
如何使用架構中的實體來提高 Google 對您內容的理解
已發表: 2023-06-26在您的網站上添加架構標記是幫助 Google 等搜索引擎更快、更準確地理解您的內容的好方法。
利用模式標記的鮮為人知的方法之一是在其中包含“實體”。 將實體添加到架構中可以幫助 Google 更好地理解您內容的關鍵主題。
在本文中,我將引導您逐步完成在架構標記中使用實體的過程。
為什麼在模式標記中使用實體?
那麼,當 Google 的自然語言處理功能(例如 BERT 和 MUM)已經幫助搜索引擎理解您文章的內容時,為什麼還要在模式標記中添加實體呢?
答案是,作者和人工智能有時都無法準確地溝通和識別文章中主題的含義、上下文和重要性。
想像一下,去您最喜歡的當地餐廳,看到菜單上有一個看起來很美味的墨西哥捲餅,但它沒有說明它是什麼種類以及里面有什麼。
所以你點了菜,當它端上來的時候,你必須想辦法用你的感官來捕捉這道菜的所有背景線索。
如果您有足夠的烹飪經驗,您可能會弄清楚大部分成分,但可能不是全部,特別是如果它含有混合香料!
使用實體模式就像向 Google 提供您文章的所有主要成分,使他們本質上更容易識別和理解您文章最重要的主題,而不會產生任何混淆。
這樣做可以減輕確保文章及其句子中完美使用單詞以傳達其含義和重要性的壓力。
將實體添加到文章的架構中
以下過程給了我更多的控制權,減少了對第三方插件的依賴。 但是,如果您想走插件路線,請查看 WordLift。
無論哪種方式,閱讀本指南將幫助您更好地了解 Google 和 NLP 工具如何看待您最重要的主題。
假設您有一篇題為“小型成年犬的 10 種最佳玩具”的文章。
以下是識別與本文最相關的實體並將其添加到架構標記中的步驟。
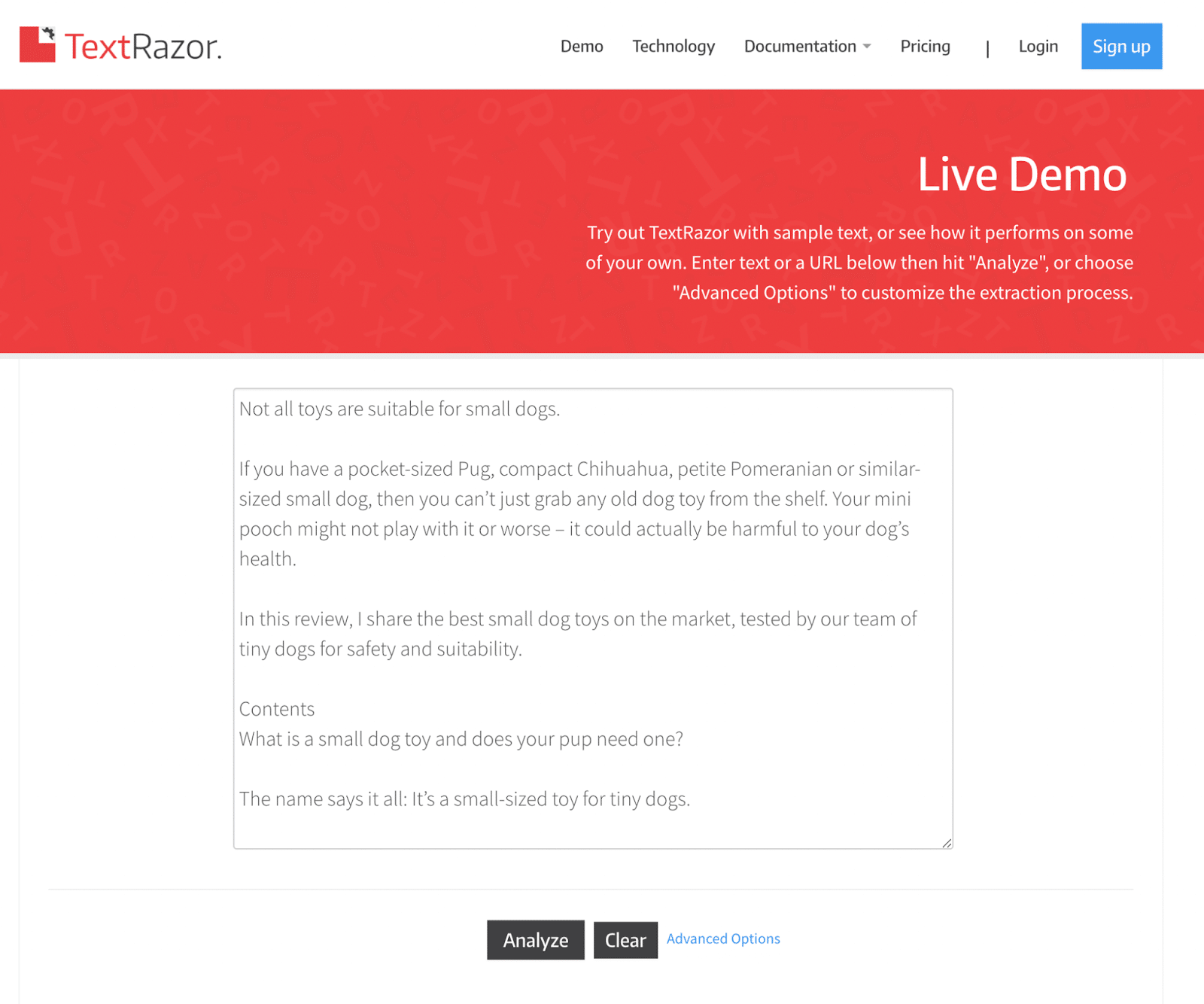
第 1 步:使用 TextRazor 分析您的文章
首先將文章的文本複制並粘貼到 TextRazor 演示中,然後單擊“分析”按鈕。
(對於本指南,我使用的是 DogLab 的文章文本。)
第 2 步:識別相關實體
在結果頁面上,您將在右側邊欄中看到按相關性排名的熱門實體或主題的列表。
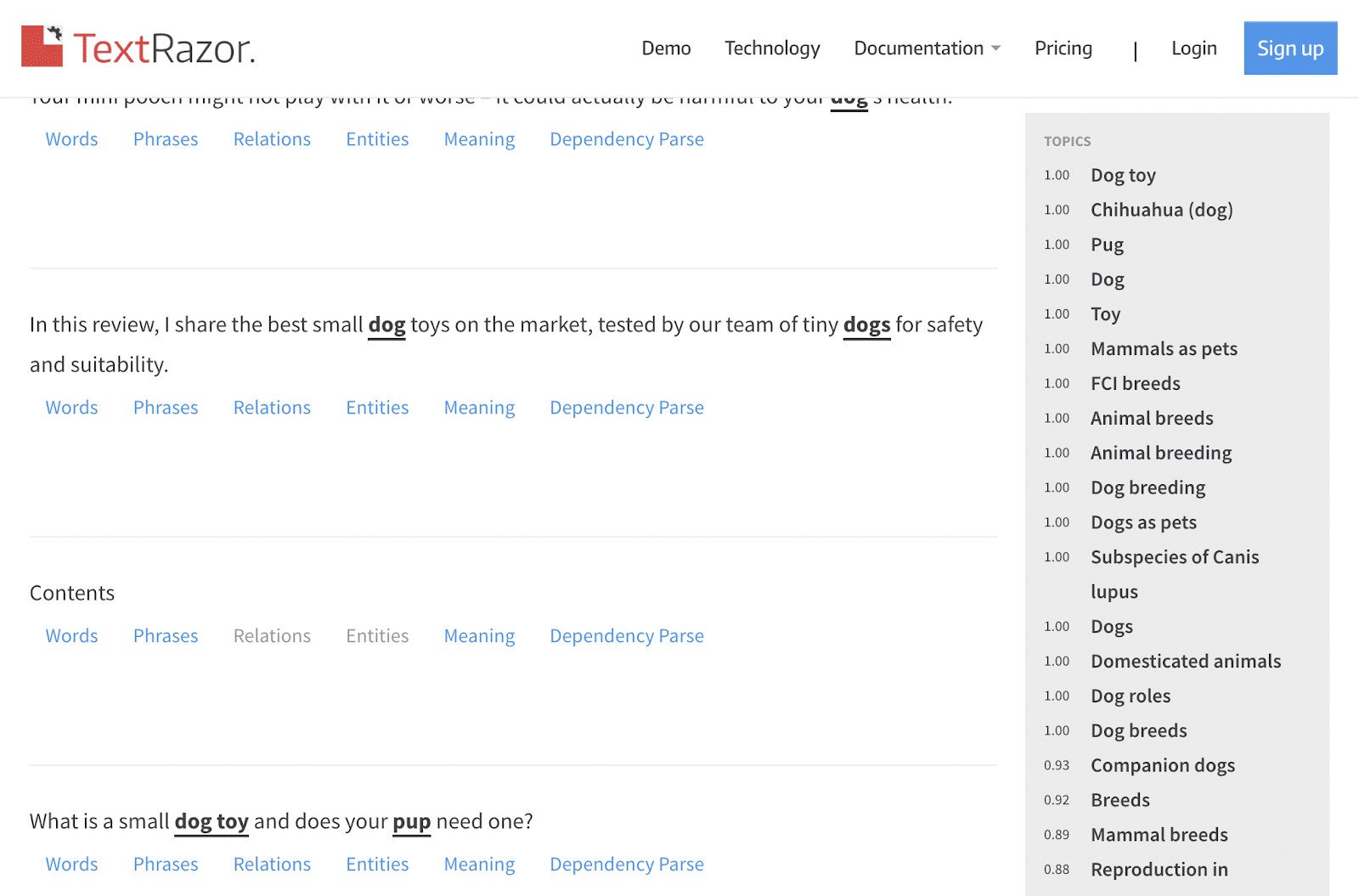
主題的得分越高,它與文章的相關性就越高。
這裡的關鍵是查看整個列表,看看它對主題相關性的評分如何。
如果有一個核心主題,例如“飛盤”,並且它的相關性分數不高,那麼將其添加到您的架構中就更重要了。
另外,您可能需要考慮重寫包含單詞“frisbee”的句子以獲得更高的顯著性或相關性分數。
在此示例中,我們將選擇以下主題或實體,然後您將獲取其架構數據。
主要實體:
- 狗
- 狗玩具
次要實體:
- 奇瓦瓦州
- 約克夏犬
- 博美犬
- 西施犬
- 哈巴狗
- 飛盤
- 咀嚼玩具
- 吱吱作響的玩具
- 網球
並非側邊欄上的每個主題都代表維基百科、維基數據或 Google 中的已知實體。
因此,查看頁面左側分解的每個句子中所有粗體和下劃線的單詞非常重要。
獲取搜索營銷人員信賴的每日新聞通訊。
查看條款。
步驟 3:從 TextRazor 檢索實體 URL
接下來,在結果頁面左側找到包含第一個實體的句子。
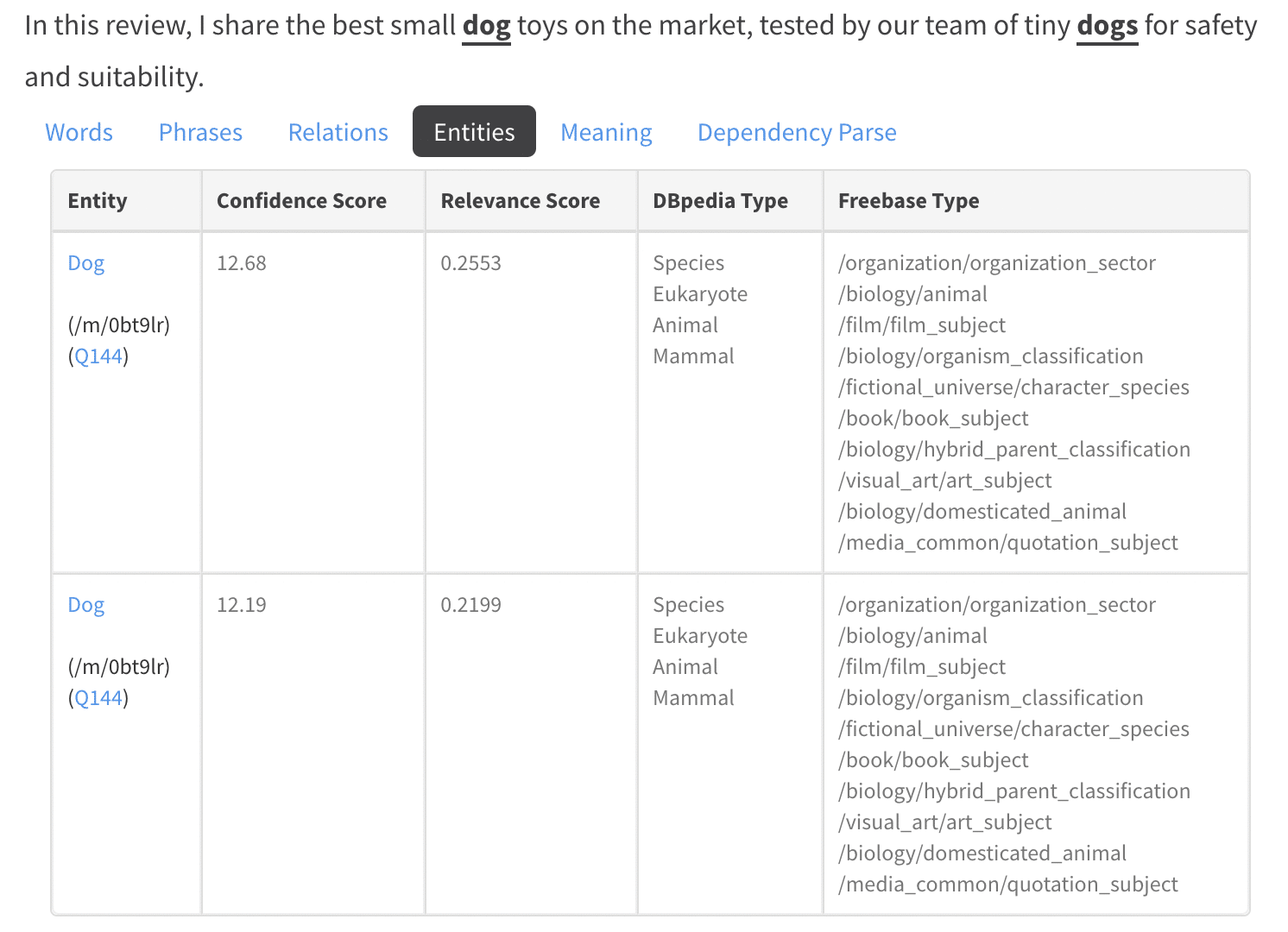
在此示例中,我們選擇“dog”作為實體。

接下來,單擊包含單詞“dog”的句子下方的“實體”選項卡。 這將顯示該特定句子中所有實體的列表。
我們需要復制該實體的所有實體 URL 並將其臨時存儲在文檔或電子表格中。
右鍵單擊列表中的第一個實體並複制其維基百科鏈接。 在這種情況下,它是:
- http://en.wikipedia.org/wiki/Dog
然後,找到相應的 Google 實體(應以“ /m/ ”開頭)並複制 ID。 在本例中,它是 ( /m/0bt9lr )
將 Google 實體 ID 添加到此 Google 搜索網址的末尾:
- https://google.com/search?&kgmid=
所以它看起來像:
- https://google.com/search?&kgmid=/m/0bt9lr
繼續並單擊此按鈕以驗證搜索結果頁面是否顯示查詢“dog”的結果。 很酷,對吧?
最後,找到 Wikidata 實體(通常以字母 Q 開頭)並複制其鏈接(例如,http://wikidata.org/wiki/Q144)。
您需要對列表中的每個實體重複此確切過程。 如果您發現這是您想要更多自動化的東西,TextRazor 確實有一個可以使用的 API。
步驟 4:將實體 URL 合併到架構中
現在您已經收集了每個實體的 Wikipedia、Google 和 Wikidata URL,您可以將它們集成到名為“about”的 JSON 架構中,該架構應嵌套在主架構下,例如“Article”。
每個實體都遵循以下結構:
"about": [ { "@type": "Thing", "name": "Dog", "sameAs": "https://google.com/search?&kgmid=/m/0bt9lr" }, { "@type": "Thing", "name": "Dog", "sameAs": "http://en.wikipedia.org/wiki/Dog" }, { "@type": "Thing", "name": "Dog", "sameAs": "http://wikidata.org/wiki/Q144" } ]如果您使用 Schema.org 進行驗證,它應該如下所示:
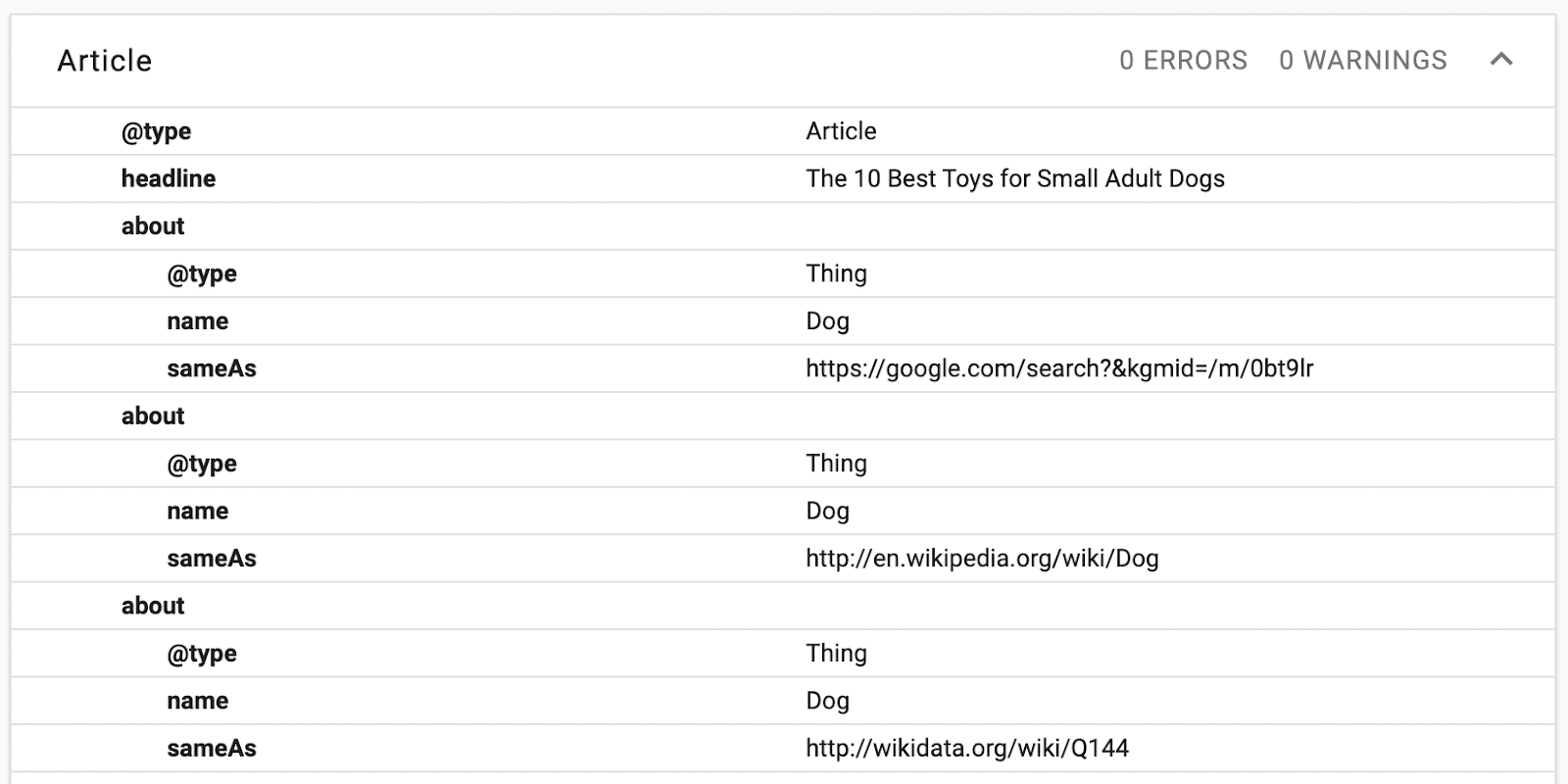
對所有實體重複此過程。
第 5 步:將架構添加到您的 WordPress 主題
這是事情變得更加技術性的地方,您可能需要程序員的幫助或嘗試 ChatGPT。
接下來,我們需要添加 PHP 代碼來存儲所有這些實體及其架構標記。
好消息是,一旦為實體生成了架構,就無需再次執行此操作。
我為我的 WordPress 網站編碼的方式是將 WordPress“標籤”與每個實體相關聯。
例如,我有一個名為“Dog”的 WordPress 標籤,任何有關狗的文章都會分配此標籤。
發生這種情況時,WordPress 代碼會自動顯示狗實體架構。
最酷的部分是,您可以向 WordPress 帖子或頁面添加任意數量的標籤,因此只需單擊按鈕即可將任意數量的相關實體加載到帖子中。
這是一個很好的 ChatGPT 提示,可以用來生成此代碼:

如果您使用像 Yoast SEO 這樣的插件,您將需要調整提示以將其合併到 JSON 格式中。
第 6 步:為您的文章分配標籤
一旦您準備好 PHP 代碼,您就可以向您的文章添加標籤。
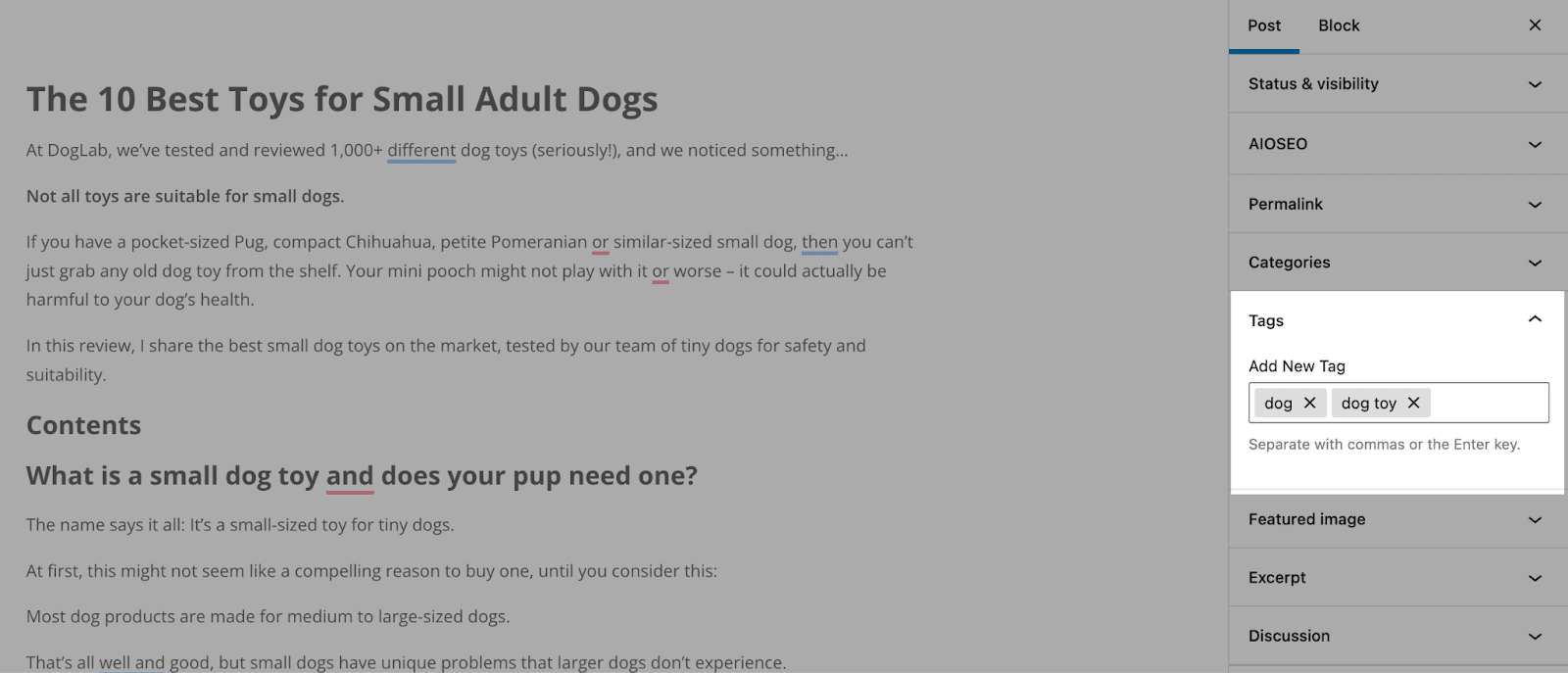
前往您的 WordPress 儀表板並確保您的文章(在本例中為“小型成年犬的最佳玩具”)已分配有適當的標籤(例如“狗”)。
這個例子中最酷的部分是,一旦我用“狗”標記任何現有文章,所有這些文章都將立即更新。
第7步:沖洗並重複
對您想要包含在架構標記中的任何其他實體(例如,“玩具”、“吉娃娃”、“約克夏犬”等)重複此過程。
將實體合併到架構標記中
將實體集成到架構標記中並不需要在自然搜索中排名第一。 然而,它可以幫助您對沖長期 SEO 賭注。
作家和人工智能並不完美。 書寫和解釋頁面上的文本並不總是完美的。 這意味著文章主要主題的相關性和重要性可能會減少或被忽略。
如果您對此持觀望態度,請對其進行測試,看看它如何適用於您的網站。 在您的網站上找到四篇主題相關的文章,並為每篇文章添加至少 5 到 10 個實體。
您可以僅手動編輯測試文章的架構。 如果效果良好,您可以將其更深入地集成到您網站的代碼中或嘗試 WordLift。
本文表達的觀點是客座作者的觀點,並不一定是搜索引擎土地的觀點。 此處列出了工作人員作者。