
爬取效能:如何提升爬取優化
已發表: 2022-10-27不能保證 Googlebot 會抓取它可以在您的網站上訪問的每個網址。 相反,絕大多數網站都缺少大量頁面。
現實情況是,Google 沒有資源來抓取它找到的每個頁面。 Googlebot 已發現但尚未抓取的所有 URL 以及它打算重新抓取的 URL 在抓取隊列中都具有優先級。
這意味著 Googlebot 只會抓取那些被分配了足夠高優先級的內容。 而且由於抓取隊列是動態的,它會隨著 Google 處理新網址而不斷變化。 並不是所有的 URL 都排在隊列的後面。
那麼如何確保您網站的 URL 是 VIP 並跳線呢?
爬行對SEO至關重要

為了讓內容獲得可見性,Googlebot 必須首先抓取它。
但好處比這更細微,因為頁面從原來的爬取速度越快:
- 已創建,新內容可以越早出現在 Google 上。 這對於限時或率先上市的內容策略尤其重要。
- 更新,更新的內容越早開始影響排名。 這對於內容重新發布策略和技術 SEO 策略都特別重要。
因此,爬行對於您的所有自然流量都是必不可少的。 然而,經常有人說抓取優化只對大型網站有益。
但這與您網站的大小、更新內容的頻率或您是否在 Google Search Console 中是否有“已發現 - 當前未編入索引”排除項無關。
抓取優化對每個網站都有好處。 對其價值的誤解似乎源於無意義的測量,尤其是爬行預算。
抓取預算無關緊要

很多時候,爬行是根據爬行預算來評估的。 這是 Googlebot 在給定時間內將在特定網站上抓取的 URL 數量。
谷歌表示,這是由兩個因素決定的:
- 抓取速度限制(或 Googlebot 可以抓取的速度):Googlebot 在不影響網站性能的情況下獲取網站資源的速度。 從本質上講,響應式服務器會導致更高的爬網率。
- 抓取需求(或 Googlebot 想要抓取的內容):Googlebot 在單次抓取期間訪問的 URL 數量,基於對(重新)索引編制的需求,受網站內容的受歡迎程度和陳舊性的影響。
一旦 Googlebot “花費”了它的抓取預算,它就會停止抓取一個網站。
谷歌沒有提供抓取預算的數字。 最接近的是在 Google Search Console 抓取統計報告中顯示總抓取請求。
包括我自己在內的許多 SEO 都煞費苦心地試圖推斷抓取預算。
經常出現的步驟大致如下:
- 確定您的網站上有多少可抓取頁面,通常建議查看 XML 站點地圖中的 URL 數量或運行無限制的抓取工具。
- 通過導出 Google Search Console Crawl Stats 報告或基於日誌文件中的 Googlebot 請求來計算每天的平均抓取次數。
- 將頁面數除以每天的平均爬網次數。 常說,如果結果在 10 以上,重點是爬取預算優化。
然而,這個過程是有問題的。
不僅因為它假定每個 URL 都被爬取一次,實際上有些 URL 被爬取了多次,而另一些則根本不被爬取。
不僅因為它假定一次爬網等於一頁。 實際上,一個頁面可能需要多次 URL 爬取來獲取加載它所需的資源(JS、CSS 等)。
但最重要的是,因為當它被提煉成一個計算指標時,比如每天的平均抓取次數,抓取預算只不過是一個虛榮指標。
任何針對“抓取預算優化”的策略(又名,旨在不斷增加抓取總量)都是徒勞的。
如果它用於沒有價值的 URL 或自上次抓取以來未更改的頁面,您為什麼要關心增加抓取的總數? 這樣的抓取不會幫助 SEO 性能。
另外,任何看過爬網統計數據的人都知道,根據多種因素,它們從一天到另一天的波動通常非常劇烈。 這些波動可能與 SEO 相關頁面的快速(重新)索引相關,也可能不相關。
抓取的 URL 數量的上升或下降本質上既不好也不壞。
抓取效率是一個 SEO KPI

對於您要編入索引的頁面,重點不應該是它是否被抓取,而是它在發布或發生重大變化後被抓取的速度。
本質上,目標是最大限度地縮短創建或更新與 SEO 相關的頁面與下一次 Googlebot 抓取之間的時間。 我把這個時間稱為延遲爬行功效。
衡量抓取效率的理想方法是計算數據庫創建或更新日期時間與下一次 Googlebot 從服務器日誌文件抓取 URL 之間的差異。
如果難以訪問這些數據點,您還可以使用 XML 站點地圖 lastmod 日期作為代理,並在 Google Search Console URL Inspection API 中查詢 URL 以了解其上次抓取狀態(每天最多 2,000 次查詢)。
此外,通過使用 URL 檢查 API,您還可以跟踪索引狀態何時更改,以計算新創建的 URL 的索引效率,這是發布和成功索引之間的區別。
因為在不影響索引狀態或處理頁面內容刷新的情況下進行爬網只是一種浪費。
抓取效率是一個可操作的指標,因為隨著它的降低,越多的 SEO 關鍵內容可以通過 Google 呈現給您的受眾。
您還可以使用它來診斷 SEO 問題。 深入研究 URL 模式,了解網站各個部分的內容被抓取的速度有多快,以及這是否是阻礙有機性能的原因。
如果您發現 Googlebot 需要數小時、數天或數週的時間來抓取並索引您新創建或最近更新的內容,您能做些什麼呢?
獲取營銷人員所依賴的每日通訊搜索。
見條款。
優化爬取的 7 個步驟
抓取優化就是引導 Googlebot 抓取重要的 URL 當它們(重新)發佈時很快。 請遵循以下七個步驟。
1. 確保快速、健康的服務器響應
高性能服務器至關重要。 在以下情況下,Googlebot 會減慢或停止抓取:

- 抓取您的網站會影響性能。 例如,它們爬得越多,服務器響應時間就越慢。
- 服務器響應大量錯誤或連接超時。
另一方面,提高頁面加載速度以提供更多頁面可以導致 Googlebot 在相同時間內抓取更多網址。 這是頁面速度作為用戶體驗和排名因素之外的另一個好處。
如果您還沒有,請考慮支持 HTTP/2,因為它允許在服務器上請求更多具有類似負載的 URL。
但是,性能和爬取量之間的相關性只是在一定程度上。 一旦您跨越了因站點而異的閾值,服務器性能的任何額外提升都不太可能與爬網的增加相關聯。
如何檢查服務器健康
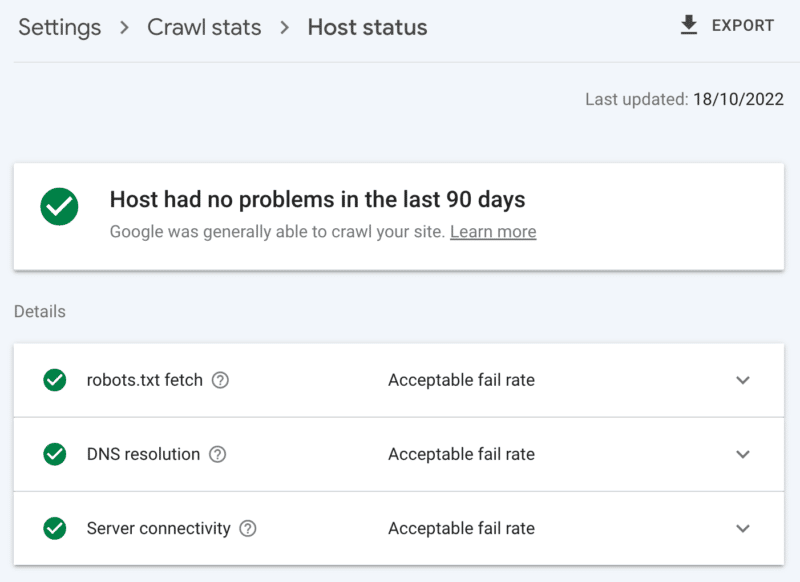
Google Search Console 抓取統計報告:
- 主機狀態:顯示綠色勾號。
- 5xx 錯誤:佔不到 1%。
- 服務器響應時間圖表:趨勢低於 300 毫秒。
2.清理低價值內容
如果大量網站內容已過時、重複或質量低下,則會導致對爬網活動的競爭,可能會延遲新內容的索引或更新內容的重新索引。
加上定期清理低價值內容還可以減少索引膨脹和關鍵字蠶食,並且有利於用戶體驗,這是 SEO 的明智之舉。
當您有另一個可以被視為明顯替代的頁面時,將內容與 301 重定向合併; 理解這一點將使您的處理爬網成本增加一倍,但對於鏈接資產而言,這是值得的犧牲。
如果沒有等效內容,使用 301 只會導致軟 404。使用 410(最佳)或 404(次之)狀態碼刪除此類內容,以發出強烈信號,不再抓取該 URL。
如何檢查低價值內容
Google Search Console 頁面中報告“已抓取 - 當前未編入索引”排除項的 URL 數量。 如果這很高,請查看為文件夾模式或其他問題指標提供的示例。
3. 查看索引控制
Rel=規範鏈接 是避免索引問題的有力提示,但通常過度依賴並最終導致爬網問題,因為每個規範化 URL 至少需要兩次爬網,一次為自己,一次為合作夥伴。
類似地,noindex robots 指令對於減少索引膨脹很有用,但大量的指令會對爬網產生負面影響——因此僅在必要時使用它們。
在這兩種情況下,問問自己:
- 這些索引指令是處理 SEO 挑戰的最佳方式嗎?
- 可以在 robots.txt 中合併、刪除或阻止某些 URL 路由嗎?
如果您正在使用它,請認真重新考慮將 AMP 作為長期技術解決方案。
隨著頁面體驗更新的重點是核心網絡生命力,並且只要您滿足網站速度要求,所有 Google 體驗中都包含非 AMP 頁面,請仔細研究 AMP 是否值得雙重抓取。
如何檢查對索引控件的過度依賴
Google Search Console 覆蓋率報告中歸類於排除項但沒有明確原因的 URL 數量:
- 具有適當規範標籤的替代頁面。
- 被 noindex 標籤排除。
- 重複,谷歌選擇了與用戶不同的規範。
- 重複的、提交的 URL 未被選為規範。
4. 告訴搜索引擎蜘蛛要抓取什麼以及何時抓取
XML 站點地圖是幫助 Googlebot 確定重要站點 URL 優先級並在此類頁面更新時進行通信的重要工具。
要獲得有效的爬蟲引導,請務必:
- 僅包含可索引且對 SEO 有價值的 URL——通常是 200 個狀態代碼、規範的原始內容頁面,帶有“索引,關注”機器人標籤,您關心它們在 SERP 中的可見性。
- 在各個 URL 和站點地圖本身上包含準確的 <lastmod> 時間戳標記,盡可能接近實時。
Google 不會在每次抓取網站時檢查站點地圖。 因此,每當它更新時,最好將其 ping 以引起 Google 的注意。 為此,請在瀏覽器或命令行中發送 GET 請求至:
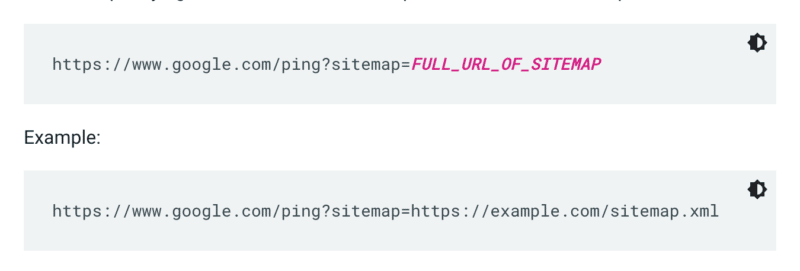
此外,在 robots.txt 文件中指定站點地圖的路徑,並使用站點地圖報告將其提交到 Google Search Console。
通常,Google 會比其他網站更頻繁地抓取站點地圖中的網址。 但是,即使站點地圖中的一小部分 URL 質量低下,它也可以阻止 Googlebot 使用它來抓取建議。
XML 站點地圖和鏈接將 URL 添加到常規爬網隊列中。 還有一個優先級爬取隊列,有兩種進入方式。
首先,對於那些有職位發布或直播視頻的人,您可以將 URL 提交到 Google 的 Indexing API。
或者,如果您想引起 Microsoft Bing 或 Yandex 的注意,您可以將 IndexNow API 用於任何 URL。 但是,在我自己的測試中,它對 URL 的抓取影響有限。 因此,如果您使用 IndexNow,請務必監控 Bingbot 的抓取效率。
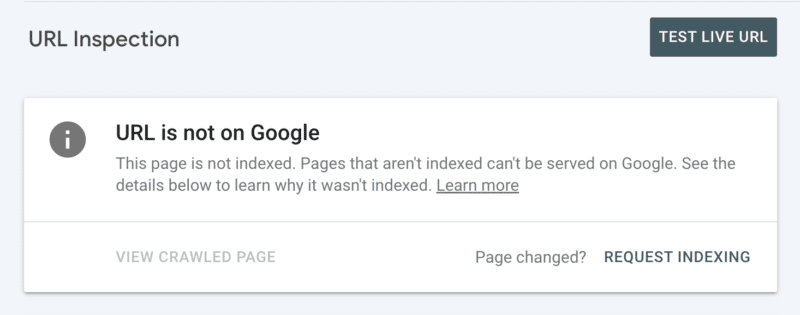
其次,您可以在 Search Console 中檢查 URL 後手動請求索引。 儘管請記住,每天有 10 個 URL 的配額,並且抓取仍然需要相當長的時間。 在您挖掘以發現爬行問題的根源時,最好將此視為臨時補丁。
如何檢查基本的 Googlebot 抓取指南
在 Google Search Console 中,您的 XML 站點地圖顯示“成功”狀態並且最近被讀取。
5.告訴搜索引擎蜘蛛什麼不要爬
某些頁面可能對用戶或網站功能很重要,但您不希望它們出現在搜索結果中。 防止此類 URL 路由使用 robots.txt 禁止分散抓取工具的注意力。 這可能包括:
- API 和 CDN 。 例如,如果您是 Cloudflare 的客戶,請務必禁止將文件夾 /cdn-cgi/ 添加到您的站點。
- 不重要的圖像、腳本或樣式文件,如果在沒有這些資源的情況下加載的頁面不會受到損失的顯著影響。
- 功能頁面,例如購物車。
- 無限空間,例如由日曆頁面創建的空間。
- 參數頁。 尤其是那些來自過濾(例如,?price-range=20-50)、重新排序(例如,?sort=)或搜索(例如,?q=)的分面導航,因為每個單獨的組合都被爬蟲計為單獨的頁面。
請注意不要完全阻止分頁參數。 對於 Googlebot 發現內容和處理內部鏈接資產而言,可抓取的分頁通常是必不可少的。 (查看有關分頁的 Semrush 網絡研討會,了解有關原因的更多詳細信息。)
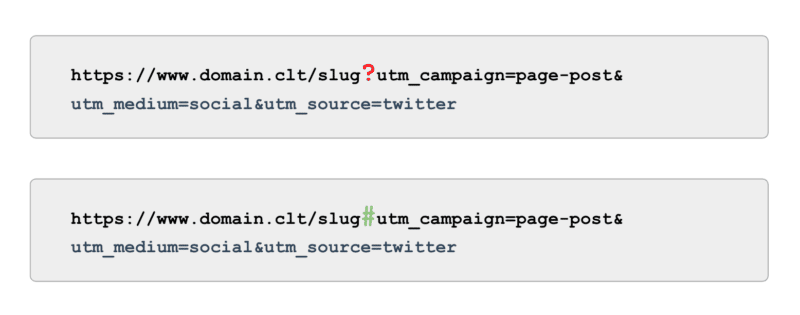
當涉及到跟踪時,不要使用由參數驅動的 UTM 標籤(又名“?”),而是使用錨點(又名“#”)。 它在 Google Analytics(分析)中提供了相同的報告優勢,但無法被抓取。
如何檢查 Googlebot 不抓取指南
在 Google Search Console 中查看“已編入索引,未在站點地圖中提交”網址示例。 忽略分頁的前幾頁,您還發現了哪些其他路徑? 它們應該被包含在 XML 站點地圖中,被阻止被抓取還是讓它被抓取?
此外,查看“已發現 - 當前未編入索引”列表 - 在 robots.txt 中阻止任何對 Google 提供低價值或沒有價值的 URL 路徑。
要將此提升到一個新的水平,請查看服務器日誌文件中所有 Googlebot 智能手機抓取的無價值路徑。
6.策劃相關鏈接
頁面的反向鏈接對於 SEO 的許多方面都很有價值,抓取也不例外。 但是對於某些頁麵類型,獲取外部鏈接可能具有挑戰性。 例如,產品、站點架構中較低級別的類別甚至文章等深層頁面。
另一方面,相關的內部鏈接是:
- 技術上可擴展。
- 向 Googlebot 發出強有力的信號,以優先抓取頁面。
- 對深度頁面抓取特別有影響。
麵包屑、相關內容塊、快速過濾器和精心策劃的標籤的使用對爬網效率都有很大的好處。 由於它們是 SEO 關鍵內容,請確保此類內部鏈接不依賴於 JavaScript,而是使用標準的、可抓取的 <a> 鏈接。
請記住,此類內部鏈接還應為用戶增加實際價值。
如何檢查相關鏈接
使用像 ScreamingFrog 的 SEO 蜘蛛這樣的工具對您的整個網站進行手動抓取,尋找:
- 孤立的 URL。
- robots.txt 阻止的內部鏈接。
- 任何非 200 狀態代碼的內部鏈接。
- 內部鏈接的不可索引 URL 的百分比。
7.審核剩餘的爬取問題
如果上述所有優化都已完成,並且您的爬網效率仍然不理想,請進行深入審核。
首先查看所有剩餘的 Google Search Console 排除示例,以確定抓取問題。
解決這些問題後,使用手動抓取工具更深入地抓取網站結構中的所有頁面,就像 Googlebot 那樣。 將此與縮小到 Googlebot IP 的日誌文件進行交叉引用,以了解哪些頁面正在被抓取,哪些頁面未被抓取。
最後,啟動日誌文件分析將範圍縮小到 Googlebot IP 至少四個星期的數據,最好是更多。
如果您不熟悉日誌文件的格式,請利用日誌分析器工具。 最終,這是了解 Google 如何抓取您的網站的最佳來源。
完成審核並獲得已識別的爬網問題列表後,按每個問題的預期工作量和對性能的影響對其進行排名。
注意:其他 SEO 專家提到,來自 SERP 的點擊會增加對著陸頁 URL 的抓取。 但是,我還無法通過測試確認這一點。
將爬網效率優先於爬網預算
爬取的目的不是為了獲得最高的爬取量,也不是為了讓網站的每個頁面都被重複爬取,它是在盡可能接近創建或更新頁面時吸引與 SEO 相關的內容的爬取。
總的來說,預算並不重要。 你投資的東西才是最重要的。
本文中表達的觀點是客座作者的觀點,不一定是 Search Engine Land。 工作人員作者在這裡列出。