
使用 Ambari 安裝 Hadoop
已發表: 2015-12-11關於使用 Ambari 安裝 Hadoop 你想知道的一切
Apache Hadoop 已成為可靠、可擴展、分佈式和大規模計算的事實上的軟件框架。 與其他計算系統不同,它將計算帶入數據,而不是將數據發送給計算。 Hadoop 於 2006 年由 Doug Cutting 在雅虎根據谷歌發表的一篇論文創建。 隨著 Hadoop 的成熟,多年來,許多新組件和工具被添加到其生態系統中,以增強其可用性和功能。 Hadoop HDFS、Hadoop MapReduce、Hive、HCatalog、HBase、ZooKeeper、Oozie、Pig、Sqoop 等等。
為什麼是安巴里?
隨著 Hadoop 的日益普及,許多開發人員跳入這項技術來體驗它。 但正如他們所說,Hadoop 不適合膽小的人,許多開發人員甚至無法跨越安裝 Hadoop 的障礙。 許多發行版都提供了預裝的虛擬機沙箱來嘗試一些東西,但它並沒有給你分佈式計算的感覺。 然而,安裝多節點並不是一件容易的事,而且隨著組件數量的增加,處理如此多的配置參數非常棘手。 謝天謝地,Apache Ambari 來到這裡來拯救我們!
什麼是安巴里?
Apache Ambari 是一個基於 Web 的工具,用於配置、管理和監控 Apache Hadoop 集群。 Ambari 提供了一個儀表板,用於查看集群健康狀況,例如熱圖,並能夠直觀地查看 MapReduce、Pig 和 Hive 應用程序以及以用戶友好的方式診斷其性能特徵的功能。 它有一個非常簡單和交互式的 UI 來安裝各種工具並執行各種管理、配置和監控任務。 下面我們將帶您完成在多節點集群上安裝 Hadoop 及其各種生態系統組件的各個步驟。
Ambari 架構如下圖所示
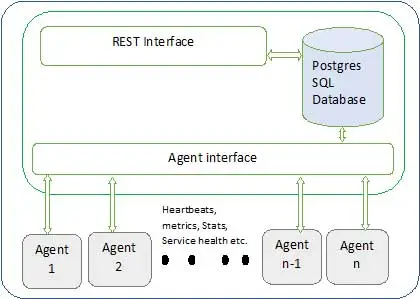
Ambari 有兩個組件
- Ambari 服務器——這是與安裝在參與集群的每個節點上的 Ambari 代理進行通信的主進程。 這具有 postgres 數據庫實例,用於維護所有與集群相關的元數據。
- Ambari 代理- 這些是每個節點上 Ambari 的代理代理。 每個代理都會定期發送自己的健康狀態以及不同的指標、已安裝的服務狀態等等。 根據 master 決定下一個動作並傳回給 agent 動作。
如何安裝安巴里?
Ambari 安裝很容易,只需幾個命令即可完成。
我們將介紹 Ambari 安裝和集群設置。 我們假設有 4 個節點。 節點 1、節點 2、節點 3 和節點 4。 我們選擇 Node1 作為我們的 Ambari 服務器。
這些是在基於 RHEL 的系統上的安裝步驟,對於 debian 和其他系統的步驟會有所不同。
- Ambari 的安裝:-
從 Ambari 服務器節點(我們決定的節點 1)
一世。 下載 Ambari 公共回購

此命令會將 Hortonworks Ambari 存儲庫添加到 yum 中,yum 是 RHEL 系統的默認包管理器。
ii.安裝 Ambari RPMS

這將需要一些時間,並將在此系統上安裝 Ambari。

iii. 配置 Ambari 服務器
安裝 Ambari 後要做的下一件事是配置 Ambari 並將其設置為供應集群。
以下步驟將解決此問題

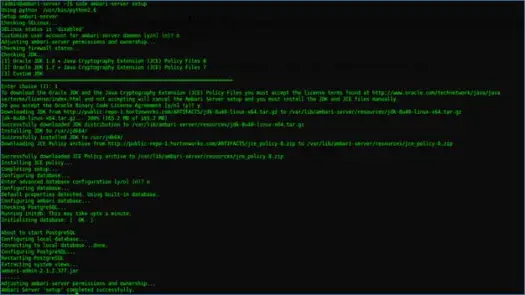

iv. 啟動服務器並登錄到 Web UI
啟動服務器

現在我們可以訪問 Ambari Web UI(託管在 8080 端口上)。
使用默認用戶名“admin”和默認密碼“admin”登錄 Ambari
搭建Hadoop集群
1.登陸頁面
單擊“啟動安裝嚮導”開始集群設置
2.集群名稱
給你集群起個好聽的名字。
注意:這只是集群的一個簡單名稱,意義不大,所以不要擔心,隨便取一個名字。
3.棧選擇
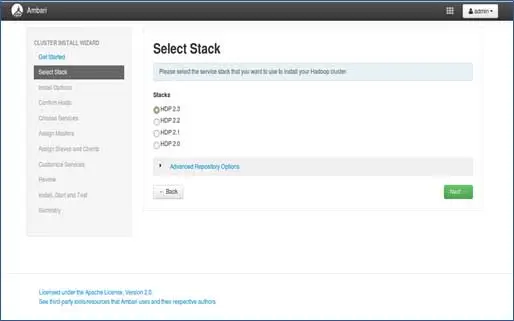
此頁面將列出可安裝的堆棧。 每個堆棧都預先打包了 Hadoop 生態系統組件。 這些堆棧來自 Hortonworks。 (我們也可以安裝普通的 Hadoop。我們將在後面的文章中介紹)。
4.Hosts入口和SSH密鑰入口
在進一步執行此步驟之前,我們應該為所有參與節點設置無密碼 SSH。
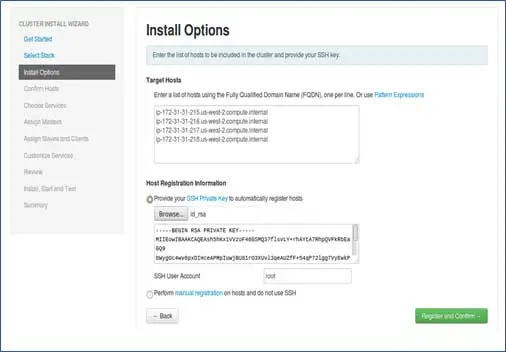

添加節點的主機名,每行單個條目。 [添加可以通過hostname –f命令獲取的FQDN]。 選擇設置無密碼 SSH 時使用的私鑰和創建私鑰的用戶名。
5. 主機註冊狀態
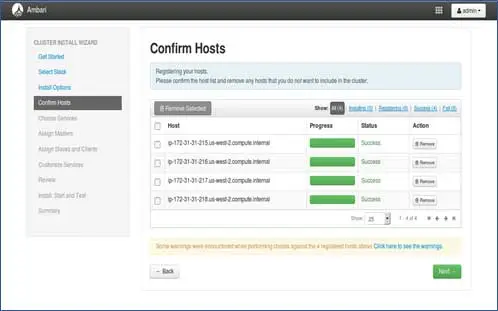
您可以看到正在執行的一些操作,這些操作包括在每個節點上設置 Ambari-agent,在每個節點上創建基本設置。 一旦我們看到 ALL GREEN,我們就可以繼續前進了。 有時這可能需要一些時間,因為它安裝的軟件包很少。

6.選擇您要安裝的服務
根據步驟 3 中選擇的堆棧,我們擁有可以在集群中安裝的服務數量。 你可以選擇你想要的。 如果您沒有選擇依賴服務,Ambari 會智能地選擇它。 例如,您選擇了 HBase 但未選擇 Zookeeper,它會提示相同並將 Zookeeper 也添加到集群中。
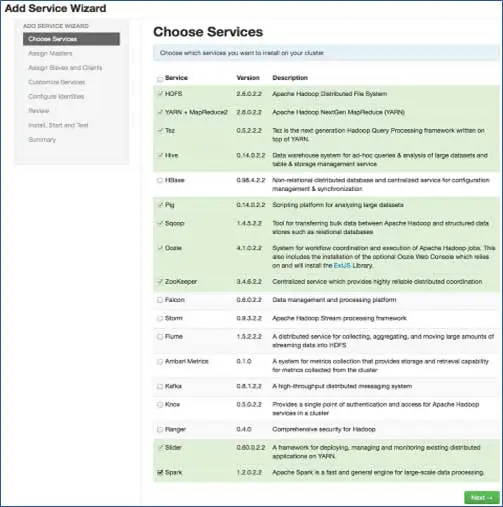
7. 與節點的主服務映射
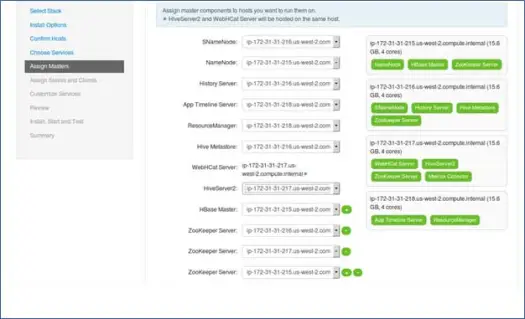
如您所知,Hadoop 生態系統擁有基於主從架構的工具。 在這一步中,我們將主進程與節點相關聯。 在這裡確保您正確平衡您的集群。 另外,請記住主要和輔助服務,如 Namenode 和輔助 Namenode 不在同一台機器上。

8. 從節點與節點的映射
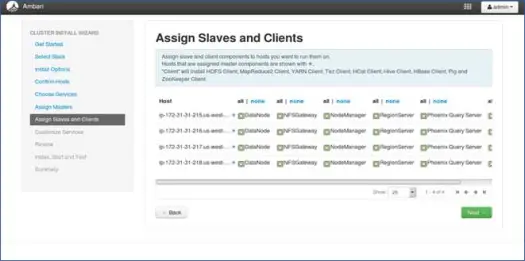
與 master 類似,在節點上映射 slave 服務。 一般來說,所有節點都會有一個至少為 Datanodes 和 Nodemanagers 運行的從屬進程。
9.定制服務
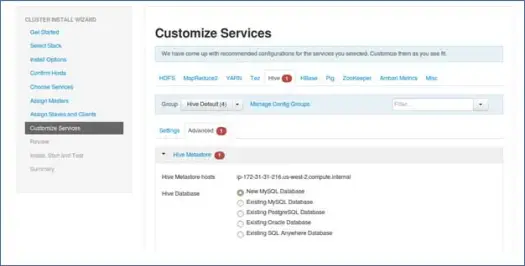
這對於管理員來說是非常重要的頁面。
您可以在此處為集群配置屬性,使其最適合您的用例。
它還將具有一些必需的屬性,例如 Hive Metastore 密碼(如果選擇了 hive)等。這些將用紅色錯誤(如符號)指出。
10. 查看並開始配置
確保在啟動之前檢查集群配置,因為這將避免在不知不覺中設置錯誤的配置。
11. 啟動並停留,直到狀態變為綠色。
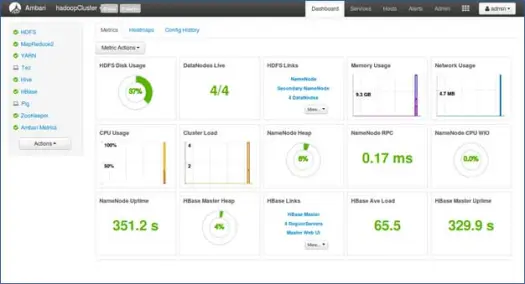
下一步
耶! 我們已經在集群的所有節點上成功安裝了 Hadoop 和所有組件。 現在我們可以開始使用 Hadoop。
Ambari 運行 MapReduce wordcount 作業來驗證一切是否運行良好。 讓我們檢查 ambari-qa 用戶運行的作業的日誌。
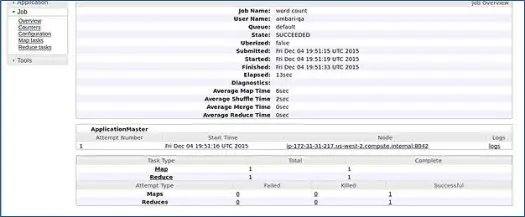
如您在上面的屏幕截圖中所見,WordCount 作業已成功完成。 這證實了我們的集群工作正常。
結論
就是這樣,我們現在已經學習瞭如何使用一個名為 Apache Ambari 的簡單的基於 Web 的工具在多節點集群上安裝 Hadoop 及其組件。 Apache Ambari 為我們提供了一個更簡單的界面,並節省了我們在安裝、監控和管理方面的大量工作,如果有如此多的組件及其不同的安裝步驟和監控控制,這些工作將非常繁瑣。
讓我留給你一個黑客

Ambari 安裝程序檢查 /etc/lsb-release 以獲取操作系統詳細信息。 在 Linux Mint 中,Ubuntu 版本的相同文件位於 /etc/upstream-release/lsb-release 下。 為了欺騙安裝程序,只需將前者替換為後者(您應該先備份文件)。

在安裝完成後的某個時間點,您可以使用以下命令恢復原始文件:

PS這是一個沒有任何保證的hack,它對我有用,所以我想和你分享。
您是開發人員/開發人員,需要快速安裝 Hadoop。 我們有一個好消息要告訴您,Ambari 提供了一種方法,您可以使用單個腳本跳過完整的嚮導過程和完成的安裝過程,我將在下一篇文章中帶來它,敬請期待,直到那時快樂 Hadooping!