
Spark vs Hadoop:哪個大數據框架將提升您的業務?
已發表: 2019-09-24“數據是數字經濟的燃料”
隨著現代企業依靠大量數據來更好地了解他們的消費者和市場,大數據等技術正在獲得巨大的發展勢頭。
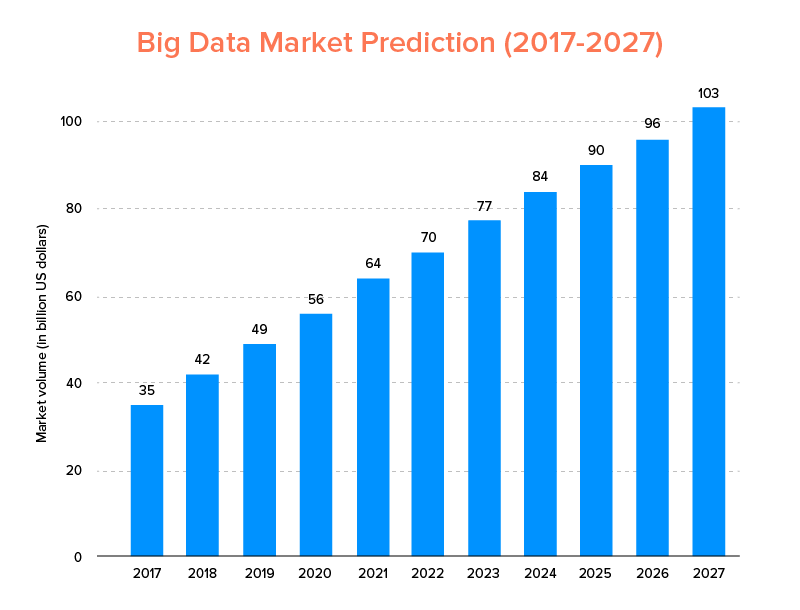
大數據,就像人工智能一樣,不僅進入了2020 年的頂級技術趨勢,而且預計將被初創公司和財富 500 強公司所接受,以享受指數級的業務增長並確保更高的客戶忠誠度。 一個明確的跡像是,到 2027 年,大數據市場預計將達到 $103B。
現在,雖然一方面每個人都非常有動力用大數據取代他們的傳統數據分析工具——大數據為區塊鍊和人工智能的發展奠定了基礎,但他們也對選擇正確的大數據工具感到困惑。 他們面臨著在大數據世界的兩大巨頭 Apache Hadoop 和 Spark 之間進行選擇的困境。
因此,考慮到這個想法,今天我們將介紹一篇關於 Apache Spark 與 Hadoop 的文章,並幫助您確定哪一個是滿足您需求的正確選擇。
但是,首先讓我們簡單介紹一下什麼是 Hadoop 和 Spark。
Apache Hadoop 是一個開源、分佈式和基於 Java 的框架,使用戶能夠使用簡單的編程結構跨多個計算機集群存儲和處理大數據。 它由各種模塊組成,這些模塊協同工作以提供增強的體驗,它們是:-
- Hadoop 通用
- Hadoop 分佈式文件系統 (HDFS)
- Hadoop 紗線
- Hadoop MapReduce
鑑於 Apache Spark 是一個開源分佈式集群計算大數據框架,它“易於使用”並提供更快的服務。
由於它們提供的一系列機會,這兩個大數據框架得到了眾多大公司的支持。
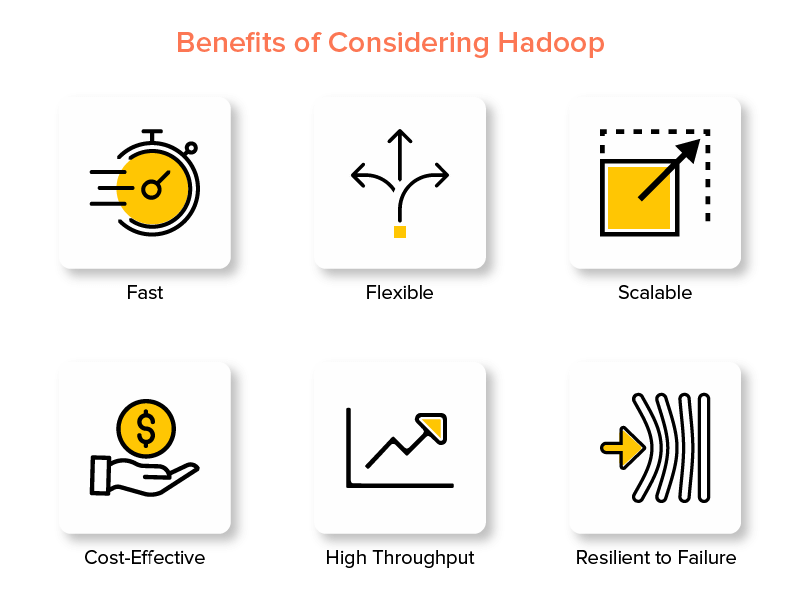
Hadoop大數據框架的優勢
1.快
Hadoop 在大數據世界中流行的特點之一是速度快。
它的存儲方法基於分佈式文件系統,該系統主要“映射”位於集群上任何位置的數據。 此外,用於數據處理的數據和工具通常在同一台服務器上可用,這使得數據處理成為一項輕鬆快捷的任務。
事實上,已經發現 Hadoop 可以在短短幾分鐘內處理 TB 級的非結構化數據,而 PB 級的數據則需要幾小時。
2.靈活
與傳統的數據處理工具不同,Hadoop 提供了高端的靈活性。
它允許企業從不同來源(如社交媒體、電子郵件等)收集數據,使用不同的數據類型(結構化和非結構化),並獲得有價值的見解以進一步用於各種目的(如日誌處理、市場活動分析、欺詐檢測等)。
3.可擴展
Hadoop 的另一個優點是它具有高度可擴展性。 與傳統的關係數據庫系統 (RDBMS)不同,該平台使企業能夠存儲和分發來自數百台並行運行的服務器的大型數據集。
4.具有成本效益
與其他大數據分析工具相比,Apache Hadoop 便宜得多。 這是因為它不需要任何專門的機器; 它在一組商品硬件上運行。 此外,從長遠來看,添加更多節點更容易。
這意味著,一種情況很容易增加節點,而不會受到任何預先計劃要求的停機時間的影響。
5.高吞吐量
在 Hadoop 框架的情況下,數據以分佈式方式存儲,以便將一個小作業並行拆分為多個數據塊。 這使企業更容易在更短的時間內完成更多工作,最終提高吞吐量。
6.對失敗有彈性
最後但同樣重要的是,Hadoop 提供了高容錯選項,有助於減輕失敗的後果。 它存儲每個塊的副本,以便在任何節點出現故障時恢復數據。
Hadoop框架的缺點
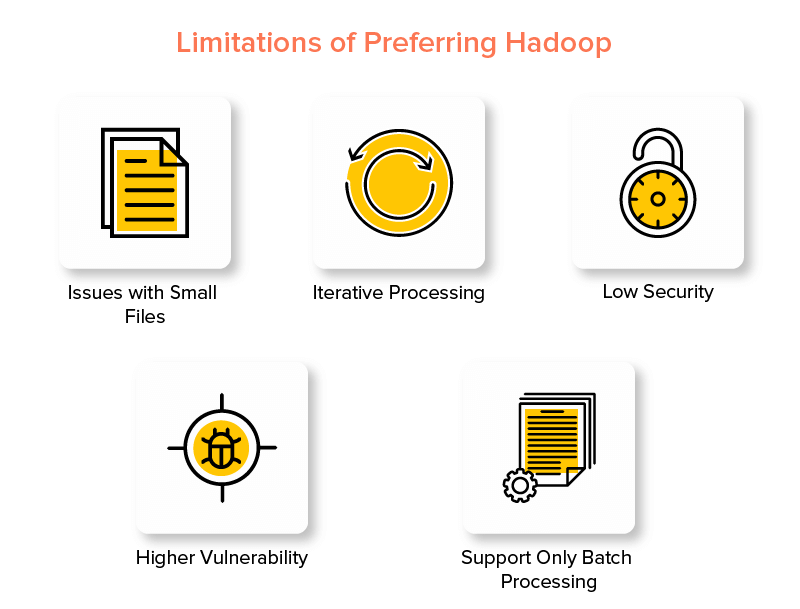
1.小文件的問題
考慮使用 Hadoop 進行大數據分析的最大缺點是它缺乏支持有效地隨機讀取小文件的潛力。
這背後的原因是,小文件的內存大小比 HDFS 塊大小要小。 在這種情況下,如果存儲了大量的小文件,那麼存儲 HDFS 命名空間的NameNode很可能會過載,這實際上不是一個好主意。
2.迭代處理
大數據Hadoop框架中的數據流是鍊式的,一個階段的輸出成為另一個階段的輸入。 而迭代處理中的數據流本質上是循環的。
因此,Hadoop 不適合機器學習或基於迭代處理的解決方案。
3.安全性低
使用 Hadoop 框架的另一個缺點是提供了較低的安全功能。
例如,該框架默認禁用安全模型。 如果使用此大數據工具的人不知道如何啟用它,他們的數據可能會面臨更高的被盜/濫用風險。 此外,Hadoop 不提供存儲和網絡級別的加密功能,這再次增加了數據洩露威脅的機會。
4.更高的脆弱性
Hadoop 框架是用 Java 編寫的,Java 是最流行但被大量利用的編程語言。 這使網絡犯罪分子更容易輕鬆訪問基於 Hadoop 的解決方案並濫用敏感數據。
5.僅支持批處理
與其他各種大數據框架不同,Hadoop 不處理流數據。 它只支持批處理,其背後的原因是 MapReduce 未能最大限度地利用 Hadoop Cluster 的內存。
雖然這都是關於 Hadoop 及其特性和缺點的,但讓我們來看看 Spark 的優缺點,以便輕鬆理解兩者之間的區別。
Apache Spark 框架的好處
1.本質上是動態的
由於 Apache Spark 提供了大約 80 個高級運算符,因此可以用於動態處理數據。 它可以被認為是開發和管理並行應用程序的正確大數據工具。
2.強大
由於其低延遲的內存數據處理能力和各種用於機器學習和圖形分析算法的內置庫的可用性,它可以應對各種分析挑戰。 這使其成為市場上強大的大數據選項。
3.高級分析
Spark 的另一個顯著特點是它不僅鼓勵“MAP”和“reduce”,還支持機器學習(ML)、SQL 查詢、圖算法和流式數據。 這使其適合享受高級分析。
4.可重用性
與 Hadoop 不同,Spark 代碼可以重用於批處理、對流狀態運行臨時查詢、針對歷史數據加入流等等。
5.實時流處理
使用 Apache Spark 的另一個優點是它可以實時處理和處理數據。
6.多語言支持
最後但同樣重要的是,這個大數據分析工具支持多種編碼語言,包括 Java、Python 和 Scala。
Spark 大數據工具的局限性

1.無文件管理流程
使用 Apache Spark 的主要缺點是它沒有自己的文件管理系統。 它依賴於 Hadoop 等其他平台來滿足這一要求。
2.少數算法
在考慮谷本距離等算法的可用性時,Apache Spark 也落後於其他大數據框架。
3.小文件問題
使用 Spark 的另一個缺點是它不能有效地處理小文件。
這是因為它使用 Hadoop 分佈式文件系統 (HDFS) 運行,它發現管理有限數量的大文件而不是大量小文件更容易。
4.沒有自動優化過程
與其他各種大數據和基於雲的平台不同,Spark 沒有任何自動代碼優化過程。 只需手動優化代碼。
5.不適合多用戶環境
由於 Apache Spark 無法同時處理多個用戶,因此在多用戶環境中運行效率不高。 這再次增加了它的局限性。
了解了這兩個大數據框架的基礎知識後,您可能希望熟悉 Spark 和 Hadoop 之間的區別。
因此,讓我們不要再等了,直接進行比較,看看哪一個引領了“Spark 與 Hadoop”之戰。
Spark vs Hadoop:兩種大數據工具如何相互疊加
[表id=38 /]
1.建築
當談到 Spark 和 Hadoop 架構時,即使兩者都在分佈式計算環境中運行,後者也處於領先地位。
之所以如此,是因為 Hadoop 的架構——與 Spark 不同——有兩個主要元素——HDFS(Hadoop 分佈式文件系統)和 YARN(又一個資源協商器)。 在這裡,HDFS 處理跨不同節點的大數據存儲,而 YARN 通過資源分配和作業調度機制處理任務。 然後將這些組件進一步劃分為更多組件,以提供具有容錯等服務的更好解決方案。
2.易用性
Apache Spark 使開發人員能夠在他們的開發環境中引入各種用戶友好的 API,例如 Scala、Python、R、Java 和 Spark SQL。 此外,它還加載了支持用戶和開發人員的交互模式。 這使其易於使用且學習曲線低。
然而,在談到 Hadoop 時,它提供了支持用戶的附加組件,但不是交互模式。 這使得 Spark 在這場“大數據”之戰中戰勝了 Hadoop。
3.容錯性和安全性
雖然 Apache Spark 和 Hadoop MapReduce 都提供容錯功能,但後者贏得了戰鬥。
這是因為必須從頭開始,以防進程在 Spark 環境中的運行過程中崩潰。 但是,當談到 Hadoop 時,他們可以從崩潰本身繼續。
4.性能
在考慮 Spark 與 MapReduce 的性能時,前者勝過後者。
Spark 框架能夠在磁盤上運行速度提高 10 倍,在內存中運行速度提高 100 倍。 這使得管理 100 TB 數據的速度比 Hadoop MapReduce 快 3 倍。
5.數據處理
在 Apache Spark 與 Hadoop 比較期間要考慮的另一個因素是數據處理。
雖然 Apache Hadoop 僅提供批處理的機會,但其他大數據框架支持使用交互式、迭代、流、圖形和批處理。 證明 Spark 是享受更好的數據處理服務的更好選擇。
6.兼容性
Spark 和 Hadoop MapReduce 的兼容性有些相同。
雖然有時,兩個大數據框架都充當獨立的應用程序,但它們也可以一起工作。 Spark 可以在 Hadoop YARN 之上高效運行,而 Hadoop 可以輕鬆與Sqoop和 Flume 集成。 因此,兩者都支持彼此的數據源和文件格式。
7.安全
Spark 環境加載了不同的安全功能,例如事件日誌記錄和使用 javax servlet 過濾器來保護 Web UI。 此外,它鼓勵通過共享密鑰進行身份驗證,並且在與 YARN 和 HDFS 集成時可以利用 HDFS 文件權限、跨模式加密和 Kerberos 的潛力。
而 Hadoop 支持Kerberos身份驗證、第三方身份驗證、常規文件權限和訪問控制列表等,最終提供了更好的安全結果。
因此,在安全性方面考慮 Spark 與 Hadoop 的比較時,後者領先。
8.成本效益
在比較 Hadoop 和 Spark 時,前者需要更多的磁盤內存,而後者需要更多的 RAM。 此外,由於 Spark 與 Apache Hadoop 相比是相當新的,因此使用 Spark 的開發人員較少。
這使得使用 Spark 成為一件昂貴的事情。 這意味著,當人們關注 Hadoop 與 Spark 成本時,Hadoop 提供了具有成本效益的解決方案。
九、市場範圍
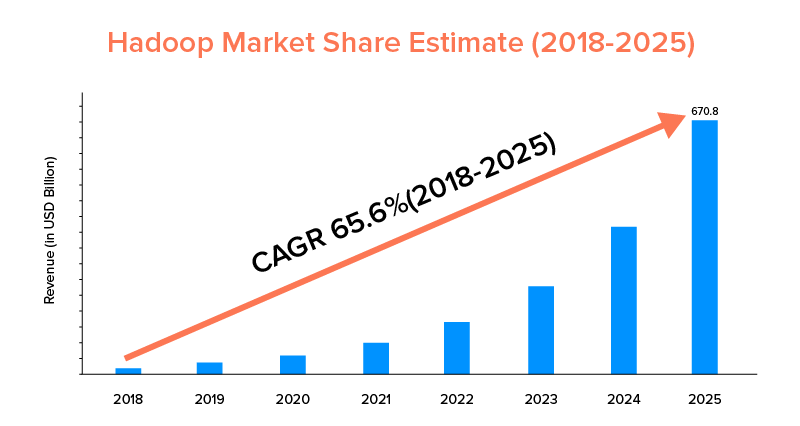
雖然 Apache Spark 和 Hadoop 都得到大公司的支持,並且被用於不同的目的,但後者在市場範圍方面處於領先地位。
根據市場統計,Apache Hadoop 市場預計在 2018 年至 2025 年期間的複合年增長率為 65.6%,而 Spark 的複合年增長率僅為 33.9%。
雖然這些因素將有助於為您的企業確定合適的大數據工具,但熟悉它們的用例是有利可圖的。 所以,讓我們在這裡介紹一下。
Apache Spark 框架的用例
當企業希望:
- 實時流式傳輸和分析數據。
- 享受機器學習的力量。
- 使用交互式分析。
- 將霧和邊緣計算引入他們的商業模式。
Apache Hadoop 框架的用例
當初創公司和企業想要:-
- 分析存檔數據。
- 享受更好的金融交易和預測選項。
- 執行包含商品硬件的操作。
- 考慮線性數據處理。
有了這個,我們希望您已經決定哪一個是與您的業務相關的“Spark 與 Hadoop”之戰的贏家。 如果沒有,請隨時與我們的大數據專家聯繫,以消除所有疑慮並獲得更高成功率的模範服務。
經常問的問題
1. 選擇哪種大數據框架?
選擇完全取決於您的業務需求。 如果你關注性能、數據兼容性和易用性,Spark 比 Hadoop 更好。 然而,當您專注於架構、安全性和成本效益時,Hadoop 大數據框架會更好。
2. Hadoop和Spark有什麼區別?
Spark 和 Hadoop 之間存在各種差異。 例如:-
- Spark 是 Hadoop MapReduce 的 100 倍。
- 雖然 Hadoop 用於批處理,但 Spark 用於批處理、圖形、機器學習和迭代處理。
- Spark 比 Hadoop 大數據框架更緊湊、更簡單。
- 與 Spark 不同,Hadoop 不支持數據緩存。
3. Spark 比 Hadoop 更好嗎?
當您的主要關注點是速度和安全性時,Spark 比 Hadoop 更好。 然而,在其他情況下,這個大數據分析工具落後於 Apache Hadoop。
4. 為什麼 Spark 比 Hadoop 快?
Spark 比 Hadoop 更快,因為磁盤的讀/寫週期數較少,並且將中間數據存儲在內存中。
5. Apache Spark 是做什麼用的?
Apache Spark 用於數據分析,當人們想要 -
- 實時分析數據。
- 將 ML 和霧計算引入您的業務模型。
- 使用交互式分析。