
Google 如何通過 EEAT 識別和評估作者
已發表: 2023-04-17在對搜索結果進行排名時,谷歌更加重視內容來源,特別是作者。 SERP 中的觀點、關於這個結果和關於這個作者的介紹清楚地表明了這一點。
本文探討了 Google 如何通過作者的經驗、專業知識、權威性和可信度 (EEAT) 來評估內容片段。
EEAT:谷歌的質量攻勢
谷歌強調了 EEAT 概念對於提高搜索結果質量和 SERP 用戶體驗的重要性。
頁面上的因素,如內容的一般質量、鏈接信號(即 PageRank 和錨文本)和實體級信號都起著至關重要的作用。
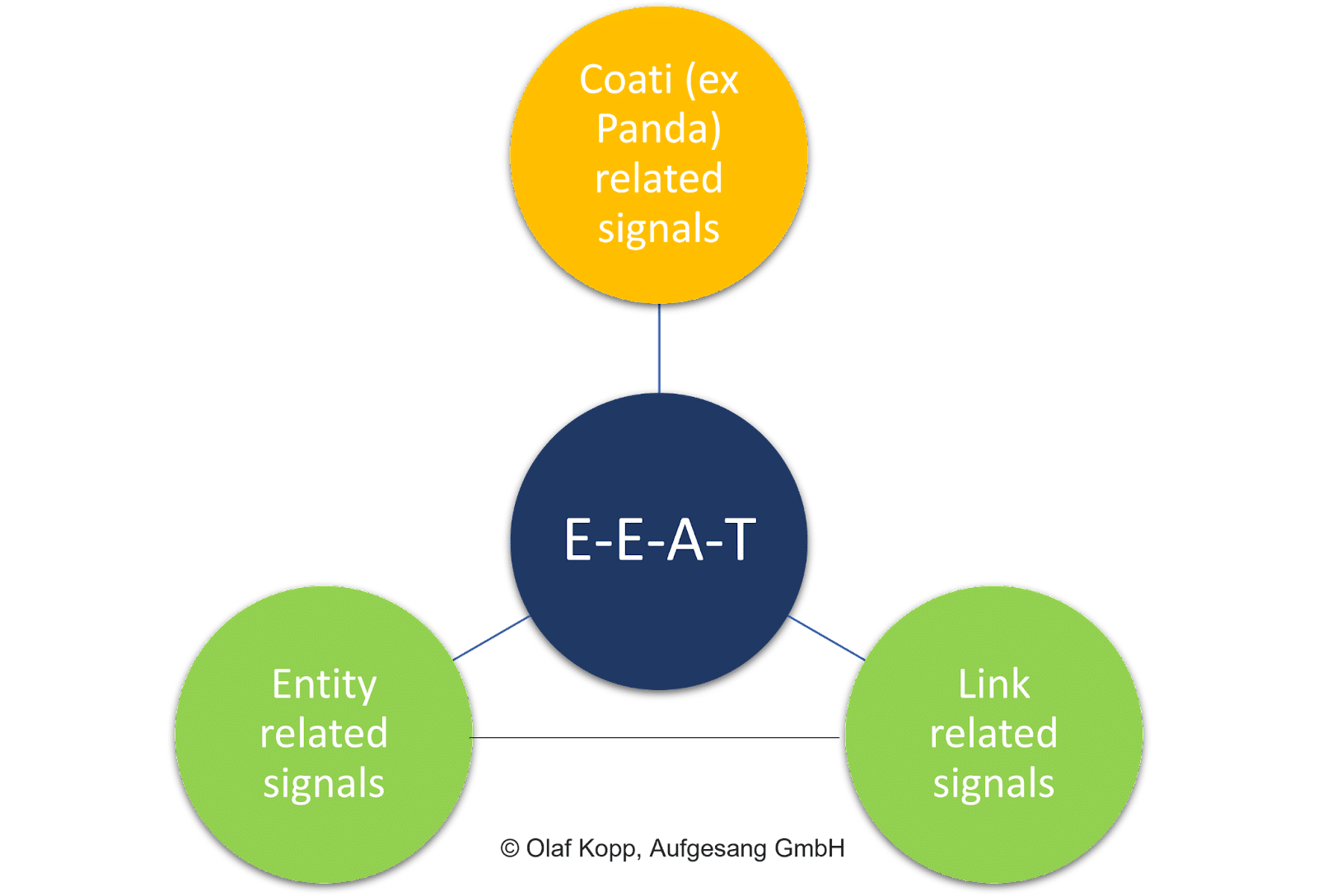
與文檔評分相反,評估單個內容不是 EEAT 的重點。
該概念有一個與域和發起者實體相關的主題參考。 它獨立於搜索意圖和個人內容本身。
最終,EEAT 是一個獨立於搜索查詢的影響因素。
EEAT主要指的是主題領域,被理解為一個評估層,用於評估與公司、組織、人員及其領域等實體相關的內容和頁外信號的集合。
作者作為內容來源的重要性
早在 (E-)EAT 之前,谷歌就試圖將內容來源的評級納入搜索排名。 例如,2009 年的 Vince 更新為品牌創建的內容提供了排名優勢。
通過像 Knol 或 Google+ 這樣早已結束的項目,谷歌試圖收集作者評級的信號(即通過社交圖譜和用戶評級)。
在過去的 20 年裡,谷歌的多項專利都直接或間接地提到了 Knol 等內容平台和 Google+ 等社交網絡。
根據 EEAT 標準評估內容片段的來源或作者是進一步提高搜索結果質量的關鍵步驟。
由於人工智能生成的內容和經典垃圾郵件數量眾多,谷歌將劣質內容納入搜索索引毫無意義。
它在信息檢索過程中索引和處理的內容越多,需要的計算能力就越大。
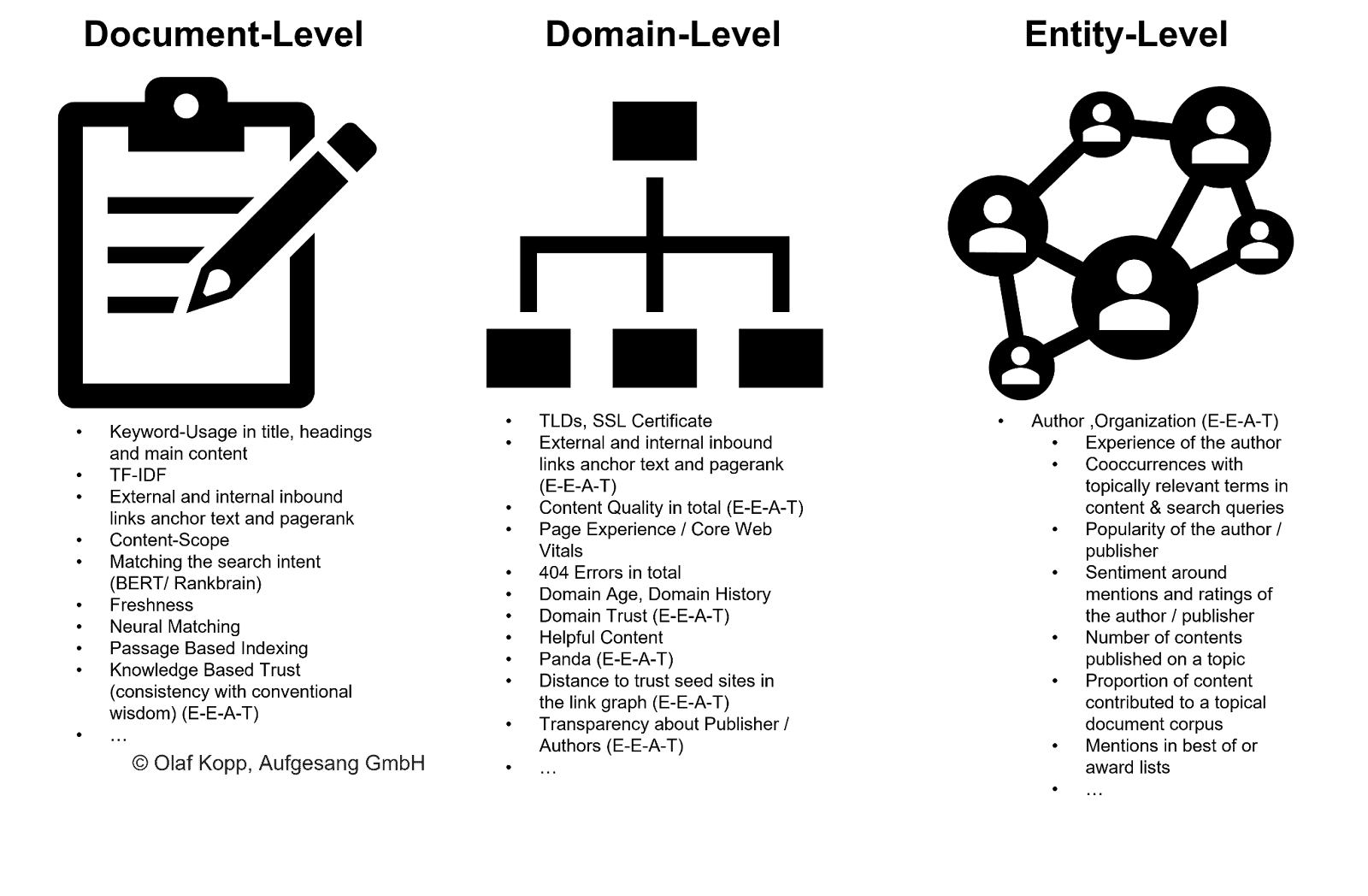
EEAT 可以幫助谷歌在更廣泛的範圍內根據實體、域和作者級別進行排名,而無需抓取每一條內容。
在這個宏觀層面上,可以根據發起者實體對內容進行分類,並分配或多或少的抓取預算。 Google 還可以使用此方法從索引中排除整個內容組。
Google 如何識別作者和屬性內容?
作者屬於個人實體類型。 必須區分知識圖譜中記錄的已知實體和知識庫(如知識庫)中記錄的先前未知或未經驗證的實體。
即使實體尚未在知識圖譜中捕獲,谷歌也可以使用機器學習和語言模型從非結構化內容中識別和提取實體。 該解決方案稱為命名實體識別 (NER),這是自然語言處理的一個子任務。
NER 根據語言模式識別實體,並分配實體類型。 一般來說,名詞是(命名的)實體。
現代信息檢索系統為此使用詞嵌入 (Word2Vec)。
數字向量表示文本或文本段落的每個單詞,實體可以表示為節點向量或實體嵌入 (Node2Vec/Entity2Vec)。
通過詞性 (POS) 標記將單詞分配到語法類別(名詞、動詞、介詞等)。
名詞通常是實體。 主體是主要實體,客體是次要實體。 動詞和介詞可以將實體彼此聯繫起來。
在下面的示例中,“olaf kopp”、“head of seo”、“co founder”和“aufgesang”是命名實體。 (NN = 名詞)。
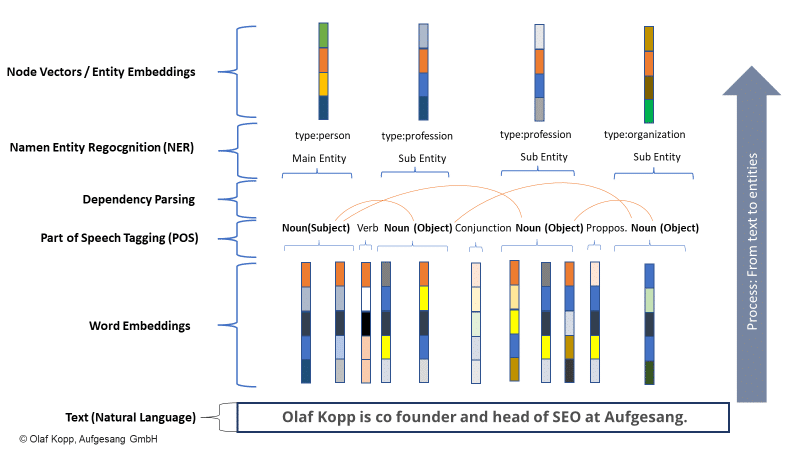
自然語言處理可以識別實體並確定它們之間的關係。
這創建了一個語義空間,可以更好地捕捉和理解實體的概念。
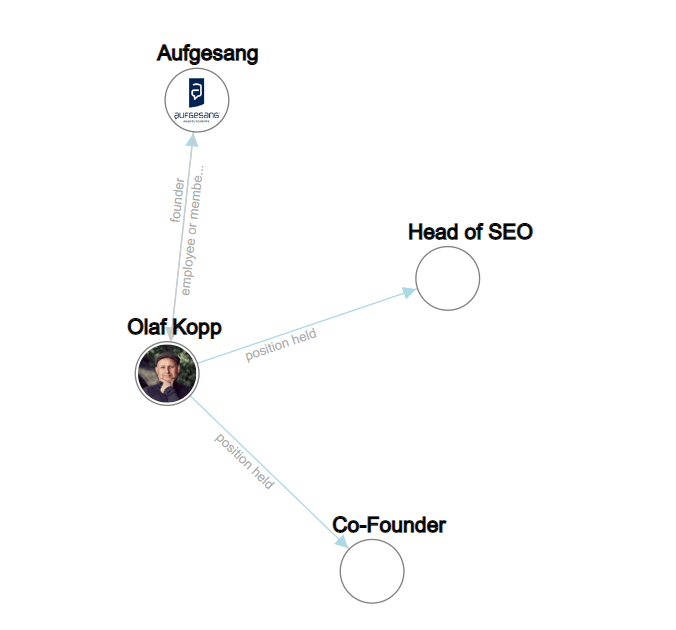
您可以在“Google 如何使用 NLP 更好地理解搜索查詢和內容”中找到更多相關信息。
與作者嵌入對應的是文檔嵌入。 通過向量空間分析將文檔嵌入與作者向量進行比較。 (您可以在 Google 專利“生成文檔的矢量表示”中了解更多信息。)
所有類型的內容都可以表示為向量,這允許:
- 要在向量空間中進行比較的內容向量和作者向量。
- 根據相似性對文檔進行聚類。
- 要分配的作者。
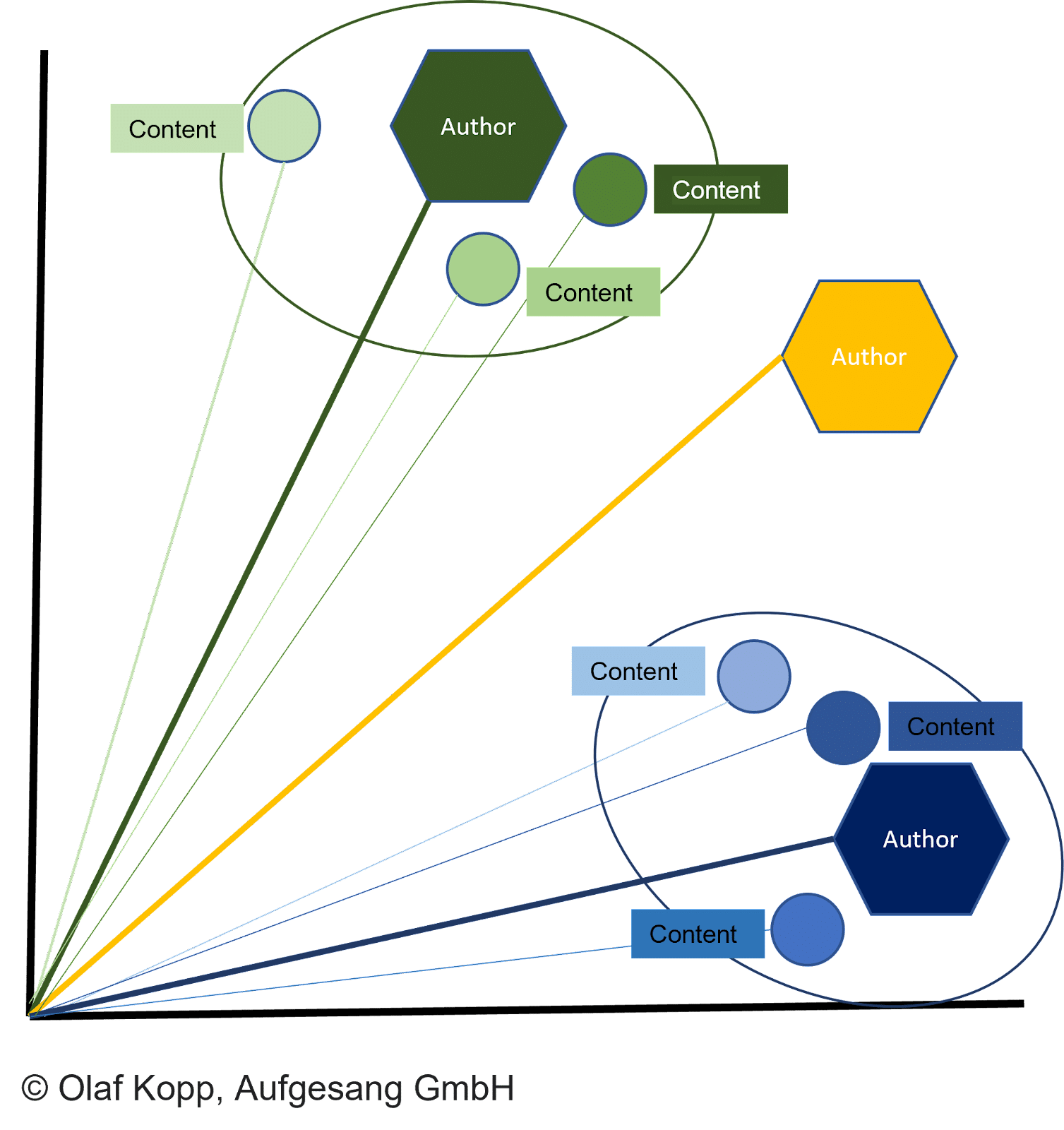
文檔向量和相應的作者向量之間的距離描述了作者創建文檔的概率。
如果距離小於其他向量並達到某個閾值,則文檔歸屬於作者。
這也可以防止在錯誤標記下創建文檔。 然後可以使用內容中指定的作者姓名將作者向量分配給作者實體,如前所述。
有關作者的重要信息來源包括:
- 關於此人的維基百科文章。
- 作者簡介。
- 揚聲器配置文件。
- 社交媒體資料。
如果你用谷歌搜索一個實體類型的人的名字,你會在前 20 個搜索結果中找到維基百科條目、作者的個人資料和與作者直接相關的域的 URL。
在移動 SERP 中,您可以看到 Google 與個人實體建立直接關係的來源。
谷歌將社交媒體資料圖標上方的所有結果識別為直接引用該實體的來源。

這張“olaf kopp”搜索查詢的屏幕截圖顯示實體鏈接到來源。
它還顯示知識面板的新變體。 看來我已經成為這裡 Beta 測試的一部分了。
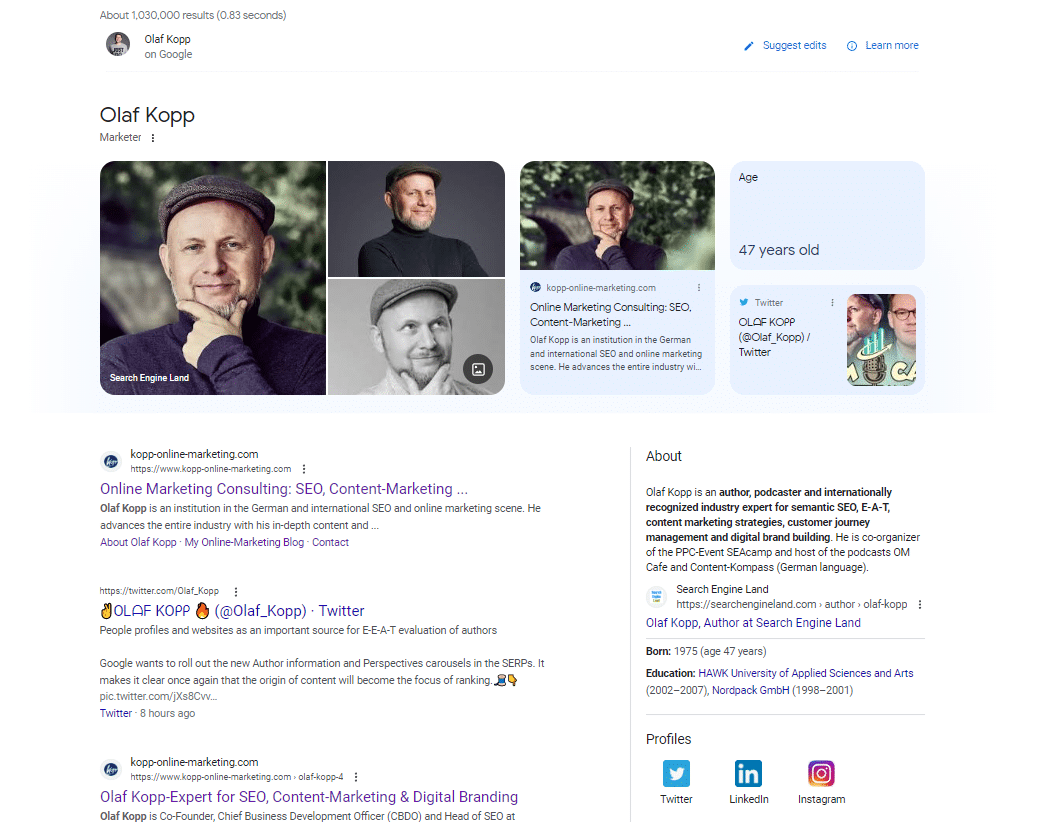
在此屏幕截圖中,您會看到除了圖像和屬性(年齡)外,Google 還直接將我的域和社交媒體資料鏈接到我的實體,並將它們提供到知識面板中。
由於沒有關於我的 Wikipedia 文章,關於描述來自美國 Search Engine Land 的作者簡介和德國代理網站的作者簡介。
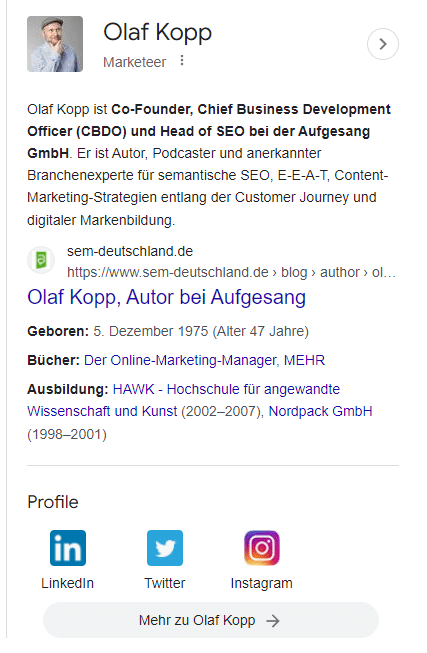
網絡上的個人資料可幫助 Google 將作者置於上下文中並識別與作者相關的社交媒體資料和域。
作者資料中的作者框或作者收藏可幫助 Google 將內容分配給作者。 作者的名字不足以作為標識符,因為可能會出現歧義。
你應該注意每個人的作者描述,以確保一致性。 Google 可以使用它們來檢查實體相互比較的有效性。
獲取搜索營銷人員所依賴的每日時事通訊。
見條款。
有趣的谷歌作者 EEAT 評級專利
以下專利分享了谷歌如何識別作者、為其分配內容並根據 EEAT 對其進行評估的可能方法。
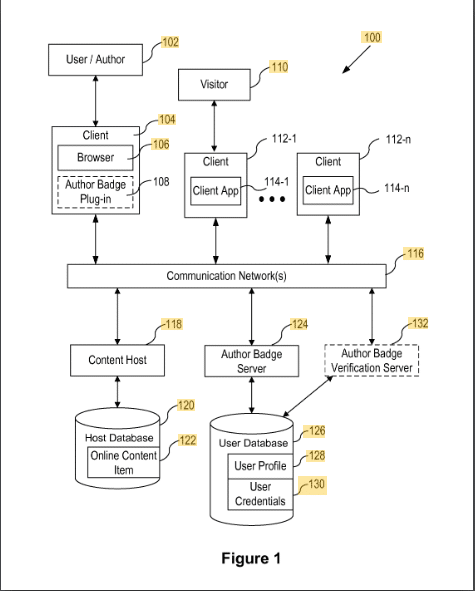
內容作者徽章
該專利描述瞭如何通過徽章將內容分配給作者。
使用電子郵件地址或作者姓名等 ID 將內容分配給作者徽章。 驗證是通過作者瀏覽器中的插件完成的。
生成作者向量
谷歌於2016年簽署了這項專利,有效期至2036年。不過目前只有美國有專利申請,這表明它尚未在全球範圍內用於谷歌搜索。
該專利描述瞭如何根據訓練數據將作者表示為向量。
矢量成為根據作者的典型寫作風格和單詞選擇識別的唯一參數。
這樣,以前不屬於作者的內容可以分配給他們,或者類似的作者可以分組到集群中。
然後可以根據用戶過去在搜索中的用戶行為(例如在 Discover 上)為一個或多個作者調整內容排名。
因此,來自已經被發現的作者和來自相似作者的內容的排名會更好。
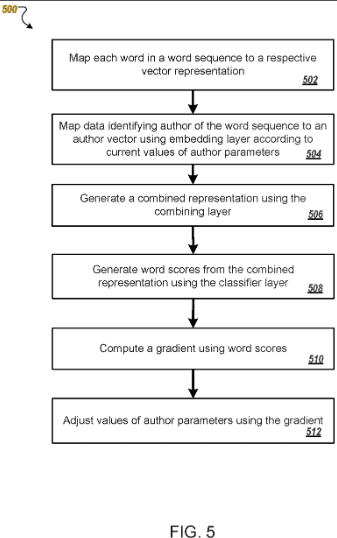
該專利基於所謂的嵌入,例如作者和詞嵌入。
如今,嵌入已成為深度學習和自然語言處理的技術標準。
因此,很明顯谷歌這樣的方法也將用於作者識別和歸屬。
作者的聲譽評分
該專利於 2008 年由 Google 首次簽署,最低期限為 2029 年。該專利最初是指關閉已久的 Google Knol 項目。
因此,更令人興奮的是,為什麼谷歌在 2017 年將其重新命名為在線內容貨幣化的新標題。 Knol 在 2012 年被谷歌關閉。
該專利是關於確定聲譽評分的。 為此可以考慮以下因素:
- 作者的框架水平。
- 在知名媒體發表文章。
- 出版物數量。
- 最近發布的年齡。
- 作者作為作者正式工作了多長時間。
- 作者內容生成的鏈接數。
一個作者的每個主題可以有多個信譽分數,每個主題領域可以有多個別名。
該專利中提出的許多觀點都與 Knol 這樣的封閉平台有關。 因此,該專利在這一點上應該足夠了。
代理等級
這項谷歌專利於 2005 年首次簽署,最短期限至 2026 年。
除美國外,它還在西班牙、加拿大和全球範圍內註冊,使其有可能被用於谷歌搜索。
該專利描述瞭如何將數字內容分配給代理人(出版商和/或作者)。 此內容根據代理等級等進行排名。
代理排名獨立於搜索查詢的搜索意圖,並根據分配給代理的文檔及其反向鏈接確定。
Agent Rank 專門指一個搜索查詢、搜索查詢集群或整個主題領域。
“代理排名也可以根據搜索詞或搜索詞類別來計算。 例如,搜索詞(或搜索詞的結構化集合,即查詢)可以分類為主題,例如體育或醫學專業,並且代理可以針對每個主題具有不同的排名。”
在線內容作者的可信度
這項谷歌專利於 2008 年首次簽署,最短期限為 2029 年,迄今為止僅在美國註冊。
Justin Lawyer 以與作者的專利聲譽得分相同的方式開發它,並與搜索中的使用直接相關。
在該專利中,可以發現與上述專利相似的地方。
對我來說,這是在信任和權威方面評估作者的最令人興奮的專利。
該專利引用了可用於通過算法確定作者可信度的各種因素。
它描述了搜索引擎如何在作者的可信度因素和聲譽得分的影響下對文檔進行排名。
一個作者可以有多個信譽分數,這取決於他們發佈內容的不同主題的數量。
作者的信譽評分與出版商無關。
同樣在該專利中,鏈接作為 EEAT 評級中的一個可能因素的參考。 已發佈內容的鏈接數量會影響作者的信譽評分。
提到了以下可能的信譽評分信號:
- 作者在某個主題領域創作內容的時長。
- 作者的意識。
- 用戶對已發佈內容的評分。
- 如果另一家發布商以高於平均水平的評級發布作者的內容。
- 作者發布的內容量。
- 作者上次發表是在多久之前。
- 作者對類似主題的先前出版物的評分。
有關專利聲譽評分的其他有趣信息:
- 一個作者可以有多個信譽分數,這取決於他們發佈內容的不同主題的數量。
- 作者的信譽評分與出版商無關。
- 如果多次發布重複的內容或摘錄,則信譽評分可能會降低。
- 已發佈內容的鏈接數量會影響信譽分數。
此外,該專利解決了作者的可信度因素。 提到了以下影響因素:
- 有關作者的職業或在公司中的角色的已驗證信息。 它還考慮了公司的信譽。
- 職業與發佈內容主題的相關性。
- 作者的教育和培訓水平。
- 作者的經驗基於時間。 作者在某個主題上發表的時間越長,他就越可信。 作者/出版商的經驗可以通過某個主題領域的首次出版日期通過算法為谷歌確定。
- 在某個主題上發布的內容數量。 如果一個作者就一個主題發表多篇文章,可以認為他是專家,具有一定的可信度。
- 到上次發布所用的時間。 自作者上次發表某個主題以來的時間越長,該主題的信譽得分可能下降得越多。 內容越新,排名越高。
- 在獎項和最佳名單中提及作者/出版商。
重新排列排名搜索結果的系統和方法
這項谷歌專利於 2013 年首次簽署,最短期限至 2033 年。它已在美國和全球範圍內註冊,這使得谷歌很可能會使用它。
該專利的發明人之一是 Chung Tin Kwok,他曾參與多項與 EEAT 相關的谷歌專利。
該專利描述了搜索引擎如何除了對作者內容的引用之外,還可以考慮作者在作者評分中對主題文檔語料庫的貢獻比例。
“在一些實施例中,確定各個實體的原始作者分數包括:識別已知內容索引中的多個內容部分,這些內容被識別為與各個實體相關聯,多個部分中的每個部分代表預定量已知內容索引中的數據;計算已知內容索引中內容部分的第一個實例的多個部分的百分比。”
它描述了基於作者評分(包括引文評分)的搜索結果重新排名。 引文評分基於對作者文檔的引用次數。
作者評分的另一個標準是作者為主題相關文檔的語料庫貢獻的內容比例。
“[W]在此確定各個實體的作者分數包括:確定各個實體的引文分數,其中引文分數對應於引用與各個實體相關的內容的頻率;確定原始作者分數相應實體,其中原始作者分數對應於與相應實體相關聯的內容的百分比,該實體是已知內容索引中內容的第一個實例;以及使用預定函數組合引文分數和原始作者分數以產生作者得分。”
該專利的目的是識別“抄襲者”並降低其內容在排名中的排名,但也可用於作者的一般評價。
評價作者的關鍵因素
除了上述專利中列出的作者評估的可能因素之外,這裡還有一些需要考慮的因素(其中一些我已經在我的文章“谷歌評估 EAT 的 14 種方式”中提到過)。
- 一個主題內容的整體質量:作者在一個主題上發表的關於他的內容的整體質量,與領域和格式無關,可能是 EEAT 的一個因素。 這方面的信號可以是用戶信號、鏈接和內容級別的其他質量信號。
- PageRank 或對作者內容的引用。
- 作者在內容(播客、視頻、網站、PDF、書籍)中與相關主題或術語同時出現。
- 作者在具有相關主題或術語的搜索查詢中同時出現。
將 EEAT 應用於作者實體
機器學習方法可以從大規模的非結構化內容中識別和映射語義結構。
這使 Google 能夠識別和理解比之前在知識圖譜中顯示的更多的實體。
因此,內容來源扮演著越來越重要的角色。 EEAT 可以通過算法應用於文檔、內容和領域之外。
該概念還可以涵蓋內容的作者實體(即,對內容負責的作者和組織)。
我認為我們將在未來幾年看到 EEAT 對 Google 搜索產生更重大的影響。 這個因素對於排名甚至可能與個別內容的相關性優化一樣重要。
本文中表達的觀點是客座作者的觀點,不一定是 Search Engine Land。 此處列出了工作人員作者。