
TW-BERT:端到端查詢詞權重和 Google 搜索的未來
已發表: 2023-09-14正如 Seth Godin 在 2005 年所寫的那樣,搜索是困難的。
我的意思是,如果我們認為 SEO 很難(確實如此),想像一下,如果您試圖在以下世界中構建一個搜索引擎:
- 用戶差異很大,並且他們的偏好會隨著時間的推移而改變。
- 他們使用的搜索技術每天都在進步。
- 競爭對手不斷緊隨你的腳步。
最重要的是,您還要應對討厭的 SEO,他們試圖欺騙您的算法,從而深入了解如何最好地為您的訪問者進行優化。
這會讓事情變得更加困難。
現在想像一下,如果您需要依靠的主要技術有其自身的局限性 - 也許更糟糕的是,成本高昂。
好吧,如果您是最近發表的論文“端到端查詢術語權重”的作者之一,您會認為這是一個發光的機會。
什麼是端到端查詢詞權重?
端到端查詢術語加權是指將查詢中每個術語的權重確定為整體模型的一部分的方法,而不依賴於手動編程或傳統的術語加權方案或其他獨立模型。
那看起來像什麼?
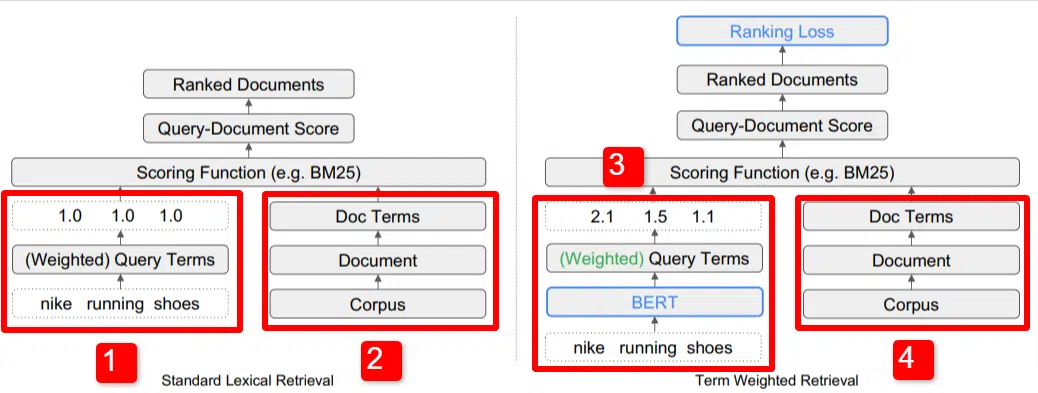
在這裡,我們看到了論文中概述的模型的關鍵區別之一的圖示(具體如圖 1 所示)。
在標準模型 (2) 的右側,我們看到與建議模型 (4) 相同的內容,即語料庫(索引中的完整文檔集),通向文檔,通向術語。
這說明了系統的實際層次結構,但您可以隨意地從上到下逆向思考它。 我們有條件。 我們尋找包含這些術語的文檔。 這些文件包含在我們所知道的所有文件的語料庫中。
在標准信息檢索 (IR) 架構的左下角 (1),您會注意到沒有 BERT 層。 他們的插圖(耐克跑鞋)中使用的查詢進入系統,權重的計算獨立於模型並傳遞給模型。
在此圖中,權重在查詢中的三個單詞之間均勻傳遞。 然而,情況並非一定如此。 這只是一個默認且很好的說明。
需要理解的重要一點是,權重是從模型外部分配的,並通過查詢輸入。 我們稍後將介紹為什麼這很重要。
如果我們查看右側的術語權重版本,您會發現查詢“nike running Shoes”輸入了 BERT(術語權重 BERT,具體而言是 TW-BERT),用於分配權重最適合該查詢。
從那裡開始,兩者都遵循類似的路徑,應用評分函數並對文檔進行排名。 但新模型還有一個關鍵的最後一步,這才是真正的重點,即排名損失計算。
我在上面提到的這種計算使得模型中確定的權重變得非常重要。 為了最好地理解這一點,讓我們快速討論一下損失函數,這對於真正理解這裡發生的事情很重要。
什麼是損失函數?
在機器學習中,損失函數基本上是計算系統的錯誤程度,該系統試圖學習盡可能接近零損失。
讓我們以一個旨在確定房價的模型為例。 如果您輸入房屋的所有統計數據,得出的價值為 250,000 美元,但您的房屋售價為 260,000 美元,則差額將被視為損失(這是絕對值)。
通過大量示例,模型被教導通過為給定的參數分配不同的權重來最小化損失,直到獲得最佳結果。 在這種情況下,參數可能包括平方英尺、臥室、庭院大小、與學校的距離等。
現在,回到查詢詞權重
回顧上面的兩個例子,我們需要關注的是 BERT 模型的存在,它為排名損失計算的下漏斗項提供權重。
換句話說,在傳統模型中,項的加權是獨立於模型本身進行的,因此無法響應整體模型的表現。 它無法學習如何提高權重。
在提議的系統中,這種情況發生了變化。 加權是在模型本身內部完成的,因此,當模型尋求提高其性能並減少損失函數時,它具有這些額外的旋鈕來將項加權引入方程。 字面上地。
ngrams
TW-BERT 的設計目的不是用單詞來操作,而是用 ngram 來操作。

這篇論文的作者很好地說明了為什麼他們使用ngrams 而不是單詞,他們指出,在查詢“nike running Shoes”中,如果你簡單地對單詞進行加權,那麼提及單詞nike、running 和Shoes 的頁面甚至可以排名很好如果正在討論“耐克跑步襪”和“滑板鞋”。
傳統的 IR 方法使用查詢統計和文檔統計,並且可能會顯示存在此問題或類似問題的頁面。 過去解決這個問題的嘗試主要集中在共現和排序上。
在這個模型中,ngram 的權重與我們之前示例中的單詞相同,因此我們最終得到如下結果:
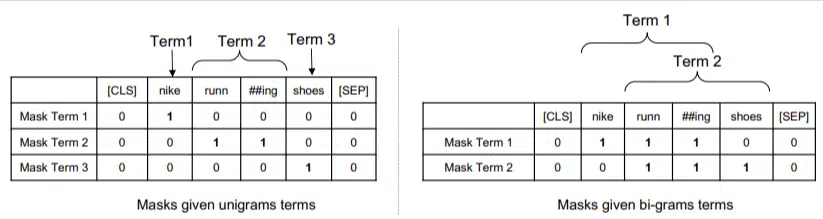
在左邊,我們看到查詢如何被加權為 uni-gram(1 個單詞的 ngram),而在右邊,我們看到如何將查詢加權為 bi-gram(2 個單詞的 ngram)。
該系統由於內置了權重,因此可以對所有排列進行訓練,以確定最佳的 ngram 以及每個 ngram 的適當權重,而不是僅依賴於頻率等統計數據。
零射擊
該模型的一個重要特徵是其在零短任務中的性能。 作者測試了:
- MS MARCO 數據集 – 用於文檔和段落排名的 Microsoft 數據集
- TREC-COVID 數據集 – COVID 文章和研究
- Robust04 – 新聞文章
- 共同核心 – 教育文章和博客文章
他們只有少量的評估查詢,並且沒有使用任何微調,這使得這是一個零樣本測試,因為該模型沒有經過訓練來專門對這些領域的文檔進行排名。 結果是:
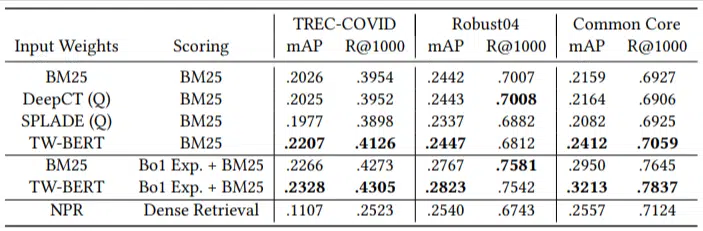
它在大多數任務中都表現出色,並且在較短的查詢(1 到 10 個單詞)上表現最好。
而且它是即插即用的!
好吧,這可能過於簡單化了,但作者寫道:
“將 TW-BERT 與搜索引擎評分器結合起來,可以最大限度地減少將其集成到現有生產應用程序中所需的更改,而現有的基於深度學習的搜索方法將需要進一步的基礎設施優化和硬件要求。 標準詞彙檢索器和其他檢索技術(例如查詢擴展)可以輕鬆利用學習到的權重。”
由於 TW-BERT 旨在集成到當前系統中,因此集成比其他選項更簡單、更便宜。
這一切對你意味著什麼
使用機器學習模型,很難預測 SEO 可以採取哪些措施(除了 Bard 或 ChatGPT 等可見部署之外)。
由於該模型的改進和易於部署(假設陳述準確),毫無疑問將部署該模型的排列。
也就是說,這是谷歌生活質量的一項改進,它將以低成本提高排名和零樣本結果。
我們真正可以信賴的是,如果實施,更好的結果將會更可靠地浮現。 這對於 SEO 專業人士來說是個好消息。
本文表達的觀點是客座作者的觀點,並不一定是搜索引擎土地的觀點。 此處列出了工作人員作者。