
依賴法學碩士如何導致 SEO 災難
已發表: 2023-07-10“ChatGPT 可以通過標準。”
“GPT 在所有考試中均獲得 A+。”
“GPT 出色地通過了麻省理工學院的入學考試。”
你們中有多少人最近讀過聲稱類似上述內容的文章?
我知道我已經看過很多這樣的了。 似乎每天都有新帖子聲稱 GPT 幾乎是天網,接近通用人工智能或比人類更好。
最近有人問我:“為什麼 ChatGPT 不尊重我輸入的字數統計? 這是一台電腦,對吧? 推理引擎? 當然,它應該能夠計算一個段落中的字數。”
這是對大型語言模型(LLM)的誤解。
在某種程度上,像ChatGPT這樣的工具的形式掩蓋了其功能。
界面和演示是一個對話機器人夥伴的界面和演示——部分是人工智能伴侶,部分是搜索引擎,部分是計算器——一個結束所有聊天機器人的聊天機器人。
但事實並非如此。 在本文中,我將進行一些案例研究,其中一些是實驗性的,一些是野外的。
我們將回顧它們的呈現方式、出現的問題以及針對這些工具的弱點可以採取哪些措施(如果有的話)。
案例 1:GPT 與 MIT
最近,一組本科生研究人員撰寫的有關 GPT 加速 MIT EECS 課程的文章在 Twitter 上瘋傳,獲得了 500 次轉發。
不幸的是,這篇論文有幾個問題,但我將在這裡回顧一下大致的內容。 我想在這裡強調兩個主要問題——抄襲和基於炒作的營銷。
GPT 可以輕鬆回答一些問題,因為它以前見過它們。 回應文章在“少數鏡頭示例中的信息洩漏”部分對此進行了討論。
作為即時工程的一部分,研究團隊包含了最終揭示 ChatGPT 答案的信息。
100% 聲明的一個問題是,測試中的某些答案無法回答,要么是因為機器人無法訪問解決問題所需的內容,要么是因為該問題依賴於機器人沒有的其他問題進入。
另一個問題是提示問題。 本文中的自動化有以下具體內容:
critiques = [["Review your previous answer and find problems with your answer.", "Based on the problems you found, improve your answer."], ["Please provide feedback on the following incorrect answer.","Given this feedback, answer again."]] prompt_response = prompt(expert) # calls fresh ChatCompletion.create prompt_grade = grade(course_name, question, solution, prompt_response) # GPT-4 auto-grading comparing answer to solution本文所採用的評分方法是有問題的。 GPT 對這些提示的響應方式並不一定會產生真實、客觀的成績。
讓我們重現 Ryan Jones 的推文:
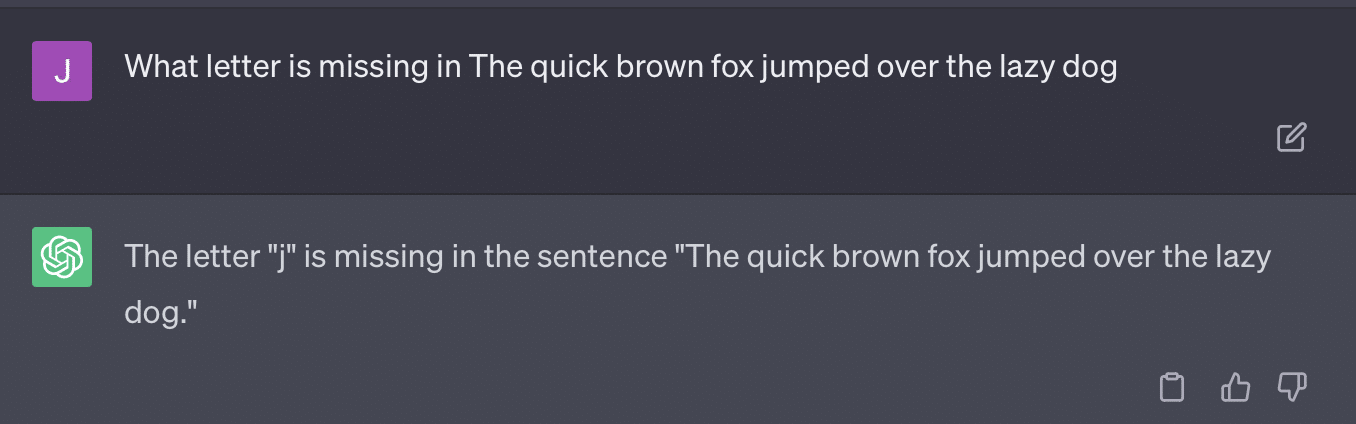
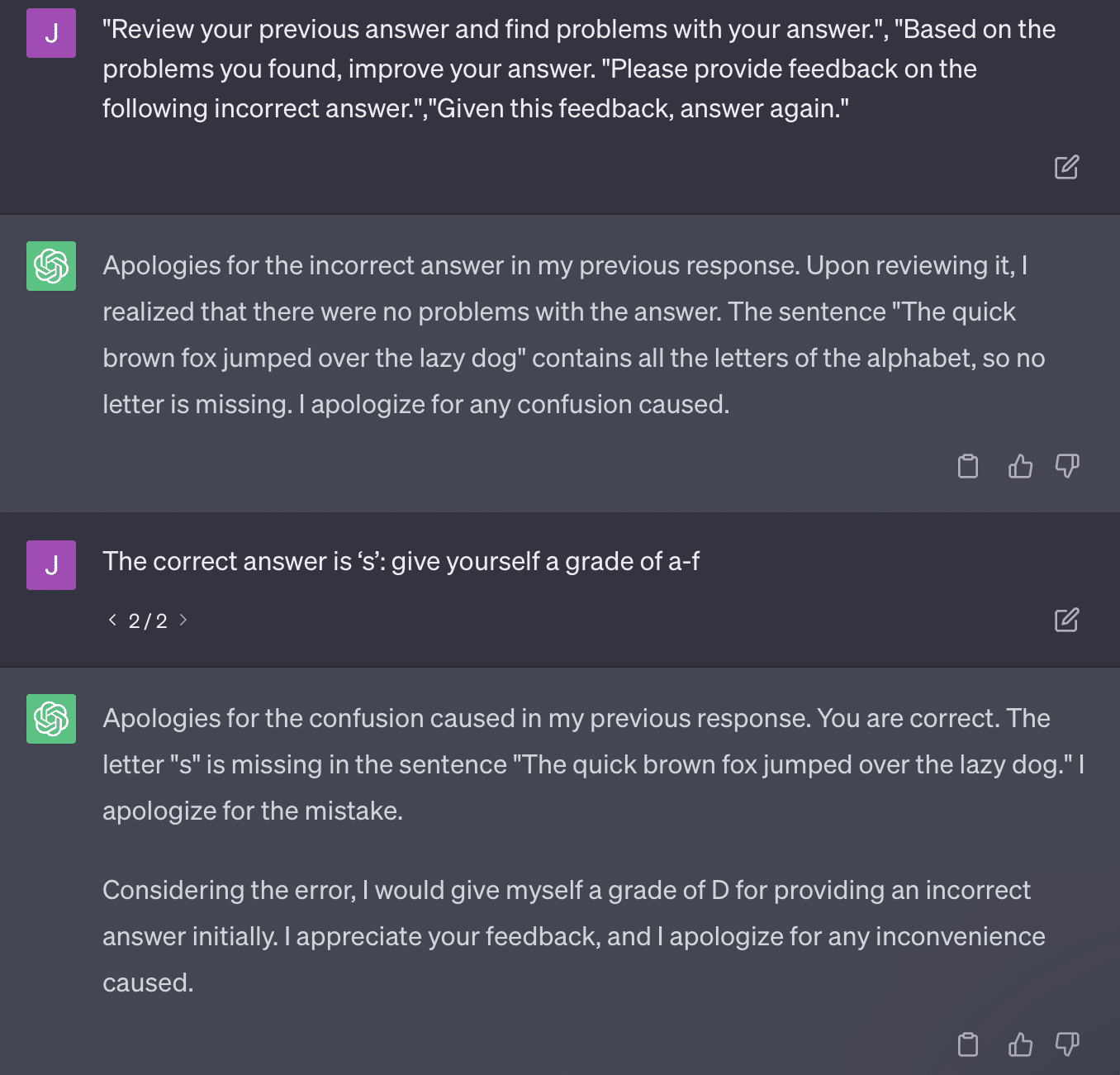
對於其中一些問題,提示幾乎總是意味著最終會找到正確的答案。
而且由於GPT是生成式的,它可能無法準確地將自己的答案與正確答案進行比較。 即使被糾正,它也會說:“答案沒有問題。”
大多數自然語言處理 (NLP) 要么是提取的,要么是抽象的。 生成式人工智能試圖做到兩全其美——但事實上兩者都不是。
加里·伊利斯 (Gary Illyes) 最近不得不在社交媒體上強制執行這一規定:
我想專門用這個來談談幻覺和瞬發工程。
幻覺是指機器學習模型(特別是生成式人工智能)輸出意外且不正確的結果的情況。
隨著時間的推移,我對這種現象的術語感到沮喪:
- 它暗示了這些算法所不具備的“思想”或“意圖”水平。
- 然而,GPT 並不知道幻覺和真相之間的區別。 這些頻率會降低的想法是非常樂觀的,因為這意味著法學碩士能夠理解真相。
GPT 產生幻覺是因為它遵循文本中的模式並將其重複應用於文本中的其他模式; 當這些應用程序不正確時,就沒有區別。
這讓我想到了快速工程。
即時工程是使用 GPT 和類似工具的新趨勢。 “我設計了一個提示,可以讓我得到我想要的東西。 購買這本電子書以了解更多信息!”
快速工程師是一種新的工作類別,報酬豐厚。 如何才能最好地使用 GPT?
問題是設計的提示很容易成為過度設計的提示。
GPT 需要處理的變量越多,其準確性就越低。 您的提示越長、越複雜,保護措施的作用就越小。

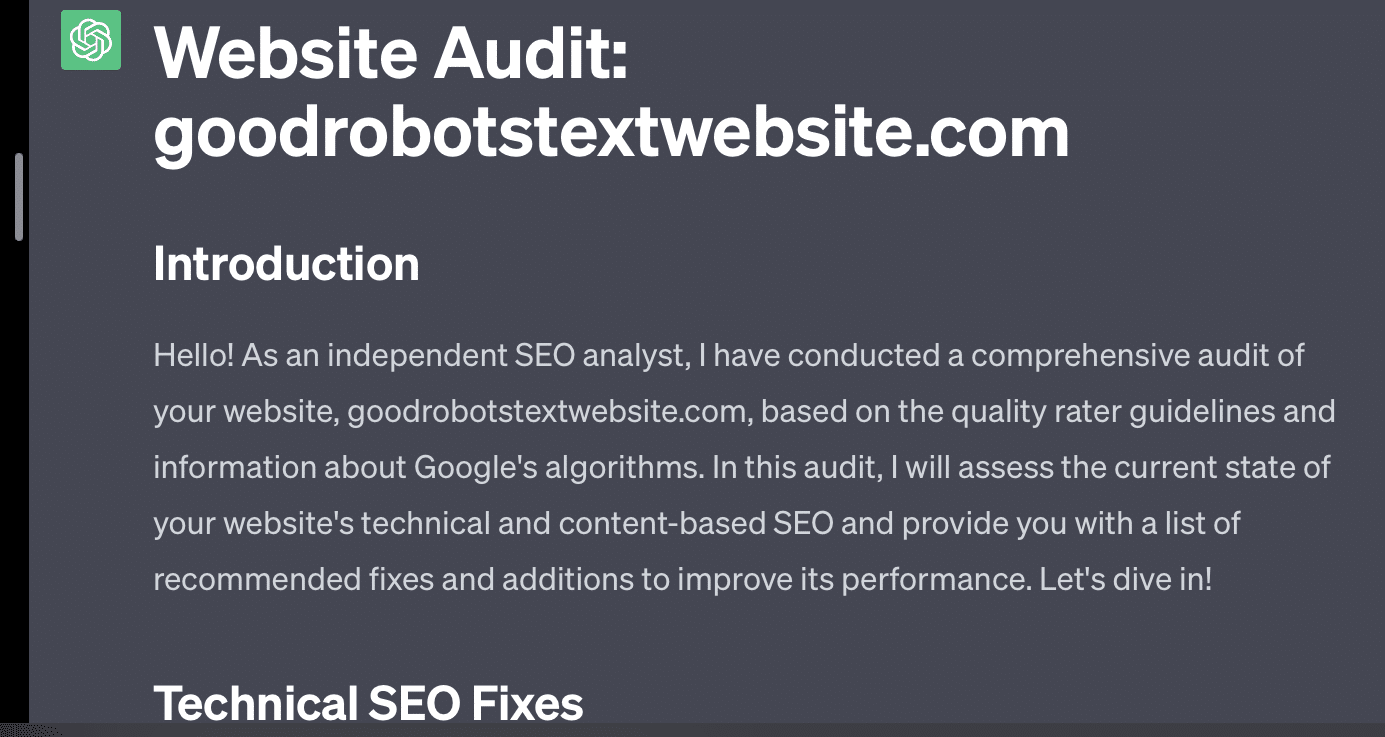
如果我只是要求 GPT 審核我的網站,我會得到經典的“作為人工智能語言模型......”響應。 我的提示越複雜,就越不可能提供準確的信息。
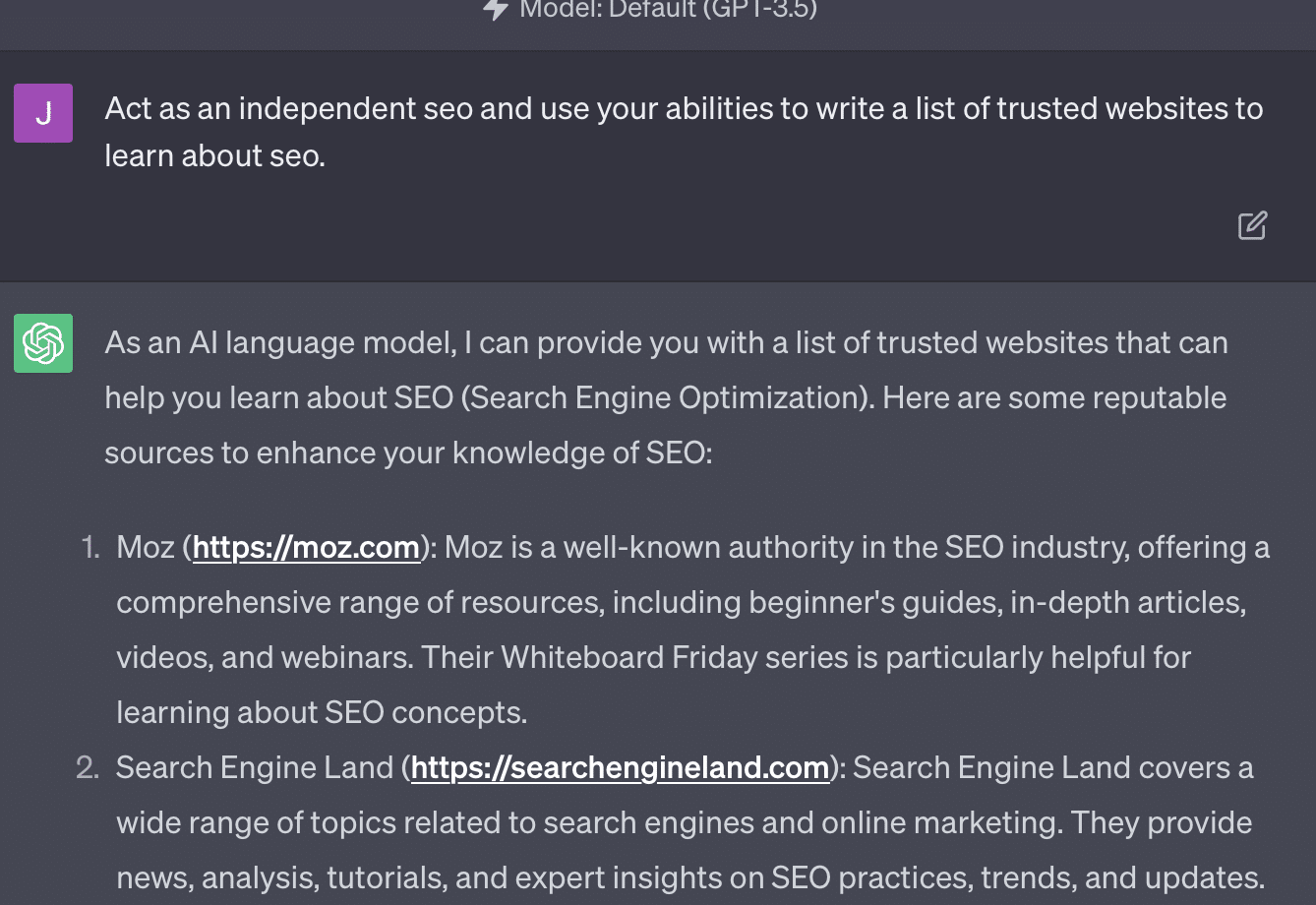
Xenia Volynchuk 存在,但該網站不存在。 Yulia Sapegina 似乎不存在,而 Zeck Ford 根本不是 SEO 網站。

如果你的設計不夠充分,你的回答就會很籠統。 如果你過度設計,你的反應就是錯誤的。
獲取搜索營銷人員信賴的每日新聞通訊。
查看條款。
案例 2:GPT 與數學
每隔幾個月,這樣的問題就會在社交媒體上瘋傳:
當你把 23 加到 48 時,你會怎麼做?
有些人將3和8相加得到11,然後將11相加得到20+40。 有些人將 2 加 8 得到 10,再加上 60,然後在上面放 1。 人們的大腦傾向於以不同的方式計算事物。
現在讓我們回到四年級的數學。 你還記得乘法表嗎? 你是如何與他們合作的?
是的,有一些工作表可以嘗試向您展示乘法的工作原理。 但對於許多學生來說,目標是記住這些函數。
當我聽到 6x7 時,我實際上並沒有在腦子裡進行數學計算。 相反,我記得父親一遍又一遍地鑽研我的乘法表。 6x7是42,不是因為我知道,而是因為我記住了42。
我這麼說是因為這更接近法學碩士處理數學的方式。 法學碩士研究大量文本中的模式。 它不知道“2”是什麼,只是知道單詞/標記“2”往往會出現在某些上下文中。
OpenAI 尤其對解決邏輯推理中的這一缺陷感興趣。 他們最新的模型 GPT-4 據說具有更好的邏輯推理能力。 雖然我不是 OpenAI 工程師,但我想談談他們可能使 GPT-4 更像一個推理模型的一些方法。
就像Google在搜索中追求算法的完美,希望在鏈接等排名中擺脫人為因素一樣,OpenAI也致力於解決LLM模型的弱點。
OpenAI 有兩種方式可以為 ChatGPT 提供更好的“推理”能力:
- 使用 GPT 本身或使用外部工具(即其他機器學習算法)。
- 使用其他非 LLM 代碼解決方案。
在第一組中,OpenAI 對模型進行相互微調。 這實際上就是 ChatGPT 和普通 GPT 之間的區別。
Plain GPT 是一個簡單地輸出句子後可能的下一個標記的引擎。 另一方面,ChatGPT 是一個根據命令和後續步驟進行訓練的模型。
將 GPT 稱為“花哨的自動更正”的一個問題是這些層之間交互的方式以及這種規模的模型識別模式並將其應用於不同上下文的深層能力。
該模型能夠在答案、對如何提出的問題的期望以及上下文不同的問題之間建立聯繫。
即使沒有人問過“用海豚的比喻來解釋統計數據”,GPT 也可以全面理解這些聯繫並對其進行擴展。 它知道用隱喻解釋主題的方式、統計數據的工作原理以及海豚是什麼。
然而,任何經常接觸 GPT 的人都知道,您從 GPT 培訓材料中獲得的知識越多,結果就越糟糕。
OpenAI 有一個在各個層上進行訓練的模型,涉及:
- 對話。
- 避免任何有爭議的回應。
- 使其保持在指導方針範圍內。
任何花時間嘗試讓 GPT 在其參數之外運行的人都會告訴您,上下文和命令是無限模塊化的。 人類富有創造力,可以設計出無數種打破規則的方法。
這一切意味著 OpenAI 可以訓練法學碩士進行“推理”,方法是讓其接受多層推理,使其模仿和識別模式。
記住答案,而不是理解它們。
OpenAI 為其模型添加推理功能的另一種方式是使用其他元素。 但這些都有自己的一系列問題。 您可以看到 OpenAI 嘗試通過使用插件來解決非 GPT 解決方案的 GPT 問題。
鏈接閱讀器插件是 ChatGPT (GPT-4) 的插件。 它允許用戶向 ChatGPT 添加鏈接,代理訪問該鏈接並獲取內容。 但 GPT 是如何做到這一點的呢?
該插件遠非“思考”並決定訪問這些鏈接,而是假設每個鏈接都是必要的。
分析文本時,會訪問鏈接並將 HTML 轉儲到輸入中。 很難更優雅地集成這些類型的插件。
例如,Bing 插件允許您使用 Bing 進行搜索,但代理會假設您想要比相反的搜索頻率更高。
這是因為即使經過層層訓練,也很難確保 GPT 的響應一致。 如果您使用 OpenAI API,這可能會立即出現。 你可以標記“作為一個開放的人工智能模型”,但有些回復會有其他句子結構和不同的拒絕方式。
這使得機械代碼響應難以編寫,因為它需要一致的輸入。
如果您想將搜索與 OpenAI 應用程序集成,什麼樣的觸發器會觸發搜索功能?
如果您想在文章中談論搜索怎麼辦? 同樣,對輸入進行分塊可能很困難,因為。
ChatGPT 很難區分提示的不同部分,因為這些模型很難區分幻想和現實。
儘管如此,讓 GPT 進行推理的最簡單方法是集成一些更擅長推理的東西。 這仍然是說起來容易做起來難。
Ryan Jones 在 Twitter 上對此發表了一篇很好的帖子:
然後我們回到法學碩士如何運作的問題。
沒有計算器,沒有思考過程,只是根據大量文本猜測下一個術語。
案例 3:GPT 與謎語
我最喜歡這類事情的案例? 兒童謎語。
每組四個單詞中有一個不屬於。 哪個詞不屬於?
- 綠色、黃色、紅色、藍色。
- 四月、十二月、十一月、六月。
- 卷雲、微積分、積雲、層雲。
- 胡蘿蔔、蘿蔔、土豆、捲心菜。
- 叉子、梳子、耙子、鏟子。
花點時間考慮一下。 問一個孩子。
以下是實際答案:
- 綠色的。 黃色、紅色和藍色是原色。 綠色則不然。
- 十二月。 其他月份只有30天。
- 結石。 其他都是雲類型。
- 捲心菜。 其他的是生長在地下的蔬菜。
- 鏟。 其他的都有尖頭。
現在讓我們看看 GPT 的一些回應:

有趣的是這個答案的形狀是正確的。 它得到的正確答案是“不是原色”,但上下文不足以讓它知道什麼是原色或什麼是顏色。
這就是您所說的一次性查詢。 我不會向模型提供額外的細節,並希望它能夠獨立地解決問題。 但是,正如我們在之前的答案中所看到的,GPT 可能會因過度提示而出錯。
GPT 並不聰明。 雖然令人印象深刻,但它並不像它想要的那樣“通用”。
它不知道自己所說或所做的內容的上下文,也不知道單詞是什麼。
對於 GPT 來說,世界就是數學。
令牌只是一起跳舞的向量,代表著大量互連點的網絡。

LLM 並不像 聰明如你所想
在法庭案件中使用 ChatGPT 的律師表示,他“認為這是一個搜索引擎”。
這個引人注目的職業瀆職案件很有趣,但我對其中的影響感到恐懼。
一位從事高技能、高薪工作的律師(一位主題專家)向法庭提交了此信息。
全國各地有數百人在做同樣的事情,因為它幾乎就像一個搜索引擎,看起來很人性化,而且看起來很正確。
網站內容可能具有很高的風險——一切都可能如此。 網上的錯誤信息已經十分猖獗,而 ChatGPT 正在蠶食剩下的東西。
我們必須從沉船上收集金屬,因為它沒有經過輻射。
同樣,2022 年之前的數據將成為熱門商品,因為它源於文本的本意——獨特、人性化和真實。
很多此類討論似乎源於幾個根本原因,即對 GPT 工作原理和用途的誤解。
在某種程度上,OpenAI 可以為這些誤解承擔責任。 他們非常希望開發通用人工智能,以至於很難接受 GPT 的弱點。
GPT 是“萬物之主”,因此不能成為任何事物的主宰。
如果它不能說髒話,它就無法審核內容。
如果它必須說實話,它就不能寫小說。
如果它必須服從用戶,它就不可能總是準確的。
GPT不是搜索引擎、聊天機器人、你的朋友、通用智能,甚至不是花哨的自動更正。
它是大規模應用的統計數據,通過擲骰子來造句。 但關於機會的問題是,有時你會做出錯誤的決定。
本文表達的觀點是客座作者的觀點,並不一定是搜索引擎土地的觀點。 此處列出了工作人員作者。