
Google 是否使用類似 ChatGPT 的系統來檢測垃圾郵件和 AI 內容並對網站進行排名?
已發表: 2023-02-01標題是故意誤導的——但僅限於使用術語“ChatGPT”。
“ChatGPT-like”立即讓讀者知道我所指的技術類型,而不是將系統描述為“像 GPT-2 或 GPT-3 這樣的文本生成模型”。 (另外,後者真的不會那麼可點擊……)
我們將在本文中看到的是 2020 年的一篇較舊但高度相關的 Google 論文,“生成模型是頁面質量的無監督預測器:一項大規模研究。”
這篇論文是關於什麼的?
讓我們從作者的描述開始。 他們這樣介紹話題:
“許多人對神經文本生成器在野外的潛在危險表示擔憂,這主要是因為它們能夠大規模生成看起來像人類的文本。
受過訓練以區分人類和機器生成的文本的分類器最近被用於監控網絡上機器生成文本的存在[29]。 然而,在將這些分類器用於其他用途方面所做的工作很少,儘管它們具有不需要標籤的吸引人的特性——只需要一個人類文本語料庫和一個生成模型。 在這項工作中,我們通過嚴格的人工評估表明,現成的人工與機器鑑別器可作為頁面質量的強大分類器。 也就是說,看起來是機器生成的文本往往語無倫次或難以理解。 為了了解普遍存在的低質量頁面,我們將分類器應用於 5 個英文網頁樣本。”
他們實質上說的是,他們發現開髮用於檢測基於 AI 的副本的相同分類器,使用相同的模型來生成它,可以成功地用於檢測低質量的內容。
當然,這給我們留下了一個重要的問題:
這是因果關係(即係統選擇它是因為它真的很擅長)還是相關性(即當前大量垃圾郵件的創建方式是否可以通過更好的工具輕鬆解決)?
然而,在我們探討之前,讓我們先看看作者的一些工作和他們的發現。
設置
作為參考,他們在實驗中使用了以下內容:
- 兩個文本生成模型,OpenAI 基於 RoBERTa 的 GPT-2 檢測器(一種使用帶有 GPT-2 輸出的 RoBERTa 模型並預測它是否可能由 AI 生成的檢測器)和 GLTR 模型,它也可以訪問 top GPT-2輸出和操作類似。
我們可以在我從上面的論文中復制的內容上看到這個模型的輸出示例:
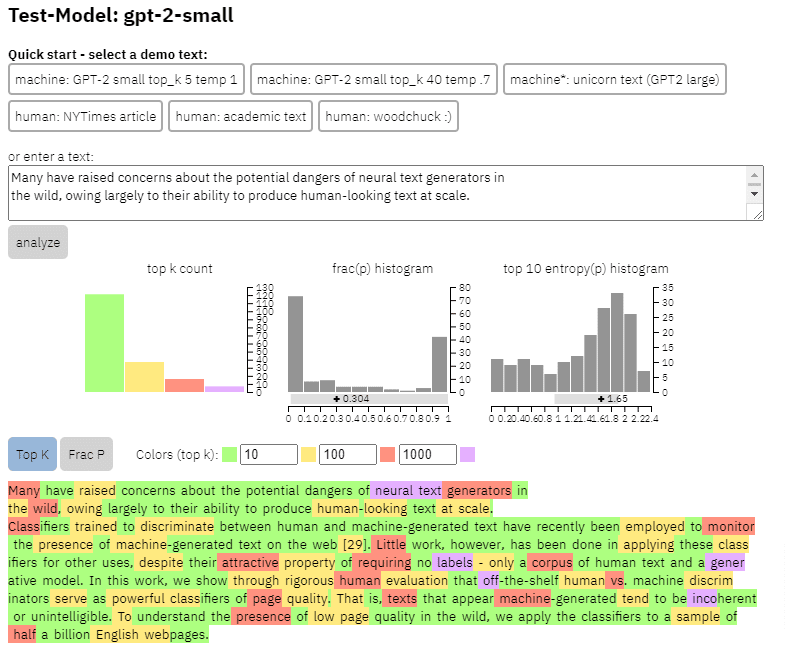
- 三個數據集Web500M(隨機抽取 5 億個英文網頁)、GPT-2 輸出(250k GPT-2 文本生成)和 Grover-Output(他們使用預訓練的 Grover-Base 模型在內部生成 1.2M 文章,該模型是設計的檢測假新聞)。
- 垃圾郵件基線,一個在 Enron 垃圾郵件數據集上訓練的分類器。 他們使用這個分類器來確定他們將分配的語言質量編號,因此如果模型確定文檔不是垃圾郵件的概率為 0.2,則分配的語言質量 (LQ) 分數為 0.2。
獲取搜索營銷人員所依賴的每日時事通訊。
見條款。
關於垃圾郵件流行的旁白
我想暫時擱置一下,討論一下作者偶然發現的一些有趣的發現。 一種如下圖所示(論文中的圖 3):
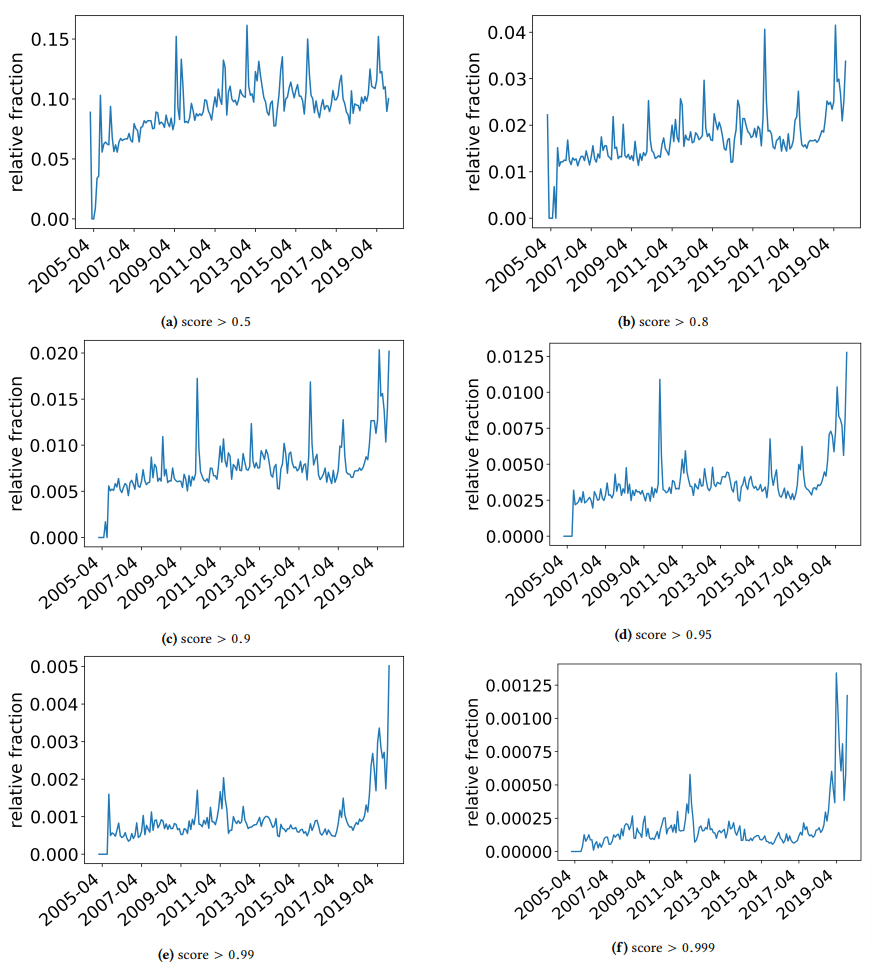
請務必注意每張圖表下方的分數。 接近 1.0 的數字表明內容是垃圾郵件。 我們當時看到的是,從 2017 年開始——並在 2019 年激增——低質量文檔盛行。
此外,他們發現低質量內容在某些領域的影響比其他領域更大(請記住,較高的分數反映出垃圾郵件的可能性較高)。
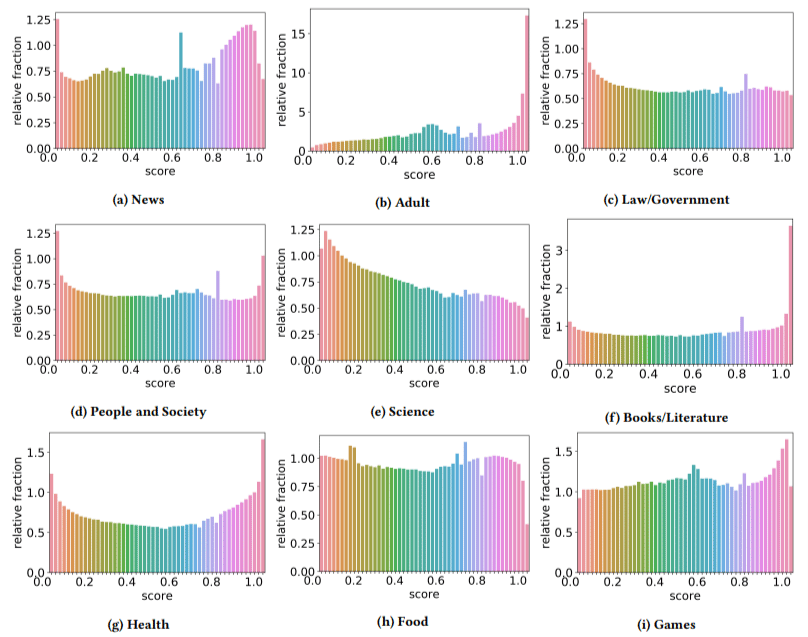
我為其中的幾個撓頭。 顯然,成人是有道理的。
但是書籍和文學作品有點令人驚訝。 健康也是如此——直到作者將偉哥和其他“成人保健品”網站稱為“健康”,將論文農場稱為“文學”——就是這樣。
他們的發現
除了我們討論的行業和 2019 年的峰值之外,作者還發現了一些有趣的事情,SEO 可以從中學習並且必須牢記在心,尤其是當我們開始依賴 ChatGPT 等工具時。
- 低質量內容的長度往往較短(最高可達 3,000 個字符)。
- 經過訓練以確定文本是否由機器編寫的檢測系統也擅長對低級內容和高級內容進行分類。
- 他們將我們為排名設計的內容稱為特定罪魁禍首,但我懷疑他們指的是我們都知道不應該存在的垃圾。
作者並沒有聲稱這是一個萬事俱備的解決方案,而是一個起點,我相信他們在過去幾年中已經將標準向前推進了。
關於 AI 生成內容的說明
多年來,語言模型同樣得到了發展。 雖然在撰寫本文時 GPT-3 已經存在,但他們使用的檢測器是基於 GPT-2,這是一個明顯較差的模型。
GPT-4 可能指日可待,Google 的 Sparrow 定於今年晚些時候發布。 這意味著不僅戰場雙方(內容生成器與搜索引擎)的技術都變得更好,組合也將更容易發揮作用。
Google 能否檢測到由 Sparrow 或 GPT-4 創建的內容? 或許。
但是,如果它是用 Sparrow 生成的,然後通過重寫提示發送到 GPT-4 呢?
另一個需要記住的因素是本文中使用的技術基於自回歸模型。 簡而言之,他們預測一個詞的分數是基於他們預測該詞之前的詞的分數。
隨著模型的複雜程度越來越高,並開始一次創建完整的想法,而不是一個單詞接著另一個單詞,AI 檢測可能會下滑。
另一方面,對簡單垃圾內容的檢測應該升級——這可能意味著唯一獲勝的“低質量”內容是人工智能生成的。
本文中表達的觀點是客座作者的觀點,不一定是 Search Engine Land。 此處列出了工作人員作者。