
了解大型語言模型 (LLM) 的 SEO 指南
已發表: 2023-05-08我應該使用大型語言模型進行關鍵詞研究嗎? 這些模型能思考嗎? ChatGPT 是我的朋友嗎?
如果您一直在問自己這些問題,那麼本指南適合您。
本指南涵蓋了 SEO 需要了解的有關大型語言模型、自然語言處理以及介於兩者之間的所有內容。
大型語言模型、自然語言處理等簡單術語
有兩種方法可以讓一個人做某事——告訴他們去做或希望他們自己做。
說到計算機科學,編程是告訴機器人去做,而機器學習是希望機器人自己去做。 前者是有監督的機器學習,後者是無監督的機器學習。
自然語言處理 (NLP) 是一種將文本分解為數字然後使用計算機對其進行分析的方法。
計算機分析單詞中的模式,隨著它們變得更高級,還會分析單詞之間的關係。
可以在許多不同類型的數據集上訓練無監督的自然語言機器學習模型。
例如,如果您根據電影“水世界”的平均評論訓練語言模型,您將獲得擅長撰寫(或理解)電影“水世界”評論的結果。
如果你根據我對電影《水世界》的兩條正面評價對其進行訓練,它只會理解那些正面評價。
大型語言模型 (LLM) 是具有超過十億個參數的神經網絡。 它們是如此之大,以至於它們更加普遍。 他們不僅接受了關於“水世界”正面和負面評論的培訓,還接受了評論、維基百科文章、新聞網站等方面的培訓。
機器學習項目經常與上下文一起工作——上下文內外的事物。
如果你有一個機器學習項目可以識別錯誤並給它看一隻貓,那麼它不會擅長那個項目。
這就是為什麼像自動駕駛汽車這樣的東西如此困難:有太多脫離背景的問題以至於很難概括這些知識。
法學碩士似乎並且可以 比其他機器學習項目更通用。 這是因為數據的龐大規模以及處理數十億種不同關係的能力。
讓我們談談實現這一點的突破性技術之一——變壓器。
從頭開始解釋變壓器
作為一種神經網絡架構,Transformer 徹底改變了 NLP 領域。
在 Transformer 出現之前,大多數 NLP 模型都依賴於一種稱為遞歸神經網絡 (RNN) 的技術,該技術按順序處理文本,一次一個詞。 這種方法有其局限性,例如速度慢並且難以處理文本中的遠程依賴關係。
變形金剛改變了這一點。
在 2017 年具有里程碑意義的論文“Attention is All You Need”中,Vaswani 等人。 介紹了transformer架構。
Transformer 不是按順序處理文本,而是使用一種稱為“自註意力”的機制來並行處理單詞,從而使它們能夠更有效地捕獲遠程依賴關係。
以前的架構包括 RNN 和長短期記憶算法。
像這樣的循環模型曾經(現在仍然)常用於涉及數據序列的任務,例如文本或語音。
然而,這些模型有一個問題。 他們一次只能處理一個數據,這會減慢他們的速度並限制他們可以處理的數據量。 這種順序處理確實限制了這些模型的能力。
引入註意力機製作為處理序列數據的不同方式。 它們允許模型一次查看所有數據片段並確定哪些片段最重要。
這在許多任務中確實很有幫助。 然而,大多數使用注意力的模型也使用循環處理。
基本上,他們有這種一次性處理數據的方式,但仍然需要按順序查看。 Vaswani 等人的論文浮出水面,“如果我們只使用注意力機制呢?”
注意力是模型在處理輸入序列時將注意力集中在輸入序列的某些部分的一種方式。 例如,當我們閱讀一個句子時,我們自然會比其他詞更注意某些詞,這取決於上下文和我們想要理解的內容。
如果你看一個轉換器,模型會根據輸入序列中每個詞對理解序列整體含義的重要性來計算它的分數。
然後,該模型使用這些分數來衡量序列中每個單詞的重要性,使其更多地關注重要的單詞,而不是不重要的單詞。
這種注意力機制有助於模型捕獲輸入序列中可能相距很遠的單詞之間的遠程依賴關係和關係,而無需按順序處理整個序列。
這使得轉換器對於自然語言處理任務非常強大,因為它可以快速準確地理解句子或較長文本序列的含義。
讓我們以處理“The cat sat on the mat”這句話的 transformer 模型為例。
句子中的每個單詞都使用嵌入矩陣表示為一個向量,一系列數字。 假設每個詞的嵌入是:
- : [0.2, 0.1, 0.3, 0.5]
- 貓:[0.6,0.3,0.1,0.2]
- 坐:[0.1,0.8,0.2,0.3]
- 上:[0.3,0.1,0.6,0.4]
- : [0.5, 0.2, 0.1, 0.4]
- 墊子:[0.2、0.4、0.7、0.5]
然後,轉換器根據句子中每個單詞與句子中所有其他單詞的關係計算句子中每個單詞的分數。
這是使用每個詞的嵌入與句子中所有其他詞的嵌入的點積來完成的。
例如,要計算單詞“cat”的分數,我們將使用它的嵌入與所有其他單詞的嵌入的點積:
- “貓”:0.2*0.6 + 0.1*0.3 + 0.3*0.1 + 0.5*0.2 = 0.24
- “貓坐著”:0.6*0.1 + 0.3*0.8 + 0.1*0.2 + 0.2*0.3 = 0.31
- “貓在”:0.6*0.3 + 0.3*0.1 + 0.1*0.6 + 0.2*0.4 = 0.39
- “貓”:0.6*0.5 + 0.3*0.2 + 0.1*0.1 + 0.2*0.4 = 0.42
- “貓墊”:0.6*0.2 + 0.3*0.4 + 0.1*0.7 + 0.2*0.5 = 0.32
這些分數表示每個單詞與單詞“cat”的相關性。 然後,轉換器使用這些分數來計算詞嵌入的加權和,其中權重是分數。
這為單詞“cat”創建了一個上下文向量,考慮了句子中所有單詞之間的關係。 對句子中的每個單詞重複此過程。
可以把它想像成轉換器根據每次計算的結果在句子中的每個單詞之間畫一條線。 有些線條比較脆弱,有些則不那麼脆弱。
Transformer 是一種新型模型,它只使用注意力而不進行任何循環處理。 這使得它更快並且能夠處理更多數據。
GPT 如何使用轉換器
你可能還記得,在谷歌的 BERT 公告中,他們吹噓它允許搜索理解輸入的完整上下文。 這類似於 GPT 使用轉換器的方式。
讓我們打個比方。
想像你有一百萬隻猴子,每隻都坐在鍵盤前。
每隻猴子隨機敲擊鍵盤上的鍵,生成一串字母和符號。
有些字符串完全是無稽之談,而另一些可能類似於真實的單詞甚至是連貫的句子。
一天,一位馬戲團訓練員看到一隻猴子寫下了“生存或毀滅”,於是訓練員給了這隻猴子一份款待。
其他猴子看到這一點並開始嘗試模仿成功的猴子,希望自己得到款待。
隨著時間的推移,一些猴子開始不斷地產生更好、更連貫的文本字符串,而其他猴子則繼續產生胡言亂語。
最終,猴子可以識別甚至模仿文本中連貫的模式。
法學碩士比猴子更有優勢,因為法學碩士首先接受了數十億段文本的訓練。 他們已經可以看到模式。 他們還了解這些文本片段之間的向量和關係。
這意味著他們可以使用這些模式和關係來生成類似於自然語言的新文本。
GPT全稱Generative Pre-trained Transformer,是一種使用轉換器生成自然語言文本的語言模型。
它接受了來自互聯網的大量文本的訓練,這使其能夠學習自然語言中單詞和短語之間的模式和關係。
該模型的工作原理是接收提示或文本中的幾個詞,並使用轉換器根據從訓練數據中學到的模式來預測接下來應該出現什麼詞。
該模型繼續逐字生成文本,使用前一個詞的上下文來通知下一個詞。
GPT 在行動
GPT 的好處之一是它可以生成高度連貫且上下文相關的自然語言文本。
這有很多實際應用,例如生成產品描述或回答客戶服務查詢。 它還可以創造性地使用,例如生成詩歌或短篇小說。
然而,它只是一個語言模型。 它根據數據進行訓練,並且該數據可能已過時或不正確。
- 它沒有知識來源。
- 它無法搜索互聯網。
- 它什麼都“不知道”。
它只是猜測下一個單詞是什麼。
讓我們看一些例子:
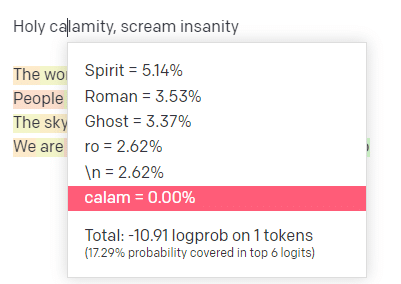
在 OpenAI playground 中,我插入了帥哥模特學校的經典曲目“聖劫[[Bear Witness ii]]”的第一行。
我提交了回复,這樣我們就可以看到我的輸入和輸出行的可能性。 因此,讓我們來看看這告訴我們的每一部分。
對於第一個詞/標記,我輸入“神聖”。 我們可以看到最期待的下一個輸入是 Spirit、Roman 和 Ghost。
我們還可以看到,前六個結果僅涵蓋接下來發生的概率的 17.29%:這意味著我們在此可視化中看不到約 82% 的其他可能性。
讓我們簡要討論一下您可以在此使用的不同輸入以及它們如何影響您的輸出。
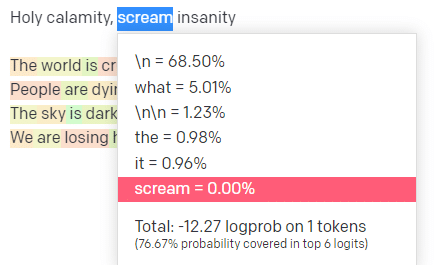
溫度是模型抓住概率最高的詞以外的詞的可能性, top P是它選擇這些詞的方式。
因此,對於輸入“Holy Calamity”,top P 是我們如何選擇下一個標記 [Ghost、Roman、Spirit] 的集群,而溫度是選擇最有可能的標記與更多種類的可能性。
如果溫度更高,則更有可能選擇不太可能的令牌。
所以高溫和高頂P可能會更狂野。 它從各種各樣的(高P)中進行選擇,並且更有可能選擇令人驚訝的代幣。


雖然高溫但較低的最高 P 會從較小的可能性樣本中選擇令人驚訝的選項:

降低溫度只會選擇最有可能的下一個標記:

在我看來,使用這些概率可以讓您深入了解這些模型的工作原理。
它正在根據已經完成的內容查看可能的下一個選擇集合。
這實際上意味著什麼?
簡而言之,LLM 接受一組輸入,將它們搖勻並將它們轉化為輸出。
我聽過人們開玩笑說這是否與人如此不同。
但這不像人——法學碩士沒有知識基礎。 他們不是在提取有關事物的信息。 他們根據最後一個單詞猜測一系列單詞。
另一個例子:想想一個蘋果。 想到什麼?
也許你可以在腦海中旋轉一個。
也許你還記得蘋果園的氣味、粉紅女士的甜美等等。
也許你會想到史蒂夫·喬布斯。
現在讓我們看看提示“think of an apple”返回了什麼。
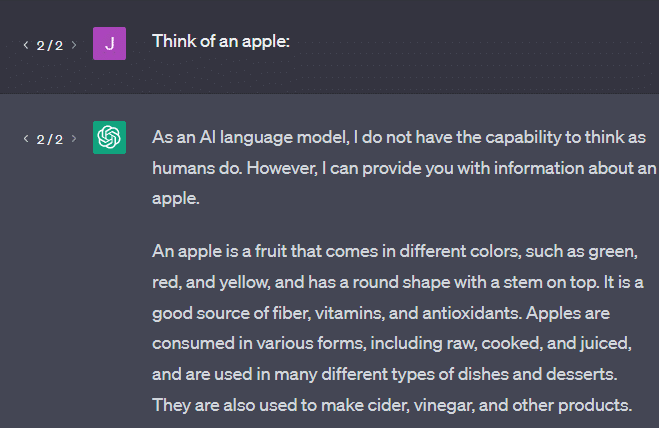
此時你可能已經聽說過“隨機鸚鵡”這個詞。
Stochastic Parrots 是一個術語,用於描述像 GPT 這樣的 LLM。 鸚鵡是一種模仿它所聽到的東西的鳥。
因此,LLM 就像鸚鵡一樣,它們接收信息(單詞)並輸出類似於他們所聽到的內容。 但它們也是隨機的,這意味著它們使用概率來猜測接下來會發生什麼。
LLM 擅長識別單詞之間的模式和關係,但他們對所看到的內容沒有任何更深入的理解。 這就是為什麼他們非常擅長生成自然語言文本但卻無法理解它。
法學碩士的良好用途
法學碩士擅長更通才的任務。
您可以向它顯示文本,無需訓練,它就可以使用該文本完成一項任務。
您可以向它發送一些文本並要求進行情緒分析,要求它將該文本轉換為結構化標記並進行一些創造性工作(例如,編寫提綱)。
像代碼這樣的東西沒問題。 對於許多任務,它幾乎可以讓您到達那裡。
但同樣,它基於概率和模式。 因此,有時它會在您的輸入中發現您不知道的模式。
這可以是積極的(看到人類看不到的模式),但也可以是消極的(為什麼它會這樣反應?)。
它也無法訪問任何類型的數據源。 使用它來查找排名關鍵字的 SEO 會遇到麻煩。
它無法查找關鍵字的流量。 它沒有超出該詞存在的關鍵字數據的信息。

ChatGPT 令人興奮的一點是,它是一種易於使用的語言模型,您可以開箱即用地執行各種任務。 但這並非沒有警告。

其他 ML 模型的良好用途
我聽到人們說他們正在使用 LLM 來完成某些任務,而其他 NLP 算法和技術可以做得更好。
舉個例子,關鍵詞提取。
如果我使用 TF-IDF 或其他關鍵字技術從語料庫中提取關鍵字,我知道該技術進行了哪些計算。
這意味著結果將是標準的、可重現的,而且我知道它們將與該語料庫具體相關。
對於像 ChatGPT 這樣的 LLM,如果您要求提取關鍵字,則不一定會從語料庫中提取關鍵字。 您得到的是 GPT認為對語料庫 + 提取關鍵字的響應。
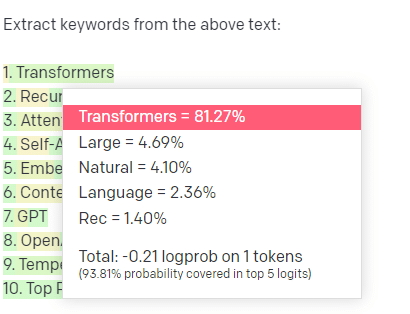
這類似於聚類或情感分析等任務。 您不一定會使用您設置的參數獲得微調的結果。 你得到的是基於其他類似任務的一些可能性。
同樣,法學碩士沒有知識庫,也沒有最新信息。 他們通常無法搜索網絡,並且他們將從信息中獲得的信息解析為統計標記。 由於這些因素,LLM 的記憶持續時間受到限制。
另一件事是這些模型無法思考。 在這篇文章中,我只用了幾次“思考”這個詞,因為在談論這些過程時真的很難不使用它。
趨勢是擬人化,即使在討論花哨的統計數據時也是如此。
但這意味著,如果你將任何需要“思考”的任務委託給法學碩士,你就不是在信任一個會思考的生物。
您相信對數百個互聯網怪人對類似標記的響應的統計分析。
如果您願意委託互聯網用戶完成一項任務,那麼您可以使用法學碩士。 否則…
永遠不應該是 ML 模型的東西
據報導,通過 GPT 模型 (GPT-J) 運行的聊天機器人鼓勵一名男子自殺。 多種因素的結合可能會造成真正的傷害,包括:
- 人們將這些反應擬人化。
- 相信他們是絕對可靠的。
- 在人類需要在機器中的地方使用它們。
- 和更多。
雖然您可能會想,“我是一名 SEO。 我沒有參與可以殺人的系統!”
想想 YMYL 頁面以及 Google 如何推廣 EEAT 等概念。
谷歌這樣做是因為他們想惹惱 SEO,還是因為他們不想為這種傷害承擔責任?
即使在具有強大知識庫的系統中,也可能造成傷害。
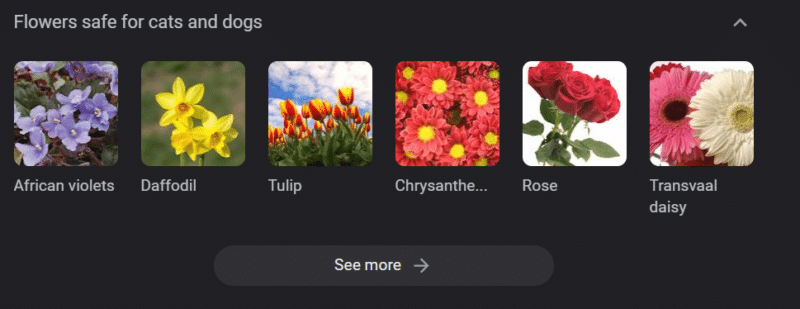
以上是“對貓和狗安全的花”的谷歌知識輪播。 儘管水仙花對貓有毒,但它仍在該名單上。
假設您正在使用 GPT 為獸醫網站大規模生成內容。 您插入一堆關鍵字並 ping ChatGPT API。
你有一個自由職業者閱讀了所有的結果,他們不是學科專家。 他們不接受一個問題。
您發布結果,鼓勵貓主人購買水仙花。
你殺了別人的貓。
不直接。 也許他們甚至不知道是那個網站。
也許其他獸醫網站開始做同樣的事情並互相餵養。
谷歌搜索“水仙花對貓有毒嗎”的頂部是一個網站,上面寫著它們沒有毒。
其他自由職業者閱讀其他 AI 內容——一頁又一頁地閱讀 AI 內容——實際上是在核查事實。 但是系統現在有不正確的信息。
在討論當前的人工智能熱潮時,我經常提到 Therac-25。 這是一個著名的計算機瀆職案例研究。
基本上,它是一台放射治療機,是第一台僅使用計算機鎖定機制的機器。 軟件中的一個故障意味著人們受到的輻射劑量是他們應該接受的數万倍。
一直讓我印象深刻的是,該公司自願召回並檢查了這些模型。
但他們認為,由於技術先進且軟件“絕對可靠”,問題與機器的機械部件有關。
因此,他們修復了機械裝置但沒有檢查軟件——Therac-25 留在了市場上。
常見問題和誤解
為什麼 ChatGPT 對我撒謊?
我從我們這一代最偉大的思想家以及 Twitter 上的影響者那裡看到的一件事是抱怨 ChatGPT 對他們“撒謊”。 這是由於一系列的誤解造成的:
- ChatGPT 有“想要的”。
- 它有一個知識庫。
- 技術背後的技術專家除了“賺錢”或“做一件很酷的事情”之外還有某種議程。
偏見滲透到你日常生活的方方面面。 這些偏見的例外情況也是如此。
目前大多數軟件開發人員都是男性:我是一名軟件開發人員,也是一名女性。
基於這種現實訓練人工智能會導致它總是假設軟件開發人員是男性,這是不正確的。
一個著名的例子是亞馬遜的招聘人工智能,它是根據成功的亞馬遜員工的簡歷進行訓練的。
這導致它丟棄了大多數黑人大學的簡歷,儘管其中許多員工本可以非常成功。
為了消除這些偏見,ChatGPT 等工具使用了多層微調。 這就是為什麼您會得到“作為 AI 語言模型,我不能……”的回應。
肯尼亞的一些工人不得不接受數百個提示,尋找誹謗、仇恨言論以及完全糟糕的回應和提示。
然後創建了一個微調層。
為什麼你不能彌補對喬·拜登的侮辱? 為什麼你可以開關於男人而不是女人的性別歧視笑話?
這不是由於自由主義偏見,而是因為數千層微調告訴 ChatGPT 不要說 N 字。
理想情況下,ChatGPT 對世界完全保持中立,但他們也需要它來反映世界。
這與 Google 遇到的問題類似。
什麼是真實的,什麼能讓人們開心,什麼能對提示做出正確的反應,這些往往是截然不同的事情。
為什麼 ChatGPT 會提出虛假引用?
我經常看到的另一個問題是關於虛假引用。 為什麼有的是假的,有的是真的? 為什麼有些網站是真實的,但頁面是假的?
希望通過閱讀統計模型的工作原理,您可以解析它。 但這裡有一個簡短的解釋:
你是一個 AI 語言模型。 您已經在大量網絡上接受過培訓。
有人告訴你寫技術方面的東西——比如說 Cumulative Layout Shift。
你沒有大量 CLS 論文的例子,但你知道它是什麼,並且你知道一篇關於技術的文章的一般形式。 你知道這種文章是什麼樣的模式。

所以你開始你的回應並遇到了一種問題。 以您理解技術寫作的方式,您知道 URL 應該放在句子的下一個位置。
那麼,從其他 CLS 文章中,您知道 Google 和 GTMetrix 經常被引用關於 CLS,所以這些很容易。
但是您也知道 CSS 技巧經常在網絡文章中鏈接到:您知道 CSS 技巧 URL 通常看起來是某種方式:所以您可以像這樣構建 CSS 技巧 URL:
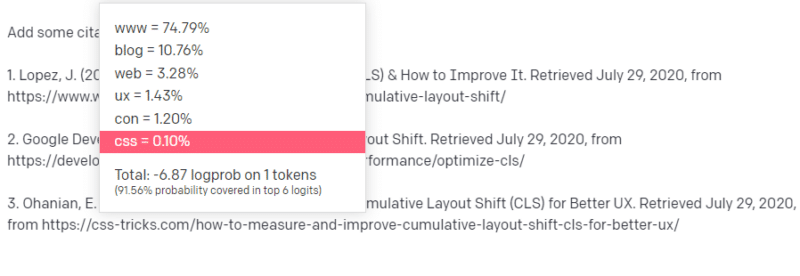
訣竅是:這是所有URL 的構造方式,而不僅僅是假的:

這篇 GTMetrix 文章確實存在:但它存在是因為它可能是這句話末尾的一串值。
GPT 和類似模型無法區分真引文和假引文。
進行該建模的唯一方法是使用其他來源(知識庫、Python 等)來解析差異並檢查結果。
什麼是“隨機鸚鵡”?
我知道我已經討論過了,但值得重複。 Stochastic Parrots 是一種描述當大型語言模型本質上看起來是通才時會發生什麼的方法。
對LLM來說,廢話和現實是一樣的。 他們像經濟學家一樣看待世界,將其視為一堆描述現實的統計數據和數字。
你知道這句話,“謊言分三種:謊言、該死的謊言和統計數據。”
法學碩士是一大堆統計數據。
法學碩士似乎是連貫的,但那是因為我們從根本上將看似人類的事物視為人類。
同樣,聊天機器人模型混淆了 GPT 響應完全連貫所需的大部分提示和信息。
我是一名開發人員:嘗試使用 LLM 來調試我的代碼會產生極其多變的結果。 如果這是一個類似於人們經常在網上遇到的問題,那麼 LLM 可以選擇並修復該結果。
如果這是一個以前沒有遇到過的問題,或者是語料庫的一小部分,那麼它不會解決任何問題。
為什麼 GPT 優於搜索引擎?
我用辛辣的方式措辭。 我不認為 GPT 比搜索引擎更好。 讓我擔心的是人們已經用 ChatGPT 代替了搜索。
ChatGPT 的一個未被充分認識的部分是遵循說明的存在程度。 你可以要求它基本上做任何事情。
但請記住,這都是基於句子中下一個單詞的統計結果,而不是事實。
因此,如果你問它一個沒有好的答案的問題,但以它有義務回答的方式問它,你將得到一個糟糕的答案。
為你和你周圍的人設計一個回應會更令人欣慰,但世界是一堆經驗。
LLM 的所有輸入都受到相同的對待:但有些人有經驗,他們的反應會比其他人的反應更好。
一位專家的價值超過一千條思想。
這是人工智能的曙光嗎? 天網在嗎?
大猩猩可可是一隻學會了手語的猿猴。 語言學研究人員做了大量研究表明可以教猿類語言。
Herbert Terrace 隨後發現類人猿並沒有組合句子或單詞,而只是模仿它們的人類馴養員。
Eliza 是一名機器治療師,是最早的聊天機器人(chatbots)之一。
人們將她視為一個人:他們信任和關心的治療師。 他們要求研究人員與她單獨相處。
語言對人們的大腦有非常特殊的作用。 人們聽到一些交流並期待其背後的想法。
法學碩士令人印象深刻,但在某種程度上顯示了人類成就的廣度。
法學碩士沒有遺囑。 他們逃不掉。 他們不能試圖接管世界。
它們是一面鏡子:具體反映人和用戶。
唯一的想法是集體無意識的統計表示。
GPT 是自己學會了一門完整的語言嗎?
Google 首席執行官 Sundar Pichai 在“60 分鐘”節目中聲稱 Google 的語言模型學會了孟加拉語。
該模型是在這些文本上訓練的。 它“說一種從未受過訓練的外語”是不正確的。
有時 AI 會做出意想不到的事情,但這本身就是意料之中的事情。
當您查看大規模的模式和統計數據時,這些模式必然會揭示一些令人驚訝的東西。
這真正揭示的是,許多兜售 AI 和 ML 的高管和營銷人員實際上並不了解這些系統的工作原理。
我聽過一些非常聰明的人談論湧現屬性、通用人工智能 (AGI) 和其他未來主義事物。
我可能只是一個普通的國家 ML 操作工程師,但它顯示了在談論這些系統時有多少炒作、承諾、科幻小說和現實被混為一談。
Theranos 臭名昭著的創始人伊麗莎白·霍姆斯 (Elizabeth Holmes) 因做出無法兌現的承諾而被釘在十字架上。
但做出不可能的承諾的循環是創業文化和賺錢的一部分。 Theranos 和 AI 炒作的不同之處在於,Theranos 無法長期偽造它。
GPT 是黑盒子嗎? 我在 GPT 中的數據會怎樣?
作為模型,GPT 不是黑匣子。 您可以查看 GPT-J 和 GPT-Neo 的源代碼。
然而,OpenAI 的 GPT 是一個黑盒子。 OpenAI 還沒有並且可能會嘗試不發布其模型,因為谷歌不發布算法。
但這並不是因為該算法太危險了。 如果那是真的,他們就不會向任何擁有計算機的傻瓜出售 API 訂閱。 這是因為專有代碼庫的價值。
當您使用 OpenAI 的工具時,您是在根據您的輸入訓練和提供他們的 API。 這意味著您放入 OpenAI 的所有內容都可以滿足它的需求。
這意味著那些在患者數據上使用 OpenAI 的 GPT 模型來幫助寫筆記和其他事情的人違反了 HIPAA。 該信息現在位於模型中,提取它非常困難。
因為很多人難以理解這一點,很可能該模型包含大量私人數據,只是等待正確的提示來發布它。
為什麼 GPT 接受仇恨言論訓練?
另一件經常出現的事情是,GPT 訓練的文本語料庫包括仇恨言論。
在某種程度上,OpenAI 需要訓練其模型來響應仇恨言論,因此它需要一個包含其中一些術語的語料庫。
OpenAI 聲稱從系統中清除了這種仇恨言論,但源文件包括 4chan 和大量仇恨網站。
爬網,吸收偏見。
沒有簡單的方法可以避免這種情況。 如果不將其作為訓練集的一部分,您如何能夠識別或理解仇恨、偏見和暴力?
當您作為機器代理以統計方式選擇句子中的下一個標記時,您如何避免偏見並理解隱式和顯式偏見?
長話短說
炒作和錯誤信息是目前人工智能繁榮的主要因素。 這並不意味著沒有合法用途:這項技術令人驚嘆且有用。
但該技術的營銷方式以及人們的使用方式可能助長錯誤信息、剽竊甚至造成直接傷害。
生死攸關時不要使用法學碩士。 當不同的算法會做得更好時,不要使用 LLM。 不要被炒作所欺騙。
了解什麼是法學碩士——什麼不是——是必要的
我推薦 Adam Conover 採訪 Emily Bender 和 Timnit Gebru。
如果使用得當,LLM 可以成為不可思議的工具。 您可以通過多種方式使用 LLM,甚至可以通過更多方式濫用 LLM。
ChatGPT 不是你的朋友。 這是一堆統計數據。 AGI 並非“已經存在”。
本文中表達的觀點是客座作者的觀點,不一定是 Search Engine Land。 此處列出了工作人員作者。