
實體 SEO:權威指南
已發表: 2023-04-06本文由Andrew Ansley合著。
事物,而不是字符串。 如果您以前沒有聽說過,它來自一篇宣布知識圖譜的著名 Google 博客文章。
距離發布 11 週年只有一個月的時間,但許多人仍然難以理解“事物,而非字符串”對於 SEO 的真正含義。
引用是試圖傳達谷歌了解事物,不再是簡單的關鍵字檢測算法。
2012 年 5 月,可以說實體 SEO 誕生了。 借助半結構化和結構化知識庫,谷歌的機器學習可以理解關鍵字背後的含義。
語言的歧義性終於有了一個長久之計。
因此,如果實體對谷歌來說已經很重要了十多年,為什麼 SEO 仍然對實體感到困惑?
好問題。 我看到四個原因:
- 實體 SEO 作為一個術語尚未廣泛使用,SEO 無法對其定義感到滿意,因此將其納入他們的詞彙表。
- 針對實體的優化與舊的以關鍵字為中心的優化方法有很大的重疊。 結果,實體與關鍵字混淆了。 最重要的是,尚不清楚實體如何在 SEO 中發揮作用,當谷歌談到這個主題時,“實體”一詞有時可以與“主題”互換。
- 理解實體是一項無聊的任務。 如果您想深入了解實體,則需要閱讀一些 Google 專利並了解機器學習的基礎知識。 實體 SEO 是一種更加科學的 SEO 方法——科學並不適合所有人。
- 雖然 YouTube 對知識傳播產生了巨大影響,但它也使許多學科的學習體驗變得扁平化。 在平台上最成功的創作者在教育觀眾時歷來採取簡單的方式。 因此,內容創建者直到最近才在實體上花費太多時間。 正因為如此,你需要從 NLP 研究人員那裡了解實體,然後你需要將這些知識應用到 SEO 中。 專利和研究論文是關鍵。 這再次強化了上面的第一點。
本文解決了所有阻礙 SEO 完全掌握基於實體的 SEO 方法的四個問題。
通過閱讀本文,您將了解到:
- 實體是什麼以及為什麼它很重要。
- 語義搜索的歷史。
- 如何識別和使用 SERP 中的實體。
- 如何使用實體對 Web 內容進行排名。
為什麼實體很重要?
實體 SEO 是搜索引擎在選擇要排名的內容和確定其含義方面走向的未來。
將此與基於知識的信任相結合,我相信實體 SEO 將成為未來兩年 SEO 的未來。
實體示例
那麼如何識別實體呢?
SERP 有幾個您可能見過的實體示例。
最常見的實體類型與位置、人員或企業相關。
也許 SERP 中實體的最佳示例是意圖集群。 對一個主題了解得越多,這些搜索功能就會出現得越多。
有趣的是,當您知道如何執行以實體為中心的 SEO 活動時,單個 SEO 活動可以改變 SERP 的外觀。
維基百科條目是實體的另一個例子。 維基百科提供了與實體相關的信息的一個很好的例子。
從左上角可以看出,該實體具有與“魚”相關的各種屬性,從解剖結構到對人類的重要性。
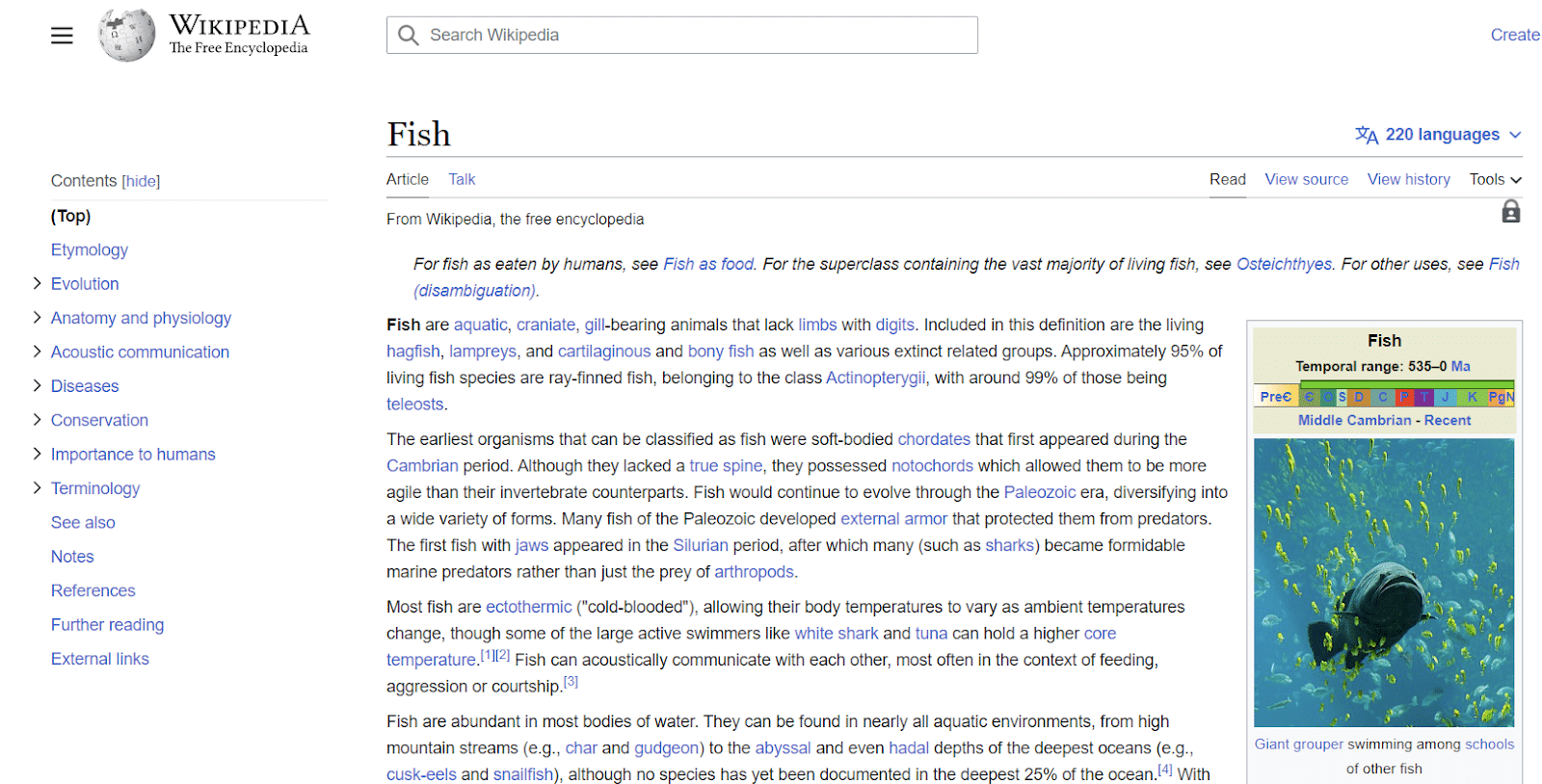
雖然維基百科包含關於某個主題的許多數據點,但它絕不是詳盡無遺的。
什麼是實體?
實體是唯一可識別的對像或以其名稱、類型、屬性和與其他實體的關係為特徵的事物。 實體只有在實體目錄中存在時才被認為存在。
實體目錄為每個實體分配一個唯一的 ID。 我的代理機構擁有使用與每個實體關聯的唯一 ID 的程序化解決方案(服務、產品和品牌都包括在內)。
如果某個詞或短語不在現有目錄中,並不意味著該詞或短語不是實體,但您通常可以通過目錄中存在某物來判斷它是否是實體。
值得注意的是,維基百科並不是決定某物是否為實體的決定因素,但該公司以其實體數據庫而聞名。
談論實體時可以使用任何目錄。 通常,實體是人、地點或事物,但也可以包括想法和概念。
實體目錄的一些示例包括:
- 維基百科
- 維基數據
- 數據庫百科
- 免費基地
- 八子

實體有助於彌合非結構化數據和結構化數據世界之間的鴻溝。
它們可用於在語義上豐富非結構化文本,而文本源可用於填充結構化知識庫。
識別文本中的實體提及並將這些提及與知識庫中的相應條目相關聯稱為實體鏈接任務。
實體可以讓人類和機器更好地理解文本的含義。
雖然人類可以根據提及實體的上下文相對容易地解決實體的歧義,但這給機器帶來了許多困難和挑戰。
實體的知識庫條目總結了我們對該實體的了解。
隨著世界不斷變化,新的事實也在不斷湧現。 跟上這些變化需要編輯和內容經理的不斷努力。 這是一項大規模的艱鉅任務。
通過分析提及實體的文檔內容,可以支持甚至完全自動化發現新事實或需要更新的事實的過程。
科學家將此稱為知識庫人口問題,這就是實體鏈接很重要的原因。
實體促進了對用戶信息需求的語義理解,如關鍵字查詢和文檔內容所表達的那樣。 因此,實體可用於改進查詢和/或文檔表示。
在擴展命名實體研究論文中,作者確定了大約 160 種實體類型。 這是列表中七個屏幕截圖中的兩個。


某些類別的實體更容易定義,但重要的是要記住概念和想法是實體。 谷歌很難自行擴展這兩個類別。
在處理模糊的概念時,您不能只用一個頁面教谷歌。 實體理解需要許多文章和許多參考資料隨著時間的推移而持續。
Google 的實體歷史
2010 年 7 月 16 日,Google 收購了 Freebase。 此次購買是導致當前實體搜索系統的第一個重要步驟。

投資 Freebase 後,Google 意識到 Wikidata 有更好的解決方案。 谷歌隨後致力於將 Freebase 合併到維基數據中,這項工作遠比預期困難。
五位 Google 科學家撰寫了一篇題為“從 Freebase 到 Wikidata:大遷移”的論文。 關鍵要點包括。
“Freebase 建立在對象、事實、類型和屬性的概念之上。 每個 Freebase 對像都有一個穩定的標識符,稱為“mid”(機器 ID)。
“維基數據的數據模型依賴於項目和陳述的概念。 一個物品代表一個實體,有一個穩定的標識符,稱為“qid”,並且可能有多種語言的標籤、描述和別名; 其他維基媒體項目中關於該實體的進一步聲明和頁面鏈接——最著名的是維基百科。 與 Freebase 不同,維基數據聲明的目的不是編碼真實事實,而是來自不同來源的聲明,這些聲明也可能相互矛盾……”
實體是在這些知識庫中定義的,但谷歌仍然必須為非結構化數據(即博客)構建其實體知識。
Google 與 Bing 和 Yahoo 合作創建了 Schema.org 來完成這項任務。
Google 提供模式說明,以便網站管理員可以擁有幫助 Google 理解內容的工具。 請記住,Google 希望專注於事物,而不是字符串。
用谷歌的話來說:
“您可以通過在頁面上包含結構化數據,向 Google 提供有關頁面含義的明確線索,從而幫助我們。 結構化數據是一種標準化格式,用於提供有關頁面的信息並對頁面內容進行分類; 例如,在食譜頁面上,配料是什麼、烹飪時間和溫度、卡路里等等。”
谷歌繼續說:
“您必須包含一個對象的所有必需屬性,該對象才有資格出現在具有增強顯示功能的 Google 搜索中。 通常,定義更多推薦功能可以使您的信息更有可能出現在具有增強顯示效果的搜索結果中。 然而,更重要的是提供更少但完整和準確的推薦屬性,而不是試圖為每個可能的推薦屬性提供不太完整、格式錯誤或不准確的數據。”
關於模式可以說更多,但足以說模式是 SEO 尋求使頁面內容對搜索引擎清晰的令人難以置信的工具。
最後一塊拼圖來自 Google 的博客公告,標題為“改進未來 20 年的搜索”。
文檔相關性和質量是本公告背後的主要理念。 Google 用於確定頁面內容的第一種方法完全集中在關鍵字上。
谷歌隨後添加了主題層來進行搜索。 這一層是通過知識圖和系統地在網絡上抓取和構建數據而實現的。
這將我們帶到了當前的搜索系統。 在不到 10 年的時間裡,谷歌從 5.7 億個實體和 180 億個事實發展到 8000 億個事實和 80 億個實體。 隨著這個數字的增長,實體搜索得到改進。
實體模型是如何改進以前的搜索模型的?
傳統的基於關鍵字的信息檢索 (IR) 模型具有固有的局限性,即無法檢索與查詢沒有明確術語匹配的(相關)文檔。
如果您使用ctrl + f在頁面上查找文本,您使用的是類似於傳統的基於關鍵字的信息檢索模型。
每天都有大量的數據發佈在網絡上。
谷歌根本不可能理解每個詞、每個段落、每篇文章和每個網站的含義。
相反,實體提供了一種結構,谷歌可以從中最大限度地減少計算負荷,同時提高理解力。
“基於概念的檢索方法試圖通過依靠輔助結構在更高級別的概念空間中獲取查詢和文檔的語義表示來應對這一挑戰。 此類結構包括受控詞彙表(詞典和敘詞表)、本體和知識庫中的實體。”
–面向實體的搜索,第 8.3 章
Krisztian Balog 是關於實體的權威著作,他確定了傳統信息檢索模型的三種可能解決方案。
- 基於擴展:使用實體作為擴展具有不同術語的查詢的來源。
- 基於投影:通過將查詢和文檔投影到實體的潛在空間來理解查詢和文檔之間的相關性
- 基於實體:在實體空間中獲得查詢和文檔的顯式語義表示,以增強基於術語的表示。
這三種方法的目標是通過識別與查詢密切相關的實體來獲得更豐富的用戶信息表示。
Balog 然後確定了六種與基於投影的實體映射方法相關的算法(投影方法涉及將實體轉換為三維空間並使用幾何測量矢量)。
- 顯式語義分析 (ESA) :給定單詞的語義由一個向量描述,該向量存儲單詞與維基百科派生概念的關聯強度。
- 潛在實體空間模型(LES) :基於生成概率框架。 文檔的檢索分數被認為是潛在實體空間分數和原始查詢似然分數的線性組合。
- EsdRank: EsdRank 用於對文檔進行排名,結合使用查詢實體和實體文檔功能。 這些分別對應於之前 LES 的查詢投影和文檔投影組件的概念。 使用判別式學習框架,還可以輕鬆合併其他信號,例如實體流行度或文檔質量
- 顯式語義排序(ESR):顯式語義排序模型結合了來自知識圖的關係信息,以實現實體空間中的“軟匹配”。
- 詞實體二重奏框架:這結合了基於術語和基於實體的表示之間的跨空間交互,導致四種類型的匹配:查詢術語到文檔術語、查詢實體到文檔術語、查詢術語到文檔實體和查詢實體記錄實體。
- 基於注意力的排名模型: 這是迄今為止描述起來最複雜的一個。
這是 Balog 寫的:
“一共設計了四個attention features,針對每個query entity提取出來。 實體歧義特徵旨在表徵與實體註釋相關的風險。 它們是:(1)表面形式被鏈接到不同實體的概率的熵(例如,在維基百科中),(2)被註釋的實體是否是表面形式最流行的意義(即具有最高的共性)分數,以及 (3) 給定表面形式最可能和第二可能候選之間的共性分數差異。第四個特徵是接近度,它定義為查詢實體與嵌入空間中的查詢之間的餘弦相似度. 具體來說,使用 skip-gram 模型在語料庫上訓練聯合實體-術語嵌入,其中實體提及被相應的實體標識符替換。查詢的嵌入被視為查詢術語嵌入的質心。

目前,重要的是對這六種以實體為中心的算法有表面的熟悉。
主要的收穫是存在兩種方法:將文檔投影到潛在實體層和文檔的顯式實體註釋。
三種數據結構
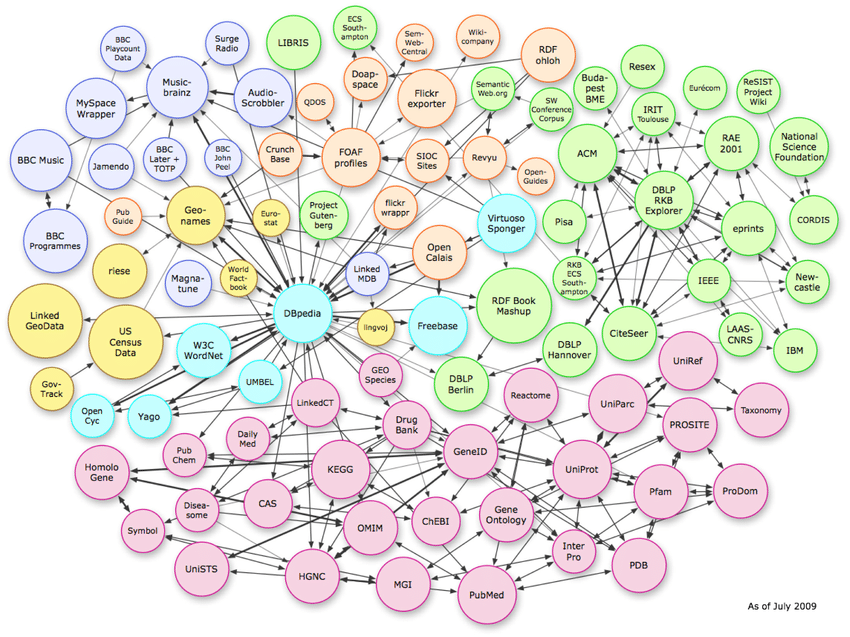
上圖顯示了向量空間中存在的複雜關係。 雖然該示例顯示了知識圖連接,但可以在逐頁模式級別上複製相同的模式。
要理解實體,了解算法使用的三種數據結構非常重要。
- 使用非結構化實體描述,必須識別和消除對其他實體的引用。 有向邊(超鏈接)從每個實體添加到其描述中提到的所有其他實體。
- 在半結構化設置(即維基百科)中,可能會明確提供指向其他實體的鏈接。
- 在處理結構化數據時,RDF 三元組定義了一個圖(即知識圖)。 具體來說,主體和客體資源 (URI) 是節點,謂詞是邊。
IR 分數的半結構化和分散注意力的上下文的問題是,如果文檔沒有為單個主題配置,則 IR 分數可能會被兩個不同的上下文稀釋,導致相對排名丟失到另一個文本文檔。
IR 分數稀釋涉及結構不良的詞彙關係和不良詞接近度。
相互補充的相關詞應在文檔的段落或部分中緊密使用,以更清楚地表明上下文以提高 IR 分數。
利用實體屬性和關係產生 5-20% 範圍內的相對改進。 利用實體類型的信息更有價值,相對改進從 25% 到 100% 以上不等。
用實體註釋文檔可以為非結構化文檔帶來結構,這可以幫助用關於實體的新信息填充知識庫。
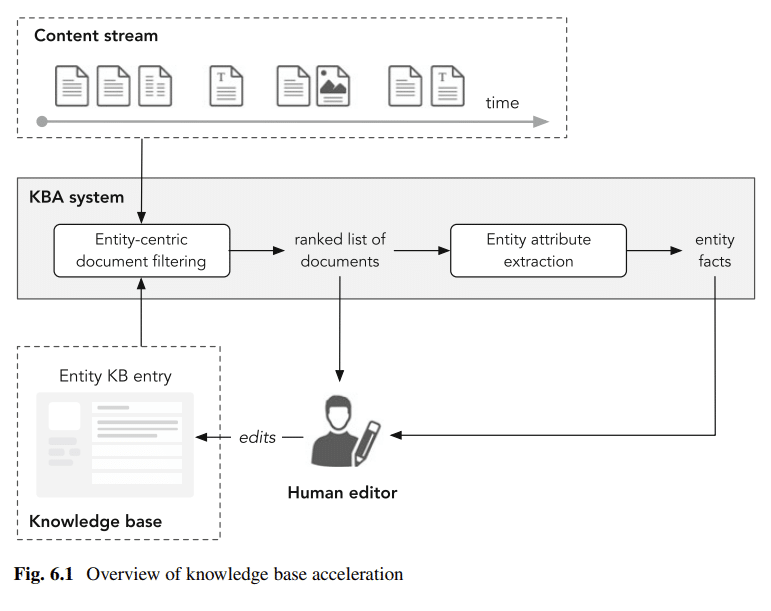
使用維基百科作為您的實體 SEO 框架
維基百科頁面的結構
- 標題(一)
- 鉛節(II.)
- 消歧鏈接(II.a)
- 信息框 (II.b)
- 介紹性文本(II.c)
- 目錄 (III.)
- 正文內容(四)
- 附錄和底質(五)
- 參考文獻和註釋 (Va)
- 外部鏈接 (Vb)
- 類別 (Vc)
大多數維基百科文章都包含介紹性文本,即“導語”,即文章的簡短摘要——通常不超過四段。 這應該以引起對文章的興趣的方式編寫。
第一句話和開頭一段特別重要。 第一句話“可以被認為是文章中描述的實體的定義。” 第一段提供了更詳盡的定義,但沒有太多細節。
鏈接的價值超出了導航目的; 他們捕捉文章之間的語義關係。 此外,錨文本是實體名稱變體的豐富來源。 維基百科鏈接可用於幫助識別和消除文本中提及的實體的歧義。
- 總結有關實體(信息框)的關鍵事實。
- 簡單的介紹。
- 內部鏈接。 給編輯的一個關鍵規則是只鏈接到實體或概念的第一次出現。
- 包括實體的所有流行同義詞。
- 類別頁面指定。
- 導航模板。
- 參考。
- 用於理解 Wiki 頁面的特殊解析工具。
- 多種媒體類型。
如何針對實體進行優化
以下是優化搜索實體時的主要考慮因素:
- 在頁面上包含語義相關的詞。
- 頁面上的單詞和短語頻率。
- 頁面上概念的組織。
- 包括頁面上的非結構化數據、半結構化數據和結構化數據。
- 主謂賓對 (SPO)。
- 網站上充當書頁的網絡文檔。
- 在網站上組織網絡文檔。
- 在 web 文檔中包含概念,這些概念是實體的已知特徵。
重要說明:當重點放在實體之間的關係時,知識庫通常稱為知識圖譜。
由於正在結合用戶搜索日誌和其他上下文來分析意圖,因此來自人 1 的相同搜索短語可能會產生與人 2 不同的結果。此人可能對完全相同的查詢有不同的意圖。
如果您的頁面涵蓋兩種類型的意圖,那麼您的頁面更適合網絡排名。 您可以使用知識庫的結構來指導您的查詢意圖模板(如上一節所述)。
People Also Ask、People Search For 和 Autocomplete 在語義上與提交的查詢相關,並且要么深入當前搜索方向,要么轉移到搜索任務的不同方面。
我們知道這一點,那麼我們如何針對它進行優化呢?
您的文檔應包含盡可能多的搜索意圖變體。 您的網站應包含集群的每個搜索意圖變體。 聚類依賴於三種類型的相似性:
- 詞彙相似性。
- 語義相似性。
- 單擊相似度。
話題覆蓋
它是什麼 –> 屬性列表 –> 專用於每個屬性的部分 –> 每個部分都鏈接到一篇完全專注於該主題的文章 –> 應該指定受眾並指定子部分的定義 –> 應該考慮什麼? –> 有什麼好處? –> 修飾符的好處 –> ___ 是什麼 –> 它有什麼作用? –> 如何獲得 –> 如何做 –> 誰可以做 –> 返回所有類別的鏈接

Google 提供了一種工具,可以提供顯著性分數(類似於我們使用“強度”或“置信度”一詞的方式),告訴您 Google 如何看待內容。

上面的示例來自 2018 年關於實體的 Search Engine Land 文章。
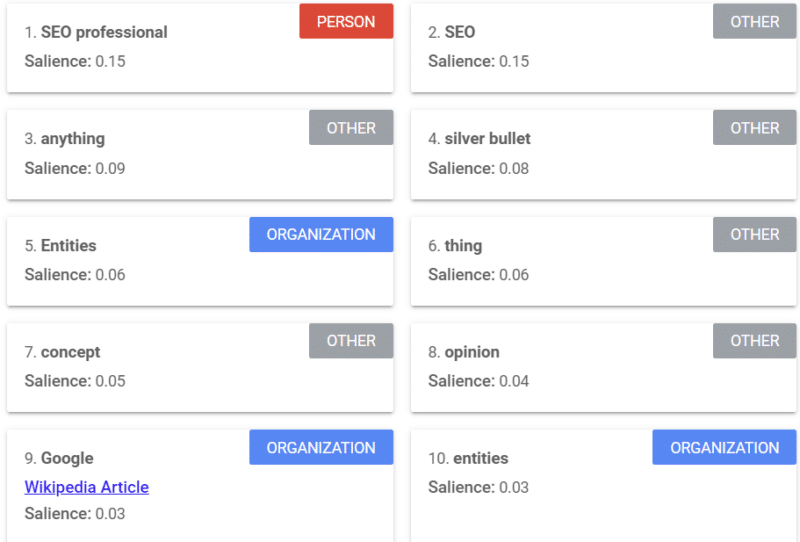
您可以從示例中看到人、其他人和組織。 該工具是 Google Cloud 的自然語言 API。
在談論實體時,每個單詞、句子和段落都很重要。 您組織想法的方式會改變 Google 對您內容的理解。
您可能包含一個關於 SEO 的關鍵字,但 Google 是否按照您希望的方式理解該關鍵字?
嘗試將一兩段放入工具中,然後重新組織和修改示例,以查看它如何增加或減少顯著性。
這種稱為“消歧”的練習對於實體來說非常重要。 語言是模棱兩可的,所以我們必須讓我們的文字對谷歌來說不那麼模棱兩可。
現代消歧方法考慮三種類型的證據:
實體和提及的優先重要性。
圍繞提及的文本與候選實體之間的上下文相似性以及文檔中所有實體鏈接決策之間的連貫性。
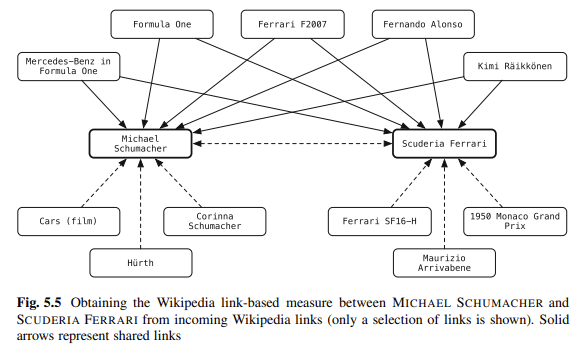
模式是我最喜歡的消除內容歧義的方法之一。 您正在將博客中的實體鏈接到知識庫。 巴洛格 說:
“[L] 將非結構化文本中的實體鏈接到結構化知識庫可以極大地增強用戶的信息消費活動能力。”
例如,文檔的讀者只需單擊一下即可獲取上下文或背景信息,並且可以輕鬆訪問相關實體。
實體註釋也可用於下游處理,以提高檢索性能或促進更好的用戶與搜索結果的交互。
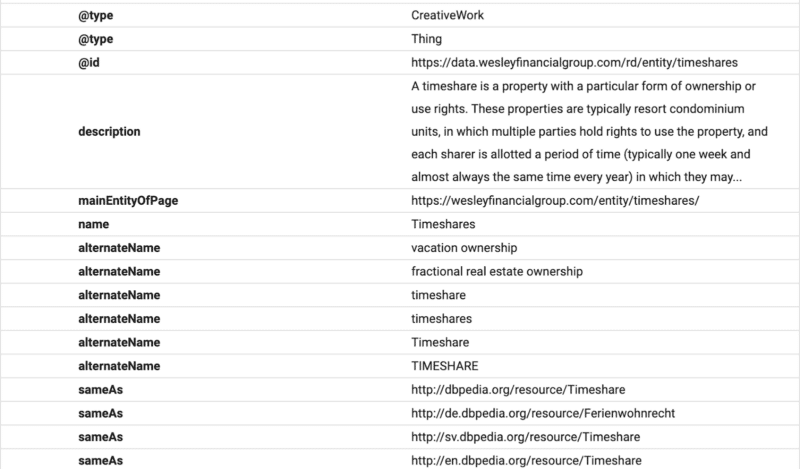
在這裡您可以看到 FAQ 內容是使用 FAQ 架構為 Google 構建的。
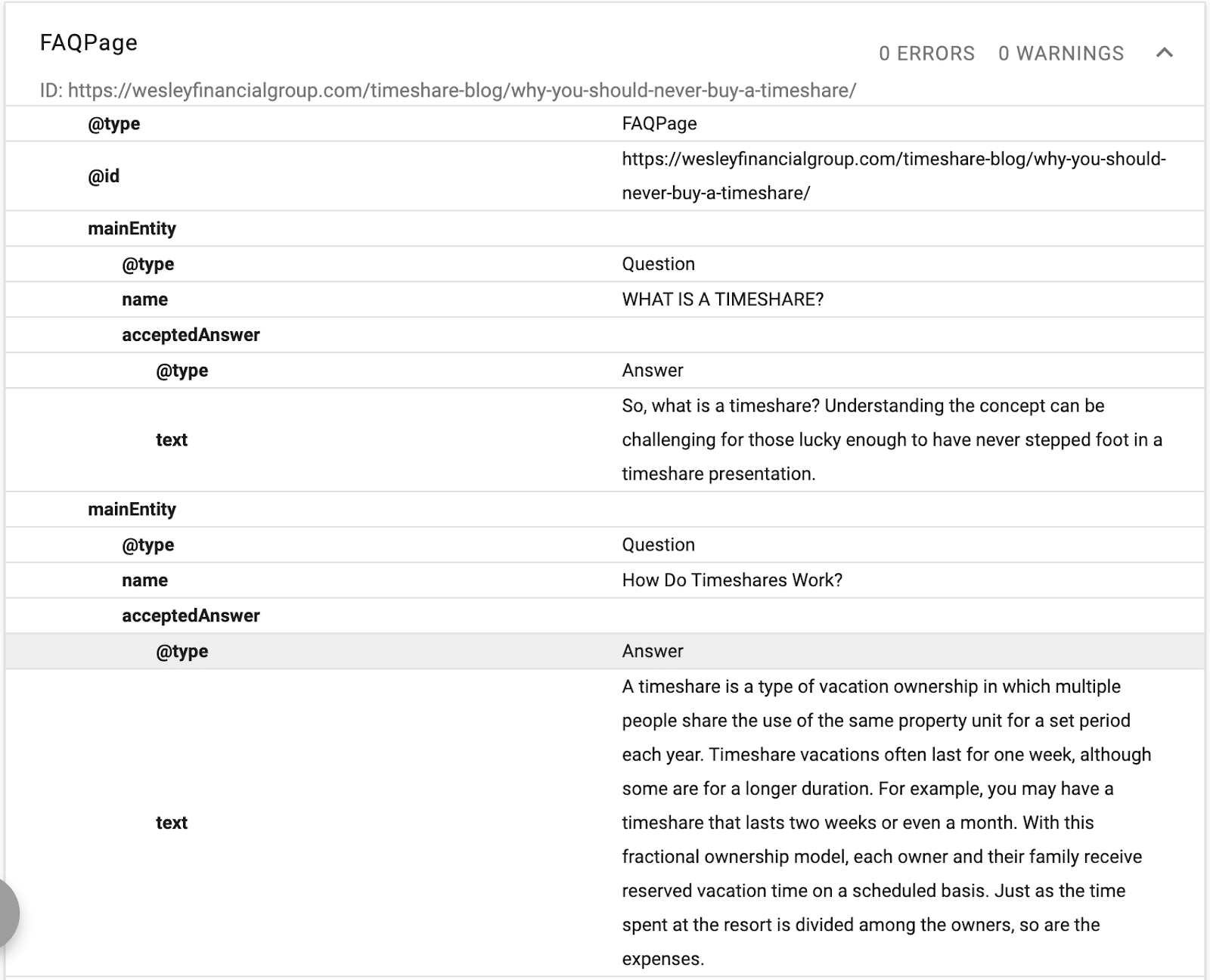
在此示例中,您可以看到模式提供了文本描述、ID 和頁面主要實體的聲明。
(請記住,Google 想要了解內容的層次結構,這就是 H1-H6 很重要的原因。)
您會看到替代名稱和與聲明相同的名稱。 現在,當谷歌閱讀內容時,它會知道將哪個結構化數據庫與文本相關聯,並且它會擁有鏈接到實體的單詞的同義詞和替代版本。
當您使用架構進行優化時,您會針對 NER(命名實體識別)進行優化,也稱為實體識別、實體提取和實體分塊。
這個想法是從事命名實體消歧>維基化>實體鏈接。
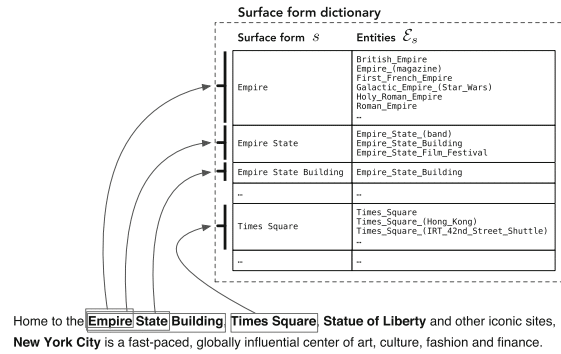
“維基百科的出現通過提供全面的實體目錄以及其他寶貴資源(特別是超鏈接、類別以及重定向和消歧頁面),促進了大規模的實體識別和消歧。”
– 面向實體的搜索
如何 超越 SEO 工具建議
大多數 SEO 使用一些頁面工具來優化他們的內容。 每個工具在識別獨特的內容機會和內容深度建議方面的能力都是有限的。
在大多數情況下,頁面工具只是匯總最熱門的 SERP 結果並創建一個平均值供您模擬。
SEO 必須記住,谷歌並不是在尋找相同的重新散列的信息。 你可以復制別人在做什麼,但獨特的信息是成為種子網站/權威網站的關鍵。
以下是 Google 如何處理新內容的簡要說明:
一旦發現文檔提到了給定的實體,就可以檢查該文檔以可能發現新的事實,利用這些新的事實可以更新該實體的知識庫條目。
巴洛格寫道:
“我們希望通過自動識別內容(新聞文章、博客文章等)來幫助編輯掌握變化,這些內容可能暗示對一組感興趣的實體(即給定編輯所關注的實體)的知識庫條目進行修改負責)。”
任何改進知識庫、實體識別和信息可抓取性的人都會得到谷歌的青睞。
在知識庫中所做的更改可以追溯到作為原始來源的文檔。
如果您提供的內容涵蓋了該主題並且您添加了一個罕見或新的深度級別,Google 可以確定您的文檔是否添加了該獨特信息。
最終,這種持續一段時間的新信息可能會使您的網站成為權威。
這不是基於域評級的權威性,而是基於主題的報導,我認為這更有價值。
使用 SEO 的實體方法,您不僅限於定位具有搜索量的關鍵字。
您需要做的就是驗證主要術語(例如“fly fishing rods”),然後您可以專注於基於良好的 ole 時尚人類思維的目標搜索意圖變化。
我們從維基百科開始。 以飛蠅釣為例,我們可以看出,釣魚網站至少應涵蓋以下概念:
- 魚類、歷史、起源、發展、技術改進、擴展、飛釣方法、鑄造、spey 鑄造、飛釣鱒魚、飛釣技術、冷水釣魚、幹飛鱒魚釣、鱒魚若蟲、靜水釣鱒魚、打鱒魚、放生鱒魚、鹹水飛蠅釣、釣具、人工蒼蠅和打結。
上面的主題來自飛釣維基百科頁面。 雖然此頁面對主題進行了很好的概述,但我想添加來自語義相關主題的其他主題想法。
對於“魚”這個主題,我們可以添加幾個額外的主題,包括詞源學、進化論、解剖學和生理學、魚類交流、魚類疾病、保護和對人類的重要性。
有沒有人將鱒魚的解剖結構與某些捕魚技術的有效性聯繫起來?
是否有一個釣魚網站涵蓋了所有魚類品種,同時將釣魚技術、魚竿和魚餌的類型與每種魚聯繫起來?
到目前為止,您應該能夠看到主題擴展是如何增長的。 在規劃內容活動時請記住這一點。
不要只是複述。 增加價值。 是獨一無二的。 使用本文中提到的算法作為您的指南。
結論
本文是關注實體的系列文章的一部分。 在下一篇文章中,我將深入探討圍繞實體的優化工作以及市場上一些以實體為中心的工具。
我想通過向兩個向我解釋許多這些概念的人大喊大叫來結束這篇文章。
SEO by the Sea 的 Bill Slawski 和 Holistic SEO 的 Koray Tugbert。 雖然 Slawski 不再與我們在一起,但他的貢獻繼續在 SEO 行業產生連鎖反應。
我的文章內容嚴重依賴以下來源,因為這些來源是該主題中存在的最佳資源:
- 擴展命名實體層次結構,作者:Satoshi Ketine、Kiyoshi Sudo 和 Chikashi Nobata
- Krisztian Balog 的面向實體搜索,信息檢索系列(INRE,第 39 卷)
- 帶實體檢測的查詢重寫,谷歌專利
- 優化搜索查詢,谷歌專利
- 將實體與搜索查詢相關聯,谷歌專利
本文中表達的觀點是客座作者的觀點,不一定是 Search Engine Land。 此處列出了工作人員作者。