
在我們結束 2016 年的同時,讓我們談談結束 CRO 測試
已發表: 2021-10-23當我們接近又一年結束時,而“這個測試什麼時候可以結束?”的問題。 仍然每周至少出現一次在我的談話中,我覺得是時候坐下來寫下我的測試結論過程以及影響這個決定的所有變量。
今天,我會用兩個提示讓你暖和起來,當你接近結論的決定時要記住,然後我會進入我在接近這個決定時看到的四個變量。 吹掉你很久以前埋藏的那本統計教科書上的灰塵,讓我們開始吧。
前言提示#1:確保您的數據美觀且健壯
在設置測試之前,您應該已經知道自己的目標是什麼。 請注意我在那裡所說的“目標”。 是的,我們都知道您應該進行集中轉換; 您正在推動用戶進行的一件大事。 但是,我們可以跟踪與任何站點的許多其他交互,以觀察我們的更改是否也影響了這些交互。 有關幾個示例,請參見下圖。

在分析任何測試數據之前,請仔細檢查您的數據是否都在平等的競爭環境中。 確保您為每個目標提取了同一確切日期範圍內的數據,以便您可以適當地比較數據點,而不會歪曲一串數據。 當您在這裡時,還要確保您的所有目標數據看起來都“正常”,並且您不會懷疑任何從未看到任何動作的錯誤目標或無效目標。
前言提示#2:永遠不要對單一變量下結論
做出結論決定不能依賴於任何一個變量。 考慮這四個變量中的每一個,如果大多數變量相互補充,那麼您可以自信地得出結論。
如果所有變量都相互矛盾,您可能會看到多種不同的情況。 但在那個時候,如果你得出結論,你可能會做出一個不合邏輯的決定,並帶來代價高昂的後果。
這些變量中的每一個都受至少一個其他變量的影響或影響。 因此,互補數據支持自身,而矛盾數據迫使您將點與謊言聯繫起來。 不要這樣做!
變量#1:樣本量
樣本量很重要。 樣本量使我們能夠根據我們的人口(總用戶數)和可接受的誤差範圍(100 個目標的統計顯著性)自信地概括行為。
這實際上是關於比例的,但如果您一直在查看流量波動很小的同一個站點,那麼您可以設置一個底線目標來工作。
一個測試的每個部分有 100 個用戶是一個合理的最低限度。 即使在低流量的網站上,也很難根據少數用戶的數據來概括行為。 因此,越多越好。 更大的樣本量還有助於消除我們可以從異常值中看到的任何偏差。
然而,在一個相當大的電子商務網站上,每天至少有 1000 個用戶,我不可能考慮 100 個合適的用戶樣本量。 這完全取決於比例以及您網站的典型用戶量是多少。
此變量包括轉化次數以及您將考慮的目標的用戶。 即使您有一個低轉化率的網站,如果您將 0 次轉化與 2 次轉化進行比較,2 次轉化的變體絕對會獲勝,因為它是技術上唯一的變體。
確保您的轉化次數至少達到兩位數; 如果這是您的最低要求(兩位數),請確保您對其他三個變量有強烈的讚美行為。
或者,如果您對統計設置中的樣本量沒有太多經驗,則可以使用這個方便的樣本量計算器來確定適合您的樣本量。
變量 #2:測試持續時間
理想情況下,我會在 2-6 週的任何地方運行測試。
兩周是最低限度,因為您消除了任何變量具有“好”或“壞”週的可能性,並且要么拖著愉快的交通要么趕走低動機的交通。 六周是一個可愛的最大值,因為它是一個足夠寬的時間網,可以捕捉您可以看到的任何波動。
但是,請注意,永遠運行測試也可能對您的測試有害。 測試結果中的一個重要因素是用戶對新刺激的反應。 因此,當我們第一次啟動測試時,我們往往會看到巨大的飛躍,其中一個變體正在大幅失敗,而其他變體則在其連續獲勝的道路上滑行。 隨著時間的推移,變化之間的這種巨大差距趨於正常化和縮小,因為“新”已經消失,而返回的用戶不像以前那樣受到新變化的影響。 因此,測試運行的時間越長,改動就越不新穎,對那些返回用戶的行為的影響也就越小。
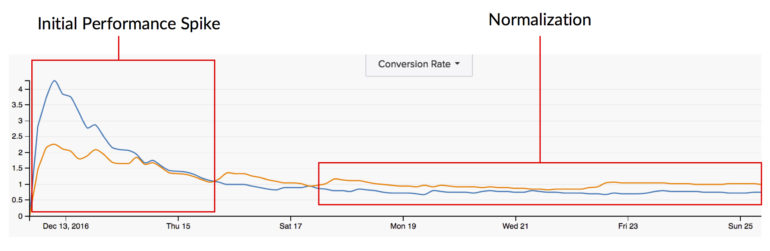
變量 #3:統計顯著性
雖然統計顯著性對於在您的結論中聲明“可信度”至關重要,但它也可能非常具有誤導性。
統計顯著性確定兩個比率的變化是由於正態方差還是由於外部因素。 因此,理論上,當我們達到很強的統計顯著性時,我們知道我們的更改對用戶產生了影響。
理想情況下,您希望統計顯著性盡可能接近 100%。 越接近 100%,誤差幅度就越小。 這意味著可以在更一致的基礎上重現您的結果。 您的統計顯著性越高,如果您實施獲勝變體,您保持該轉化率提升的機會就越大。 95% 是一個很好的高目標。 90% 是一個定居的好地方。 任何低於 90% 的值,您實際上都可能“自信地”得出結論。
這裡的威脅是樣本量真的很重要。 您可以在幾天內達到 98% 的統計顯著性,並且實際上只查看總共 16 個用戶,這顯然不是一個值得信賴的樣本量。
統計顯著性還可以捕捉到我之前在首次啟動測試時提到的巨大性能峰值。 測試具有所有的觸發能力,我們也知道隨著時間的推移數據會標準化。 因此,過早地衡量統計顯著性可能會讓我們完全錯誤地了解這種變化最有可能如何在更長期的基礎上影響我們的用戶。
此外,並非每個測試都會獲得統計顯著性。 您所做的一些更改可能不會對用戶行為產生足夠大的影響,以至於被視為超出正常差異。 沒關係! 這只是意味著您需要測試更大的更改以更多地吸引用戶的注意力。
變量 #4:數據一致性
這個適用於所有那些觸發器測試。 有一些測試拒絕正常化並拒絕為您提供明顯的贏家。 他們會花每一天的時間向您展示不同的獲勝者,他們會絕對讓您發瘋。
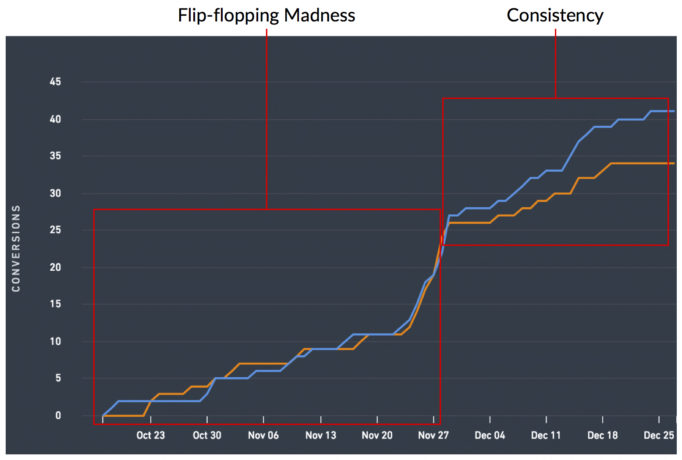
但它們確實存在,這正是尋找一致的數據方向性如此重要的原因。 您宣布獲勝者的變體是否一直是獲勝者? 如果沒有,為什麼它不總是贏家? 如果你不能自信地回答“為什麼?” 那麼,如果您以贏家的身份實施變體,那麼實施贏家可能會損害您的底線。
我還測量了控件的轉化率和變體的轉化率(又名“提升”或“下降”)之間的差異。 我也希望這個指標保持一致,以便我可以確保測試不在初始峰值階段。
定期計算統計顯著性以查看該指標的一致性也很有用。
最後的想法
結束任何類型的測試都不是開玩笑,而且充滿壓力。 如果你做出錯誤的決定並實施了一些你“覺得”是贏家的東西,而數據卻另有說明,那麼你的底線和你的用戶都會受到影響。
從每個可行的角度得出一個結論,這樣你就可以確保你有一個由數據驅動的真正自信的結論!