重要的零售和消費活動之一。 傳統上,這一天是零售商全年盈利(淨正數)的日子。 電子郵件營銷和交易電子郵件的使用已成為所有企業的關鍵。
從零售商到提供營銷自動化的企業,在黑色星期五週末無法可靠地發送電子郵件可能會導致重大的收入損失。 因此,這個週末對我們來說通常是一個決定業務的周末。 我們盡最大努力為我們的工程師、支持代理、客戶成功經理、高管,最重要的是,為我們的客戶提供盡可能簡單的服務。
為黑色星期五做準備
那麼我們如何為黑色星期五做準備呢? 我們買T卹! (並做大量工作。)繼續閱讀我們如何準備。
Twilio SendGrid 爾灣辦事處的成員

Twilio SendGrid 丹佛辦事處的一些成員。

統計數據
讓我們從一些統計數據開始:
- 在黑色星期五處理 4.1B+ 電子郵件,在網絡星期一處理 4.2B+ 電子郵件
- 從感恩節到網絡星期一處理了 16.5B+ 封電子郵件
- 在高峰時段處理了 3.15 億多封電子郵件
- 黑色星期五和網絡星期一,每個連續 8 小時處理 2.2 億封或更多電子郵件
- 所有這一切,可交付電子郵件的中位端到端時間為 1.9 秒
- 平均而言,我們每條消息大約發出 5.5 個事件。 基於此,我們的系統發出並處理了從感恩節到網絡星期一的 91B+ 事件,僅網絡星期一就發出並處理了 23B+
挑戰
前所未有的規模:我們要測試的規模必須與我們預測的峰值負載相匹配。 當我們在 4 月初對過去一年的準備工作進行第一次測試時,我們的平均工作日交易量還不到我們預測峰值的一半。 我們的每小時峰值甚至不到我們將要測試的一半。
管理我們的環境:電子郵件是一個有狀態的工作流程:有必要跟踪消息的狀態。 因此,當消息在管道中移動時,我們會跟踪它是否反彈或延遲,並防止重複。 因此,我們的郵件管道是混合雲和本地架構,自動縮放並不是一個神奇的解決方案。 我們面臨的挑戰是在不影響客戶成本的情況下,最大限度地提高數據中心服務的效率,同時準備處理海量峰值的能力。

縮放不是線性的:並非所有系統都是線性縮放的。 由於我們預測的規模比我們第一次開始測試時要高得多,我們不能僅僅通過一個簡單的數學模型來計算我們的硬件需求。 同樣重要的是要記住,盲目地擴展服務會使依賴項過載,而數據庫等依賴項的擴展方式與我們的郵件傳輸代理 (MTA) 不同。
平衡我們的投資:隨著我們不斷創新,確保我們支持與電子郵件傳遞相關的客戶需求,我們明白,如果我們的功能無法訪問並按需要執行,我們的功能不會為我們的客戶提供任何價值。 我們必須找到一個平衡點,並在測試、學習、升級和改進我們的系統方面進行適當的投資,以在我們的規模上保持可靠和彈性。 有效地這樣做使我們能夠繼續投資於創新。
我們是怎麼做的?
我們一起做,作為一個團隊。 正如我們所說,手挽手。 從 4 月到 11 月,我們今年的準備工作涉及多個團隊的 100 多名成員的參與。 對峰值預測進行建模、定義可觀察性標準、從我們的觀察中學習、設計必要的更改、規劃和管理需要多個人的各種技能。
我們彼此信任,同時保持彼此誠實,保持專注並實現我們的目標。
一個有效且不斷改進的過程是我們的朋友。
規劃
我們有三個數據中心來處理客戶的電子郵件。 為了規劃一個未達到的規模,我們驗證我們可以在只有兩個數據中心可用的情況下處理我們的峰值預計流量。 為了滿足我們的高可用性 SLA,我們的基礎架構內置了區域故障轉移。 這意味著我們有能力在區域之間對流量進行故障轉移。
我們在全年以頻繁的節奏利用此功能作為標準操作程序,並加速它作為我們努力證明我們能夠在保持服務質量的同時服務黑色星期五/網絡星期一高峰量的一部分。 如果系統遙測接近我們的服務級別目標 (SLO) 的閾值,我們能夠快速利用多個區域來恢復名義狀態。 然後,我們利用收集到的遙測數據來確定我們需要在哪裡進行更改。
與此同時,我們已經開始審查和鞏固我們的服務水平目標 (SLO),它為我們提供了系統可用性的精確數字目標和我們的服務水平指標 (SLI),它為我們提供了成功探測系統的頻率。
觀察、學習和交流
每次測試都提供了大量信息。 我們面臨的挑戰之一是有效地記錄和交流輪換測試團隊的觀察結果,然後跨多個系統分析數據。 儘管我們有標準的團隊儀表板,但每個成員都可以有他們觀察到的特定內容。
我們開始與測試團隊一起進行回顧,以分析為多個團隊管理的多個服務轉儲的所有技術信息。 這些回顧很長,而且在大部分時間裡,每次測試只對一兩個團隊有用。 我們最終轉而使用 Slack Thread 進行複古筆記,每次測試節省了 10 個小時的會議時間。
我們的測試管理團隊包括兩名工程經理、一名架構師和一名高級工程師。 管理人員在規劃和依賴管理方面發揮著關鍵作用,而更多的技術人員則幫助處理和分析端到端系統級別的信息。
基於對可用信息的分析,我們反複驗證我們的 SLI 嚴格符合我們的 SLO。 我們微調了我們的警報並使某些關鍵警報更加敏感,以便提前識別任何潛在的系統降級。
優先級和實施
我們對提議的更改進行了票證,並且團隊對這些票證進行了優先排序。 這裡的第一個挑戰是跨多個團隊董事會管理這些票證。 另一個挑戰是無情地將黑色星期五的工作與其他優先事項放在一起。
我們需要為我們的工程師提供創造性的自由,以提出解決難題的方法。 同時,我們必須確保這些解決方案符合我們的長期計劃。 同樣至關重要的是,我們始終意識到任何利益衝突,這意味著要避免任何可能反過來影響我們的短期解決方案。
驗證已實施的更改將成為我們即將進行的測試的目標。
隨著我們接近黑色星期五,保持和加快節奏是計劃和執行方面的一項重大挑戰。
加速度
進入 9 月後,我們開始每週進行多次壓力測試。 這要求我們更快地識別、修復和驗證問題。 它還為我們提供了更快的學習和適應週期。
除瞭如前所述的郵件管道的全面測試外,我們還同時開始對我們的支持服務進行壓力測試。 在同一時期,我們開始與我們最大的客戶之一進行負載測試,以確保我們的傳入 geopod 能夠在假期期間毫無顧慮地處理他們預期的突發發送。
由於工作時間長和管理工作的挑戰,我們的團隊已經筋疲力盡。 我們列出了必要時停止測試所需的最關鍵警報,並使它們更加敏感。 這使我們能夠開始進行測試,而無需我們一大早就在場監控我們的系統。
小心加速
當我們接近 9 月底時,有人擔心我們可能沒有朝著正確的方向足夠快地前進。 我們創建了一個老虎團隊,一個可以跨多個團隊處理任何票證的專家團隊,以及一個日常工作流程更精簡的團隊。
我們對運營基礎設施和郵件處理軟件進行了重大改進,為黑色星期五做準備。 這些變化被明確優先考慮,團隊必須相互配合。 對於將 SendGrid 放在首位的人來說,這是一次很棒的經歷。 我們正在對應用程序、基礎架構進行更改,並增加我們的硬件容量,同時以啟動速度運行上市公司業務部門的核心引擎。 最重要的是,我們做到了這一切,並沒有降低客戶的服務體驗。
未來的計劃
我們花了很多時間為 2019 年黑色星期五做準備。今年的經驗教訓將幫助我們為 2020 年黑色星期五和網絡星期一的大部分準備工作自動化。我們期待在無壓力、創紀錄的情況下又一個成功的一年- 為我們的客戶和員工發送大量假期。