
為什麼損壞的書籤會損害 SEO 以及如何查找和修復它們
已發表: 2023-04-12用戶體驗對客戶旅程有著深遠的影響。 這包括您的網站導航的難易程度、頁面加載速度,以及指向相關頁面的鏈接是否會影響客戶是否會完成他們的購買旅程或離開您的網站。
不用說,斷開的鏈接會很快將潛在客戶變成流失客戶。
更重要的是,它還會影響您的排名,特別是您網站上的鏈接資產流量。 因此,您必須確保所有鏈接都正常工作。
但在我們深入研究如何修復您網站上的任何損壞鏈接之前,讓我們仔細看看什麼是書籤或跳轉鏈接。
什麼是書籤鏈接?
HTML 鏈接可用於創建書籤(也稱為“跳轉鏈接”、“命名錨點”、“跳過鏈接”和“碎片鏈接”),以便您網站的訪問者可以跳轉到頁面的特定部分。 簡單地說,URL 中的井號 (#) 稱為書籤。 通常,井號 (#) 後有一些單詞。 它們可以稱為片段標識符/片段 ID 或錨標記。 單擊這些鏈接時,網頁將滾動網頁到書籤所在的位置。
跳轉鏈接的功能不同於其他類型的URI 或統一資源標識符:它們的處理僅在客戶端進行,服務器端不進行任何合作。 服務器通常有助於理解多用途 Internet 郵件擴展或MIME類型以及在處理碎片標識符時的 MIME 類型。 在 URL 的源代碼中,用戶代理將搜索由包含 ID= 屬性等於片段標識符的 HTML 標記標識的錨點。
我們為什麼要關心跳轉鏈接?
想像一下,您正在書店挑選一本百科全書。 您打開目錄以瀏覽最重要的章節。 當您跳轉到您最感興趣的頁面時,您會看到另一個不符合您期望的標題和段落。 您可能會返回目錄或嘗試翻幾頁以找到相關主題,但最後,您會把書放回書架上並找到結構更完整的百科全書。
書籤是在您的網頁上為用戶提供特定信息的一種簡單有效的方式。 雖然跳轉鏈接對您的受眾很有用,但在設置中很容易出錯,並且隨著內容和 ID 的更新,它可能會“損壞”。
Googlebot 如何處理跳轉鏈接?
雖然 Googlebot 會將這些 URL 視為同一網頁(因為機器人會忽略 URL 的 # 部分中的任何內容),但它可以使用命名錨點來為SERP 中的“跳轉到”鏈接進行頁面排名。
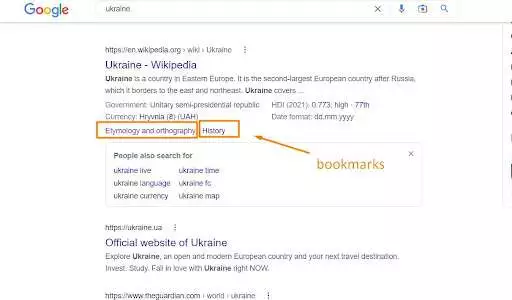
和往常一樣,谷歌的算法說了算。 當搜索機器人請求頁面時,它總是忽略“ # ”字符後的 URL 部分。 瀏覽器只使用書籤——它們不影響從服務器返回的資源。 如果您從以下內容更新 URL 的“#”部分:
https://www.example#old-heading到這個:
https://www.example#new-heading ,
瀏覽器會將頁面滾動到新標題,但不會重新加載 URL。 然而,瀏覽器確實會在瀏覽器的歷史記錄中創建一條記錄,以便單擊瀏覽器菜單中的“後退”按鈕會將訪問者引導至之前打開的源代碼。
碎片化鏈接是否顯示在搜索引擎結果頁面 (SERP) 中將在很大程度上取決於訪問者在每種情況下的搜索意圖。 另外,您應該知道,當您創建書籤時,不會傳遞任何PageRank信號。 網站頁面不會在分散的鏈接之間拆分 PageRank。
如何創建 SEO 友好的書籤?
1.首先,使用ID屬性創建一個書籤:
<h2 id=”seo-answer”>視情況而定</h2>
2.其次,在同一頁面內添加指向書籤的鏈接(“跳轉到有史以來最好的 SEO 答案”):
例子:
<a href=”#seo-answer”>跳轉到有史以來最好的 SEO 答案</a>您還可以在另一個頁面上添加指向書籤的鏈接:
<a href=”the-new-page.html#link-to-another-page”>跳轉到新頁面</a>
關於如何創建 SEO 友好書籤的提示
– 創建描述性錨點/替代文本:超鏈接顯示的可見字符和文字應該是描述性的,讓訪問者知道他們將被導航到哪裡。
– 在易於訪問的部分添加書籤:書籤通常在長篇頁面中用作目錄,允許訪問者快速跳轉到他們想要閱讀的部分。
– 避免在片段中使用特殊字符和空格:必要時為了可讀性,使用/下劃線分隔單詞。
– 仔細插入書籤:如果您使用過多的碎片化鏈接,訪問者可能會感到困惑,並使您的內容顯得雜亂無章。
要檢查結果,請將 URL 插入瀏覽器並單擊碎片鏈接。 如果任何跳轉鏈接沒有將您鏈接到正確的內容部分,請檢查 HTML 源代碼以確定問題所在。 書籤非常簡單,但需要特定格式才能正常運行。
如何鏈接到外部碎片化 URL?
如果你想鏈接到外部網站的頁面,並且內容在網頁的特定部分有相關信息,那麼插入到頁面的鏈接以及標題的標識符(例如,htt p s : //xxx.com/post-title/#section )。

這樣,一旦頁面加載完畢,訪問者就會自動導航到相應的內容部分。 為了使書籤起作用,外部網站的標題必須包含用於頁面跳轉的標識符(例如,<h2 id=” section”>)。
如何使用 SEO Spider 查找損壞的書籤?
棘手的是,無法以與 SEO 爬蟲中的跳轉鏈接斷開鏈接相同的方式找到斷開的跳轉鏈接,因為它們不會觸發 404 Not Found 響應狀態代碼。 這就是為什麼碎片化鏈接問題經常被忽視的原因。 讓我們來看看如何使用SF spider檢測這些錯誤。 請注意,您應該切換到爬蟲的付費版本來設置下面描述的配置。
1. 前往“配置”>“蜘蛛”>“高級”ta
在這裡你應該勾選“抓取碎片標識符”功能。 不要忘記按“確定”綠色按鈕保存設置。
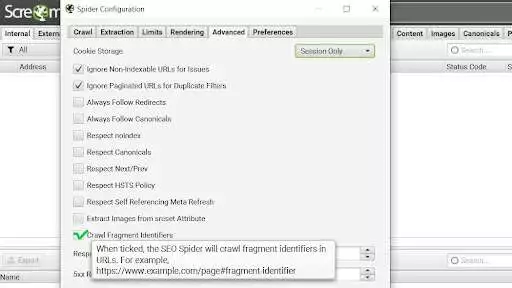
圖片來源:尖叫蛙爬蟲-配置
2.爬行
現在插入您要分析的站點的 URL,然後按“開始”啟動爬網。
圖片來源:順豐爬蟲-起始頁
3.找到“損壞的書籤”部分
抓取完成後,您可以單擊頂部的下拉過濾器或瀏覽右側窗口抓取的“概述”部分,然後單擊“URL”部分下的相關行。 選擇什麼方式並不重要; 他們都顯示相同的數據。
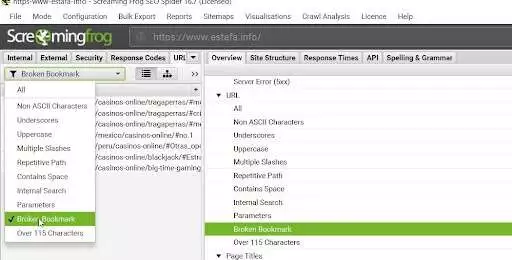
圖片來源:順豐爬蟲-Filters
現在您可以看到哪些跳轉鏈接損壞了,是時候解決這個問題了。
如何修復損壞的書籤
所以,你已經找到了所有不正確的跳轉鏈接; 做得好! 下一個問題是如何處理這些數據。
現在,您應該檢測網站上的哪些頁面會導致斷開的碎片化鏈接,以便您可以打開這些 URL 並修復不正確的 ID。
為此,請突出顯示報告上部的所有 URL (Cntrl/Command +A),然後在底部的“Inlinks”選項卡上突出顯示。 現在您可以在“收件人”列中看到發現損壞書籤的頁面(“發件人”列)以及哪個書籤和哪個錨點/替代文本(如果損壞的鏈接在圖像中)被損壞。
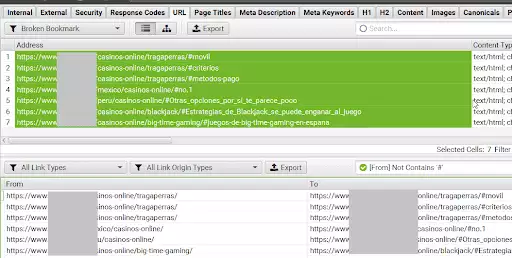
圖片來源:順豐爬蟲-Tabs
為了簡化分析,使用過濾器“From”>“Not contain”>“#”來去除重複的報告案例。
那麼過程就簡單了。 您知道哪個 ID 不正確(提醒:ID = # 之後的 URL 的一部分)以及哪個錨點/替代文本導致損壞的書籤。 在頁面上找到,分析哪裡出了問題。 例如,在下面的示例中,使用了大寫字母而不是小寫字母。
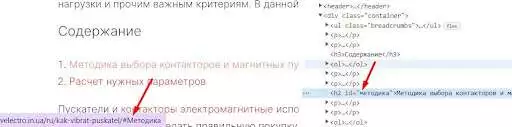
圖片來源:HTML代碼截圖
不幸的是,沒有一種萬能的解決方案來修復破碎的碎片。 有時,由於開發團隊的失誤,錯誤會出現在頁腳、頁眉或導航菜單中。 在這種情況下,您可能需要額外的開發人員幫助來修復代碼中的問題。 按 LinkPosition 列對包含損壞片段的表進行排序始終是一個好習慣,這樣可以更輕鬆地找到模式。
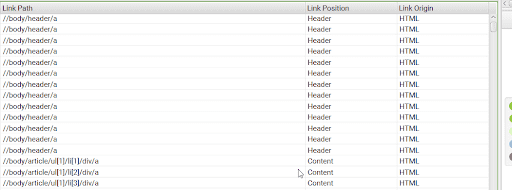
圖片來源:順豐爬蟲-友情鏈接
包起來
書籤可幫助用戶輕鬆滾動和瀏覽長篇內容。 雖然搜索機器人會將這些鏈接視為相同的 URL,但它們可以使用碎片標識符作為 SERP 中的“跳轉到”鏈接。
斷開的跳轉鏈接將意味著訪問者仍在正確的頁面上著陸,但他們不會被發送到內容的預期部分。 可以手動或使用 SEO 爬蟲批量發現跳轉鏈接問題。
要使跳轉鏈接正常工作,您應該找到哪些頁面鏈接到損壞的書籤,然後更新屬性 ID。 不正確的跳轉鏈接會導致糟糕的用戶體驗。 這就是為什麼您應該盡一切可能找到並修復它們。 您在修復碎片化標識符方面有何經驗? 請在下面的評論中告訴我們。