
Hadoop 生態系統及其組件
已發表: 2015-04-23大數據是從 2008 年開始在 IT 行業流行的流行詞。社交網絡、製造、零售、股票、電信、保險、銀行和醫療保健行業產生的數據量遠遠超出我們的想像。
在 Hadoop 出現之前,大數據的存儲和處理是一個巨大的挑戰。 但既然 Hadoop 可用,公司已經意識到大數據的業務影響以及理解這些數據將如何推動增長。 例如:
• 銀行業有更好的機會了解忠誠客戶、貸款違約者和欺詐交易。
• 零售業現在有足夠的數據來預測需求。
• 製造業不必依賴昂貴的質量檢測機制。 捕獲傳感器數據並對其進行分析將揭示許多模式。
• 電子商務、社交網絡可以根據客戶興趣對頁面進行個性化設置。
• 股票市場產生海量數據,不時關聯將揭示美麗的見解。
大數據有許多有用且富有洞察力的應用。
Hadoop 是處理大數據的直接答案。 Hadoop生態系統是在解決業務問題方面具有熟練優勢的技術組合。
讓我們了解 Hadoop Ecosytem 中的組件,以便為給定的業務問題構建正確的解決方案。
Hadoop生態系統:
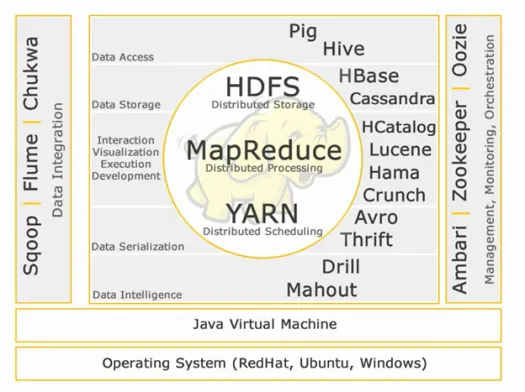

核心Hadoop:
HDFS:
HDFS 代表 Hadoop 分佈式文件系統,用於管理具有高容量、速度和多樣性的大數據集。 HDFS 實現了主從架構。 主節點是名稱節點,從節點是數據節點。
特徵:
• 可擴展
• 可靠的
• 商品硬件
HDFS 以大數據存儲而聞名。
地圖縮減:
Map Reduce 是一種旨在處理大量分佈式數據的編程模型。 平台是使用 Java 構建的,以便更好地處理異常。 Map Reduce 包括兩個守護進程,Job tracker 和 Task Tracker。
特徵:
• 函數式編程。
• 非常適用於大數據。
• 可以處理大型數據集。
Map Reduce 是處理大數據的主要組件。
紗:
YARN 代表又一個資源談判者。 它也被稱為 MapReduce 2(MRv2)。 MRv1 中 Job Tracker 的兩個主要功能,資源管理和作業調度/監控被拆分為獨立的守護進程,即 ResourceManager、NodeManager 和 ApplicationMaster。
特徵:
• 更好的資源管理。
• 可擴展性
• 集群資源的動態分配。
數據訪問:
豬:
Apache Pig 是一種建立在 MapReduce 之上的高級語言,用於使用簡單的即席數據分析程序分析大型數據集。 Pig 也稱為數據流語言。 它與python很好地集成在一起。 它最初是由雅虎開發的。
豬的顯著特點:
• 易於編程
• 優化機會
• 可擴展性。
內部的 Pig 腳本將被轉換為 map reduce 程序。

蜂巢:
Apache Hive 是另一種建立在 Hadoop 之上的高級查詢語言和數據倉庫基礎架構,用於提供數據匯總、查詢和分析。 它最初由雅虎開發並開源。
蜂巢的顯著特點:
• 類似於 SQL 的查詢語言,稱為 HQL。
• 分區和分桶以加快數據處理速度。
• 與Tableau 等可視化工具集成。
Hive 查詢內部將被轉換為 map reduce 程序。
如果你想成為一名大數據分析師,這兩種高級語言是必須知道的!!

數據存儲:
數據庫:
Apache HBase 是一個 NoSQL 數據庫,用於在 Hadoop 商品硬件機器上託管具有數十億行和數百萬列的大型表。 當您需要對大數據進行隨機、實時的讀/寫訪問時,請使用 Apache Hbase。
特徵:
• 嚴格一致的讀取和寫入。 在內存操作中。
• 易於使用的Java API 進行客戶端訪問。
• 與豬、蜂巢和sqoop 完美集成。
• 是 CAP 定理中的一致和分區容忍系統。

卡桑德拉:
Cassandra 是一個 NoSQL 數據庫,專為線性可擴展性和高可用性而設計。 Cassandra 基於鍵值模型。 由 Facebook 開發,以更快響應查詢而聞名。
特徵:
• 列索引
• 支持去規範化
• 物化視圖
• 強大的內置緩存。

交互-可視化-執行-開發:
目錄:
HCatalog 是一個表管理層,它為其他 Hadoop 應用程序提供配置單元元數據的集成。 它使使用 Apache pig、Apache MapReduce 和 Apache Hive 等不同數據處理工具的用戶能夠更輕鬆地讀取和寫入數據。
特徵:
• 不同格式的表格視圖。
• 數據可用性通知。
• 用於外部系統訪問元數據的 REST API。

盧森:
Apache LuceneTM 是一個完全用 Java 編寫的高性能、功能齊全的文本搜索引擎庫。 它是一種適用於幾乎所有需要全文搜索的應用程序的技術,尤其是跨平台的應用程序。
特徵:
• 可擴展的高性能索引。
• 強大、準確和高效的搜索算法。
• 跨平台解決方案。
哈馬:
Apache Hama 是一個基於 Bulk Synchronous Parallel (BSP) 計算的分佈式框架。 以矩陣、圖形和網絡算法等大規模科學計算能力和知名。
特徵:
• 簡單的編程模型
• 非常適合迭代算法
• 支持紗線
• 協同過濾無監督機器學習。
• K-Means 聚類。
緊縮:
Apache crunch 是為簡單高效的流水線化 MapReduce 程序而構建的。 該框架用於編寫、測試和運行 MapReduce 管道。
特徵:
• 以開發者為中心。
• 最少的抽象
• 靈活的數據模型。
數據序列化:
阿夫羅:
Apache Avro 是一個語言中立的數據序列化框架。 專為語言可移植性而設計,允許數據在讀取和寫入時可能比語言壽命更長。

節約:
Thrift 是一種開髮用於構建接口以與基於 Hadoop 構建的技術進行交互的語言。 它用於為多種語言定義和創建服務。
數據智能:
鑽頭:
Apache Drill 是一個用於 Hadoop 和 NoSQL 的低延遲 SQL 查詢引擎。
特徵:
• 敏捷性
• 靈活性
• 熟悉度。

馬豪:
Apache Mahout 是一個可擴展的機器學習庫,設計用於在大數據上構建預測分析。 Mahout 現在已經實現了 apache spark 以更快地進行內存計算。
特徵:
• 協同過濾。
• 分類
• 聚類
• 降維

數據整合:
Apache Sqoop:

Apache Sqoop 是為關係數據庫和 Hadoop 之間的批量數據傳輸而設計的工具。
特徵:
• 從HDFS 導入和導出。
• 從Hive 導入和導出。
• 導入和導出到 HBase。
阿帕奇水槽:
Flume 是一種分佈式、可靠且可用的服務,用於高效收集、聚合和移動大量日誌數據。
特徵:
• 強壯的
• 容錯
• 基於流數據流的簡單靈活的架構。

阿帕奇楚誇:
用於監控大型分佈式文件系統的可擴展日誌收集器。
特徵:
• 擴展到數千個節點。
• 可靠的交付。
• 應該能夠無限期地存儲數據。

管理、監控和編排:
阿帕奇安巴里:
Ambari 旨在通過提供用於配置、管理和監控 Apache Hadoop 集群的接口來簡化 hadoop 管理。
特徵:
• 配置Hadoop 集群。
• 管理Hadoop 集群。
• 監控Hadoop 集群。

阿帕奇動物園管理員:
Zookeeper 是一個集中式服務,旨在維護配置信息、命名、提供分佈式同步和提供組服務。
特徵:
• 序列化
• 原子性
• 可靠性
• 簡單的 API

阿帕奇奧齊:
Oozie 是一個用於管理 Apache Hadoop 作業的工作流調度系統。
特徵:
• 可擴展、可靠和可擴展的系統。
• 支持多種類型的Hadoop 作業,例如Map-Reduce、Hive、Pig 和Sqoop。
• 簡單易用。

我們將在接下來的文章中詳細討論這些組件。 敬請關注。