
如何使用 Google 實體和 GPT-4 創建文章大綱
已發表: 2023-06-06在本文中,您將學習如何使用一些抓取和 Google 的知識圖來進行自動提示工程,為一篇文章生成大綱和摘要,如果寫得好,將包含許多獲得良好排名的關鍵要素。
從根本上講,我們告訴 GPT-4 根據關鍵字和他們在您選擇的排名良好的頁面上找到的頂級實體生成文章大綱。
實體按其顯著性分數排序。
“為什麼顯著性得分?” 你可能會問。
Google 在他們的 API 文檔中將顯著性描述為:
“實體的顯著性分數提供了有關該實體對整個文檔文本的重要性或中心性的信息。 接近 0 的分數不太顯著,而接近 1.0 的分數非常顯著。”
似乎是一個很好的指標,可以用來影響哪些實體應該存在於您可能想要編寫的一段內容中,不是嗎?
入門
有兩種方法可以解決這個問題:
- 花大約 5 分鐘(如果您需要設置計算機,則可能需要 10 分鐘)並從您的機器上運行腳本,或者……
- 跳轉到我創建的 Colab 並立即開始嘗試。
我偏愛第一個,但我也跳到一兩個 Colab。 😀
假設您還在這裡並希望在您自己的機器上進行此設置但尚未安裝 Python 或 IDE(集成開發環境),我將首先指導您快速閱讀如何設置您的機器以供使用木星筆記本。 時間不應超過 5 分鐘。
現在,是時候開始了!
使用 Google 實體和 GPT-4 創建文章大綱
為了讓這更容易理解,我將按如下方式格式化說明:
- 步驟:我們正在進行的步驟的簡要說明。
- 代碼:完成該步驟的代碼。
- Explanation :對代碼正在做什麼的簡短說明。
第一步:告訴我你想要什麼
在我們深入創建大綱之前,我們需要定義我們想要的東西。
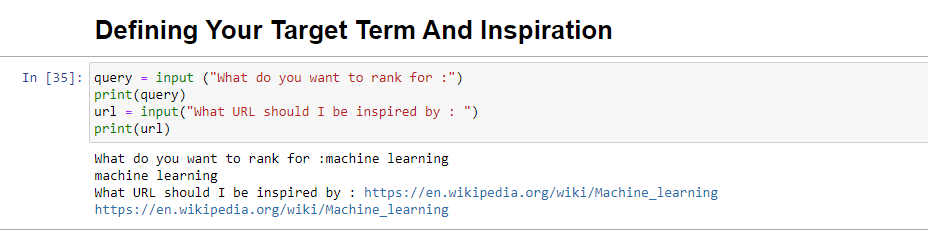
query = input ("What do you want to rank for :") print(query) url = input("What URL should I be inspired by : ") print(url)運行時,此塊將提示用戶(可能是您)輸入您希望文章排名/關於的查詢,並為您提供一個放置您想要的文章的 URL 的位置一塊受到啟發。
我會建議一篇排名不錯的文章,其格式適合您的網站,並且您認為僅憑文章的價值而不僅僅是網站的實力就值得排名。
運行時,它看起來像:
第 2 步:安裝所需的庫
接下來,我們必須安裝所有我們將用來實現奇蹟的庫。
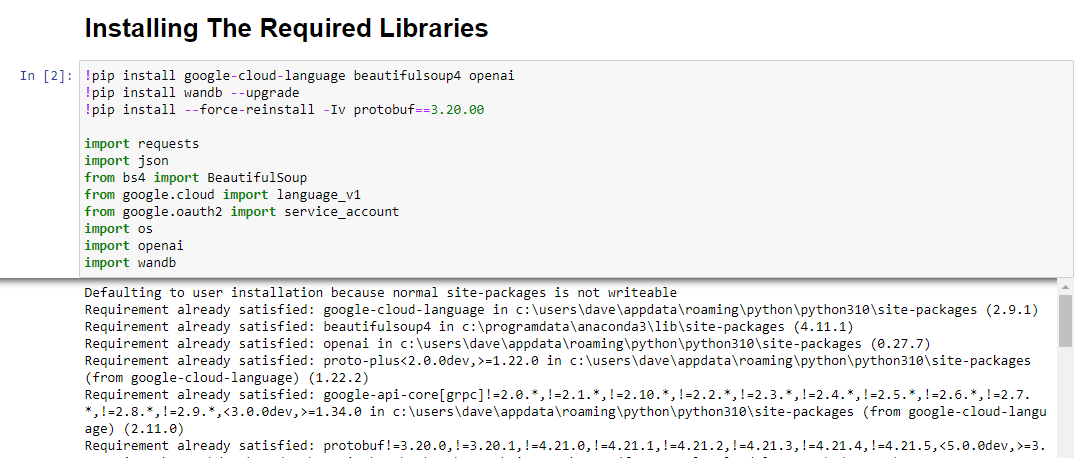
!pip install google-cloud-language beautifulsoup4 openai !pip install wandb --upgrade !pip install --force-reinstall -Iv protobuf==3.20.00 import requests import json from bs4 import BeautifulSoup from google.cloud import language_v1 from google.oauth2 import service_account import os import openai import pandas as pd import wandb我們正在安裝以下庫:
- Requests :該庫允許發出 HTTP 請求以從網站或 Web API 檢索內容。
- JSON :它提供了處理 JSON 數據的功能,包括將 JSON 字符串解析為 Python 對像以及將 Python 對象序列化為 JSON 字符串。
- BeautifulSoup :這個庫用於網絡抓取目的。 它有助於解析和導航 HTML 或 XML 文檔並從中提取相關信息。
- Google.cloud.language_v1 :它是來自谷歌云的庫,提供自然語言處理能力。 它允許對文本數據執行各種任務,如情感分析、實體識別和語法分析。
- Google.oauth2.service_account :這個庫是 Google OAuth2 Python 包的一部分。 它支持使用服務帳戶通過 Google API 進行身份驗證,這是一種授予對 Google Cloud 項目資源的有限訪問權限的方法。
- 操作系統:這個庫提供了一種與操作系統交互的方法。 它允許訪問各種功能,如文件操作、環境變量和進程管理。
- OpenAI :這個庫是 OpenAI Python 包。 它提供了一個與 OpenAI 的語言模型交互的接口,包括 GPT-4(和 3)。 它允許開發人員生成文本、執行文本完成等。
- Pandas :它是一個強大的數據處理和分析庫。 它提供數據結構和函數以有效地處理和分析結構化數據,例如表格或 CSV 文件。
- WandB :這個庫代表“權重和偏差”,是一個用於實驗跟踪和可視化的工具。 它有助於記錄和可視化機器學習實驗的指標、超參數和其他重要方面。
運行時,它看起來像這樣:
獲取搜索營銷人員所依賴的每日時事通訊。
見條款。
第 3 步:身份驗證
我將不得不暫時轉移我們的注意力,以便讓我們的身份驗證到位。 我們需要一個 OpenAI API 密鑰和谷歌知識圖譜搜索憑證。
這只需要幾分鐘。
獲取您的 OpenAI API
目前,您可能需要加入候補名單。 我很幸運能夠及早訪問 API,因此我寫這篇文章是為了幫助您在獲得 API 後儘快進行設置。
註冊圖像來自 GPT-3,一旦流程對所有人可用,將針對 GPT-4 進行更新。
在您可以使用 GPT-4 之前,您需要一個 API 密鑰來訪問它。
要獲得一個,只需轉到 OpenAI 的產品頁面,然後單擊“開始” 。
選擇您的註冊方式(我選擇了 Google)並完成驗證過程。 您需要使用可以接收此步驟文本的電話。
完成後,您將創建一個 API 密鑰。 這樣 OpenAI 就可以將您的腳本連接到您的帳戶。
他們必須知道誰在做什麼,並確定他們是否應該向您收取費用以及收取多少費用。
OpenAI 定價
註冊後,您將獲得 5 美元的信用額度,如果您只是進行試驗,這將使您走得更遠。
在撰寫本文時,過去的定價是:

創建您的 OpenAI 密鑰
要創建您的密鑰,請單擊右上角的個人資料並選擇View API keys 。
...然後您將創建您的密鑰。
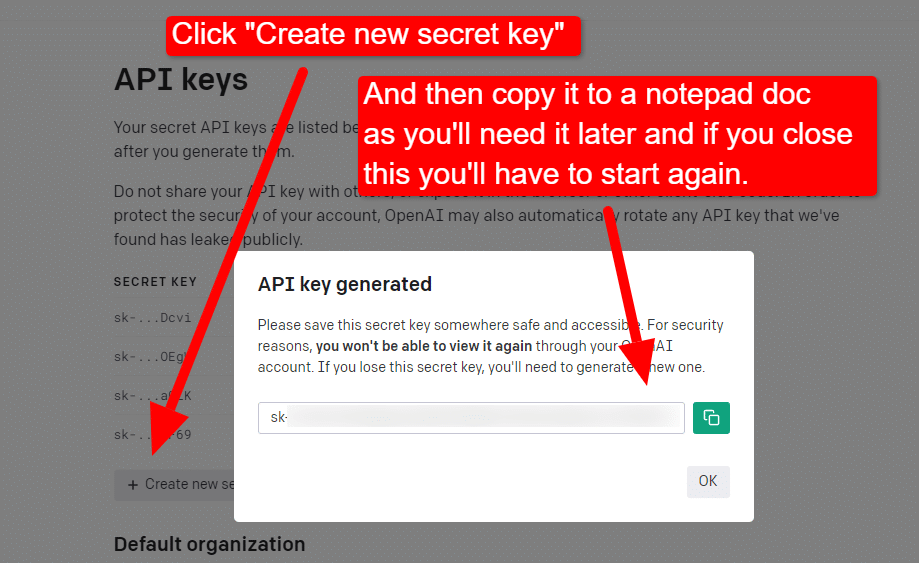
關閉燈箱後,您將無法查看您的密鑰並且必須重新創建它,因此對於此項目,只需將其複製到記事本文檔中即可使用。
注意:不要保存您的密鑰(桌面上的記事本文檔不是很安全)。 一旦你暫時使用它,關閉記事本文檔而不保存它。
獲取您的 Google Cloud 身份驗證
首先,您需要登錄您的 Google 帳戶。 (你在一個 SEO 網站上,所以我假設你有一個。🙂)
完成此操作後,如果您願意,可以查看知識圖譜 API 信息,或者直接跳轉到 API 控制台並開始使用。
一旦你在控制台:
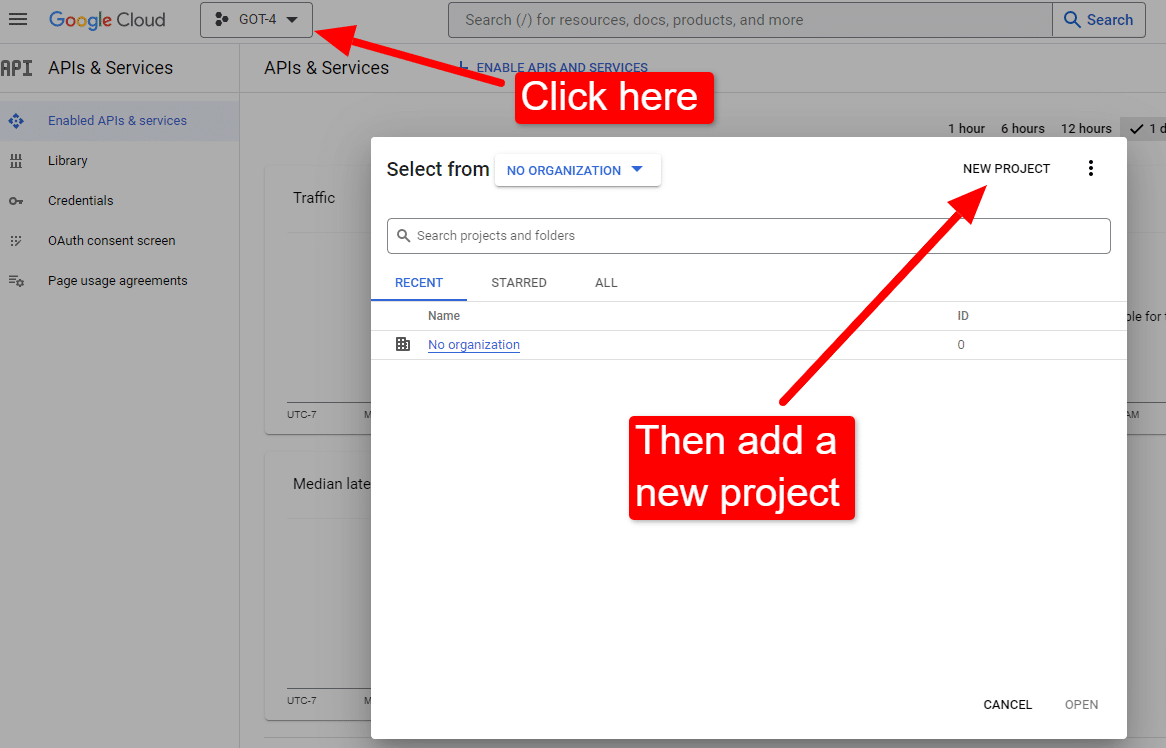
將其命名為“戴夫的精彩文章”。 你知道……很容易記住。
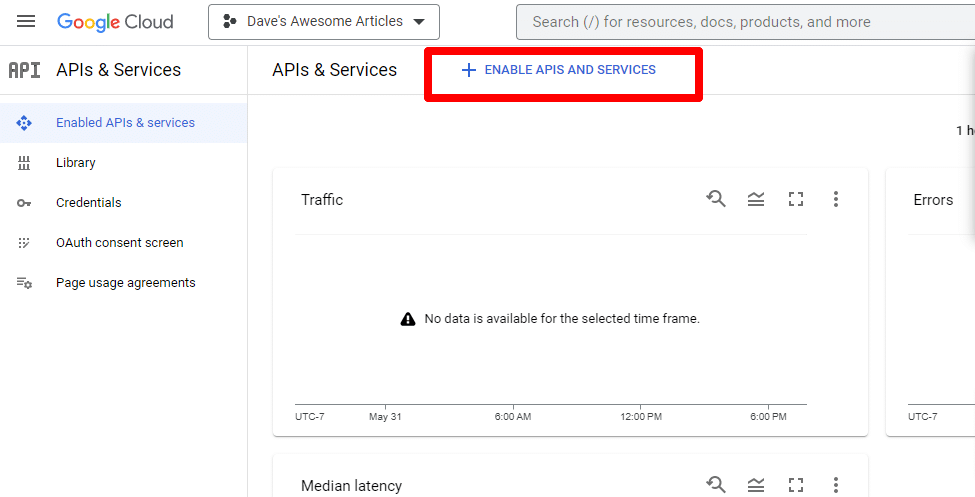
接下來,您將通過單擊啟用 API 和服務來啟用 API。
找到 Knowledge Graph Search API,並啟用它。
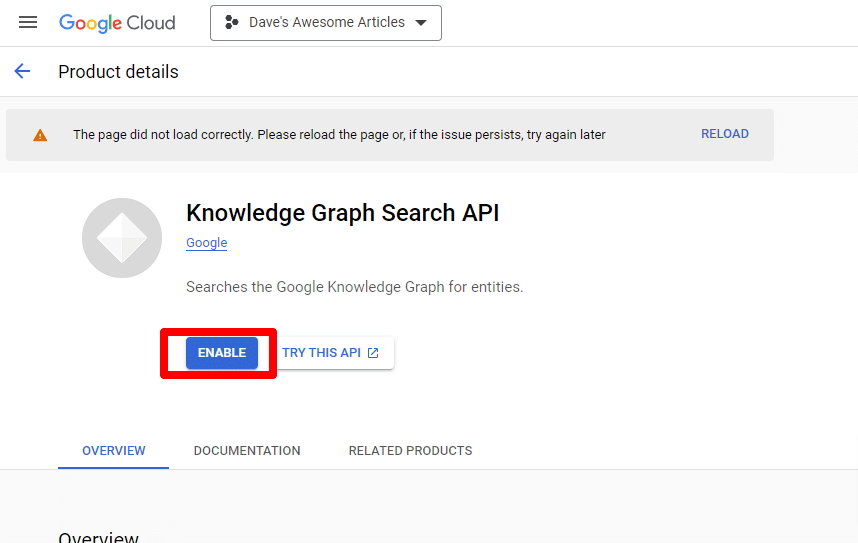
然後您將被帶回主 API 頁面,您可以在其中創建憑據:
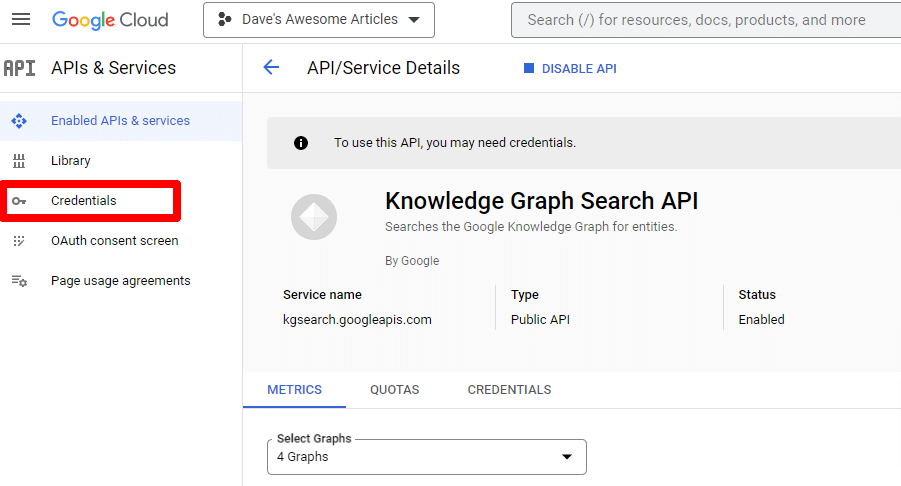
我們將創建一個服務帳戶。
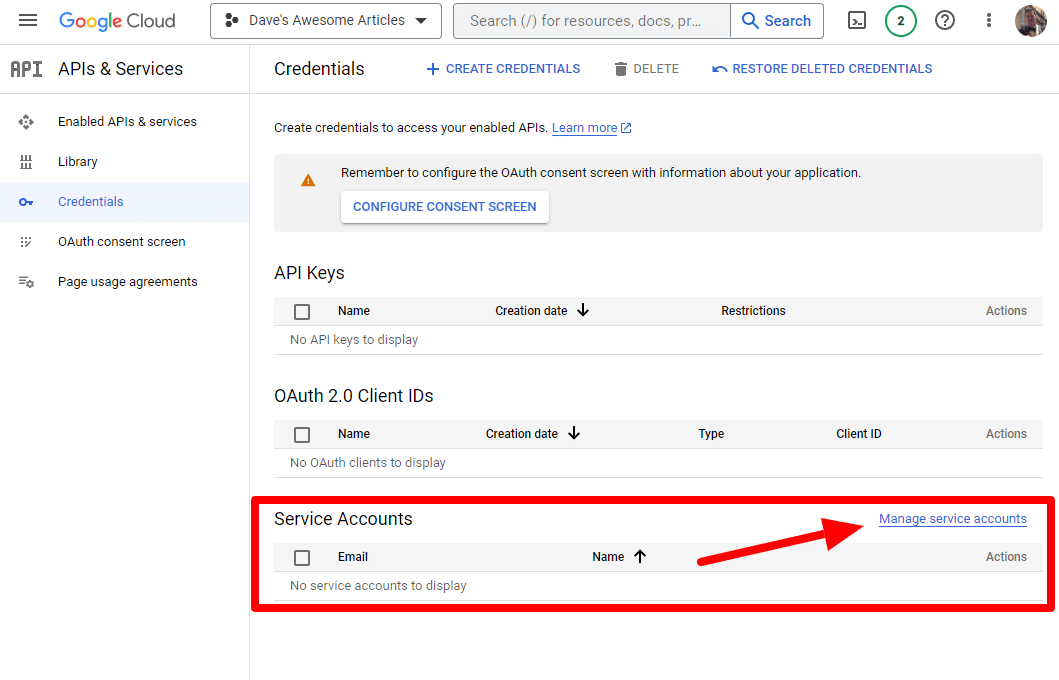
只需創建一個服務帳戶:

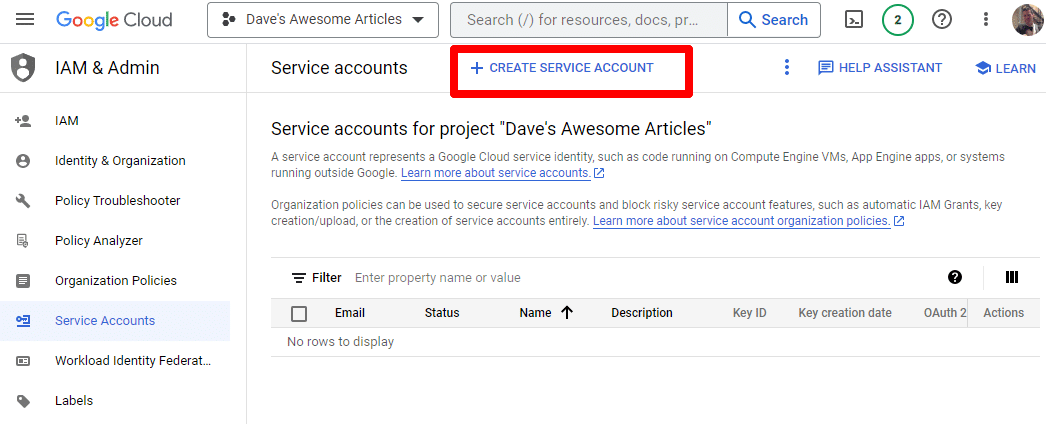
填寫必填信息:
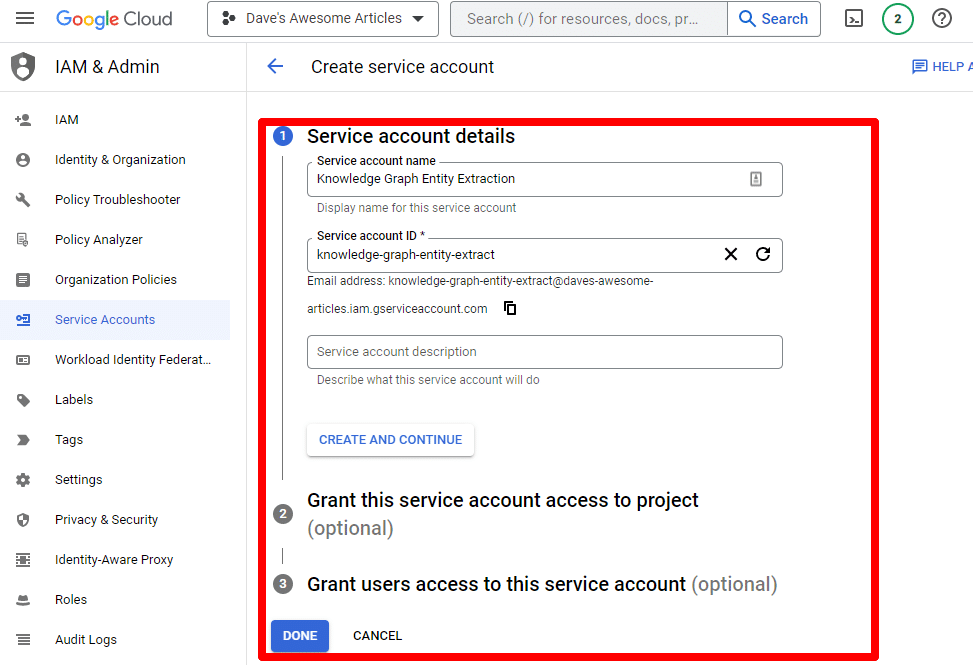
(您需要為其命名並授予其所有者權限。)
現在我們有了我們的服務帳戶。 剩下的就是創建我們的密鑰。
單擊Actions下的三個點,然後單擊Manage keys 。
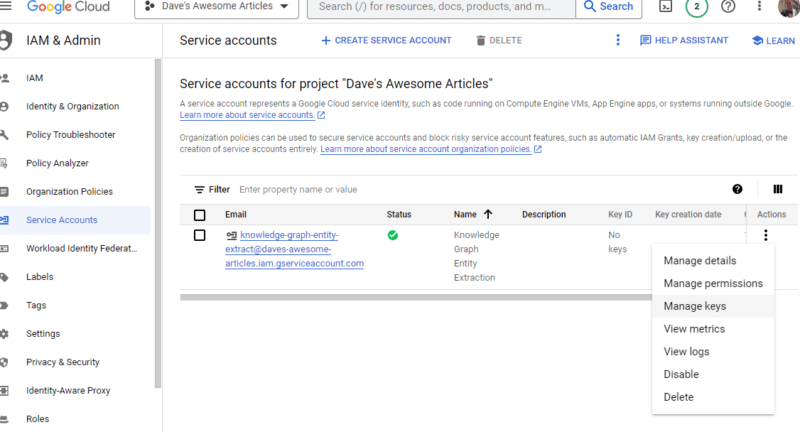
單擊添加密鑰然後創建新密鑰:
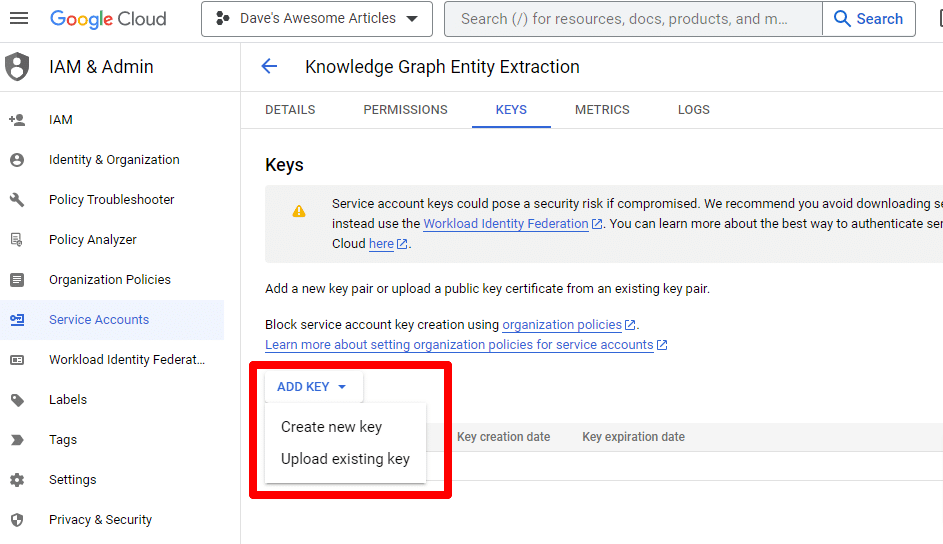
密鑰類型將是 JSON。
您會立即看到它下載到您的默認下載位置。
此密鑰將提供對您的 API 的訪問權限,因此請妥善保管它,就像您的 OpenAI API 一樣。
好吧……我們回來了。 準備好繼續我們的腳本了嗎?
現在我們有了它們,我們需要定義我們的 API 密鑰和下載文件的路徑。 執行此操作的代碼是:
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/PATH-TO-FILE/FILENAME.JSON' %env OPENAI_API_KEY=YOUR_OPENAI_API_KEY openai.api_key = os.environ.get("OPENAI_API_KEY") 您將用您自己的密鑰替換YOUR_OPENAI_API_KEY 。
您還將/PATH-TO-FILE/FILENAME.JSON替換為剛剛下載的服務帳戶密鑰的路徑,包括文件名。
運行單元,您就可以繼續了。
第 4 步:創建函數
接下來,我們將創建函數來:
- 抓取我們上面輸入的網頁。
- 分析內容並提取實體。
- 使用 GPT-4 生成文章。
#The function to scrape the web page def scrape_url(url): response = requests.get(url) soup = BeautifulSoup(response.content, "html.parser") paragraphs = soup.find_all("p") text = " ".join([p.get_text() for p in paragraphs]) return text #The function to pull and analyze the entities on the page using Google's Knowledge Graph API def analyze_content(content): client = language_v1.LanguageServiceClient() response = client.analyze_entities( request={"document": language_v1.Document(content=content, type_=language_v1.Document.Type.PLAIN_TEXT), "encoding_type": language_v1.EncodingType.UTF8} ) top_entities = sorted(response.entities, key=lambda x: x.salience, reverse=True)[:10] for entity in top_entities: print(entity.name) return top_entities #The function to generate the content def generate_article(content): openai.api_key = os.environ["OPENAI_API_KEY"] response = openai.ChatCompletion.create( messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, {"role": "user", "content": content}], model="gpt-4", max_tokens=1500, #The maximum with GPT-3 is 4096 including the prompt n=1, #How many results to produce per prompt #best_of=1 #When n>1 completions can be run server-side and the "best" used stop=None, temperature=0.8 #A number between 0 and 2, where higher numbers add randomness ) return response.choices[0].message.content.strip()這幾乎正是評論所描述的。 我們正在為上述目的創建三個函數。
敏銳的眼睛會注意到:
messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, 你可以編輯內容( You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well. )並描述你希望 ChatGPT 扮演的角色。 您還可以添加語氣(例如,“您是一位友善的作家……”)。
第 5 步:抓取 URL 並打印實體
現在我們開始動手了。 是時候:
- 抓取我們在上面輸入的 URL。
- 提取段落標籤中的所有內容。
- 通過 Google Knowledge Graph API 運行它。
- 輸出實體以進行快速預覽。
基本上,您想在這個階段看到任何東西。 如果您什麼也沒看到,請檢查其他站點。
content = scrape_url(url) entities = analyze_content(content)你可以看到第一行調用了抓取我們第一次輸入的 URL 的函數。 第二行分析內容以提取實體和關鍵指標。
analyze_content 函數的一部分還打印找到的實體列表,以供快速參考和驗證。
第 6 步:分析實體
當我第一次開始玩這個腳本時,我從 20 個實體開始,但很快發現這通常太多了。 但是默認值 (10) 對嗎?
為了找出答案,我們會將數據寫入 W&B 表以便於評估。 它將無限期地保留數據以供將來評估。
首先,您需要花大約 30 秒的時間進行註冊。 (別擔心,這類事情是免費的!)你可以在 https://wandb.ai/site 上這樣做。
完成後,執行此操作的代碼是:
run = wandb.init(project="Article Summary With Entities") columns=["Name", "Salience"] ent_table = wandb.Table(columns=columns) for entity in entities: ent_table.add_data(entity.name, entity.salience) run.log({"Entity Table": ent_table}) wandb.finish()運行時,輸出如下所示:
當您單擊鏈接查看您的跑步時,您會發現:
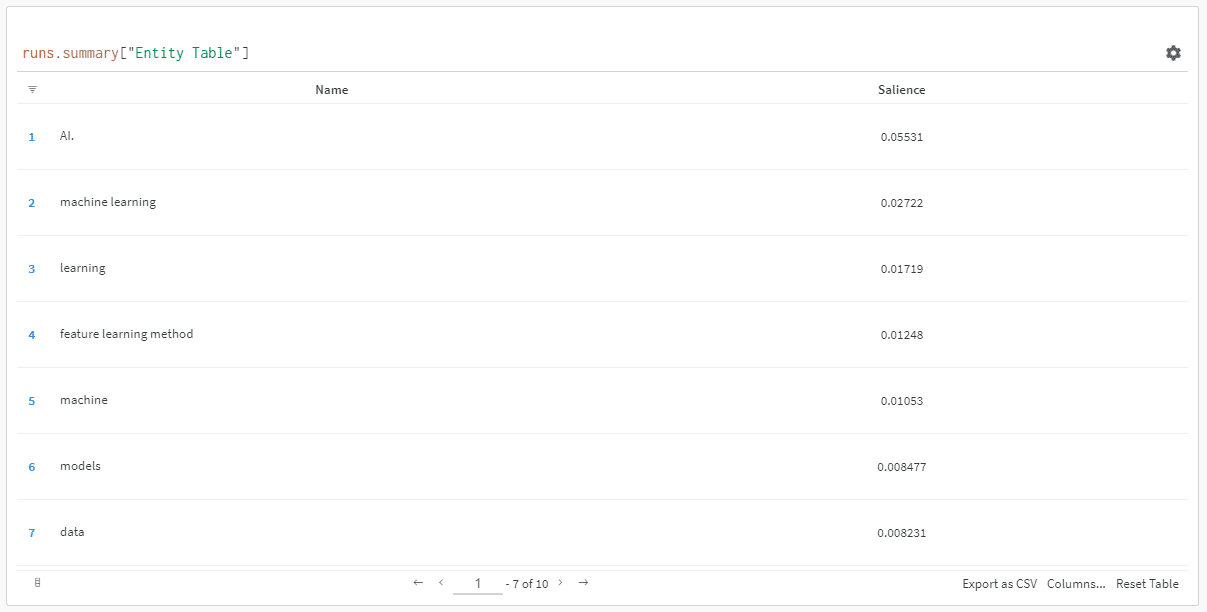
您可以看到顯著性分數下降。 請記住,此分數計算的是該術語對頁面而非查詢的重要性。
查看此數據時,您可以選擇根據顯著性調整實體數量,或者僅在看到不相關的術語彈出時調整實體數量。
要調整實體的數量,您可以前往功能單元格並編輯:
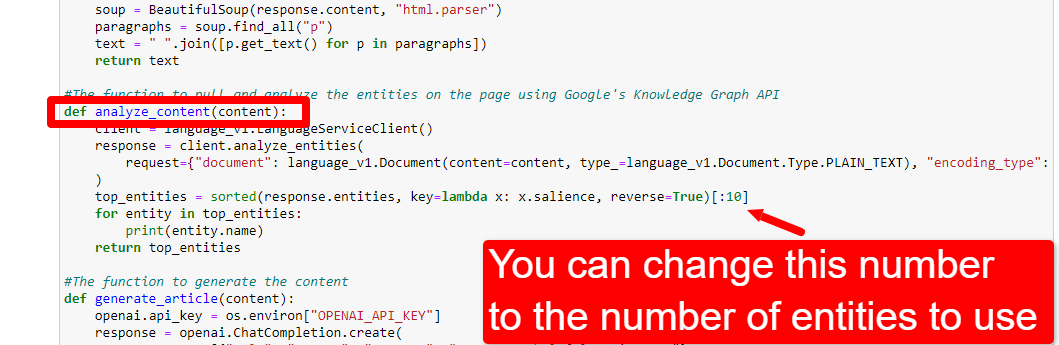
然後,您需要再次運行該單元格以及您運行的單元格以抓取和分析內容以使用新的實體計數。
第七步:生成文章大綱
您一直在等待的那一刻,就是生成文章大綱的時候了。
這分兩部分完成。 首先,我們需要通過添加單元格來生成提示:
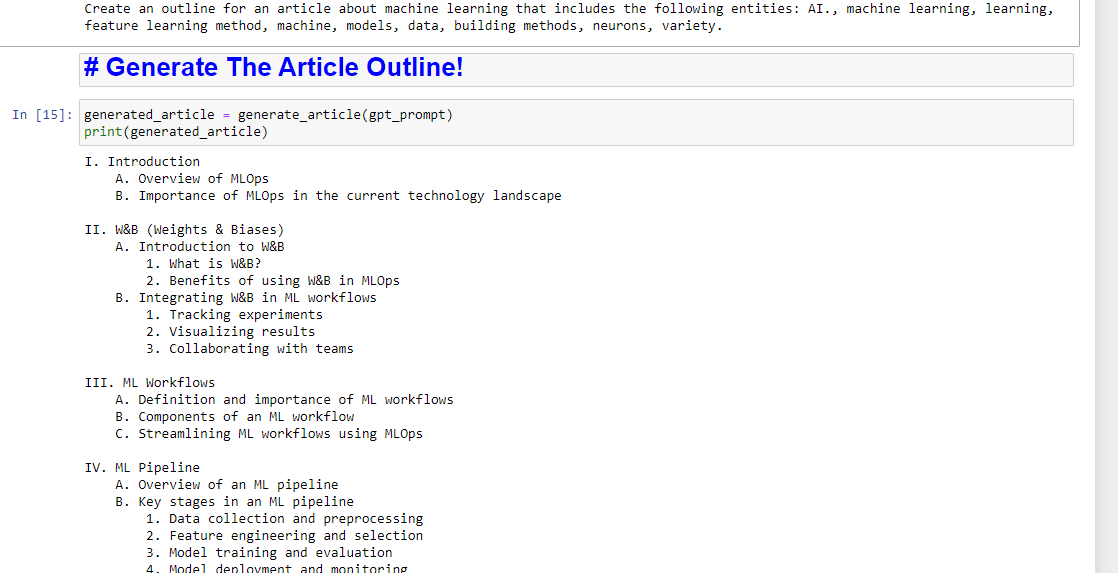
entity_names = [entity.name for entity in entities] gpt_prompt = f"Create an outline for an article about {query} that includes the following entities: {', '.join(entity_names)}." print(gpt_prompt)這實質上創建了生成文章的提示:

然後,剩下的就是使用以下內容生成文章大綱:
generated_article = generate_article(gpt_prompt) print(generated_article)這將產生類似的東西:
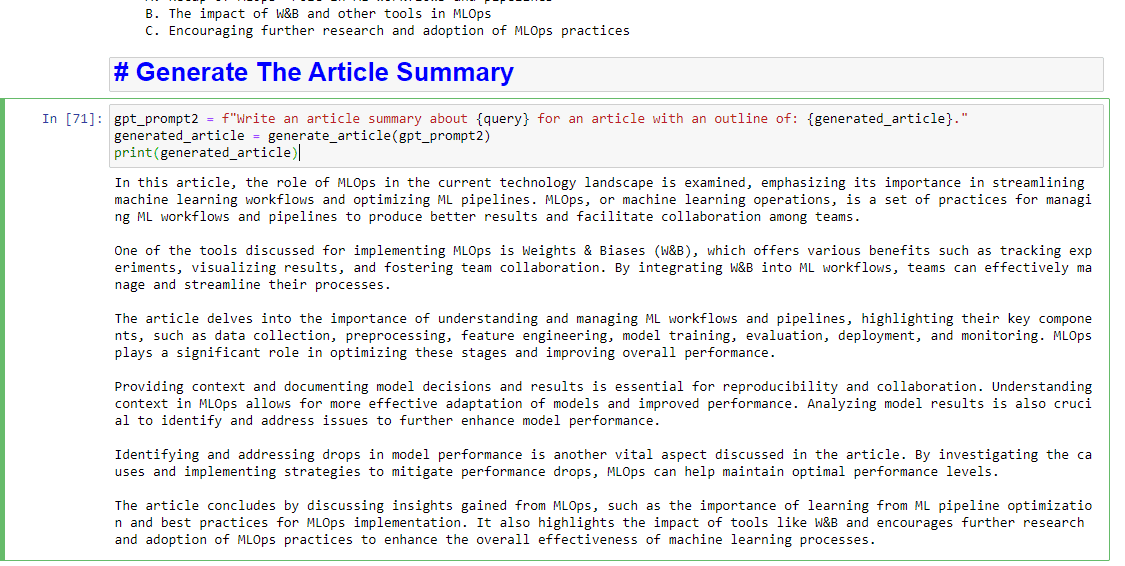
如果你還想寫一個總結,你可以添加:
gpt_prompt2 = f"Write an article summary about {query} for an article with an outline of: {generated_article}." generated_article = generate_article(gpt_prompt2) print(generated_article)這將產生類似的東西:
本文中表達的觀點是客座作者的觀點,不一定是 Search Engine Land。 此處列出了工作人員作者。