
為期一年的 SEO 案例研究:關於 Googlebot 您需要了解的內容
已發表: 2019-08-30編者註: JetOctopus 爬蟲 Serge Bezborodov 的首席執行官就如何使您的網站對 Googlebot 具有吸引力提供了專家建議。 本文中的數據基於長達一年的研究和 3 億個已抓取的頁面。
幾年前,我試圖增加我們擁有 500 萬頁的工作聚合網站的訪問量。 我決定使用 SEO 代理服務,預計流量會飆升。 但是我錯了。 我沒有進行全面審核,而是閱讀了塔羅牌。 這就是為什麼我回到原點並創建了一個網絡爬蟲來進行全面的頁面搜索引擎優化分析。
一年多以來,我一直在監視 Googlebot,現在我準備分享有關其行為的見解。 我希望我的觀察至少可以闡明網絡爬蟲的工作原理,最多可以幫助您有效地進行頁面優化。 我收集了對新網站或擁有數千頁的網站有用的最有意義的數據。
您的頁面是否出現在 SERP 中?
要確定哪些頁面在搜索結果中,您應該檢查整個網站的索引能力。 然而,在一個超過 1000 萬頁的網站上分析每個 URL 的成本很高,大約相當於一輛新車的價格。
讓我們改用日誌文件分析。 我們以下列方式與網站合作:我們像搜索機器人一樣抓取網頁,然後分析半年收集的日誌文件。 日誌顯示機器人是否訪問網站、抓取了哪些頁面以及機器人訪問頁面的時間和頻率。
抓取是搜索機器人訪問您的網站、處理網頁上的所有鏈接並將這些鏈接放入索引中的過程。 在抓取過程中,機器人會將剛剛處理的 URL 與索引中已有的 URL 進行比較。 因此,機器人會刷新數據並從搜索引擎數據庫中添加/刪除一些 URL,為用戶提供最相關和最新的結果。
現在,我們可以很容易地得出以下結論:
- 除非搜索機器人位於 URL 上,否則該 URL 可能不會出現在索引中。
- 如果 Googlebot 一天多次訪問該網址,則該網址具有高優先級,因此需要您特別注意。
總而言之,這些信息揭示了是什麼阻礙了您網站的有機增長和發展。 現在,您的團隊可以明智地優化網站,而不是盲目操作。
我們主要與大型網站合作,因為如果您的網站很小,Googlebot 遲早會抓取您的所有網頁。
相反,當爬蟲訪問網站管理員看不到的頁面時,擁有 100,000 多個頁面的網站會面臨問題。 寶貴的抓取預算可能會浪費在這些無用甚至有害的頁面上。 同時,由於網站結構混亂,機器人可能永遠找不到您的盈利頁面。
抓取預算是 Googlebot 準備在您的網站上花費的有限資源。 它的創建是為了確定分析內容和分析時間的優先順序。 抓取預算的大小取決於很多因素,例如您網站的大小、網站結構、用戶查詢量和頻率等。
請注意,搜索機器人對完全抓取您的網站不感興趣。
搜索引擎機器人的主要目的是以最小的資源損失為用戶提供最相關的答案。Bot 會根據主要目的抓取盡可能多的數據。 因此,幫助機器人挑選最有用和最有利可圖的內容是您的任務。
監視 Googlebot
在過去的一年裡,我們在大型網站上掃描了超過 3 億個 URL 和 60 億條日誌行。 根據這些數據,我們追踪了 Googlebot 的行為以幫助回答以下問題:
- 哪些類型的頁面會被忽略?
- 哪些頁面被頻繁訪問?
- bot需要注意什麼?
- 什麼沒有價值?
以下是我們的分析和發現,而不是對 Google 網站管理員指南的重寫。 事實上,我們不會給出任何未經證實和不合理的建議。 為方便起見,每個點都基於事實統計數據和圖表。
讓我們切入正題,找出答案:
- 對 Googlebot 真正重要的是什麼?
- 什麼決定了機器人是否訪問該頁面?
我們確定了以下因素:
與索引的距離
DFI 代表與索引的距離,是您的 URL 在點擊中與主/根/索引 URL 的距離。 這是影響 Googlebot 訪問頻率的最重要標準之一。 這是一個教育視頻,可以了解有關 DFI 的更多信息。
請注意,DFI 不是 URL 目錄中斜杠的數量,例如:
site.com/shop/iphone/iphoneX.html – DFI– 3__ _
因此,DFI 是由主頁上的 CLICKS 準確計算的
https://site.com/shop/iphone/iphoneX.html
https://site.com iPhone 目錄 → https://site.com/shop/iphone iPhone X → https://site.com/shop/iphone/iphoneX.html – DFI – 2
您可以在下面看到 Googlebot 對帶有 DFI 的 URL 的興趣在上個月和過去六個月中是如何逐漸減少的。
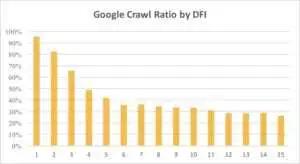
如您所見,如果 DFI 為 5 t0 6,則 Googlebot 僅抓取了一半的網頁。 如果 DFI 較大,則處理頁面的百分比會降低。 表中指標統一為1800萬頁。 請注意,數據可能因特定網站的利基市場而異。
該怎麼辦?
很明顯,在這種情況下最好的策略是避免長度超過 5 的 DFI,構建易於導航的網站結構,特別注意鏈接等。
事實上,這些措施對於 100,ooo-plus 頁面的網站來說真的很耗時。 通常大型網站都有很長的重新設計和遷移歷史。 這就是為什麼網站管理員不應該只刪除 DFI 為 10、12 甚至 30 的頁面。此外,從經常訪問的頁面插入一個鏈接也不能解決問題。
應對長 DFI 的最佳方法是檢查和估計這些 URL 是否相關、是否有利可圖以及它們在 SERP 中的位置。
DFI 較長但在 SERP 中排名較高的頁面具有很高的潛力。 為了增加高質量頁面的流量,網站管理員應該從下一頁插入鏈接。 一到兩個鏈接不足以取得切實進展。
從下圖中可以看出,如果頁面上的鏈接超過 10 個,Googlebot 會更頻繁地訪問 URL。
鏈接
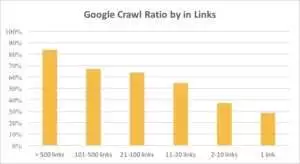
事實上,網站越大,網頁上的鏈接數量就越多。 該數據實際上來自 100 萬多個頁面的網站。

如果您發現盈利頁面上的鏈接少於 10 個,請不要驚慌。 首先,檢查這些頁面是否優質且有利可圖。 當你這樣做時,不要急於在高質量的頁面上插入鏈接,迭代要短,在每個步驟後分析日誌。
內容大小
內容是 SEO 分析中最受歡迎的方面之一。 當然,您網站上的相關內容越多,您的抓取率就越高。 您可以在下面看到 Googlebot 對少於 500 字的頁面的興趣是如何急劇下降的。
該怎麼辦?
根據我的經驗,所有少於 500 字的頁面中有將近一半是垃圾頁面。 我們看到一個案例,一個網站有 70,000 個頁面,只列出了衣服的尺寸,所以只有部分頁面被索引。
因此,首先檢查您是否真的需要這些頁面。 如果這些網址很重要,你應該在上面添加一些相關的內容。 如果您沒有什麼要添加的,請放鬆並保持這些 URL 不變。 有時什麼都不做比發布無用的內容更好。
其他因素
以下因素會顯著影響抓取率:
加載時間
網頁速度對於抓取和排名至關重要。 Bot 就像人一樣:它討厭等待網頁加載的時間過長。 如果您的網站上有超過 100 萬個頁面,搜索機器人可能會在 1 秒的加載時間內下載 5 個頁面,而不是等待 5 秒內加載的一個頁面。
該怎麼辦?
事實上,這是一項技術任務,並沒有“一刀切”的解決方案,例如使用更大的服務器。 主要思想是找到問題的瓶頸。 您應該了解為什麼網頁加載緩慢。 只有揭露原因後,你才能採取行動。
獨特內容和模板內容的比例
獨特數據和模板化數據之間的平衡很重要。 例如,您有一個包含各種寵物名稱的網站。 您真的可以收集到多少關於該主題的相關且獨特的內容?
Luna 是最受歡迎的“名人”狗名,其次是 Stella、Jack、Milo 和 Leo。
搜索機器人不喜歡將資源花在這些類型的頁面上。
該怎麼辦?
保持平衡。 用戶和機器人不喜歡訪問具有復雜模板、一堆外向鏈接和很少內容的頁面。
孤立頁面
孤立頁面是不在網站結構中的 URL,您不知道這些頁面,但這些孤立頁面可能會被機器人抓取。 為了說清楚,看下圖中的歐拉圓:

可以看到young網站的正常情況,結構已經有一段時間沒有改動了。 您和爬蟲可以分析 900,000 個頁面。 大約 500,000 個頁面由爬蟲處理但不為 Google 所知。 如果您使這 500,000 個 URL 可索引,您的流量肯定會增加。
注意:即使是一個年輕的網站也包含一些不在網站結構中但經常被機器人訪問的頁面(圖中藍色部分)。
這些頁面可能包含垃圾內容,例如無用的自動生成的訪問者查詢。
但是大網站很少這麼準確。 有歷史的網站通常是這樣的:

另一個問題是:Google 比您更了解您的網站。 可能有被刪除的頁面、基於 JavaScript 或 Ajax 的頁面、損壞的重定向等等。 曾經我們遇到這樣一種情況,由於程序員的失誤,站點地圖中出現了 500,000 個損壞鏈接的列表。 三天后,錯誤被發現並修復,但 Googlebot 已經訪問這些損壞的鏈接半年了!
通常,您的抓取預算經常浪費在這些孤立頁面上。
該怎麼辦?
有兩種方法可以解決這個潛在的問題:第一種是規範的:清理混亂。 組織網站結構,正確插入內部鏈接,通過添加來自索引頁面的鏈接將孤立頁面添加到 DFI,為程序員設置任務並等待下一次 Googlebot 訪問。
第二種方法是提示:收集孤立頁面列表並檢查它們是否相關。 如果答案是“是”,則使用這些 URL 創建站點地圖並將其發送給 Google。 這種方式更簡單快捷,但只有一半的孤立頁面會在索引中。
下一個級別
搜索引擎算法已經改進了二十年,認為搜索爬行可以用幾張圖來解釋是天真的想法。
我們為每個頁面收集了 200 多個不同的參數,我們預計到今年年底這個數字將會增加。 想像一下您的網站是一個包含 100 萬行(頁面)的表格,並將這些行乘以 200 列,簡單的示例不足以進行全面的技術審核。 你同意?
我們決定深入研究並使用機器學習來找出在每種情況下影響 Googlebots 抓取的因素。

一方面,網站鏈接至關重要,而內容是另一個關鍵因素。
這項任務的主要目的是從復雜而龐大的數據中獲得簡單的答案:您網站上的什麼對索引化影響最大? 哪些 URL 集群與相同的因素相關聯? 這樣您就可以全面地與他們合作。
在我們的 HotWork 聚合器網站上下載和分析日誌之前,關於機器人可見但我們不可見的孤立頁面的故事對我來說似乎是不現實的。 但真實情況更讓我吃驚:Crawl 顯示了 500 個帶有 301 重定向的頁面,但 Yandex 發現了 700,000 個具有相同狀態代碼的頁面。
通常,技術極客不喜歡存儲日誌文件,因為這些數據會使磁盤“超載”。 但客觀地說,在大多數月訪問量高達 1000 萬的網站上,日誌存儲的基本設置是完美的。
說到日誌量,最好的解決方案是創建一個存檔並在 Amazon S3-Glacier 上下載它(您只需 1 美元就可以存儲 250 GB 的數據)。 對於系統管理員來說,這個任務就像泡一杯咖啡一樣簡單。 將來,歷史日誌將有助於揭示技術錯誤並估計 Google 更新對您網站的影響。