
Wikipedia Web Scraping 2023:提取數據進行分析
已發表: 2023-03-29在線抓取使您能夠從網站收集開放數據,用於價格比較、市場研究、廣告驗證等目的。
通常會提取大量必要的公共數據,但當您遇到封鎖時,提取可能會變得具有挑戰性。
限制可能是速率阻塞或 IP 阻塞(請求的 IP 地址受到限制,因為它來自禁止區域、禁止類型的 IP 等)。 (該 IP 地址被阻止,因為它發出了多次請求)。

現在,如果您想抓取一些有用的知識和信息,那麼我相信您一定考慮過抓取維基百科,這是包含大量信息的知識百科全書。
讓我們了解一些關於網絡抓取維基百科的事情。
目錄
維基百科網頁抓取
Web 抓取是一種從 Internet 收集數據的自動化方法。 本文提供了有關網絡抓取的深入信息、與網絡抓取的比較以及支持網絡抓取的論據。
目標是使用各種網絡抓取方法從維基百科主頁收集數據,然後對其進行解析。
您將更加熟悉各種網絡抓取方法、Python 網絡抓取庫以及數據提取和處理過程。
Web 抓取和 Python
Web 抓取本質上是使用以編程語言創建的軟件從大量網站的大量數據中提取結構化數據並將其保存在我們設備本地的過程,最好是 Excel 工作表、JSON 或電子表格。
這有助於程序員為小型和大型項目創建合乎邏輯、易於理解的代碼。
Python 主要被認為是網絡抓取的最佳語言。 它可以有效地處理大多數與網絡爬蟲相關的任務,更像是一個多面手。
如何從維基百科抓取數據?
可以通過多種方式從網頁中提取數據。
例如,您可以使用 Python 等計算機語言自己實現它。 但是,除非您精通技術,否則您需要大量學習才能在此過程中做很多事情。
這也很耗時,可能需要與手動梳理維基百科頁面一樣長的時間。 此外,還可以在線訪問免費的網絡抓取工具。 然而,他們經常缺乏可靠性,而且他們的供應商可能有不正當的意圖。
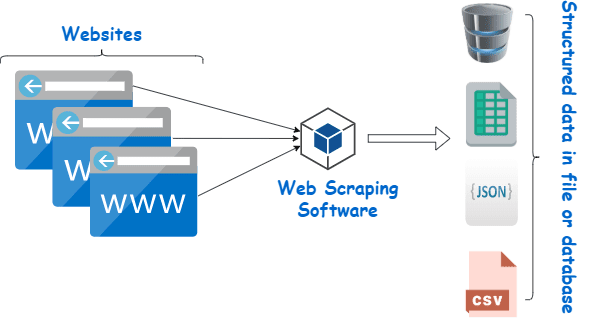
從信譽良好的供應商那裡投資一個像樣的網絡抓取工具是收集 Wiki 數據的最佳方法。
下一步通常很簡單,因為提供商會向您提供有關如何安裝和使用刮板的說明。
代理是一種工具,您可以將其與 wiki 抓取工具結合使用,以更有效地抓取數據。 基於 Python 的框架,如 Scrapy、Scraping Robot 和 Beautiful Soup 只是使用這種語言進行抓取是多麼容易的幾個例子。
從維基百科抓取數據的代理
您需要速度極快、使用安全且保證不會在您需要時出現故障的代理,以便有效地抓取數據。 Rayobyte 以合理的價格提供此類代理。
我們努力提供各種代理,因為我們知道每個用戶都有不同的偏好和用例。
用於網絡抓取維基百科的旋轉代理
代理實例是定期輪換其 IP 地址的實例。 此外,為了防止中斷,IP 地址會在發生禁令時立即更改。 這使得這個特定的代理成為網站抓取的絕佳選擇。
相比之下,靜態代理只有一個 IP 地址。 如果您的 ISP 沒有啟用自動替換,您將遇到一堵磚牆,如果您只能訪問一個 IP 地址並被阻止。 因此,靜態代理不是網絡抓取的最佳選擇。
用於網絡抓取 Wiki 數據的住宅代理
住宅代理是互聯網服務提供商 (ISP) 分配並與特定家庭相關聯的代理 IP 地址。 因為它們來自真實的人,所以獲取它們非常具有挑戰性。 因此,它們稀缺且相對昂貴。


當您使用住宅代理來抓取數據時,您似乎是一個日常用戶,因為它們鏈接到真實個人的地址。
因此,使用住宅代理可以顯著降低被發現和阻止的機會。 因此,它們是數據抓取的優秀候選者。
用於收集 wiki 數據的旋轉住宅代理
結合了我們剛才談到的兩種類型的旋轉住宅代理是網絡抓取維基百科的最佳代理。
您可以使用頻繁輪換的代理訪問大量家庭 IP。
這一點很重要,因為儘管難以識別住宅代理,但它們生成的請求量最終會引起被抓取網站的注意。
輪換確保即使 IP 地址不可避免地被列入黑名單,項目也可以繼續進行。
因此,無論您決定使用多個數據中心代理還是更願意投資一些住宅代理,我們都能滿足您的需求。
通過以 1GBS 速度運行的代理、無限帶寬和全天候客戶幫助,您將享受到最好的網絡抓取體驗。
你也可以閱讀
- 最佳網頁抓取技術:實用指南
- Octoparse 評論 真的是很好的網頁抓取工具嗎?
- 最好的網頁抓取工具
- 什麼是網頁抓取? - 它是如何使用的? 它如何使您的業務受益
為什麼要抓取維基百科?
維基百科是目前在線世界中最受信任和信息最豐富的服務之一。 在這個平台上,幾乎所有你能想到的話題都有答案和信息。
所以,維基百科自然是一個很好的數據來源。 讓我們討論一下您應該抓取維基百科的主要原因。
用於學術研究的網頁抓取
數據收集是研究中最痛苦的活動之一。 正如已經討論過的,網絡抓取工具使這個過程更快更容易,同時也為您節省了大量的時間和精力。
使用網絡抓取工具,您可以快速掃描大量 wiki 頁面並以有組織的方式收集您需要的所有數據。
暫時假設您的目標是確定抑鬱症和陽光照射是否因國家/地區而異。
您可以使用維基爬蟲來查找信息,例如不同國家的抑鬱症患病率和他們的晴天時間,而不是瀏覽大量的維基百科條目。
聲譽管理
製作維基百科頁面已成為現代許多不同類型企業必須做的營銷策略,因為維基百科帖子經常出現在谷歌的首頁。
但是,在維基百科上擁有一個頁面不應該是您營銷工作的終點。 維基百科是一個眾包平台,所以故意破壞是經常發生的事情。
因此,有人可能會向您公司的頁面添加不利信息並損害您的聲譽。 或者,他們可能會在相關的 wiki 文章中誹謗您的企業。
因此,您必須密切關注您的 Wiki 頁面以及提及您的業務的其他頁面。 您可以藉助 wiki 抓取工具輕鬆完成此操作。
您可以定期搜索維基百科頁面以查找有關您的業務的參考資料,並指出那裡的任何破壞行為。
提升搜索引擎優化
您可以利用維基百科來增加您網站的訪問量。
通過使用 Wiki 數據抓取器找到與您的業務和目標受眾相關的頁面,創建您想要更改的文章列表。
首先閱讀文章並進行一些有用的調整,以獲得作為網站貢獻者的信譽。
一旦建立了一定的可信度,您就可以在鏈接斷開或需要引用的地方添加到您網站的鏈接。
快速鏈接
- 最佳法國代理人
- 頂級最佳 Spotify 代理
- 最佳耐克代理
用於網絡抓取的 Python 庫
如前所述,Python 是世界上最流行、最負盛名的編程語言和網絡抓取工具。 現在讓我們看看現在可用的 Python 網絡抓取庫。
用於 Web 抓取的請求(HTTP for Humans)庫
它用於發送不同的 HTTP 請求,例如 GET 和 POST。 在所有庫中,它是最基礎的,也是最關鍵的。
用於網頁抓取的 lxml 庫
lxml 包提供了對來自網站的 HTML 和 XML 文本的非常快速和高性能的解析。 如果你打算抓取龐大的數據庫,這是一個選擇。
用於網頁抓取的漂亮湯庫
它的工作是構建用於內容解析的解析樹。 對於初學者來說是一個很好的起點,並且對用戶非常友好。
用於網頁抓取的 Selenium 庫
這個庫解決了上面提到的所有庫都有的問題,即從動態填充的網頁中抓取內容。
它最初是為 Web 應用程序的自動化測試而設計的。 因此,它速度較慢且不適合工業級任務。
用於網頁抓取的 Scrapy
一個完整的使用異步使用的網絡抓取框架是所有包的BOSS。 這提高了效率並使其非常快。
結論
所以這幾乎是您需要了解的關於維基百科網頁抓取的最重要的方面。 請繼續關注我們,以獲取更多有關 Web Scraping 的信息性帖子以及更多內容!
快速鏈接
- 旅行費用匯總的最佳代理
- 最佳法國代理人
- 最佳 Tripadvisor 代理
- 最佳 Etsy 代理
- IPRoyal 優惠券代碼
- 最佳 TikTok 代理